在《》中我们知道一个值类型或者引用类型的实例在内存中占多少字节。如果我们知道这段连续的字节序列的初始地址,我们就能够将代表该实例的字节内容读取出来。在接下来的内容中,我们将利用一个简单的方法输出指定实例的字节序列,并此次分析值类型和引用类型实例在内存的布局。
一、读取实例在内存中的字节
如下所示的printbytes<t>会将指定实例在内存中的字节输出到控制台上。如代码片段所示,我们先调用《如何计算一个实例占用多少内存?》中定义了sizecalculator将承载实例内容的字节数计算出来,并创建对应长度的字节数组来存放读取的字节。如果指定的变量value是一个结构体(值类型),意味着变量会直接指向结构体的首字节。在这种情况下,我们只需要将该变量的引用转换成指针(void*),然后将其转换成intptr对象,并作为起始地址调用marshal的copy方法将指定数量的字节拷贝到创建的字节数组就可以了。
public static class bytesprinter
{
public unsafe static void printbytes<t>(t value)
{
var size = sizecalculator.instance.sizeof(() => value);
var bytes = new byte[size];
var pointer = unsafe.aspointer(ref value);
intptr head = typeof(t).isvaluetype ? new intptr(pointer) : *(intptr*)pointer - intptr.size;
marshal.copy(head, bytes, 0, size);
console.writeline($"[{size}]{bitconverter.tostring(bytes)}");
}
public static string asstring(this intptr ptr) => bitconverter.tostring(bitconverter.getbytes(ptr.toint64()));
}对于引用类型,整个过程就要复杂一些。此时指定的变量value指向的是目标对象的地址,所以在将此变量引用转换成void*指针后,还需要将其转换成intptr*指针,并最终将指针的内容(也就是目标对象的地址)解析出来。由于变量指向的地址并非目标实例映射内存字节的首地址,仅仅是存储方法表地址的地方,所以还需要向前移动一个身位(intptr.size)才是实例所在内存片段的首地址。在将所需字节拷贝到创建的字节数组之后,我们将其格式化成字符串输出到控制台上。另一个asstring扩展方法会将指定intptr对象表示的内存地址输出到控制台上,我们会在后续的演示中使用到它。顺便把《如何计算一个实例占用多少内存?》中介绍的sizecalculator类型定义给出来。
public class sizecalculator
{
private static readonly concurrentdictionary<type, int> _sizes = new();
private static readonly methodinfo _getdefaultmethod = typeof(sizecalculator).getmethod(nameof(getdefault), bindingflags.static | bindingflags.nonpublic)!;
public static readonly sizecalculator instance = new();
public int sizeof(type type, func<object?>? instanceaccessor = null)
{
if (_sizes.trygetvalue(type, out var size)) return size;
if (type.isvaluetype) return _sizes.getoradd(type, calculatevaluetypeinstance);
object? instance;
try
{
instance = instanceaccessor?.invoke() ?? activator.createinstance(type);
}
catch
{
throw new invalidoperationexception("the delegate to get instance must be specified.");
}
return _sizes.getoradd(type, type => calculatereferencetypeinstance(type, instance));
}
public int sizeof<t>(func<t>? instanceaccessor = null)
{
if (instanceaccessor is null) return sizeof(typeof(t));
func<object?> accessor = () => instanceaccessor();
return sizeof(typeof(t), accessor);
}
public int calculatevaluetypeinstance(type type)
{
var instance = getdefaultasobject(type);
var fields = type.getfields(bindingflags.declaredonly | bindingflags.instance | bindingflags.public | bindingflags.nonpublic)
.where(it => !it.isstatic)
.toarray();
if (fields.length == 0) return 0;
