1、背景
之前我们讲过redo日志类型有很多种,但是要想保证服务器崩溃数据能还原,这些日志还是得存储在磁盘上,接下来我们就来讲解一下redo日志的存储过程。
2、redo日志存储过程
【1】redo log block
redo日志也是存储在页中的,页的大小为512字节,存储redo日志的页就被称为redo log block,一个redo log block有三部分组成,其组成如图:
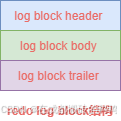
字段含义如下:
| 字段名 | 字节大小 | 含义 |
|---|---|---|
| log block header | 12 | 由4部分组成,存储管理信息 |
| log block body | 496 | 真正存储redo日志数据的地方 |
| log block trailer | 4 | 由1部分组成,用于校验正确性 |
log block header的组成结果如图:

字段含义如下:
| 字段名 | 字节大小 | 含义 |
|---|---|---|
| log_block_hdr_no | 4 | 每个block的唯一编号 |
| log_block_hdr_data_len | 2 | block中已经使用了多少字节,初始就为log block header大小12 |
| log_block_first_rec_group | 2 | 这个block中第有个mtr(mini-transaction)对应的redo日志组中第一条redo日志偏移量 |
| log_block_checkpoint_no | 4 | checkpoint序号 |
【2】log buffer
redo日志也不是直接写入磁盘,会写入一块连续的内存区域,这块连续的内存就叫log buffer,其结构如图:
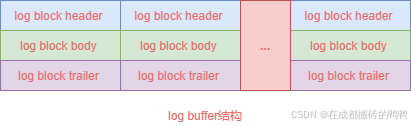
这块连续内存的大小可以通过innodb_log_buffer_size字段查看,单位字节:
mysql> show variables like 'innodb_log_buffer_size'; +------------------------+----------+ | variable_name | value | +------------------------+----------+ | innodb_log_buffer_size | 16777216 | +------------------------+----------+ 1 row in set, 1 warning (0.00 sec)
【3】buf_free
一个事务可以有多个mtr,一个mtr可以有多个redo日志记录,将redo日志写入log buffer中时,时间上是写入block中的log block body部分,当一个block写满也就是log block body写满时,就去写连续的下一个block,可以写入redo日志的空闲log buffer的最小偏移量就叫buf_free,所以每次我们要写入redo日志只需要找到buf_free偏移量,就可以知道在log buffer的哪个地方写redo日志了,可以如图表示:
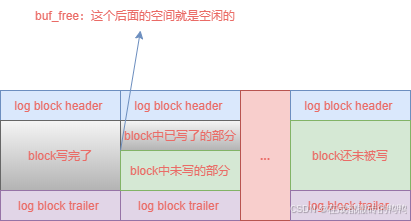
【4】redo日志刷盘时机
log buffer空闲有限,所以也需要将redo日志写到磁盘再释放空间,用于写入新的redo日志,从内存刷到磁盘的时机有如下几种:
- 1、log buffer空间不足
- 2、事务提交时
- 3、后台线程定时刷
- 4、正常关闭服务器
- 5、checkpoint时
【5】redo日志文件组
从log buffer刷新到磁盘中的redo日志是存储在ib_logfile0、ib_logfile1、ib_logfilen文件中,这些文件就叫redo日志文件组,可以通过配置文件指定此组文件的目录、大小、数量。
查看目录方式如下:
mysql> show variables like 'innodb_log_group_home_dir'; +---------------------------+--------------------------------------------+ | variable_name | value | +---------------------------+--------------------------------------------+ | innodb_log_group_home_dir | /xxx/data | +---------------------------+--------------------------------------------+ 1 row in set (0.002 sec)
查看大小方式如下,单位字节:
