01
背景
部门中一核心应用,因为各种原因其依赖的mysql数据库一直处于高水位运行,无论是硬件资源,还是磁盘使用率或者qps等都处于较高水位,急需在大促前完成对应的治理,降低各项指标,以保障在大促期间平稳运行,以期更好的支撑前端业务。
02
基本情况
背景
部门中一核心应用,因为各种原因其依赖的mysql数据库一直处于高水位运行,无论是硬件资源,还是磁盘使用率或者qps等都处于较高水位,急需在大促前完成对应的治理,降低各项指标,以保障在大促期间平稳运行,以期更好的支撑前端业务。
基本情况
2.1 数据库
| 域名 | 主/从 | cpu | 内存 | 容量 | disk(/export)使用率(%) | memory使用率(%) | 数据库版本 | |
| 1x.x.x.36 | xxx_m.mysql.jddb.com | 主 | 64 | 256g | 16t | 66.3% | 87.7% | 5.5.14 |
| 1x.x.x.73 | xxx_sb.mysql.jddb.com | 从 | 64 | 256g | 16t | 66.6% | 85.2% | 5.5.14 |
| 1x.x.x.135 | xxx_sa.mysql.jddb.com | 从 | 64 | 128g | 128t | 76.5% | 57.2% | 5.5.14 |
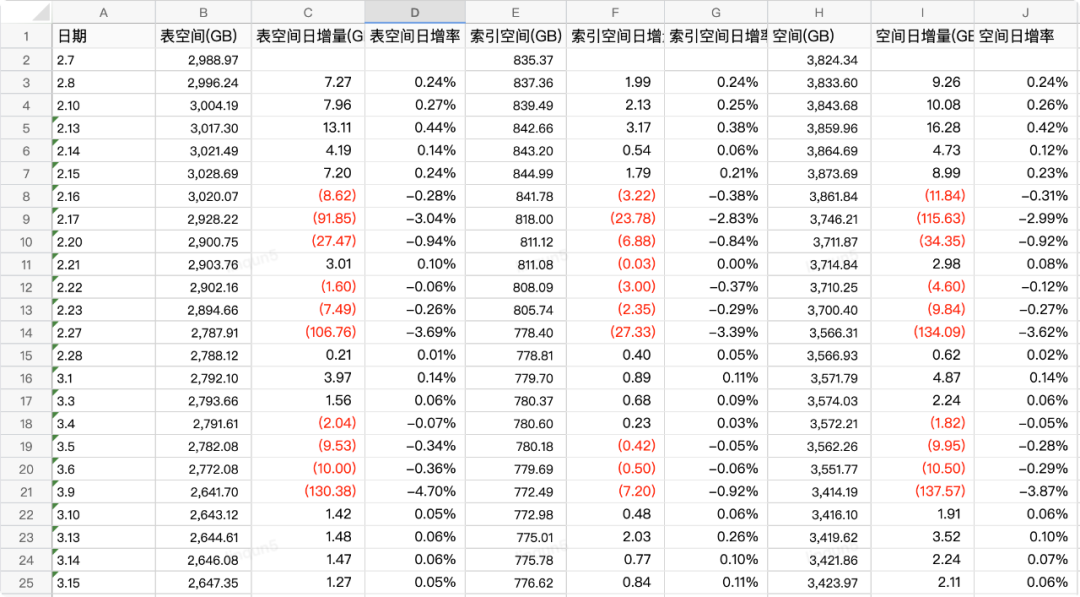
2.2 磁盘空间
截止到2月底,各数据库磁盘空间占用情况如下:
| ip | 主从 | 使用大小(g) | 已用比例(%) | 剩余空间(g) | 周增长量(g) | 预计报警(d) | 预计可用(d) | binlog(g) | 日志(g) |
| 1x.x.x.36 | m | 5017 | 69 | 2151 | 9 | 617.1 | 1735.8 | 159.45543 | 6 |
| 1x.x.x.73 | s | 5017 | 71 | 2151 | 14.8 | 333.2 | 1012.7 | 158.52228 | 1 |
| 1x.x.x.135 | s | 5017 | 4 | 129000 | 14.4 | 2986 | 8958 | 158.13548 | 0 |
从上表咱们可以看出,各数据库的磁盘空间占用已处于较高水位,急需需要治理,通过结转或删除数据来降低磁盘占用比例。
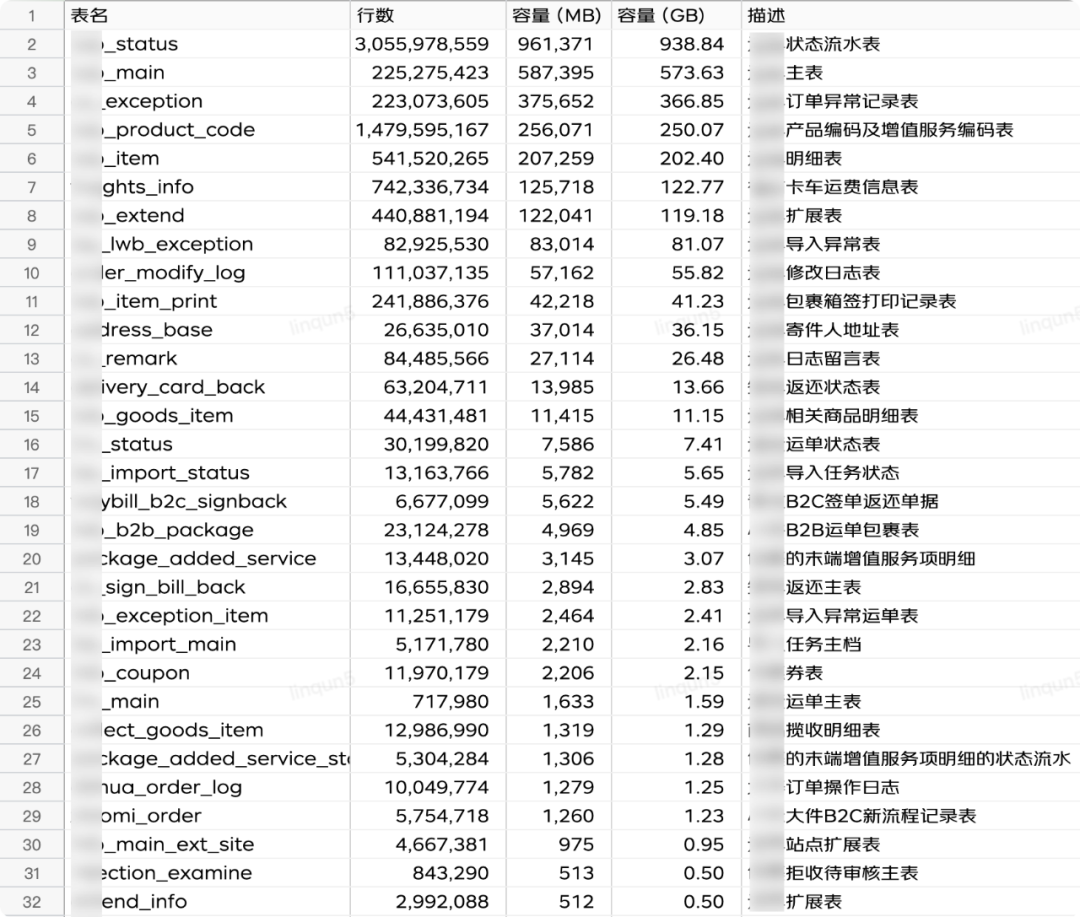
2.3 表空间
数据库存在大表其中一个原因是多条业务线共用一个应用,同时代码层面抽象的部分不够抽象,扩展部分又不容易扩展,导致数据都糅合和一起。
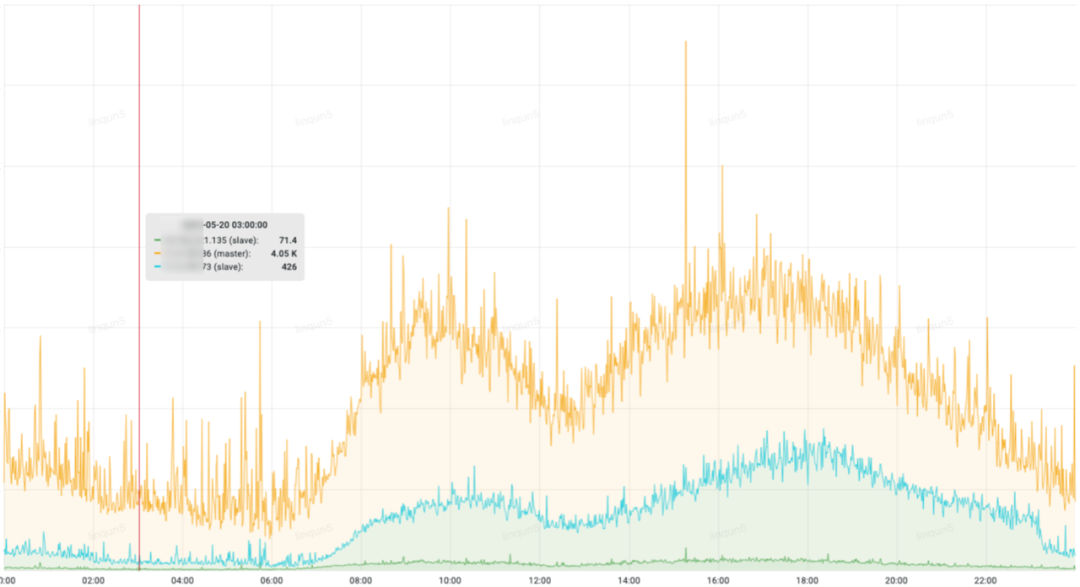
2.4 qps情况
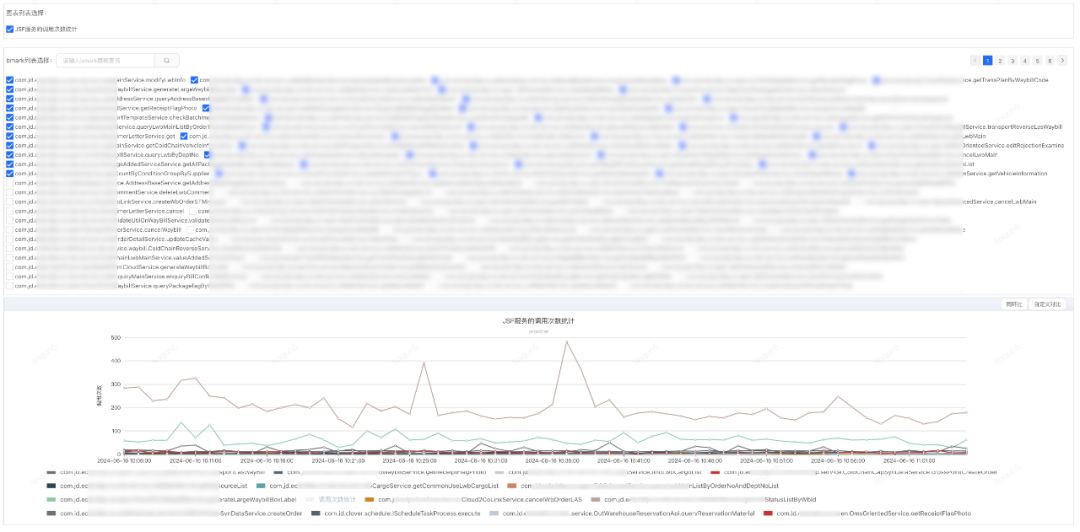
黄色的为主库的qps,可以看出主库的查询量远大于从库,由于各种原因,应用代码里只有少部分的查询是走的从库,急需将部分流量大的查询接口从主库切到从库去查询。