var tupletype = typeof(valuetuple<,>).makegenerictype(type, type);
var tupple = tupletype.getconstructors()[0].invoke(new object?[] { instance, instance });
var addresses = generatefieldaddressaccessor(tupletype.getfields()).invoke(tupple).orderby(it => it).toarray();
return (int)(addresses[2] - addresses[0]);
}
public int calculatereferencetypeinstance(type type, object? instance)
{
var fields = getbasetypesandthis(type)
.selectmany(type => type.getfields(bindingflags.declaredonly | bindingflags.instance | bindingflags.public | bindingflags.nonpublic))
.where(it => !it.isstatic).toarray();
if (fields.length == 0) return type.isvaluetype ? 0 : 3 * intptr.size;
var addresses = generatefieldaddressaccessor(fields).invoke(instance);
var list = new list<fieldinfo>(fields);
list.insert(0, null!);
fields = list.toarray();
array.sort(addresses, fields);
var lastfieldoffset = (int)(addresses.last() - addresses.first());
var lastfield = fields.last();
var lastfieldsize = lastfield.fieldtype.isvaluetype ? calculatevaluetypeinstance(lastfield.fieldtype) : intptr.size;
var size = lastfieldoffset + lastfieldsize;
// round up to intptr.size
int round = intptr.size - 1;
return ((size + round) & (~round)) + intptr.size;
static ienumerable<type> getbasetypesandthis(type? type)
{
while (type is not null)
{
yield return type;
type = type.basetype;
}
}
}
private static func<object?, long[]> generatefieldaddressaccessor(fieldinfo[] fields)
{
var method = new dynamicmethod(
name: "getfieldaddresses",
returntype: typeof(long[]),
parametertypes: new[] { typeof(object) },
m: typeof(sizecalculator).module,
skipvisibility: true);
var ilgen = method.getilgenerator();
// var addresses = new long[fields.length + 1];
ilgen.declarelocal(typeof(long[]));
ilgen.emit(opcodes.ldc_i4, fields.length + 1);
ilgen.emit(opcodes.newarr, typeof(long));
ilgen.emit(opcodes.stloc_0);
// addresses[0] = address of instace;
ilgen.emit(opcodes.ldloc_0);
ilgen.emit(opcodes.ldc_i4, 0);
ilgen.emit(opcodes.ldarg_0);
ilgen.emit(opcodes.conv_i8);
ilgen.emit(opcodes.stelem_i8);
// addresses[index] = address of field[index + 1];
for (int index = 0; index < fields.length; index++)
{
ilgen.emit(opcodes.ldloc_0);
ilgen.emit(opcodes.ldc_i4, index + 1);
ilgen.emit(opcodes.ldarg_0);
ilgen.emit(opcodes.ldflda, fields[index]);
ilgen.emit(opcodes.conv_i8);
ilgen.emit(opcodes.stelem_i8);
}
ilgen.emit(opcodes.ldloc_0);
ilgen.emit(opcodes.ret);
return (func<object?, long[]>)method.createdelegate(typeof(func<object, long[]>));
}
private static t getdefault<t>() where t : struct => default!;