mysql> show variables like 'innodb_log_file_size'; +----------------------+----------+ | variable_name | value | +----------------------+----------+ | innodb_log_file_size | 50331648 | +----------------------+----------+ 1 row in set, 1 warning (0.01 sec)
查看数量方式如下:
mysql> show variables like 'innodb_log_files_in_group'; +---------------------------+-------+ | variable_name | value | +---------------------------+-------+ | innodb_log_files_in_group | 2 | +---------------------------+-------+ 1 row in set, 1 warning (0.00 sec)
查看一下ib_logfile文件如下:
[root@xxx xxx]# ls /xxx/data/ | grep 'ib_log' ib_logfile0 ib_logfile1
写文件是ib_logfile0到ib_logfile1循环写入,当ib_logfile1写满时就重新从ib_logfile0重新写入。
【6】ib_logfile文件格式
和log buffer的组成结构一样,ib_logfile也是由连续的512字节大小的block组成,有区别的是ib_logfile的前四个block用了存储管理信息,后面的block才用来存储redo日志,其存储过程可以如图表示:
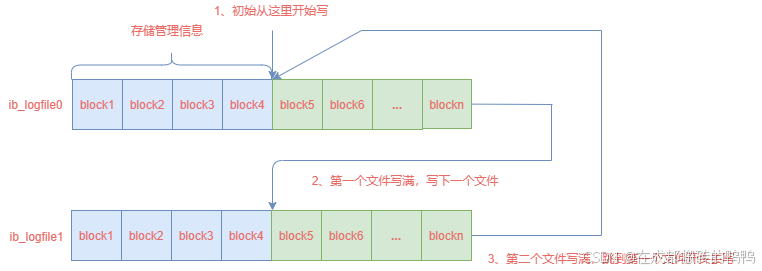
redo日志文件前四个block分别为log file header、checkpoint1、未使用、checkpoint2,checkpoint1和checkpoint2是一样的,接下来我们就来讲一下log file header和checkpoint。
log file header结构如下:

其字段含义为:
| 字段 | 字节大小 | 含义 |
|---|---|---|
| log_header_format | 4 | redo日志版本 |
| log_header_pad1 | 4 | 无用 |
| log_header_start_lsn | 8 | 标记redo日志文件开始的lsn值,也就是第5个block开始对应的lsn值 |
| log_header_creator | 32 | 标记redo日志的创建者 |
| log_block_checksum | 4 | 本block的校验值 |
checkpoint结构如下:
其字段含义为:
| 字段 | 字节大小 | 含义 |
|---|---|---|
| log_checkpoint_no | 8 | 服务器每做一次checkpoint,该值就加1 |
| log_checkpoint_lsn | 8 | 服务器做checkpoint结束时对应的lsn值,系统崩溃恢复时从该值开始 |
| log_checkpoint_offset | 8 | 上个属性中lsn值在redo日志文件组中的偏移量 |
| log_checkpoint_log_buf_size | 8 | 服务器在做checkpoint时对应的log buffer大小 |
| log_block_checksum | 4 | block的校验值 |
【7】log sequeue number
log buffer中,innodb为已经写入的redo日志量用个全局变量log sequeue number表示,也叫日志序列号,简称lsn,lsn的初始值为8704,但是block真正写redo日志的是中间的body部分,所以初始的lsn值需要加上第一个block的log block header(12字节)的大小得到初始的lsn值为8716,需要注意后续写入的redo日志如果占用了几个block,计算lsn就需要加上log block header和log block trailer。
【8】flushed_to_disk_lsn
lsn是标记log buffer中已经写入redo日志的量,不关心log buffer上的redo日志是否刷新到磁盘上也就是ib_logfile中,所以innodb中提供了flushed_to_disk_lsn的全局变量来标识log buffer中已经被刷到磁盘的量。
【9】flush链表中的lsn
当我们修改一条数据可能会产生以下流程,首先会产生多个mtr,将这些mtr对应的redo日志组写到log buffer中,然后修改buffer pool中的页,最后再将修改的页对应的控制块加入flush链表,控制块中有个两个记录lsn的属性,oldest_modification和newest_modification,其属性含义如下:
| 属性名 | 含义 |
|---|---|
| oldest_modification | 控制块对应的页被修改起始对应的lsn值 |
