注解bean
我们常用的向spring容器中添加bean的方式主要有三种
- @component注解
- @configuration 加 @bean
- @import
那么spring是如何解析这些注解的,本文具体研究这个问题
parse
spring解析注解bean的代码写在configurationclassparser类的parse方法,参数就是springapplication.run时传入的启动主类
spring启动时会解析我们的主配置类(就是带@springbootapplication的启动类),解析的任务交给解析器configurationclassparser,对应的方法就是parse
configurationclassparser中一个属性configurationclasses,用来存放解析出来的结果
private final map<configurationclass, configurationclass> configurationclasses = new linkedhashmap<>();
对应的get方法
public set<configurationclass> getconfigurationclasses() {
return this.configurationclasses.keyset();
}
processconfigurationclass
parse方法最终会走向processconfigurationclass方法
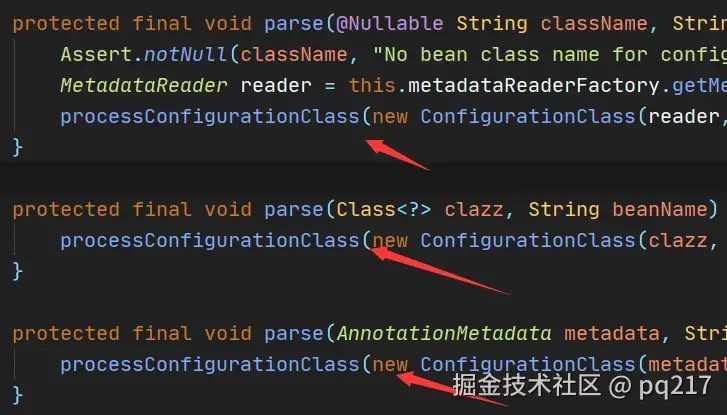
这个方法贴主要代码
do {
sourceclass = doprocessconfigurationclass(configclass, sourceclass, filter);
}
while (sourceclass != null);
调用doprocessconfigurationclass方法,如果有返回值,递归调用doprocessconfigurationclass,看spring的注释说// recursively process the configuration class and its superclass hierarchy.,也就是递归解析配置类和他的父类,所以这代码的意思就是解析配置类,如果有父类再解析父类,如果父类有父类再一直解析下去。 所以重点就来到了doprocessconfigurationclass方法
doprocessconfigurationclass
doprocessconfigurationclass(spring源码中的doxxx一般都很重要),接下来就分析这个代码,贴完整代码
protected final sourceclass doprocessconfigurationclass(
configurationclass configclass, sourceclass sourceclass, predicate<string> filter)
throws ioexception {
if (configclass.getmetadata().isannotated(component.class.getname())) {
// 1.内部类 这一步看看有没有内部类,一般不咋用
processmemberclasses(configclass, sourceclass, filter);
}
// 2.@propertysource 这一步解析@propertysource注解,更改配置文件位置时会使用,一般使用默认位置,不咋更改
for (annotationattributes propertysource : annotationconfigutils.attributesforrepeatable(
sourceclass.getmetadata(), propertysources.class,
org.springframework.context.annotation.propertysource.class)) {
if (this.environment instanceof configurableenvironment) {
processpropertysource(propertysource);
}
else {
logger.info("ignoring @propertysource annotation on [" + sourceclass.getmetadata().getclassname() +
"]. reason: environment must implement configurableenvironment");
}
}
// 3.@componentscan 这一步就很重要了,解析@componentscan注解
set<annotationattributes> componentscans = annotationconfigutils.attributesforrepeatable(
sourceclass.getmetadata(), componentscans.class, componentscan.class);
if (!componentscans.isempty() &&
!this.conditionevaluator.shouldskip(sourceclass.getmetadata(), configurationphase.register_bean)) {
for (annotationattributes componentscan : componentscans) {
// 开始扫描,把@componentscan指定包下的@component类全部扫描出来
set<beandefinitionholder> scannedbeandefinitions =
this.componentscanparser.parse(componentscan, sourceclass.getmetadata().getclassname());
// 把所有扫描到的beanclass递归解析,所以我们也可以加多个@configuration类
for (beandefinitionholder holder : scannedbeandefinitions) {
beandefinition bdcand = holder.getbeandefinition().getoriginatingbeandefinition();
if (bdcand == null) {
bdcand = holder.getbeandefinition();
}
//判断是不是configurationclass 带@configuration注解和@component注解都算
if (configurationclassutils.checkconfigurationclasscandidate(bdcand, this.metadatareaderfactory)) {
// 解析
parse(bdcand.getbeanclassname(), holder.getbeanname());
}
}
}
}
// 4.@import 解析@import注解
processimports(configclass, sourceclass, getimports(sourceclass), filter, true);
// 5.@importresource解析@importresource解析
annotationattributes importresource =