private static object? getdefaultasobject(type type) => _getdefaultmethod.makegenericmethod(type).invoke(null, array.empty<object>());
}二、查看值类型和引用类型实例的内存字节
在如下的代码片段中,我们定义的结构体foobarstructure和类foobarclass具有两个字段foo和bar,对应类型分别是byte和int32。我们分别创建了它们的实例,并将这两个字段设置成255(0xff)和65535(0xffff)。我们将它们作为参数调用了上面定义的printbytes方法。
bytesprinter.printbytes(new foobarstructure(255, 65535));
bytesprinter.printbytes(new foobarclass(255, 65535));
public struct foobarstructure
{
public byte foo;
public int bar;
public foobarstructure(byte foo, int bar)
{
foo = foo;
bar = bar;
}
}
public class foobarclass
{
public byte foo;
public int bar;
public foobarclass(byte foo, int bar)
{
foo = foo;
bar = bar;
}
}程序执行后会将指定的foobarstructure和foobarclass实际对应的字节输出控制台上。为了更好地理解该字节序列每一部分的内容,我特意按照如下的方式添加了方括号对它们进行了分割。从下面的内容可以看出,虽然byte和int32对应的字节数分别为1和4,但是foobarstructure这个结构体的字节数却是8,三个空白字节(红色标记)是为了内存对齐额外添加的“留白(padding,红色标注)”。从字节的内容还可以看出,内存中体现的字段顺序默认与它们在结构体中定义的顺序是一致的(foo:ff;bar:ff-ff-00-00)。顺便提一下,基元类型在内存中是按照“小端序”存储的。
[8][ff-00-00-00]-[ff-ff-00-00]
[24][00-00-00-00-00-00-00-00]-[38-39-78-b3-fd-7f-00-00]-[ff-ff-00-00-ff-00-00-00]
foobarclass实例在内存中的字节数要多很多,变成了24。第一组8字节是代表objectheader(包含4字节用于内存对齐的空字节),第2组8字节代表foobarclass类型的方法表的内存地址。两个字段的内容体现在最后一组8字节中,可以看出它们内容与foobarstructure不一样,这是因为在默认的情况下,结构体采用sequential(与定义一致),而类则采用auto,其目的是为了满足内存对其规则的情况下对字段进行重新排序,以节省内存空间。在这里bar字段(ff-ff-00-00)被放在foo字段(ff)的前面。由于24是引用类型实例在内存中的最小字节数(针对x64架构),字段重排针对内存的“压缩”没有体现出来。
三、存储方法表地址
.net运行时中针对“类型”的描述信息几乎都来自于方法表这个内部的数据结构。引用类型实例在内存中的第二部分内容(objectheader之后)存放的就是对应方法表的地址,实例和类型就是通过这种方式关联起来的。在c#中,我们也可以利用表示“类型句柄(type handle)”的runtimetypehandle对象得到对应类型方法表的地址。在如下所示的代码片段中,我们在输出foobarclass对象的内存字节序列后,我们进一步获得了foobarclass类型的typehandle对象,该对象的value属性返回的就是方法表地址。我们调用上面定义的asstring扩展方法将其转换成格式化字符串后输出到控制台上。
[8][ff-00-00-00]-[ff-ff-00-00] [24][00-00-00-00-00-00-00-00]-[38-39-78-b3-fd-7f-00-00]-[ff-ff-00-00-ff-00-00-00]
从如下所示的输出结果可以看出,实例内存字节承载的和typehandle提供的方法表地址是一致的。
[24]00-00-00-00-00-00-00-00-38-37-78-b3-fd-7f-00-00-ff-ff-00-00-ff-00-00-00
[typehandle]38-37-78-b3-fd-7f-00-00
四、object header的内存布局
我看到一些文档将object header命名为syncblock index/number,这种命名不能算错,但至少没有完整地体现object header的作用以及存储方式。当我们对某个对象加锁的时候,系统会使用一个名为syncblock的内部数据结果与之关联,syncblock中会包含当前线程id和递归等级等信息。这样的syncblock被保存在一个syncblock table中,它在这个表中的索引会存储在object header。
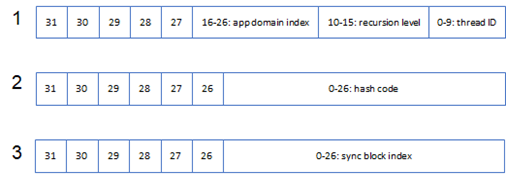
实际上syncblock index只体现了object header只体现了object header的一种使用场景而已。这种将syncblock index存储在object header中实现的锁被称为 “胖锁(fat lock)” ,既然有胖锁,自然就有瘦锁(thin lock),瘦锁直接将同步信息存储在object header中。由于不需要访问syncblock table,瘦锁的性能要高很多。除了用于存储同步信息,object header还可以用来缓存对象的hash码。上图体现了object header典型的三种存储场景:
- 瘦锁:使用object header的低27位存储当前appdomain索引(16-26)、锁的递归等级(10-15)和线程id(0-9);
