1、背景
innodb存储引擎的基本存储单位是页,索引也是存储在页上的,b+树中非叶子节点的页也是数据页,和我们插入数据的区别是存放的行记录叫目录项记录,我们插入的行记录叫用户记录。
b+树由叶子节点和非叶子节点组成,叶子节点只有一层,用来存放用户记录,非叶子节点可以由一层或多层组成,用来存放目录项记录。
b+树这种结构是为了方便我们查找想要的数据,可以将b+树这种结构叫索引,建议先参考一下上篇文章讲解的页,接下来我们就来学习一下索引到底是什么。
2、准备
创建一个表并插入一些数据用来演示索引:
#创建表
create table test
(
id int auto_increment primary key,
str varchar(255) not null default ''
) engine = innodb default charset = utf8mb4;
#插入数据
insert into test (str)
values ('aaa'),
('bbb'),
('ccc');
查看记录:
mysql [xxx]> select * from test; +----+-----+ | id | str | +----+-----+ | 1 | aaa | | 2 | bbb | | 3 | ccc | +----+-----+ 3 rows in set (0.001 sec)
3、正篇
【1】存储用户记录的数据页
上面的3条记录可以用如下图表示,为了简介只展示主要字段:
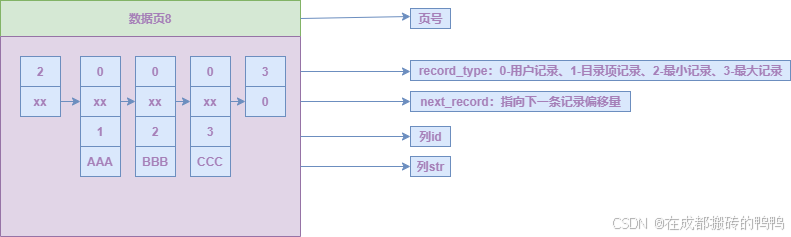
一个页面上的主键是顺序排列的,当要通过主键查找数据时,如果数据全在一张页上,通过二分法很快就能找到所查找的主键,但如果我们不通过主键查找数据,或者数据在很多张页上,页之间并不是连续存储的,这个时候就要遍历所有页所有数据,索引就是为解决这个问题而生的。