annotationconfigutils.attributesfor(sourceclass.getmetadata(), importresource.class);
if (importresource != null) {
string[] resources = importresource.getstringarray("locations");
class<? extends beandefinitionreader> readerclass = importresource.getclass("reader");
for (string resource : resources) {
string resolvedresource = this.environment.resolverequiredplaceholders(resource);
configclass.addimportedresource(resolvedresource, readerclass);
}
}
// 6.@bean 解析带有@bean注解的方法,加入到configclass的beanmethods属性中
set<methodmetadata> beanmethods = retrievebeanmethodmetadata(sourceclass);
for (methodmetadata methodmetadata : beanmethods) {
configclass.addbeanmethod(new beanmethod(methodmetadata, configclass));
}
// 6.接口@bean 解析实现的接口中带有@bean注解的默认方法,加入到configclass的beanmethods属性中
processinterfaces(configclass, sourceclass);
// 7.父类 如果有父类返回父类,以继续解析
if (sourceclass.getmetadata().hassuperclass()) {
string superclass = sourceclass.getmetadata().getsuperclassname();
if (superclass != null && !superclass.startswith("java") &&
!this.knownsuperclasses.containskey(superclass)) {
this.knownsuperclasses.put(superclass, configclass);
// superclass found, return its annotation metadata and recurse
return sourceclass.getsuperclass();
}
}
// 没有父类,解析结束
return null;
}
整个流程总结如下
- 解析内部类
- 解析@propertysource注解
- 解析@componentscan注解,扫描指定包下的所有@component类,并递归解析
- 解析@import注解
- 解析@importresource注解
- 解析@bean
- 解析实现接口中的@bean
- 返回父类
接下来一个个看
解析内部类
if (configclass.getmetadata().isannotated(component.class.getname())) {
// 1.内部类 这一步看看有没有内部类,一般不咋用
processmemberclasses(configclass, sourceclass, filter);
}
也就是说如果一个类有@component注解,会解析他的内部类如果也有@component会注册成bean,写个代码测试一下
@configuration
@componentscan("com.pqsir.parser")
public class classparserapplication {
public static void main(string[] args) {
applicationcontext context = new annotationconfigapplicationcontext(classparserapplication.class);
nested nested = context.getbean(nested.class);
system.out.println(nested); // com.pqsir.parser.classparserapplication$nested@4e7912d8
}
@component
class nested {
}
}
所以内部类也可以注册到bean容器
解析@propertysource注解
这个真没用过,我觉得配置文件放在规定的地就不错,以后也好找,这个就不研究了
解析@componentscan
这个都懂,就是扫描的包路径,值的注意的是扫描到的class都会递归调用parser 这一步的代码细分析下
扫描包下的类
set<beandefinitionholder> scannedbeandefinitions =
this.componentscanparser.parse(componentscan, sourceclass.getmetadata().getclassname());
这个componentscanparser内部有个scaner(扫描器),扫描@component注解的类(包括子注解@configuration,@service等)
循环判断扫描到的类是否是configurationclass,如果是则递归解析
// 如果是configurationclass
if (configurationclassutils.checkconfigurationclasscandidate(bdcand, this.metadatareaderfactory)) {
// 解析
parse(bdcand.getbeanclassname(), holder.getbeanname());
}
这一步configurationclass不单单是指带@configuration注解的类,带@component注解的也算configurationclass,spring内部有个集合,只要是这个集合里的注解,都算configurationclass
// configurationclassutils
private static final set<string> candidateindicators = new hashset<>(8);
static {
candidateindicators.add(component.class.getname());
candidateindicators.add(componentscan.class.getname());
candidateindicators.add(import.class.getname());
candidateindicators.add(importresource.class.getname());
}
public static boolean isconfigurationcandidate(annotationmetadata metadata) {
// 省略
// 是否有候选注解
for (string indicator : candidateindicators) {
if (metadata.isannotated(indicator)) {
return true;
}
}
// 省略
}
