mysql中关键字段的执行顺序
一句话概括mysql数据库中的select查询语句各个子句的执行顺序:
from >> (xxx join) >> where > group by >> 聚合 >>having >> select>> order by >> limit ,union关键字的执行顺序是不定的,需要具体情况具体分析;
一个丰满的sql举例
查询语句都是从from开始执行的,每个步骤都会为下一个步骤生成一个虚拟表:
(9) select (10) distinct <select_list>
(1) from <left_table> <right_table>
(3) <join_type> join <right_table>
(2) on <join_condition>
(4).......join thirdtable on ......
(5) where <where_condition>
(6) group by <group_by_list>
(7) with {cube|rollup}
(8) having <having_condition>
(11) order by <order_by_list>
(12) limit <limit_number>
上述的sql的查询过程
1:from执行from子句,前两个表执行第一个笛卡尔乘积,此时生成第一个虚拟表
什么是笛卡儿积?
当两张表进行连接查询,没有任何条件限制的时候,最终查询结果条数,是两张表条数的乘积,这种现象被称为:笛卡尔积现象
2:上述形成的虚拟表各行基于on表达式进行筛选,留下符合的生成新的虚拟表
3:将在第二步中形成的虚拟表按照left或者right或者outer关键字,这样生成新的虚拟表
具体过程是这样的
left join把左表记为基础保留表,缺失的数据使用外部行的方式向虚拟表中进行插入,右表部分为null,形成新的虚拟表
right join把右表记为基础保留表,缺失的数据使用外部行的方式向虚拟表中进行插入,左表部分为null,形成新的虚拟表
4:超过两表关联的情况下,上述新生成的虚拟表和第三个表计算笛卡尔乘积,生成虚拟表,重复1-3的步骤,最终得到一个新的虚拟表
5:应用where筛选器,对上一步生产的虚拟表引用where筛选器,进行最终的数据过滤,生成新的虚拟表;
6:group by后边列中值一样的归为一组组合成为一组,得到新的虚拟表
7:应用cube或者rollup选项,生成超组,执行分组之后的聚合函数,生成新的虚拟表
在这里就不难理解,为什么不能使用计算表达式或者别名进行分组,因为
8:having筛选已分组数据,生成新的虚拟表
9:处理select子句,保留select后边定义的列,生成新的虚拟表
10:应用distinct子句,移除相同的行,生成新的虚拟表。
事实上如果应用了group by子句那么distinct是多余的,原因同样在于,分组的时候是将列中唯一的值分成一组,同时只为每一组返回一行记录,那么所以的记录都将是不相同的;
11:应用order by子句,此时返回的一个游标,而不是虚拟表。
正因为返回值是游标,那么使用order by 子句查询不能应用于表表达式,排序是很需要成本的,除非你必须要排序,否则最好不要指定order by,在这一步中是第一个也是唯一一个可以使用select列表中别名的步骤。
12: limit筛选返回的数据条数
对于包含outer join子句的查询,到底在on筛选器还是用where筛选器指定逻辑表达式呢?
on和where的最大区别在于,如果在on应用逻辑表达式那么在第三步outer join中还可以把移除的行再次添加回来,而where的移除的最终的;
group函数的作用?
如果应用了group by,那么后面的所有步骤都只能得到的某一列的第一行的值,或者是聚合函数(count、sum、avg等)
原因在于最终的结果集中只为每个组包含一行。这一点请牢记,如果某一行没有使用聚集函数,默认返回第一行
是先执行group by还是先执行select
通过上面的sql顺序执行可知,先进行group by 在进行select
为什么group by和select同时使用时,select中的字段必须出现在group by后或者聚合函数中。
如何实现数据去重
在sql中可以通过关键字distinct去重,也可以通过group by分组实现去重,但实际上,如果数据量很大的话,使用distinct去重的效率会很慢,使用group by去重的效率会更高,而且,很多distinct关键字在很多数据库中只支持对某个字段去重,无法实现对多个字段去重,如postgresql数据库。(测试数据300w+,使用distinct去重需要十几秒,使用group by去重只需要几秒)。
应用having过滤中可以使用聚合函数或者计算表达式或者别名进行过滤吗?
执行having的时候,已经执行过第六步的group by以及第七步的的聚合函数和计算表达式的以及别名。所以having过滤中可以使用聚合函数或者计算表达式或者别名进行过滤吗
select * from customers c left join orders o on c.customer_id = o.customer_id where c.city='hangzhou' group by c.customer_id having count(o.order_id) < 2;
哪些column要放到group by后边呢?
这是一个表
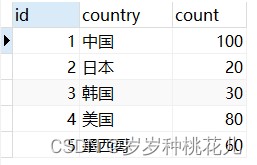
select country ccc,max(count),concat(country,max(count)) bbb,1,concat(country,count) from coutry group by ccc,concat(country,count)
我们在select后边可以选择的列包括:自然列,单纯聚合函数、计算表达式(不含聚合函数)、常量、计算表达式(聚合函数)
其中:
- group by后边可放可不放:常量
- group by必须放:自然列、计算表达式(不含聚合函数)
- group by不允许放:聚合函数、计算表达式(包含聚合函数)
注意:
单纯使用case when的话,属于计算表达式(不带聚合函数)如果使用group by的话,我们是必须和自然列一样把他放到group by后边的。
留一个问题:为什么select在order by之前,但是order by可以使用select后并不存在的列进行排序呢?
总结
到此这篇关于mysql中select语句执行顺序的文章就介绍到这了,更多相关mysql select语句执行顺序内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论