1、背景
在进行sql查询时有时需要多张表的查询结果组成一个共同的结果返回,这时就用到了mysql中连接的用法,接下来就以两张表来讲解表连接的原理。
2、环境
创建两张表并插入数据如下:
mysql> select * from testjoin1; +----+------+------+ | id | str1 | num1 | +----+------+------+ | 1 | aaa | 111 | | 2 | bbb | 222 | | 3 | ccc | 333 | +----+------+------+ 3 rows in set (0.00 sec) mysql> select * from testjoin2; +----+------+------+ | id | str2 | num2 | +----+------+------+ | 1 | bbb | 333 | | 2 | ccc | 444 | | 3 | ddd | 555 | +----+------+------+ 3 rows in set (0.00 sec)
3、表连接原理
【1】驱动表和被驱动表
两张表连接查询过程为:
- 1、先确定第一张要查询的表得到第一张表的查询结果,
- 2、第一张表的查询结果作为第二张表的查询条件进行查询得到最终查询结果。
其中第一张表叫驱动表,第二张表叫被驱动表,先看一下最基本连接查询的例子:
mysql> select * from testjoin1, testjoin2; +----+------+------+----+------+------+ | id | str1 | num1 | id | str2 | num2 | +----+------+------+----+------+------+ | 3 | ccc | 333 | 1 | bbb | 333 | | 2 | bbb | 222 | 1 | bbb | 333 | | 1 | aaa | 111 | 1 | bbb | 333 | | 3 | ccc | 333 | 2 | ccc | 444 | | 2 | bbb | 222 | 2 | ccc | 444 | | 1 | aaa | 111 | 2 | ccc | 444 | | 3 | ccc | 333 | 3 | ddd | 555 | | 2 | bbb | 222 | 3 | ddd | 555 | | 1 | aaa | 111 | 3 | ddd | 555 | +----+------+------+----+------+------+ 9 rows in set (0.00 sec)
再看一下执行计划:
mysql> explain select * from testjoin1, testjoin2;
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+----------------
---------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | extra
|
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+----------------
---------------+
| 1 | simple | testjoin1 | null | all | null | null | null | null | 3 | 100.00 | null
|
| 1 | simple | testjoin2 | null | all | null | null | null | null | 3 | 100.00 | using join buff
er (hash join) |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+----------------
---------------+
2 rows in set, 1 warning (0.00 sec)
可以看到执行计划输出了两条,第一条代表testjoin1表是驱动表, testjoin2表是被驱动表。
【2】内连接
驱动表的查询结果作为查询条件但没有在被驱动表中匹配到结果时,这条记录就不会加入到最终结果集中,这种连接方式就叫内连接,例如:
mysql> select * from testjoin1 inner join testjoin2 on str1=str2; +----+------+------+----+------+------+ | id | str1 | num1 | id | str2 | num2 | +----+------+------+----+------+------+ | 2 | bbb | 222 | 1 | bbb | 333 | | 3 | ccc | 333 | 2 | ccc | 444 | +----+------+------+----+------+------+ 2 rows in set (0.00 sec)
可以看到testjoin1表中str1为aaa的记录就不在查询结果中,用图红色部分表示:
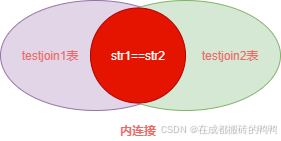
【3】外连接
与内连接相对应的就是外连接,外连接中驱动表的查询结果作为查询条件即使没有在被驱动表中查到,也会展示在最终结果集中,外连接分为左外连接和右外连接,左外连接就是将左边的表作为驱动表,左外连接查询如下:
mysql> select * from testjoin1 left join testjoin2 on str1=str2; +----+------+------+------+------+------+ | id | str1 | num1 | id | str2 | num2 | +----+------+------+------+------+------+ | 1 | aaa | 111 | null | null | null | | 2 | bbb | 222 | 1 | bbb | 333 | | 3 | ccc | 333 | 2 | ccc | 444 | +----+------+------+------+------+------+ 3 rows in set (0.00 sec)
用图紫色部分表示:
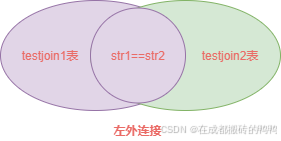
右外连接就是将右边的表作为驱动表,右外连接查询如下:
mysql> select * from testjoin1 right join testjoin2 on str1=str2; +------+------+------+----+------+------+ | id | str1 | num1 | id | str2 | num2 | +------+------+------+----+------+------+ | 2 | bbb | 222 | 1 | bbb | 333 | | 3 | ccc | 333 | 2 | ccc | 444 | | null | null | null | 3 | ddd | 555 | +------+------+------+----+------+------+ 3 rows in set (0.00 sec)
用图绿色部分表示:
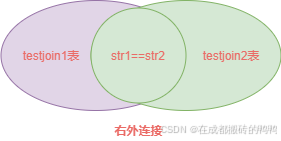
【4】嵌套循环连接
驱动表只会被访问一次,被驱动表可能被访问多次,取决于从驱动表中得到的结果,这种连接执行方式就叫嵌套循环连接。
【5】join buffer
mysql中的查表过程就是把数据从磁盘中加载到内存进行比较查询,加载后面的记录时会释放内存中前面已经使用过的记录,我们上面说过被驱动表可能会被访问很多次,每次都从磁盘重新加载数据到内存无疑会增加开销,所以提出了join buffer,也就是存储驱动表的所有查询结过,然后只执行一次将被驱动表从磁盘加载到内存中,在内存中计算得到最终查询结果,前面测试连接的explain语句中就可以看到被驱动表的extra字段中有using join buffer。
4、总结
对驱动表进行查询时就相当于单表查询,也可以通过索引去优化查询速度,当确定了驱动表的查询结果时,其实被驱动的查询条件也就确定了,也可以通过加索引去优化查询速度,当然索引是否生效还要看和全表扫描的执行效率进行对比。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。




发表评论