- 哈希码:使用object header的低26位存储对象的哈希码;
- syncblock index: 使用object header的低26位存储关联的syncblock 在syncblock table的索引。
为了确定object header存储的内容,它的高5位被预留了下来,它们分别表示:
- 27-bit_sblk_is_hash_or_syncblkindex:确定存储的内容是否是哈希或者syncblock index;
- 28-bit_sblk_spin_lock:clr使用它以原子操作的方式修改object header的内容;
- 29- bit_sblk_gc_reserve :gc在执行过程中用于标记对象是否被固定(pined)
- 30- bit_sblk_finalizer_run:gc用于确定对象的析构函数是否被调用;
- 31- bit_sblk_agile_in_progress:在debug build下被用来确定两个跨appdomain应用的对象之间是否存在死循环。
对于上图中的第2/3中存储场景下,由于bit_sblk_is_hash_or_syncblkindex只能确定承载的内容是否是哈希码还是syncblock index,我们还得使用第26位(0-base)作进一步区分。这个比特被称为bit_sblk_is_hashcode,顾名思义,它表示承载得内容是否是对象得哈希码。
五、存储“瘦锁”
在了解了object header的字节布局后,我们利用我们定义的方法将对象的object header的内容读取出来,看看它的内容是否与描述的一致。我们先来看看基于“瘦锁”的存储方式。
await task.yield();
printthreadid();
var foobar = new foobar();
lock (foobar)
{
bytesprinter.printbytes(foobar);
lock (foobar)
{
bytesprinter.printbytes(foobar);
lock (foobar)
{
bytesprinter.printbytes(foobar);
debugger.break();
}
}
}
static void printthreadid()
{
var bytes = bitconverter.getbytes(environment.currentmanagedthreadid);
console.writeline($"thread id: {bitconverter.tostring(bytes)}");
}
public class foobar{}在如下所示的演示程序中,我们定义了一个“空”的类foobar。await task.yield()之后的操作将以异步的方式执行,为了确定object header中是否包含当前线程的id,我们将线程id以16进制的形式输出到控制台上。然后我们创建了一个foobar对象,然后嵌套的方式锁定它,并在锁定上下文中将改对象的内存字节输出来。
thread id: 06-00-00-00
[24]00-00-00-00-06-00-00-00-10-02-66-4c-fa-7f-00-00-00-00-00-00-00-00-00-00
[24]00-00-00-00-06-04-00-00-10-02-66-4c-fa-7f-00-00-00-00-00-00-00-00-00-00
[24]00-00-00-00-06-08-00-00-10-02-66-4c-fa-7f-00-00-00-00-00-00-00-00-00-00
如下所示的程序运行后在控制台上的输出,我们可以看到当前线程id是6(采用小端字节序)。按照我们上面介绍的内存布局,0-9这10位用来表示线程,由于三次输出都是在同一个线程中进行的,所以这10位比特(红色)是一致的(0000000110),对应的值位6,刚好是当前线程id。10-15这6位(紫色)表示递归等级,解析出来值分别是0,1和2,与我们的程序正好吻合。
[0000 0][000 0000 0000] [0000 00][00 0000 0110]
[0000 0][000 0000 0000] [0000 01][00 0000 0110]
[0000 0][000 0000 0000] [0000 10][00 0000 0110]
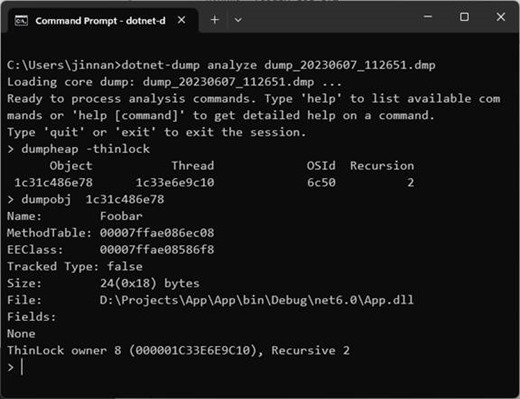
我们在最里层的lock语句中调用了debugger的break方法,所以程序会在这里停下来。如果此时我们将当前进程的dump抓下来,通过执行dumpheap -thinlock命令会将所有“瘦锁”列出来,从输出的嵌套等级(2)和dumpobj的显式结果可以看出这个瘦锁就是foobar对象。
六、存储哈希码
我们接下来采用类似的方式演示object header针对哈希码的缓存。如下面的代码片段所示,我们创建了上面定义的foobar对象,在将其内存字节打印出来之前,我们先将其gethashcode方法返回的哈希码打印来。
var foobar = new foobar();
var hashcode = foobar.gethashcode();
printhashcode(hashcode);
bytesprinter.printbytes(foobar);
static void printhashcode(int hashcode)
{
var bytes = bitconverter.getbytes(hashcode);
console.writeline($"hash code: {bitconverter.tostring(bytes)}");
}从下面的输出可以看出整个object header的内容应该和哈希码是有关系,因为至少可以看到前面3个字节内容(9d-0d-3c)的完全一致的,但是为什么最后一个字节不同呢?
