引言
开发程序debug的时候,看到了pdf有个trailer数据,挺有意思,于是考虑用代码把它读出来,那么就用到我们常用的itext框架了。
实际上,使用 itext 获取 pdf 的 trailer 数据是一个稍微底层一些的操作,但完全可以实现。trailer 是 pdf 文件结构的核心部分,它告诉解析器如何找到文件的关键部分,比如交叉引用表 (xref)、文档信息字典 (/info) 和文档根对象 (/root)。
在 itext 中,这个操作被很好地封装了。本文将详细说明能从 trailer 中获得什么信息。
itext 核心概念
- 高级抽象 vs. 底层访问: itext 提供了高级的类,如
pdfdocumentinfo和pdfcatalog,来方便地访问trailer指向的内容。例如,pdfdocument.getdocumentinfo()会自动找到trailer中的/info条目并解析它。 - 直接访问: 同时,itext 也允许你直接获取
trailer本身,它是一个pdfdictionary对象。这对于需要检查非标准字段或进行底层分析的程序员来说非常有用。
c# 代码示例
这个示例将演示如何打开一个 pdf 文件,并同时使用高级方法和底层方法来检查 trailer 相关的数据。
步骤 1: 确保已安装 itext
请在你的项目中通过 nuget 包管理器安装 itext。
install-package itext
步骤 2: c# 代码
using system;
using system.io;
using itext.kernel.pdf;
public class pdftrailerinspector
{
public static void inspectpdftrailer(string filepath)
{
if (!file.exists(filepath))
{
console.writeline($"错误:文件不存在 '{filepath}'");
return;
}
try
{
// 使用 pdfreader 和 pdfdocument 打开 pdf 文件
using (var pdfreader = new pdfreader(filepath))
using (var pdfdocument = new pdfdocument(pdfreader))
{
console.writeline($"--- 正在分析文件: {path.getfilename(filepath)} ---");
// --- 方法 1: 使用高级 api 访问 trailer 指向的内容 (推荐的常规做法) ---
console.writeline("\n=== 通过高级 api 获取 trailer 指向的信息 ===");
// getdocumentinfo() 会读取 trailer 的 /info 字典
pdfdocumentinfo docinfo = pdfdocument.getdocumentinfo();
console.writeline($"信息字典 (来自 /info): creator = {docinfo.getcreator()}, producer = {docinfo.getproducer()}");
// getcatalog() 会读取 trailer 的 /root 字典,这是文档的入口点
pdfcatalog catalog = pdfdocument.getcatalog();
console.writeline($"文档目录 (来自 /root): 页面模式 = {catalog.getpagemode()}, 页面布局 = {catalog.getpagelayout()}");
// --- 方法 2: 直接访问和遍历 trailer 字典本身 (底层操作) ---
console.writeline("\n=== 直接访问 trailer 字典的原始键值对 ===");
// 使用 gettrailer() 直接获取 trailer 字典对象
pdfdictionary trailer = pdfdocument.gettrailer();
if (trailer != null)
{
// 遍历 trailer 字典中的所有条目
foreach (var key in trailer.keyset())
{
pdfobject value = trailer.get(key); // 值 (可能是数字、引用等)
console.writeline($"键: {key}, 值: {value}, 值的类型: {value.gettype().name}");
}
// 你也可以直接获取特定的键
console.writeline("\n--- 单独获取 trailer 中的关键值 ---");
pdfobject size = trailer.get(pdfname.size);
pdfobject root = trailer.get(pdfname.root);
pdfobject info = trailer.get(pdfname.info);
pdfobject id = trailer.get(pdfname.id);
console.writeline($"大小 (size): {size}");
console.writeline($"根对象引用 (root): {root}");
console.writeline($"信息字典引用 (info): {info}");
console.writeline($"文件id (id): {id}");
}
else
{
console.writeline("无法获取 trailer 字典。");
}
}
}
catch (exception ex)
{
console.writeline($"读取 pdf 时发生错误: {ex.message}");
}
}
public static void main(string[] args)
{
// 请将 "c:\\path\\to\\your\\document.pdf" 替换为你的 pdf 文件路径
string pdfpath = "c:\\path\\to\\your\\document.pdf";
inspectpdftrailer(pdfpath);
}
}
程序运行效果
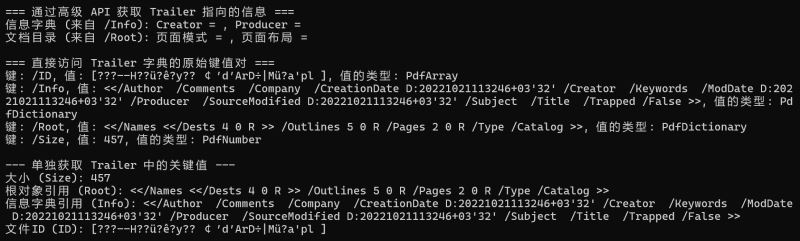
解读 trailer 的输出
当你运行上面的代码并查看“直接访问 trailer 字典”部分的输出时,你会看到类似下面的内容:
键: /size, 值: 25, 值的类型: pdfnumber 键: /root, 值: 23 0 r, 值的类型: pdfindirectreference 键: /info, 值: 1 0 r, 值的类型: pdfindirectreference 键: /id, 值: [<0ddb5968...>, <f3c3b2a6...>], 值的类型: pdfarray
这里是对这些关键条目的解释:
/size: (类型:pdfnumber) 表示 pdf 文件中对象的总数(大约值)。/root: (类型:pdfindirectreference) 这是一个间接引用,指向文档的根对象(catalog字典)。23 0 r的意思是“第 23 号对象,第 0 代”。itext 使用这个引用来找到文档的所有页面和其他核心内容。pdfdocument.getcatalog()就是帮你完成了这个查找过程。/info: (类型:pdfindirectreference) 同样是一个间接引用,指向文档的信息字典(包含作者、标题等元数据)。1 0 r指向第 1 号对象。pdfdocument.getdocumentinfo()会自动解析这个引用。/id: (类型:pdfarray) 这是一个包含两个字符串的数组,用于唯一标识该 pdf 文件。第一个字符串在文件创建时生成,并且永不改变。第二个字符串在每次保存文件时都会更新。这对于追踪文件的版本非常有用。/prev(可选): 如果文件是增量更新的,这个键会指向前一个版本的交叉引用表的位置。/encrypt(可选): 如果文件被加密,这个键会指向加密字典。
总结
- 常规需求: 如果我们只是想获取作者、标题、页面内容等信息,使用 itext 的高级 api(
getdocumentinfo(),getcatalog(),getpage()等)就足够了,它们在后台为你处理了trailer的解析。 - 底层分析: 如果你需要检查
trailer的所有原始条目,或者查找可能存在的非标准字段,或者想验证 pdf 结构,那么使用pdfdocument.gettrailer()是最直接和强大的方法。
上面的代码提供了两种,我们可以根据具体需求选择使用。
到此这篇关于c#使用itext获取pdf的trailer数据的代码示例的文章就介绍到这了,更多相关c# itext获取pdf的trailer数据内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论