日志常用于输出到控制台或指定文件,帮助我们记录用户行为以及排查bug
最早接触的就是system.out.println将内容输出到控制台,也导致经常在后续开发中可能顺手就写了sout来记录。
这种方式虽然简单,但在真实项目中远远不够。正式开发里,我们更推荐使用标准的日志框架,比如 slf4j + logback 或 slf4j + log4j2。
一、为什么不能只用 system.out.println
system.out.println() 的优点只有一个:简单,写了就能看到输出。
但它的问题也很明显:
- 没有日志级别,无法区分普通信息、警告、错误
- 无法统一格式,排查问题时信息杂乱
- 不方便输出到文件、日志平台、监控系统
- 不能按环境灵活控制输出
- 高并发、生产环境下几乎不适合作为正式日志手段
例如:
system.out.println("用户登录成功:" + userid);这句代码只是把一行文字打印到控制台,既没有时间、线程、类名,也无法统一收集。
而日志框架的写法通常是:
log.info("用户登录成功, userid={}", userid);它的价值在于:
- 有明确的日志级别
- 支持格式化输出
- 能输出到控制台、文件或日志系统
- 可以按配置决定哪些日志要打印、哪些不打印
- 更适合线上运维和问题排查
所以,sout 更像临时调试工具,log.info() 才是项目开发中的标准做法。
二、java 常见日志框架
java 日志体系里,经常会看到好几个名字,初学者容易混淆。可以把它们分成三类来看。
1. 日志门面
日志门面本身不负责真正输出日志,它只负责“定义统一接口”,让业务代码不直接依赖某个具体实现。
常见门面:
- slf4j
- jcl(jakarta commons logging,较老)
目前主流项目中最常见的是 slf4j。
它的好处是:代码里统一写 log.info()、log.error(),底层到底用 logback 还是 log4j2,可以后续替换,不影响业务代码。
2. 日志实现
日志实现才是真正把日志打印出来、写到文件里的组件。
常见实现:
- logback
- log4j2
- java.util.logging
其中:
- logback:spring boot 默认常用实现,配置方便,生态成熟
- log4j2:性能好、功能强,企业项目也很常见
- java.util.logging:jdk 自带,但实际项目中使用相对少
3. 历史框架
- log4j 1.x:老版本,现在一般不推荐新项目使用
- system.out.println():只能算打印,不算真正意义上的日志框架
三、主流推荐方案
在现在的 java 项目中,推荐组合一般是:
- slf4j + logback
- slf4j + log4j2
如果是 spring boot 项目,默认通常就是 slf4j + logback,上手成本最低,适合大多数场景。
可以记一个简单结论:
开发中优先面向 slf4j 编码,具体实现选 logback 或 log4j2。
四、日志级别怎么理解
日志框架通常提供多个级别,用于表示信息的重要程度。常见级别从低到高如下:
- trace
- debug
- info
- warn
- error
下面逐个理解。
1. trace
最细粒度的跟踪信息,一般用于非常详细的程序执行过程。
log.trace("进入方法 checkpermission, userid={}", userid);平时业务开发中很少开。
2. debug
用于开发调试,记录一些关键变量、执行路径、参数信息。
log.debug("查询条件: userid={}, status={}", userid, status);开发环境常用,生产环境通常关闭或谨慎开启。
