介绍
相信前端的小伙伴对谷歌浏览器插件开发并不陌生,或许你会想到,当习得这个技能后最后又能做些什么呢?当然又很多,本期就带大家去实现一个插件,其具体作用就是,你可以在在网页上选择一段文本然后就会自动复制下来,同时,还可以自动完成语音朗读,这样你就可以不用看就可以了解到内容,而且也不用每次按ctrl+c去复制啦~
正文
基础配置
众所周知,开发谷歌浏览器插件前先要去配置一下 manifest.json 文件,它是用于指定扩展插件应用名称、描述、图标、应用文件入口、权限等信息的。
{
"name": "文本拷贝&语音朗读插件",
"description":"在页面选中所需要复制、语音的文本,将会完成自动复制,且会帮你语音说出所选的内容",
"version": "0.1",
"manifest_version": 3,
"background": {
"service_worker": "background.js"
},
"action": {
"default_icon": {
"16": "/assets/favicon-16x16.png",
"48": "/assets/favicon-48x48.png"
}
},
"icons": {
"16": "/assets/favicon-16x16.png",
"48": "/assets/favicon-48x48.png"
},
"permissions": [
"tts",
"clipboardread",
"clipboardwrite"
],
"content_scripts":[{
"js":["page.js"],
"matches":["http://*/*","https://*/*"]
}]
}
这里我们简单说明一下以上配置都做了什么吧:首先我们起好扩展应用的名字和描述。然后定义了版本好,因为目前为纯自娱自乐式的demo,所以给一个v0.1版本吧。
mainfest版本设置为3,所以后面的 action 插件页面展示和 icons 插件图标要分开写在下面,如果mainfest设置为2的话,则需要写 browser_action 来代替 action ,同时,要把 icons 并入其中。mainfest版本2与3细碎的差异其实还是比较多的,具体可以查看官方的文档来再来尝试。
另外,指定background的脚本,因为它是 chrome 插件比较重要的一个部分,也是chrome 插件生命周期最长的一个组件。background 的生命周期在 chrome 启动后,启用的插件会被启动,background.js 就会被执行。我们后面写的功能调用都会经过它之手来发出。
而 content_scripts 顾名思义其目的就是要写入页面将要执行那个脚本文件。在这里我们就给它写一个 page.js 后面我们的业务层面都将从头入手。
当然,最关键的是我们要在 permissions 开启拷贝和语音朗读的权限,然后我们才可以顺畅的使用chrome 提供的api来完成这些功能。其中 tts 表示语音朗读的权限,而后面那俩则是拷贝的读写权限。
好了准备工作都完成了,接下来就开始搞事情~
获取内容
刚才说道我们的目的是选中网页中的文本内容来完成再做拷贝和朗读任务的,那有什么办法能快速获取到这些内容呢?当然有办法,就是用 window.getselection 方法来返回一个 selection 对象,再对这个 selection 里就是你所选中的文本信息了,可以直接使用 tostring 方法来读到。
// page.js
document.addeventlistener("mouseup", e => {
// 获取内容
const txt = window.getselection().tostring()
if(txt == "") return;
// 拷贝文本
document.execcommand('copy')
})
语音朗读
语音朗读我们就要借助 background.js 来完成,所以,我们在 chrome.runtime 先发出一个消息出去。
// page.js
document.addeventlistener("mouseup", e => {
// ...
// 发送语音朗读消息
chrome.runtime.sendmessage({
type: "word",
value: txt,
}, res => {
console.log(res)
})
})
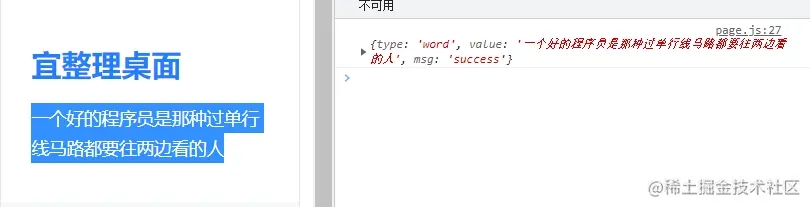
然后在 background.js 中接收到这个消息,在回调函数里就可以用 tts.speak 方法读出我们所选中的内容了,非常的简单。
// background.js
chrome.runtime.onmessage.addlistener((request, sender, sendresponse) => {
chrome.tts.speak(request.value)
sendresponse({
...request,
msg: "success",
})
console.log(chrome.tts)
})
结语
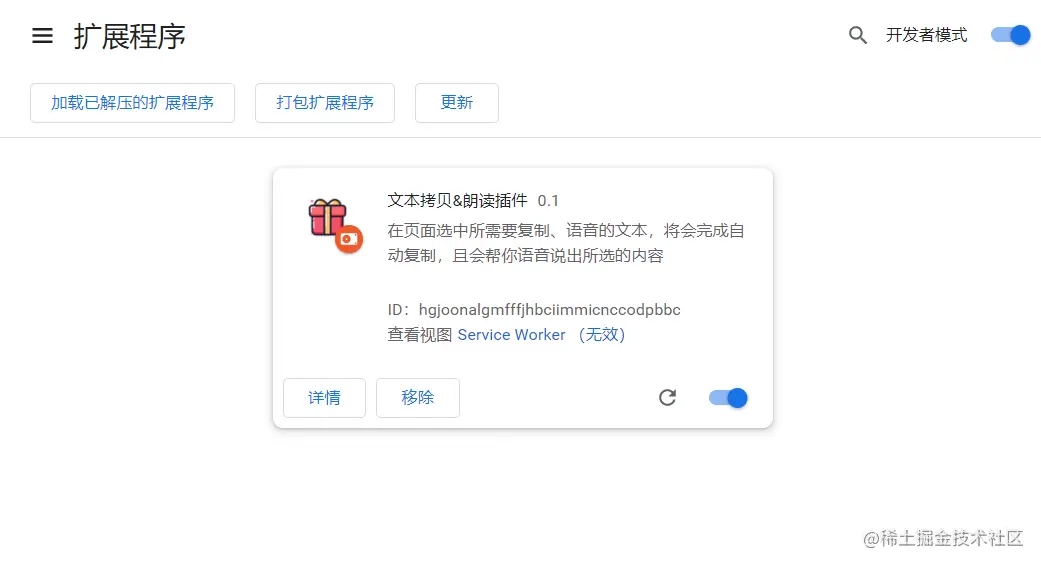
最后你可把刚才的文件夹导入到扩展程序里,一个属于你自己的小工具就完成了,当然本篇也是用一个小案例来抛砖引玉,希望你可以联想到更多的业务需求来做一款真正好用的浏览器插件,还有更多未知好玩的api等你去发现和使用。
以上就是js实现谷歌浏览器插件拷贝语音功能详解的详细内容,更多关于js谷歌浏览器插件拷贝语音的资料请关注代码网其它相关文章!





发表评论