总结**【1】带@configuration或@component类都是configurationclass**
最后做个小测试--主类制定了@componentscan包下又一个带@componentscan的类指向另一个包,那么这两个包下的bean都会被注入,测试一下,我们建两个包parser和parser2 parser2下一个普通bean:beanout
package com.pqsir.parser2;
@component
public class beanout {
@override
public string tostring() {
return "beanout";
}
}
parser下classparserapplication主类扫描parser和 otherconfiguration:在parser包下定义扫描parser2
package com.pqsir.parser
@configuration
@componentscan("com.pqsir.parser") //扫描parser
public class classparserapplication {
public static void main(string[] args) {
applicationcontext context = new annotationconfigapplicationcontext(classparserapplication.class);
beanout bean = context.getbean(beanout.class);
system.out.println(bean); // beanout
}
}
@configuration
@componentscan("com.pqsir.parser2")
public class otherconfiguration {
}
最终正常输出"beanout"
解析@import注解
这个也比较好理解,就是如果某个bean带@import注解,就把@import注解指定的类也注册成bean 测试一下,我们把上一步beanout的@component注解去掉,删除otherconfiguration
@configuration
@componentscan("com.pqsir.parser")
@import({beanout.class})
public class classparserapplication {
public static void main(string[] args) {
applicationcontext context = new annotationconfigapplicationcontext(classparserapplication.class);
beanout bean = context.getbean(beanout.class);
system.out.println(bean); // beanout
}
}
结果也可以正常输出 这个@import的最大好处可以把一些第三方的类给注入到bean容器,因为第三方的类一般也改不了总不能去加@component注解吧,而且如果你是一个第三方开发者,肯定不希望一直的工具依赖spring(万一哪天没人用了你的工具也废了),所以通过@import把你的工具引入spring是一个完美的解决方案。 还有个比较大的好处是可以做封装,@import注解可以被继承,比如我们写个自定义注解继承了@import,并指定import的类,就可以把这个类注册到bean容器中,甚至可以让这个类继承一些后置处理器来给bean容器做调整,比如aop的@enableaspectjautoproxy就是用到这一点,还有mybaits的也是用@mapperscan也是使用import的方式完成一些mapper bean的生成工作 上例是@configuration+@import,用@component+@import也ok,因为【1】
解析@importresource注解
主要为了兼容之前的xml写法
解析@bean
@bean注解一般经常使用,使用工厂方法创建一个bean,一般就是@configuration+@bean,由于上述原因【1】,所以@component+@bean也可以。
解析实现接口中的@bean
这是对@bean注解的一个扩展,解析实现的接口中带有@bean注解的默认方法,写个例子测试一下
接口(包含默认方法带@bean注解,本身不带任何注解)
public interface ibeana {
@bean
default beanout beanout() {
return new beanout();
}
}
实现(带@component注解)
@component
//@import({beanout.class})
public class beana implements ibeana {
}
测试类
@configuration
@componentscan("com.pqsir.parser")
public class classparserapplication {
public static void main(string[] args) {
applicationcontext context = new annotationconfigapplicationcontext(classparserapplication.class);
beanout bean = context.getbean(beanout.class);
system.out.println(bean); // beanout
}
}
也会正常输出,这个真没想到什么使用场景,遇到再说吧
返回父类
最后一步如果返回父类继续递归解析,测试一下
父类(没有@component注解)
public class beanfather {
@override
public string tostring() {
return "beanfather";
}
}
子类(有@component注解)
@component
public class beanson extends beanfather{
}
测试类(尝试获取父类bean)
@configuration
@componentscan("com.pqsir.parser")
public class classparserapplication {
public static void main(string[] args) {
applicationcontext context = new annotationconfigapplicationcontext(classparserapplication.class);
beanfather bean = context.getbean(beanfather.class);
system.out.println(bean); // beanfather
}
}
正常可获取
最后
完成这一系列的解析扫描再解析过程,就可以通过getconfigurationclasses拿到所有扫描并解析到的类。 spring拿到这些类之后再通过一个reader把configurationclasse转换为bean定义,注册到beanfactory,所以parser+reader,就完成了这些bean的扫描&解析&注册工作,代码在configurationclasspostprocessor中。
public void processconfigbeandefinitions(beandefinitionregistry registry) {
// 创建一个解析器