【2】存储目录项记录的数据页
目录项记录和用户记录的区别就是record_type的值为1,也代表b+树非叶子节点记录,还有一个区别就是min_rec_mask(b+树非叶子节点中的最小记录)不同,给一个3层b+树的例子如图:
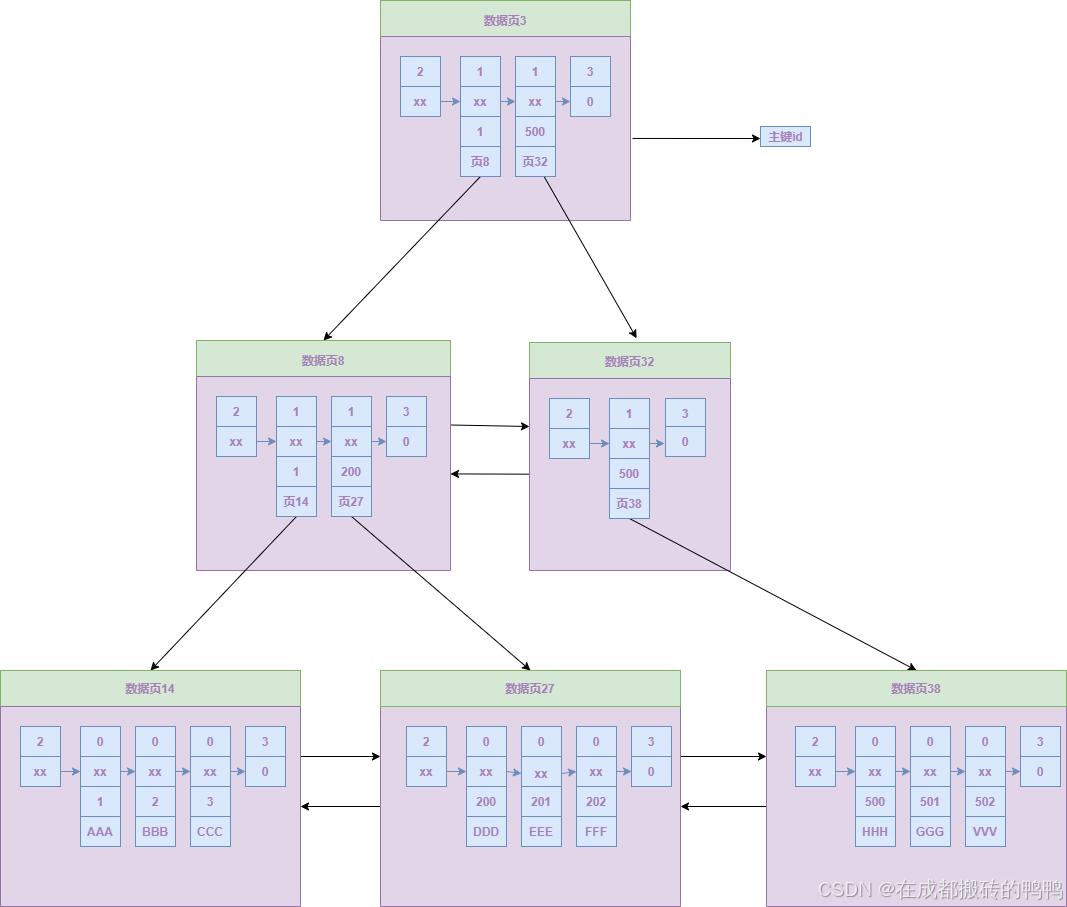
从上网往下数,最上面一层叫根节点,第二层叫非叶子节点,第三层叫叶子节点。
1、根节点和非叶子节点中的目录项记录根据主键大小进行排序,最左边的记录主键id在这个页中最小,所以它的min_rec_mask属性为1,根节点只有一个页,对根节点的目录项记录进行二分法很快就能找到下一个层级的数据页,然后再进行二分法得到要查的页,最后再对页里的用户数据进行二分法找到指定的记录。
2、叶子节点只有一层,叶子节点的页全部是用来存储用户记录。
【3】聚簇索引
主键索引就是聚簇索引,聚簇索引,满足以下条件:
- 1、一个页上的所有用户记录或者目录项记录根据主键大小形成一个单向链表。
- 2、b+树同一层级的所有页根据主键大小形成一个双向链表。
- 3、b+树叶子节点存放用户项记录包含所有列的数据。
【4】二级索引
聚簇索引只有在根据主键进行查找的时候能使用对应的b+树,根据其它列去查找时就要进行全表扫描了,我们给上述例子中str列也设置索引:
alter table test add index str (str);
设置完之后会产出一颗新的b+树,如图:
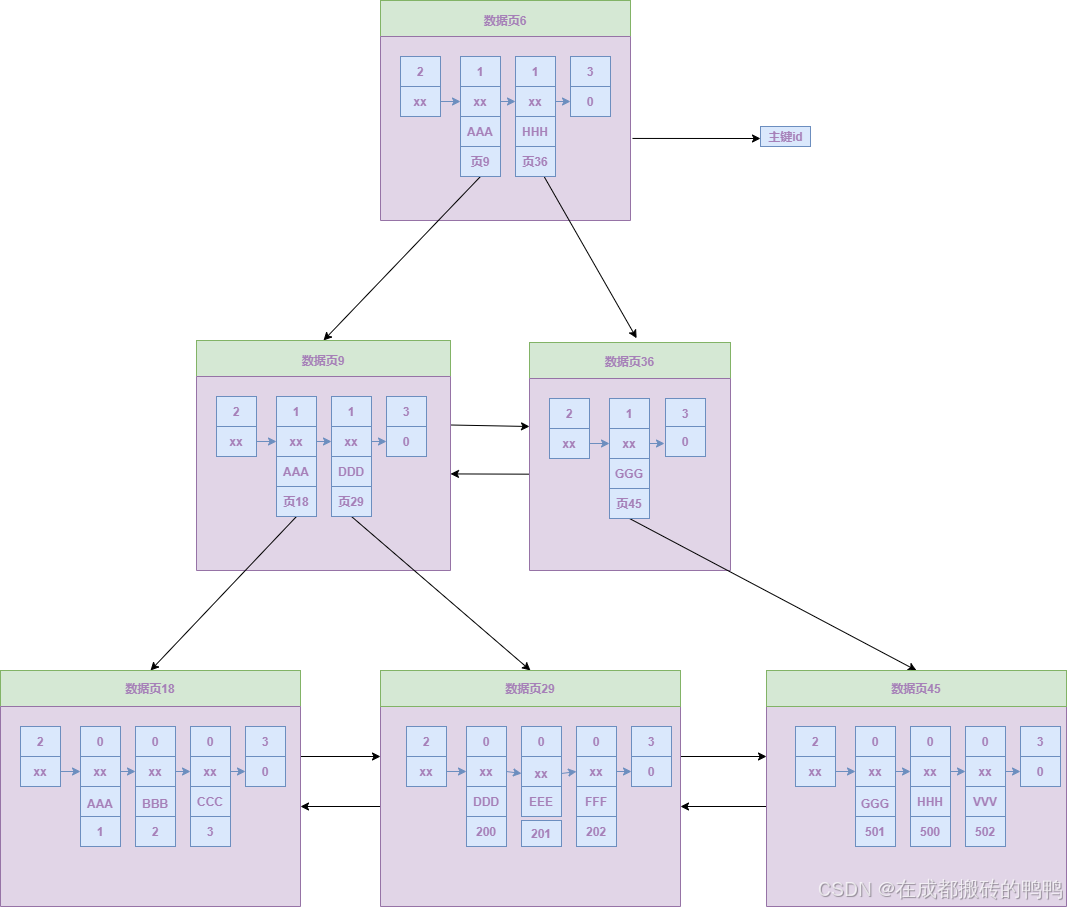
str列建的b+树由如下特性:
1、页里的目录项记录和用户记录根据str列大小组成一个单向链表。
2、每层节点的所有页根据str列大小组成一个双向链表。