2.5 慢sql
不论是主库还是从库,都有偶发的慢sql查询,引发磁盘繁忙,影响系统稳定性。

治理目标
-
数据结转,降低磁盘使用率,处较低水位运行。
-
降低主库qps,保障主库安全。
-
慢sql治理,避免导致磁盘繁忙而影响整体业务。
4.1 大表数据结转
| 表名 | 表空间gb | 索引空间gb | 大数据 | 结转类型 | 开始值 | 完成值 |
| xxx_status | 991.65 | 265.29 | 是 | 删除 | 2020-04-30 01:00:00 | 2022-01-01 |
| xxx_main | 611.80 | 149.91 | 是 | 结转 | 2021-09-30 | 2022-01-01 |
| xxx_exception | 382.80 | 24.65 | 否 | 删除 | 2018-05-16 20:30:04 | 2022-01-01 |
| xxx_product_code | 244.18 | 61.54 | 是 | 删除 | 23亿 | |
| xxx_item | 208.66 | 85.46 | 是 | 结转 | 2016-12-29 13:20:33 | 2022-01-01 |
| xxx_freights_info | 128.78 | 109.03 | 是 | 结转 | 2018-11-29 13:26:00 | |
| xxx_extend | 127.36 | 26.07 | 是 | 结转 | 2019-03-29 14:30:00 | 2022-01-01 |
 ps:红色数字部分为负值,也就是磁盘的释放空间。
ps:红色数字部分为负值,也就是磁盘的释放空间。
4.2 拦截无参数查询
mybatis-config.xml里的plugin配置:

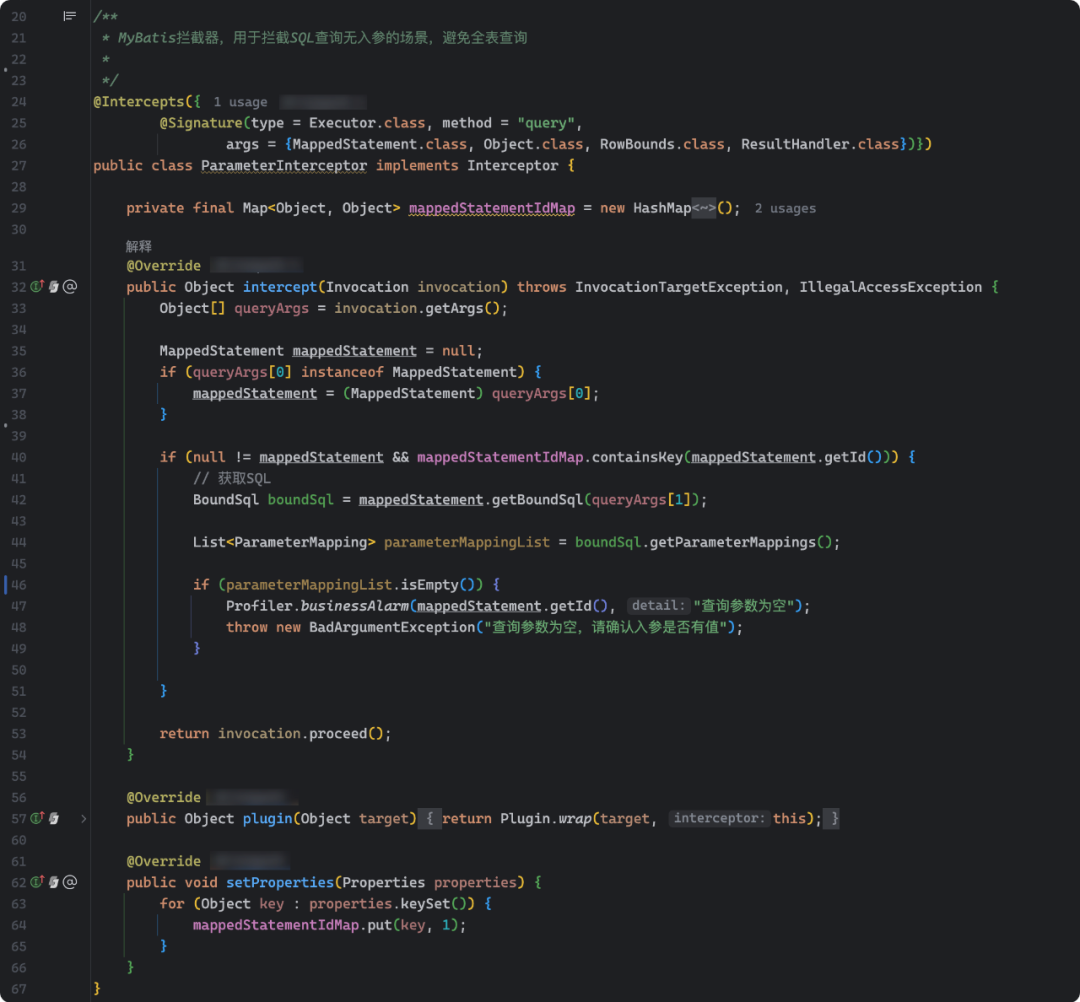
import org.apache.ibatis.executor.executor;import org.apache.ibatis.mapping.boundsql;import org.apache.ibatis.mapping.mappedstatement;import org.apache.ibatis.mapping.parametermapping;import org.apache.ibatis.plugin.*;import org.apache.ibatis.session.resulthandler;import org.apache.ibatis.session.rowbounds;import java.lang.reflect.invocationtargetexception;import java.util.hashmap;import java.util.list;import java.util.map;import