3. info
记录正常业务流程中的关键信息,是项目里最常用的级别之一。
log.info("订单创建成功, orderid={}, userid={}", orderid, userid);比如:
- 服务启动成功
- 用户登录成功
- 订单创建成功
- 定时任务开始/结束
4. warn
表示程序出现异常情况或风险,但还没有导致功能彻底失败。
log.warn("库存不足, skuid={}, remain={}", skuid, remain);比如:
- 参数不规范但系统做了兼容
- 某个远程调用超时后触发重试
- 检测到配置缺失但系统使用默认值继续运行
5. error
表示发生了明确错误,通常需要重点关注。
log.error("支付失败, orderid={}", orderid, e);比如:
- 数据库操作失败
- 接口调用异常
- 程序捕获到未预期异常
五、日志的基本使用方式
下面用常见的 slf4j 风格说明日志怎么写。
1. 定义日志对象
传统写法:
public class userservice {
private static final logger log =
loggerfactory.getlogger(userservice.class);
}如果项目使用 lombok,也可以简化为:
@slf4j
public class userservice {
}然后直接使用:
log.info("日志打印");2. 参数化输出,不要字符串拼接
推荐写法:
log.info("用户登录成功, userid={}", userid);不推荐:
log.info("用户登录成功, userid=" + userid);原因:
- 代码更整洁
- 日志框架会更高效地处理参数
- 可读性更好
多个参数时:
log.info("订单创建成功, orderid={}, userid={}, amount={}", orderid, userid, amount);3. 异常日志要带堆栈
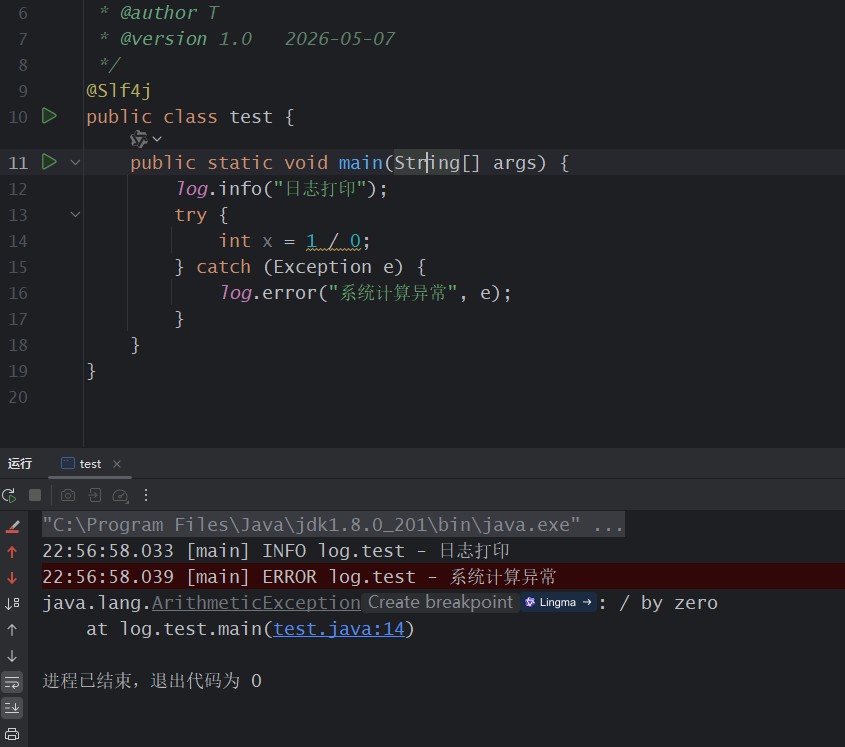
正确写法:
@slf4j
public class test {
public static void main(string[] args) {
log.info("日志打印");
try {
int x = 1 / 0;
} catch (exception e) {
log.error("系统计算异常", e);
}
}
}
或者带业务上下文:
log.error("订单支付异常, orderid={}, userid={}", orderid, userid, e);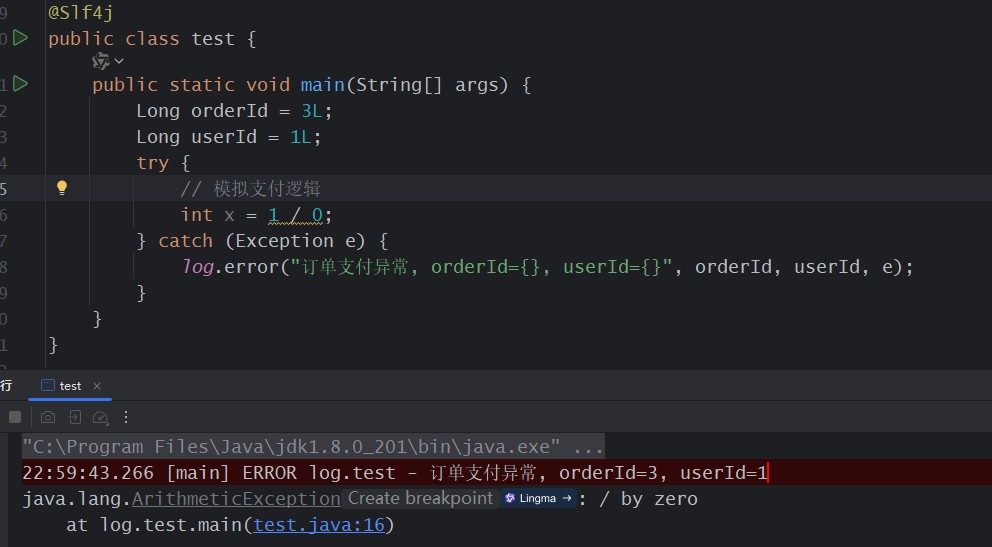
不推荐只打印异常信息:
log.error("订单支付异常, orderid={}, userid={}", orderid, userid);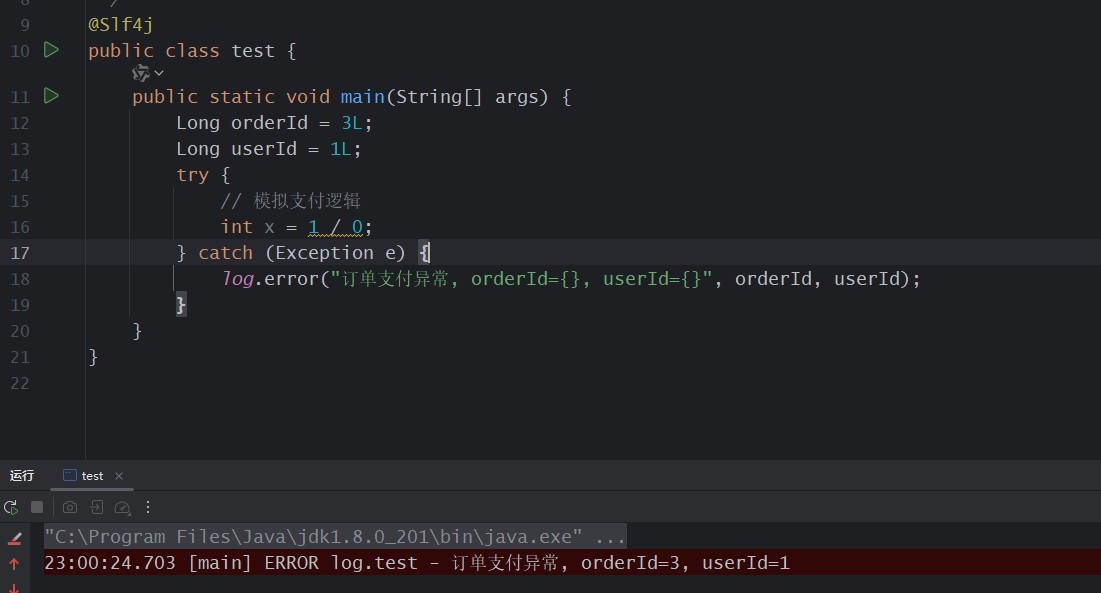
因为这样会丢失完整堆栈,不利于定位问题。
六、spring boot 中的日志使用
spring boot 默认对日志支持比较友好,一般引入 web 依赖后就已经带了日志能力。
业务代码里通常直接这样写:
@slf4j
@service
public class orderservice {
public void createorder(long userid) {
log.info("开始创建订单, userid={}", userid);
log.info("订单创建成功, userid={}", userid);
}
}配置日志级别也比较方便,例如在 application.yml 中:
logging:
level:
root: info # 全局默认日志级别
com.example.demo: debug # 你项目包的日志级别表示:
- 全局日志级别是 info
- com.example.demo 包下允许输出 debug 级别日志
七、日志记录规范
下面是比较实用的一套日志规范。
1. 日志要有价值,避免“流水账”
不要什么都记,也不要一句话完全没有信息量。
不推荐:
log.info("进入方法");
log.info("执行结束");这种日志看起来很多,但对排查问题帮助有限。
推荐:
log.info("开始处理退款申请, refundid={}, orderid={}", refundid, orderid);
log.info("退款处理完成, refundid={}, status={}", refundid, status);要尽量带上业务上下文,让日志能回答:
- 是谁触发的
- 处理了什么对象
- 结果是什么
- 出错时影响了哪个业务数据
2. 关键业务日志必须带唯一标识
例如:
- userid
- orderid
- requestid
- traceid
- taskid
示例:
log.info("订单支付成功, orderid={}, userid={}", orderid, userid);这样才能通过一个 id 把整条调用链串起来。
3. 不要打印敏感信息
日志中严禁直接记录:
- 密码
- 身份证号完整信息
- 银行卡完整号码
- 手机号完整号码
- token、密钥、验证码
- 用户隐私数据
例如下面这种就不合适:
log.info("用户登录, username={}, password={}", username, password);正确做法是脱敏或不打印:
log.info("用户登录, username={}", username);如果必须记录手机号,也要脱敏处理。
4. info 记录业务节点,debug 记录调试细节
很多项目的日志问题不是“太少”,而是“太乱”。最常见错误是把大量细节都打成 info,导致生产日志噪声很大。
可以这样理解:
- info:记录关键业务事件
- debug:记录开发调试信息
- error:记录失败和异常
例如:
log.info("开始支付流程, orderid={}", orderid);
log.debug("支付请求参数: {}", request);
log.info("支付完成, orderid={}, response={}, userid={}, orderid, response, userid);5. 不要重复记录同一个异常
一个异常如果层层捕获、层层 log.error(),最后日志里就会出现多份重复堆栈,反而干扰排查。
常见原则:
- 能处理就处理,不一定要打 error
- 不能处理再往上抛
- 最终由边界层统一记录一次完整异常
例如在 service 里:
catch (exception e) {
throw new businessexception("支付失败", e);
}在 controller 或全局异常处理中统一打印:
log.error("请求处理失败, requestid={}", requestid, e);这样更清晰。
6. 日志内容要统一、可检索
建议统一格式,避免同一种业务场景每个人写法都不一样。
例如统一风格:
log.info("订单创建成功, orderid={}, userid={}, amount={}", orderid, userid, amount);统一风格的好处是:
- 搜索方便
- 排查高效
- 团队协作成本低
7. 重要操作必须记日志
下面这些场景通常建议记录日志:
