1、背景
我们往一张表里插入的行数据是存储在页上的,一张页的大小为16kb,数据量大的时候一张页不可能存储完一张表里的所有数据,所以需要多张页来进行存储,这多张页所在的存储空间就叫表空间,表空间分为系统表空间和独立表空间,接下来就讲一下独立表空间上是如何存储页的。
2、独立表空间
【1】表空间大小
之前讲过页的组成,我们再来看一下页的通用部分file header(38字节大小)的组成:
| 名称 | 字节大小 | 含义 |
|---|---|---|
| fil_page_space_or_chksum | 4 | 页的校验和 |
| fil_page_offset | 4 | 页号 |
| fil_page_prev | 4 | 上一页 |
| fil_page_next | 4 | 下一页 |
| fil_page_lsn | 8 | 页最后被修改时对应的日志序列位置 |
| fil_page_type | 2 | 页类型 |
| fil_page_file_flush_lsn | 8 | 仅在系统表空间的一个页中定义,代表文件执行被刷新到了对应的lsn值 |
| fil_page_arch_log_no_or_space_id | 4 | 页属于哪个表空间 |
file header里的页号由4字节组成,也就是32位,所以一个表空间最多能存储232个页,每个页按照16kb的大小来算,一个表空间最多可以存储64tb的大小的数据
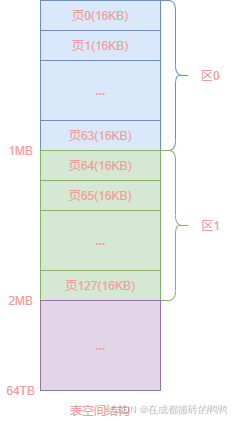
【2】区
表空间里每连续64个页组成一个区,一个页按16kb大小来算,一个区的大小就为64*16kb=1mb,如下图表示:
【3】组
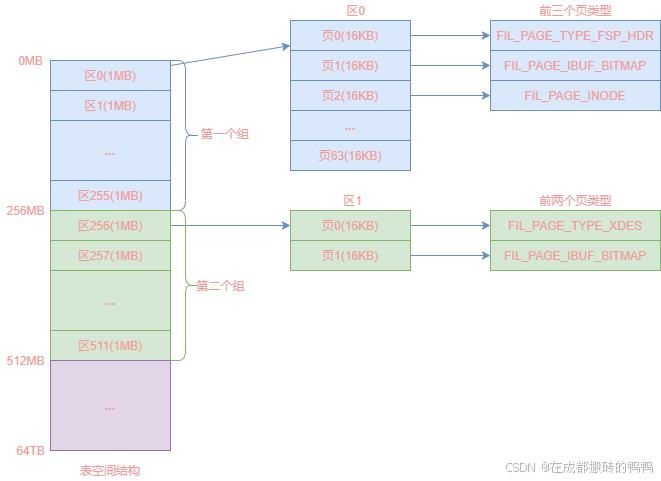
表空间上连续256个区就为一个组,区0到区255就为第一个组,区256到区511就为第二个组,剩下的以此内推,需要注意的是,第一个组的前三个页的类型是固定,其它组的前两个页类型是固定的,在讲这些页之前我们先看一下页的类型有几种:
| 类型 | 含义 |
|---|---|
| fil_page_undo_log | undo日志页 |
| fil_page_inode | 段信息节点 |
| fil_page_ibuf_free_list | insert buffer空闲列表 |
| fil_page_ibuf_bitmap | insert buffer位图 |
| fil_page_type_sys | 系统页 |
| fil_page_type_trx_sys | 事务系统数据 |
| fil_page_type_fsp_hdr | 表空间头部信息 |
| fil_page_type_xdes | 扩展描述页 |
| fil_page_type_blob | blob页 |
再看组的表结构图,如下图:
【4】段
一个索引有叶子节点和非叶子节点,存放叶子节点所在区的集合就叫叶子段,存放非叶子节点所在区的集合就叫非叶子段,一个索引有两个段。
【5】区的类型
段就是索引中叶子节点和非叶子节点所在区的集合,一个索引两个段,一个区64个页,数据量小的时候用一个区来作为存储单位十分浪费空间,所以就有了碎片区的概念,在数据量小的时候段就以碎片区中的页为单位来分配空间,数据量大的时候就以区为单位来分配存储空间,碎片区不属于任何段,并且碎片区里的页可以存储多个索引的数据,区的类型有如下几种:
| 区类型 | 含义 |
|---|---|
| free | 属于表空间,区中的页都没被使用 |
| free_frag | 属于表空间,有可用页的碎片区 |
| full_frag | 无可用页的碎片区 |
| fseg | 属于某个段的区 |
【6】xdes entry区结构
innodb中每一个区都对应一个xdes entry结构,其组成图如下:
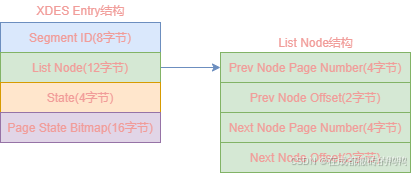
xdes entry结构字段含义如下:
| xdes entry | 字节大小 | 含义 |
|---|---|---|
| segment id | 8 | 段的唯一编号,只有fseg类型的区此字段才有用 |
| list node | 12 | 指向上一个和下一个xdes entry结构 |
| state | 4 | free、free_frag、full_frag、fseg四种区类型 |
| page state bitmap | 16 | 16字节对应的128比特位,其中每2个比特位对应一个区64个页中的一个页,2个比特位中第一个比特位代表该页是否被使用 |
list node结构字段含义如下:
| list node | 字节大小 | 含义 |
|---|---|---|
| prev node page number | 4 | 上一个xdes entry结构所在的页 |