java.util.properties;/*** mybatis拦截器,用于拦截sql查询无入参的场景,避免全表查询**/({(type = executor.class, method = "query",args = {mappedstatement.class, object.class, rowbounds.class, resulthandler.class})})public class parameterinterceptor implements interceptor {private final map<object, object> mappedstatementidmap = new hashmap<object, object>();public object intercept(invocation invocation) throws invocationtargetexception, illegalaccessexception {object[] queryargs = invocation.getargs();mappedstatement mappedstatement = null;if (queryargs[0] instanceof mappedstatement) {mappedstatement = (mappedstatement) queryargs[0];}if (null != mappedstatement && mappedstatementidmap.containskey(mappedstatement.getid())) {// 获取sqlboundsql boundsql = mappedstatement.getboundsql(queryargs[1]);list<parametermapping> parametermappinglist = boundsql.getparametermappings();if (parametermappinglist.isempty()) {profiler.businessalarm(mappedstatement.getid(), "查询参数为空");throw new badargumentexception("查询参数为空,请确认入参是否有值");}}return invocation.proceed();}public object plugin(object target) {return plugin.wrap(target, this);}public void setproperties(properties properties) {for (object key : properties.keyset()) {mappedstatementidmap.put(key, 1);}}}
4.3 查询切从库
jsf的配置文件新增filter
