一个对象总是映射一块连续的内存序列(不考虑对象之间的引用关系),如果我们知道了引用类型实例的内存布局,以及变量引用指向的确切的地址,我们不仅可以采用纯“二进制”的方式在内存“绘制”一个指定引用类型的实例,还可以修改某个变量的“值”指向它,还能直接通过改变二进制内容来更新实例的状态。
一、引用类型实例的内存布局
从内存布局的角度来看,一个引用类型的实例由如下图所示的三部分组成:objheader + typehandle + fields。前置的objheader用来缓存哈希值和同步状态(《》具有对此的详细介绍),typehandle部分存储类型对应方法表(method table)的地址,方法表可以视为针对类型的描述。也正是这部分内容的存在,运行时可以确定任何一个实例的真实类型,所以我们才说引用类型的实例是自描述(self describing)的。fields用于存储实例每个字段的内容。
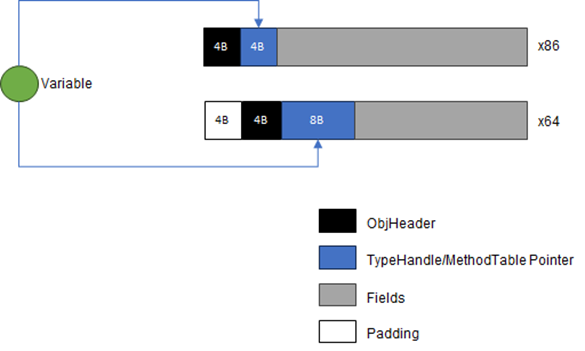
对于32位(x86)的机器来说,objheader 和 typehandle的长度都是4字节。如果是64位(x64)的机器,用于存储方法表地址的typehandle 需要8个字节来存储,但是objheader 依然是4个直接。考虑到内存对齐,需要前置4个字节的padding。对于一个不为null的应用类型变量来说,它存储的是实例的内存地址。但是这个地址并不是实例所在内存的“首地址(objheader)”,而是typehandle部分的地址。
二、以二进制的形式创建对象
既然我们已经知道了引用类型实例的内存布局,也知道了引用指向的确切的地址,我们不仅可以采用纯“二进制”的方式在内存“绘制”一个指定引用类型的实例,还可以修改某个变量的“值”指向它。具体的实现体现在如下所示的create方法中,该方法根据指定的属性值创建一个foobar对象。除了用来提供两个属性值的foo、bar参数之外,它还通过输出参数bytes返回整个实例的字节序列。
var foobar = create(1, 2, out var bytes);
debug.assert(foobar.foo == 1);
debug.assert(foobar.bar == 2);
static unsafe foobar create(int foo, int bar, out byte[] bytes)
{
foobar foobar = null!;
bytes = new byte[24];
binaryprimitives.writeint64littleendian(bytes.asspan(8), typeof(foobar).typehandle.value.toint64());
binaryprimitives.writeint32littleendian(bytes.asspan(16), foo);
binaryprimitives.writeint32littleendian(bytes.asspan(20), bar);
unsafe.write(unsafe.aspointer(ref foobar), new intptr(unsafe.aspointer(ref bytes[8])));
return foobar;
}
public class foobar
{
public int foo { get; set; }
public int bar { get; set; }
}根据上述针对内存布局的介绍,我们知道任何一个foobar实例在x64机器中都映射位一段连续的24字节内存,所以create方法创建了一个长度位24的字节数组。我们保持objheader为空,所以我们从第8(zero based)个字节开始写入foobar类型对应typehandle的值(8字节),然后将指定的数据成员的值(int类型占据4个字节)填充到最后8个字节(由于两个字段的类型均为int,所以不需要添加额外的“留白”来确保内存对齐)。自此我们将“凭空”在内存中“绘制”了一个foobar对象。由于x86机器采用“小端字节序”,所以二进制的写入最终是通过调用binaryprimitives的writeint32/64littleendian方法来完成的。
接下来我们定义一个foobar类型的变量,并让它指向这个绘制的foobar对象。我们在上面说过,它指向的不是实例内存的首字节,而是typlehandle部分。对于我们的例子来说,它指向的就是我们创建的字节数组的第8(zero based)的元素。针对变量内容(目标对象的地址)的改写是通过调用unsafe的静态方法write实现的。我们的演示程序调用了create创建了一个foo和bar属性分别为1和2的foobar对象,并得到它真正映射在内存中的字节序列。
三、字节数组与实例状态的同一性
对于我们定义的create方法来说,由于通过输出参数返回的字节数字就是返回的foobar对象在内存中的映射,所以foobar的状态(foo和bar属性)发生改变后,字节数组的内容也会发生改变。这一点可以通过如下的程序来验证。
var foobar = create(1, 1, out var bytes); console.writeline(bitconverter.tostring(bytes)); foobar.foo = 255; foobar.bar = 255; console.writeline(bitconverter.tostring(bytes));
输出结果
00-00-00-00-00-00-00-00-d8-11-30-17-f9-7f-00-00-01-00-00-00-01-00-00-00
00-00-00-00-00-00-00-00-d8-11-30-17-f9-7f-00-00-ff-00-00-00-ff-00-00-00
既然返回的字节数据和foobar对象具有同一性,我们自然也可以按照如下的方式通过修改字节数组的内容来到达改变实例状态的目的。
var foobar = create(1, 1, out var bytes); debug.assert(foobar.foo == 1); debug.assert(foobar.bar == 1); binaryprimitives.writeint32littleendian(bytes.asspan(16), 255); binaryprimitives.writeint32littleendian(bytes.asspan(20), 255); debug.assert(foobar.foo == 255); debug.assert(foobar.bar == 255);
四、objheader针对哈希被同步状态的缓存
我们可以进一步利用这种方式验证实例的objheader针对哈希值和同步状态的缓存。如下面的代码片段所示,我们调用create创建了一个foobar对象并将得到的字节数组打印出来。然后我们调用其gethashcode方法触发哈希值的计算,并再次打印字节数组。接下来我们创建一个新的foobar对象,分别对它进行加锁和解锁状态打印字节数组。
var foobar = create(1, 2, out var bytes);
console.writeline($"{bitconverter.tostring(bytes)}[original]");
foobar.gethashcode();
console.writeline($"{bitconverter.tostring(bytes)}[gethashcode]");
foobar = create(1, 2, out bytes);
lock (foobar)
{
console.writeline($"{bitconverter.tostring(bytes)}[enter lock]");
}
console.writeline($"{bitconverter.tostring(bytes)}[exit lock]");从如下所示的输出结果可以看出,在gethashcode方法调用和被“锁住”之后,承载foobar对象的objheader字节(4-7字节)都发生了改变,实际上运行时就是利用它来存储计算出的哈希值和同步状态。至于objheader具体的字节布局,我的另一篇文章《?》提供了系统的说明。
00-00-00-00-00-00-00-00-90-1c-30-17-f9-7f-00-00-01-00-00-00-02-00-00-00[original]
00-00-00-00-c7-d5-9f-0d-90-1c-30-17-f9-7f-00-00-01-00-00-00-02-00-00-00[gethashcode]
00-00-00-00-01-00-00-00-90-1c-30-17-f9-7f-00-00-01-00-00-00-02-00-00-00[enter lock]
00-00-00-00-00-00-00-00-90-1c-30-17-f9-7f-00-00-01-00-00-00-02-00-00-00[exit lock]
到此这篇关于以纯二进制的形式在内存中绘制一个对象的文章就介绍到这了,更多相关二进制形式绘制一个对象内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论