3、叶子节点存储的数据部分其实只有str列和主键大小,因为这里建表的列字段只有str列和主键,假如有多个列,要想知道其它列的信息,我们就得根据查出来的str列对应的主键到聚簇随意对应的b+树里去找到其它列数据,这种查找方式就叫"回表"。
我们这里只有主键和str两列,所以不需要回表就能得到所有列的数据,这种需要最多进行一次回表的b+树,被称为"二级索引"。
二级索引对应的目录项记录有个要注意的地方:
并不是只存储了str列和页号,还存储了主键值,这是为了插入记录的str列相同时,需要根据主键的不同来确定将记录插入到哪个页。
【5】组合索引
给多个列建一颗b+树就叫组合索引,假设有这样一个表:
create table test
(
id int auto_increment primary key,
str1 varchar(255) not null default '',
str2 varchar(255),
str3 char(5)
) engine = innodb default charset = utf8mb4;
建立组合索引的sql语句:
alter table test add index str1_str2_str3 (str1, str2, str3);
上面组合索引有这样的特性:
- 1、所有页和行记录先根据str1的大小顺序进行排列。
- 2、在str1相同的情况下根据str2的大小顺序进行排列。
- 3、在str2相同的情况下再根据str3的大小顺序进行排列。
- 4、b+树中的所有页和页里所有行记录会根据3个列的大小分别组成双向链表和单向链表。
4、总结
通过本文学习到了,索引就是b+树对应的结构,放了方便我们根据某列快速找到想要的记录,根据b+ 树的不同又可以分为:聚簇索引、二级索引、组合索引。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。



发表评论