| prev node offset | 2 | 上一个xdes entry结构页内偏移量 |
| next node page number | 4 | 下一个xdes entry结构所在的页 |
| next node offset | 2 | 下一个xdes entry结构页内偏移量 |
【7】xdes entry链表
在数据量比较小的时候,段是以碎片区中的页为单位来分配存储空间的,插入数据方式如下:
- 1、查找表空间中状态为free_frag的区,找到了就取出零碎的页把数据插进去,
- 2、没找到就申请一个状态为free的区,将状态变为free_frag,再取出零碎的页将数据插入进去,
- 3、之后再插入数据当没有零碎的页可用时状态就变为full_frag。
快速查找这3个类型的区通过3个链表来查找,这3个链表是属于表空间独有的,3个链表如下:
| 链表 | 含义 |
|---|---|
| free链表 | free状态的区对应的xdes entry结构通过list node组成的链表 |
| free_frag链表 | free_frag状态的区对应的xdes entry结构通过list node组成的链表 |
| full_frag链表 | full_frag状态的区对应的xdes entry结构通过list node组成的链表 |
当一个段中的数据超过32个零碎的页之后,就以区为单位来分配存储空间了,此时每个段都涉及3个链表,注意每个段都有3个链表,3个链表如下:
| 链表 | 含义 |
|---|---|
| free链表 | 同一个段中所有页都是空闲的区对应的xdes entry结构组成一个链表 |
| not_full链表 | 同一个段中有空闲页的区对应的xdes entry结构组成一个链表 |
| full链表 | 同一个段中没有有空闲页的区对应的xdes entry结构组成一个链表 |
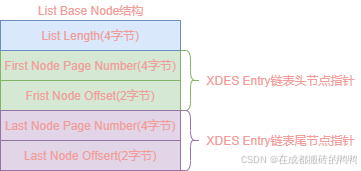
【8】xdes entry链表基节点
为了快速找到xdes entry链表的头和尾,innodb中设计了链表基节点结构list base node,其结构图如下:
【9】inode entry段结构
段也有一个对应的结构inode entry,其结构如图:
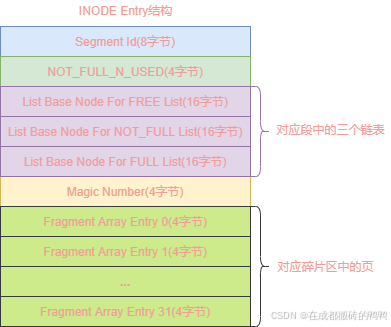
inode entry结构字段含义如下:
| inode entry | 字节大小 | 含义 |
|---|---|---|
| segment id | 8 | 段的唯一id |
| not_full_n_used | 4 | not_full链表中已经使用了的页数 |
| list base node for free list | 16 | 对应段中的free链表 |
| list base node for not_full list | 16 | 对应段中的not_full链表 |
| list base node for fulllist | 16 | 对应段中的full链表 |
| magic number | 4 | inode entry是否被初始化 |
| fragment array entry | 4 | 零碎页页号,总共32个 |
【10】fil_page_type_fsp_hdr页类型
表空间第一个组中第一个页的类型为fil_page_type_fsp_hdr,结构如下:
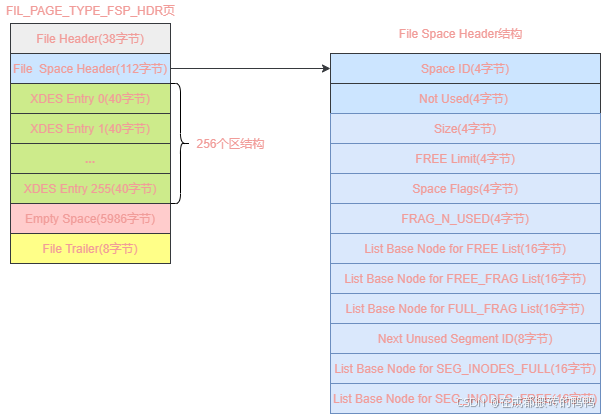
fil_page_type_fsp_hdr字段解释:
| 字段 | 字节大小 | 含义 |
|---|---|---|
| file header | 38 | 页的通用信息 |
| file space header | 112 | 表空间的一些整体属性 |
| xdes entry | 10240 | 256个区信息 |
| empty space | 5986 | 未使用的空间 |
| file trailer | 8 | 校验页是否完整 |
file space header结构字段解释:
| 字段 | 字节大小 | 含义 |
|---|---|---|
| space id | 4 | 表空间id |
| not used | 4 | 未使用 |
| size | 4 | 表空间占有的页数 |
| free limit | 4 | 未被初始化的最小页号,大于等于此页号对应的区的xdes entry结构都没被加入free链表 |
| space flags | 4 | 存储占用空间比较小的属性 |
| frag_n_used | 4 | free_frag链表中已使用的页数量 |
| list base node for free list | 16 | free链表基节点 |