- 用户登录、登出
- 创建订单、支付、退款
- 定时任务执行
- 第三方接口调用结果
- 权限校验失败
- 数据导入导出
- 配置加载、服务启动与停止
- 关键异常和兜底逻辑
8. 高频循环里谨慎打日志
如果在循环中大量打印日志,可能导致:
- 日志量暴增
- 磁盘占用过快
- io 压力变大
- 排查时淹没关键信息
例如:
for (user user : userlist) {
log.info("处理用户: {}", user.getid());
}如果数据量很大,这种写法就要非常谨慎。
更好的方式可能是汇总记录:
log.info("开始批量处理用户, size={}", userlist.size());处理结束后再输出结果摘要。
八、一个简单的日志示例
下面给一个比较符合规范的 service 示例:
@slf4j
@service
public class orderservice {
public void pay(long orderid, long userid) {
log.info("开始支付订单, orderid={}, userid={}", orderid, userid);
try {
// 1. 参数校验
log.debug("校验订单状态, orderid={}", orderid);
// 2. 执行支付逻辑
log.debug("调用支付网关, orderid={}", orderid);
// 3. 支付成功
log.info("订单支付成功, orderid={}, userid={}", orderid, userid);
} catch (exception e) {
log.error("订单支付失败, orderid={}, userid={}", orderid, userid, e);
throw e;
}
}
}这个例子体现了几个点:
- info 记录关键业务节点
- debug 记录内部处理细节
- error 记录失败并保留异常堆栈
- 日志中带了 orderid 和 userid 这样的关键上下文
九、实际开发中的常见误区
1. 把 system.out.println() 当正式日志用
这是最常见的初级问题。临时调试可以,但不能作为项目正式方案。
2. 所有日志都打 info
这会让生产日志变得非常吵,真正重要的信息反而不明显。
3. 只打印“异常了”,不打印上下文
例如:
log.error("支付失败");这太模糊了。至少要带上订单号、用户 id 等关键信息。
4. 只打印 e.getmessage(),不打印堆栈
这样往往无法定位代码具体在哪一行出错。
5. 打印敏感数据
这是日志安全的大忌。
6. 每层都打印同一个异常
会导致重复日志,影响排查效率。
十、总结
java 日志框架的核心价值,不只是“输出内容”,而是帮助我们在开发、测试、上线、运维整个生命周期里快速理解系统发生了什么。
从实践角度来说,可以记住这几个结论:
- 正式项目不要依赖 system.out.println(),而要使用日志框架。
- 推荐面向 slf4j 编码,底层常用 logback 或 log4j2。
- 合理区分 debug、info、warn、error。
- 日志要带关键业务上下文,比如 userid、orderid、traceid。
- 异常日志要保留完整堆栈,不要只打印一句错误信息。
- 严禁记录密码、密钥、身份证号等敏感数据。
- 日志要服务于排查问题,而不是机械地“打印几行字”。
到此这篇关于java日志框架和使用、日志记录规范的文章就介绍到这了,更多相关java日志框架使用内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论