configurationclassparser parser = new configurationclassparser(
this.metadatareaderfactory, this.problemreporter, this.environment,
this.resourceloader, this.componentscanbeannamegenerator, registry);
// 开始解析,这个candidates就是我们传入的mainapplication
parser.parse(candidates);
// 获取解析到的类
set<configurationclass> configclasses = new linkedhashset<>(parser.getconfigurationclasses());
// 初始化一个reader
this.reader = new configurationclassbeandefinitionreader(
registry, this.sourceextractor, this.resourceloader, this.environment,
this.importbeannamegenerator, parser.getimportregistry());
// 把上面解析到的类转化为bean定义并注册到bean定义注册器(registry)
this.reader.loadbeandefinitions(configclasses);
}
扩展
@configuration和@component的区别
上文很多@configuration的注解都可以用@component代替,甚至主类使用@component来替换@configuration也能正常跑,那问题来了,他俩就没有区别吗,那要@configuration有啥用。 却别主要两方面 一.首先,@configuration和@service,@controller注解很像,都继承@component注解,没有实际的什么作用只是告诉别人这个类是个配置类型的bean 二.其次,也是实际功能上的区别,使用@configuration类+@bean,sping会生成一个cglib动态代理,这个代理的工能就是第一次调用@bean的方法会直接执行并返回结果,同时存储结果,下一次调用同样方法直接返回结果,这样可以保证单例,不管调用多少次@bean的方法最终得到的结果是同一个对象,而使用@component则不会
做个测试
通过@bean注册三个bean a b c,其中bc依赖注入a,先使用@configuration
@configuration
public class beanconfiguration {
@bean
public a a() {
return new a();
}
@bean
public b b() {
b b = new b();
b.a = a();
return b;
}
@bean
public c c() {
c c = new c();
c.a = a();
return c;
}
static class a {
}
static class b {
public a a;
}
static class c {
public a a;
}
}
试一下
applicationcontext context = new annotationconfigapplicationcontext(classparserapplication.class); beanconfiguration.b b = context.getbean(beanconfiguration.b.class); beanconfiguration.c c = context.getbean(beanconfiguration.c.class); system.out.println(b.a.equals(c.a));
输出结果是true 如果把@configuration改成@component,输出结果就变成false了,这个代理的代码configurationclasspostprocessor.enhanceconfigurationclasses中,有兴趣的自己研究吧 其实这种写法本来就不太好,还是觉得用依赖注入更好,如下
@configuration
public class beanconfiguration {
@bean
public a a() {
return new a();
}
@bean
public b b(a a) {
b b = new b();
b.a = a;
return b;
}
@bean
public c c(a a) {
c c = new c();
c.a = a;
return c;
}
static class a {
}
static class b {
public a a;
}
static class c {
public a a;
}
}
这种写法就算改成@component也没问题
@import+importbeandefinitionregistrar
上面说了@import可以导入bean,一个或多个bean,但如果比如把一个包下的所有类都注入到bean,它就不能实现了,除非你一个一个写,但是这样新增一个就得写一个。 这种需求其实很常见,比如mybaits的@mapperscan,他需要你指定一个mapper的位置,然后把mapper全部注入到bean容器,不管你加多少mapper都会注入进去。 spring批量注册bean是有个后置处理器支持的,就是beandefinitionregistrypostprocessor,如果你某个bean实现了beandefinitionregistrypostprocessor,就会拿到bean定义注册器beandefinitionregistry,然后爱怎么注册bean定义、注册多少随你。 所以我最开始遇到这种需求解决思路是@import+beandefinitionregistrypostprocessor,虽然可行,但获取不到注解的属性,比如@mapperscan的value
所以spring要引入importbeandefinitionregistrar这个接口,其中重要方法
default void registerbeandefinitions(annotationmetadata importingclassmetadata, beandefinitionregistry registry) {
}
通过实现这个方法也能拿到beandefinitionregistry(configurationclasspostprocessor本身继承beandefinitionregistrypostprocessor,所以可以拿到),然后可以按照自己的意思注册bean定义,更重要的:通过第一个参数importingclassmetadata可以获取使用@import注解的类的元数据,就可以获取到外层注解的属性值 那么问题来了,什么时候执行呐。 刚才"最后"章节的代码有一句this.reader.loadbeandefinitions(configclasses);,就是在这个时候继承这个接口的类(被@import引入)执行registerbeandefinitions方法

可以自己去找代码,整个过程再configurationclasspostprocessor执行的生命周期执行完毕
到此这篇关于spring扫描解析bean的方法详解的文章就介绍到这了,更多相关spring解析bean内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论