hash code: 9d-0d-3c-03
[24]00-00-00-00-9d-0d-3c-0f-10-86-78-e0-fa-7f-00-00-00-00-00-00-00-00-00-00
再次回到上面的描述,在第二种用于存储哈希码的场景中,object header利用低26位来存储哈希,所以我们按照如下的方式将其低26位提取出来后就会发现对应的值就是哈希码。在看前面的6位,bit_sblk_is_hash_or_syncblkindex和bit_sblk_is_hashcode位均为1,这样就可以确定后26位存储的就是哈希码了。
0f 3c 0d 9d
00001111 00111100 00001101 10011101
00000011 00111100 00001101 10011101
03 3c 0d 9d
由于object类型的gethashcode方法的返回类型为int32,如果我们重写了这个方法,就可能导致objectheader无法使用26位来存放哈希值。比如我们将重写了演示实例所用的foobar类型,让重写的gethashcode返回int32.maxvalue。
public class foobar
{
public override int gethashcode() => int.maxvalue;
}很显然foobar对象的哈希码就无法存储在object header中,如下的输出体现了这一点。其实不管计算出来的哈希码能否使用26个比特来表示,只要类型重写了gethashcode方法且没有直接返回base.gethashcode(),使用object header来缓存哈希码的策略就会失效。这一点告诉我们:当我们需要试图去重写某个类的gethashcode方法,先考虑一下这个类型是否应该定义成结构体。
hash code: ff-ff-ff-7f
[24]00-00-00-00-00-00-00-00-70-27-7a-e0-fa-7f-00-00-00-00-00-00-00-00-00-00
七、存储syncblock index
我们使用如下的代码来演示object header针对syncblock index的存储。在将foobar对象创建出来后,我们先调用其gethashcode方法,并在针对该对象的lock上下文中完成针对内存字节的输出。
var foobar = new foobar();
foobar.gethashcode();
lock (foobar)
{
bytesprinter.printbytes(foobar);
debugger.break();
}
public class foobar{}如下所示的是程序运行后的输出结果,红色标注的正是存储syncblock index的object header的内容。
[24]00-00-00-00-0f-00-00-08-20-bd-87-e0-fa-7f-00-00-00-00-00-00-00-00-00-00
我们按照与上面一样的方式将这4个字节转换成二进制,可以确定bit_sblk_is_hash_or_syncblkindex和bit_sblk_is_hashcode位分别为1和0,所以可以确定低26位存储的就是syncblock index,对应的值位15(0b111)。
08 00 00 0f
00001000 00000000 00000000 00001111
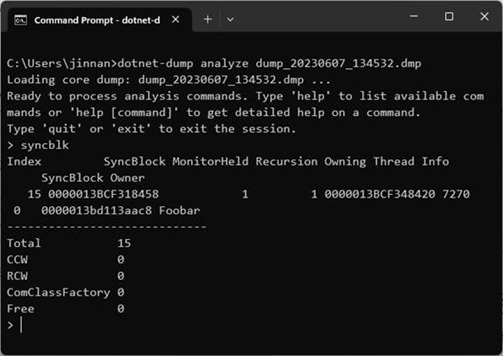
我们在lock上下文中同样调用了debugger的break方法,所以程序会在这里停下来。如果此时我们将当前进程的dump抓下来,通过执行syncblk将正在被使用的syncblock显式出来,唯一的那个的index正是15。
到此这篇关于如何将一个实例的内存二进制内容读出来的文章就介绍到这了,更多相关内存二进制内容读出来内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论