| list base node for free_frag list | 16 | free_frag链表的基节点 |
| list base node for full_frag list | 16 | full_freg链表的基节点 |
| next unused segment id | 8 | 表空间中下一个未使用的段id |
| list base node for seg_inodes_full list | 16 | seg_inodes_full链表的基节点 |
| list base node for seg_inodes_free list | 16 | seg_inodes_free链表的基节点 |
【11】fil_page_ibuf_bitmap页类型
表空间所有组的第二个页的类型为fil_page_ibuf_bitmap,用于innodb存储引擎中事务日志缓冲区,与插入缓冲有关,后面再讲。
【12】fil_page_inode页类型
第一组第三个页类型就为fil_page_inode,用于存储段结构inode entry,其页结果如图:
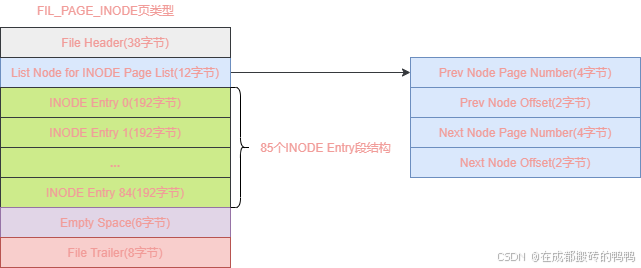
fil_page_inode页类型字段解释如下:
| 字段名 | 字节大小 | 含义 |
|---|---|---|
| file header | 38 | 页的通用信息 |
| list node for inode page list | 12 | 存储上一个inode页和下一个inode页 |
| inode entry | 16128 | 段信息,可以存储85个 |
| empty space | 6 | 未使用的空间 |
| file trailer | 8 | 校验页是否完整 |
可以看到一个fil_page_inode类型的页最多存储85个inode entry段结构,如果超过85个,就需要申请其它fil_page_inode类型的页来进行存储了,所有fil_page_inode类型的页会组成两个链表,这两个链表存储在fil_page_type_fsp_hdr类型页的file space header结构里,链表如下:
| 链表 | 含义 |
|---|---|
| seg_inodes_full链表 | fil_page_inode类型的页中没有空闲空间来存储inode entry段结构 |
| seg_inodes_free链表 | fil_page_inode类型的页中有空闲空间来存储inode entry段结构 |
存储一个inode entry结构的过程如下:
- 1、从seg_inodes_full链表中取出一个页去存储inode entry段结构,
- 2、如果页上的inode entry段机构存储满了就放入seg_inodes_free链表,
- 3、如果seg_inodes_full链表为空,就从表空间所属的free_frag链表中取出一个零碎页,修改其类型为fil_page_inode,再放入seg_inodes_full链表中。
【13】fil_page_type_xdes页类型
表空间第一个组之外的其它组的第一个页类型为fil_page_type_xdes,和fil_page_type_fsp_hdr页类型差不多,相比少了一些其它属性,其结构图如下:
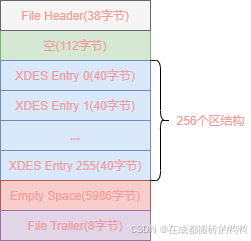
【14】索引关联inode entry段结构
一个索引有两个段,它们之间是这样关联起来的,数据页组成的页类型中有两个字段如下:
| 字段 | 字节大小 | 含义 |
|---|---|---|
| page_btr_seg_leaf | 10 | b+树叶子段的头部信息,只在b+树的根页定义 |
| page_btr_seg_top | 10 | b+树非叶子段的头部信息,只在b+树的根页定义 |
这两个字段各对应一个segment header结构如下:
| segment header字段 | 字节大小 | 含义 |
|---|---|---|
| spaceid ofthe inode entry | 4 | inode entry结构所在的表空间id |
| page number of the inode entry | 4 | inode entry结构所在页号 |
| byte offset of the inode ent | 2 | inode entry结构在页中偏移量 |
通过segment header就能很方便找到索引对应的inode entry段结构,并且只需要在b+树的根节点中定义这两字段。
3、总结
本文主要讲解独立表空间的组成部分,涉及到页、区、组还有各种结构等,后续可以再讲解系统表空间的组成,和独立表空间类似。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。





发表评论