<jsf:filter id="callfilter" ref="jsfinvokefilter"/>import com.jd.jsf.gd.filter.abstractfilter;import com.jd.jsf.gd.msg.requestmessage;import com.jd.jsf.gd.msg.responsemessage;import com.jd.jsf.gd.util.rpccontext;import com.jd.ump.profiler.proxy.profiler;import org.springframework.stereotype.component;import java.util.hashmap;import java.util.map;/*** jsf filter* jsf服务的调用次数统计*/public class jsfinvokefilter extends abstractfilter {/*** 按api接口统计方法调用量 - 业务监控key*/private static final string api_provider_method_count_key = "api.jsf.provider.method.count.key";private static final string api_consumer_method_count_key = "api.jsf.consumer.method.count.key";public responsemessage invoke(requestmessage requestmessage) {string key;if (rpccontext.getcontext().isproviderside()) {key = api_provider_method_count_key;} else {key = api_consumer_method_count_key;}string method = requestmessage.getclassname() + "." + requestmessage.getmethodname();map<string, string> tags = new hashmap<string, string>(2);tags.put("bmark", method);tags.put("bcount", "1");profiler.sourcedatabystr(key, tags);return getnext().invoke(requestmessage);}}
明细项
import osimport openpyxlimport jsonimport requestsfrom cookies import cookieimport timeheaders = {'cookie': cookie,'content-type': 'application/json','token': '******','erp': '******'}def get_jsf(start_time, end_time):url = 'http://xxx.taishan.jd.com/api/xxx/xxx/xxx/'body = {}params = {'starttime': start_time,'endtime': end_time,'endpointkey': 'api.jsf.provider.method.count.key','quicktime': int((end_time - start_time) / 1000),'markflag': 'true','marklimit': 500}res = requests.post(url=url, data=json.dumps(body), params=params, headers=headers)print('url: ', res.request.url) # 查看发送的url# print('response: ', res.text) # 返回请求结果res_json = json.loads(res.text)title = ['序号', 'jsf key', '次数', '占比%', '峰值', '次/秒', '峰值时间']i = 0keys = {}marks = res_json['response_data']['marks']for mark in marks:keys.setdefault(mark, [0, 0, 0, ''])data = []records = res_json['response_data']['monitordata']print(len(records))for key, value in records.items():count = 0max_val = 0max_time = ''for val in value:v = val['value']count += vif v > max_val:max_val = vmax_time = time.strftime("%y-%m-%d %h:%m:%s", time.localtime(int(val['datetime'] / 1000)))keys[key] = [count, max_val, int(max_val / 1200), max_time]key_list = sorted(keys.items(), key=lambda x: x[1], reverse=true)# print(key_list)all_count = key_list[0][1][0]for key in key_list:values = [i, key[0], key[1][0], str(round(key[1][0] / all_count * 100, 2)) + '%', key[1][1], key[1][2], key[1][3]]data.append(values)i += 1## # print(data)#path = r"/users/xxx/documents/治理/qps治理/"os.chdir(path) # 修改工作路径workbook = openpyxl.workbook()sheet = workbook.activesheet.title = 'jsf接口调用次数统计'sheet.append(title)for record in data:sheet.append(record)workbook.save('jsf接口调用次数统计-' + str(start_time / 1000) + '-' + str(end_time / 1000) + '.xlsx')def change_time(dt):# 转换成时间数组time_array = time.strptime(dt, "%y-%m-%d %h:%m:%s")# 转换成时间戳timestamp = time.mktime(time_array)return int(timestamp * 1000)if __name__ == '__main__':start_time = '2024-03-06 12:20:00'end_time = '2024-03-07 12:20:00'get_jsf(change_time(start_time), change_time(end_time))
cookie = '*****'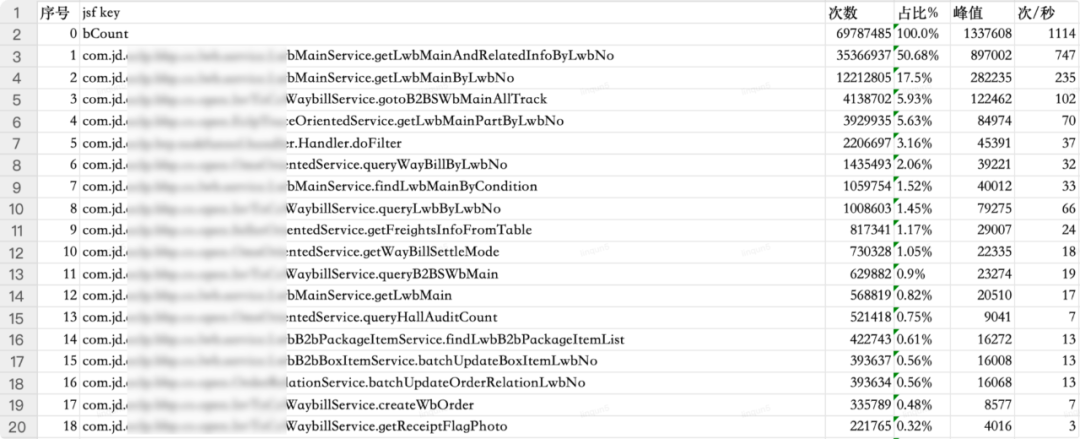
| 接口 | 日调用量 | 占比% | 次/秒 | 涉及到的表 | 是否可以切从库 | 切从库方案 | |
| 0 | 总调用量 | 69787485 | 100.0% | 1114 | |||
| 1 | com.jd.xxx.service.xxx.getlwbmainandrelatedinfobylwbno | 35366937 | 50.68% | 747 | lxxx_main xxx_goods_item extend_info xxx_extend | 是 | 单查询,在service层加注解走从库查询 |
| 2 | com.jd.xxx.service.xxx.getlwbmainbylwbno | 12212805 | 17.5% | 235 | xxx_main xxx_main_ext_coldchain xxx_product_code xxx_extend | 是 | 有很多地方引用这个方法,切从库需要新增api接口,在service新增的方法上加走从库注解 |
| 3 | com.jd.xxx.open.xxx.getlwbmainpartbylwbno | 4138702 | 5.93% | 102 | xxx_main | 是 | 在service层加注解走从库查询 |
| 4 | com.jd.xxx.open.xxx.gotob2bswbmainalltrack | 3929935 | 5.63% | 70 | xxx_main 两次 xxx_main_ext_coldchain | 是 | 在service层加注解走从库查询 |