| newest_modification | 控制块对应的页被修改结束对应的lsn值 |
需要注意的是多个mtr修改相同的页,不会修改页对应的控制块在链表中的位置,但是会更新newest_modification属性的值。
【10】checkpoint
innodb中提出了一个全局变量checkpoint_lsn,用来表示redo日志文件中小于该值的部分都可以被覆盖,checkpoint指的是buffer pool中的脏页被刷新到磁盘,这时脏页对应的redo日志就可以被覆盖了,我们就能计算一个checkpoint_lsn值这个过程。
innodb中还有一个checkpoin_no的变量,每执行一次checkpoint,该值就会加1。
前面讲过checkpoint的属性就会包含:checkpoint_lsn、checkpoint_no、checkpoint_lsn对应的偏移量,至于这些属性是存储在checkpoint1还是checkpoint2中,是根据checkpoint_no是奇数还是偶数,如果是奇数就写到checkpoit2中,偶数就写checkpoint1中。
【11】系统中的lsn值
我们可以查看系统中的lsn值,可以通过如下命令去查看:
mysql> show engine innodb status\g; ... --- log --- log sequence number 20993334 log buffer assigned up to 20993334 log buffer completed up to 20993334 log written up to 20993334 log flushed up to 20993334 added dirty pages up to 20993334 pages flushed up to 20993334 last checkpoint at 20993334 log minimum file id is 6 log maximum file id is 6 25 log i/o's done, 0.00 log i/o's/second ...
其字段含义为:
| 字段名 | 含义 |
|---|---|
| log sequence number | 当前redo日志中lsn的最大值,表示所有修改数据的操作产生的日志序列号,该值会随着日志的写入逐渐增大 |
| log buffer assigned up to | log buffer中被分配到的lsn值,与log sequence number相同 |
| log buffer completed up to | log buffer中准备好写磁盘的lsn值,与log sequence number相同 |
| log written up to | 已经写到redo日志文件的日志序列号 |
| log flushed up to | 已经刷新到磁盘的redo日志序列号 |
| added dirty pages up to | 已添加到脏页列表的页面的lsn值 |
| pages flushed up to | 已经刷新到磁盘脏页的lsn值 |
| last checkpoint at | 当前checkpoit_lsn的值 |
| log minimum file id is | redo日志文件的最小文件id |
| log maximum file id is | redo日志文件的最大文件id |
【12】innodb_flush_log_at_trx_commit
redo日志刷新到磁盘的方式由innodb_flush_log_at_trx_commit控制,刷新方式有3种,分别为:
| innodb_flush_log_at_trx_commit值 | 刷新方式 |
|---|---|
| 0 | 事务提交时不立即刷新redo日志到磁盘,由后台线程去刷新到磁盘,如果服务器挂了,后台线程没及时将redo日志刷新到磁盘,事务对该页面的修改就会丢失 |
| 1 | 事务提交时就将redo日志同步到磁盘 |
| 2 | 事务提交时将redo日志写入log buffer,不需要刷新到磁盘,当数据库挂,操作系统挂也能保证持久性,数据库和操作系统都挂就保证不了持久性了 |
【13】崩坏是redo日志恢复
redo日志的恢复过程如下:
1、确定恢复的起点,也就是checkpoint_lsn,
2、确定恢复的终点,也就是ib_logfile中block未写满的位置,
3、从checkpoint_lsn恢复页时,如果页的fil_page_lsn值,也就是newest_modification的值如果大于checkpoint_lsn,说明该页已经恢复,直接跳过,如果小于checkpoint_lsn,就需要读取redo日志进行恢复。
3、总结
redo日志是innodb使用崩溃恢复的核心机制,通过物理日志、顺序写入和checkpoint机制,保证事务的持久性并且提高了数据库的性能。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。





发表评论