| 5 | com.jd.xxx.btp.taskfunnel.handler.handler.dofilter | 2206697 | 3.16% | 37 | 否 | 接单框架(实现方法太多) | |
| 6 | com.jd.xxx.service.xxx.findlwbmainbycondition | 1435493 | 2.06% | 32 | xxx_main 列表查询 xxx_item 是否查明细 package_added_service package_added_service_item 取旧服务 xxx_pay_main xxx_extend xxx_product_code xxx_main_ext_coldchain | 是 | 有很多地方引用这个方法,切从库需要新增api接口,在service新增的方法上加走从库注解 |
| 7 | com.jd.xxx.open.omsorientedservice.querywaybillbylwbno | 1059754 | 1.52% | 33 | xxx_main freights_info xxx_enquiry_main xxx_status 两次 xxx_b2b_box_item xxx_coupon 两次 xxx_extend 积分 | 是 | 在service层加注解走从库查询 |
| 8 | com.jd.xxx.open.sellerorientedservice.getfreightsinfofromtable | 1008603 | 1.45% | 66 | xxx_main xxx_b2b_package xxx_extend xxx_product_code xxx_main_ext_coldchain xxx_main_ext_site freights_info fee_detail xxx_b2b_box_item | 是 | 在service层加注解走从库查询 |
| 9 | com.jd.xxx.service.xxx.getlwbmain | 817341 | 1.17% | 24 | xxx_main xxx_b2b_package xxx_extend xxx_product_code xxx_main_ext_coldchain xxx_main_ext_site | 是 | 有很多地方引用这个方法,切从库需要新增api接口,在service新增的方法上加走从库注解 |
| 10 | com.jd.xxx.open.omsorientedservice.getwaybillsettlemode | 730328 | 1.05% | 18 | 无数据库查询 |
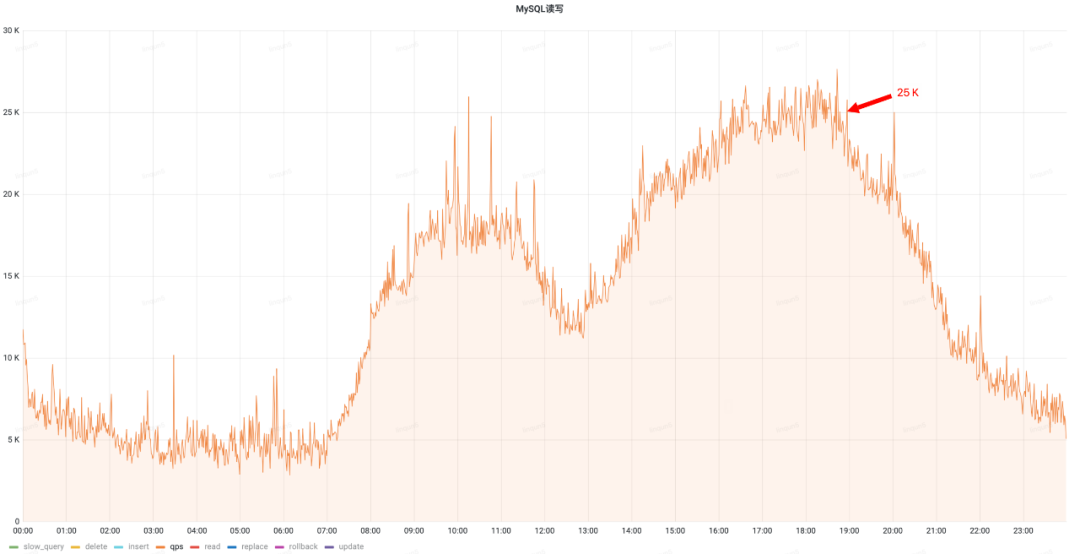 治理前qps(峰值25k)
治理前qps(峰值25k)
 治理后qps(峰值17.5k)
治理后qps(峰值17.5k)






发表评论