前一段时间有网友问excel转pdf怎么转pdf,小编帮他实现了一个,方法是使用epplus和pdfsharp组件实现,由于依赖officeopenxml他也没有用上,后来小编又实现了二种不依赖officeopenxml的方法。本文将介绍这三种方法实现excel转pdf。
一、epplus和pdfsharp组件实现
逻辑是先将excel内容转换为html字符串,然后再将html字符串转换为pdf文件。转换过程中的格式和样式可能会有一些差异,您可能需要根据需求进行进一步的调整和优化。
使用方法
1、首先使用“nuget 包管理器”安装epplus和pdfsharp
2、在代码页面引用
using ironpdf; using officeopenxml;
3、建两个方法convertexceltopdf和exceltohtml
convertexceltopdf方法用于将excel文件转换为pdf文件,exceltohtml这个方法将excel工作表的内容转换为html字符串。代码如下:
public static void convertexceltopdf(string excelfilepath, string pdffilepath)
{
// 读取excel文件
using (excelpackage package = new excelpackage(new fileinfo(excelfilepath)))
{
excelpackage.licensecontext = licensecontext.noncommercial;
excelworksheet worksheet = package.workbook.worksheets[0]; // 假设要转换的工作表是第一个工作表
// 创建一个html字符串,将excel内容转换为html
string htmlcontent = exceltohtml(worksheet);
// 使用ironpdf将html字符串转换为pdf
var renderer = new htmltopdf();
renderer.printoptions.margintop = 0;
renderer.printoptions.marginbottom = 0;
renderer.printoptions.marginleft = 0;
renderer.printoptions.marginright = 0;
var pdf = renderer.renderhtmlaspdf(htmlcontent);
// 保存pdf文件
pdf.saveas(pdffilepath);
}
}
public static string exceltohtml(excelworksheet worksheet)
{
var sb = new stringbuilder();
sb.appendline("<table>");
var startrow = worksheet.dimension.start.row;
var endrow = worksheet.dimension.end.row;
var startcolumn = worksheet.dimension.start.column;
var endcolumn = worksheet.dimension.end.column;
for (int row = startrow; row <= endrow; row++)
{
sb.appendline("<tr>");
for (int col = startcolumn; col <= endcolumn; col++)
{
var cellvalue = worksheet.cells[row, col].value;
sb.appendline("<td>" + (cellvalue != null ? cellvalue.tostring() : "") + "</td>");
}
sb.appendline("</tr>");
}
sb.appendline("</table>");
return sb.tostring();
}
//调用方法
string excelfilepath = "c:\\users\\user\\desktop\\test.xlsx";
string pdffilepath = "c:\\users\\user\\desktop\\test.pdf";
exceltopdf.convertexceltopdf(excelfilepath, pdffilepath);
主要有两个方法:
convertexceltopdf: 这个方法用于将excel文件转换为pdf文件。它首先使用excelpackage类从excel文件中读取数据。然后,调用exceltohtml方法将excel内容转换为html字符串。接下来,使用ironpdf库中的htmltopdf类将html字符串转换为pdf对象。最后,将pdf对象保存到指定的pdf文件路径中。
exceltohtml: 这个方法将excel工作表的内容转换为html字符串。它使用stringbuilder来构建html字符串。首先,它添加
标签作为表格的开始。然后,通过遍历工作表的行和列,将每个单元格的值添加到html字符串中作为一个td元素。最后,添加table标签作为表格的结束,并将构建好的html字符串返回。
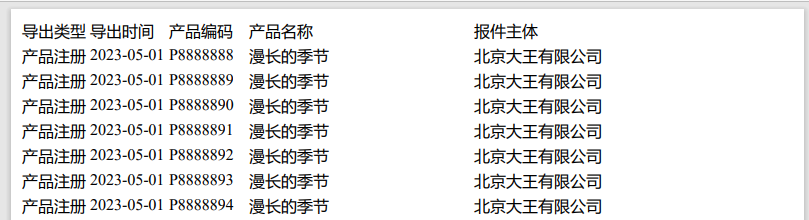
缺点:此方法可能需要依赖office,网友回复反馈;另外需要用html进行格式处理,也是个麻烦事情。
效果:
二、spire组件实现
逻辑是首先使用spire.xls库加载excel文件,并使用spire.pdf库创建pdf文档。然后,我们遍历excel文件的每个工作表,将表格内容逐个绘制到pdf页面上。
使用方法
1、首先使用“nuget 包管理器”安装spire。注意的是需要安装spire,不要安装spire.xls和spire.pdf否则会出现不兼容的问题。
2、在代码页面引用
using spire.pdf; using spire.pdf.graphics; using spire.xls;
3、只需要建一个方法convertexceltopdf。传入要转换的excel路径和输出的路径,代码如下:
public static void convertexceltopdf(string excelfilepath, string pdffilepath)
{
// 加载excel文件
workbook workbook = new workbook();
workbook.loadfromfile(excelfilepath);
// 创建pdf文档
pdfdocument pdfdocument = new pdfdocument();
// 添加excel表格内容到pdf
foreach (worksheet sheet in workbook.worksheets)
{
pdfpagebase pdfpage = pdfdocument.pages.add();
pdfdocument document = new pdfdocument();
pdftruetypefont fonts = new pdftruetypefont(@"c:\windows\fonts\simfang.ttf", 10f);
// 获取excel表格的行数和列数
int rowcount = sheet.lastrow + 1;
int columncount = sheet.lastcolumn + 1;
// 将excel表格内容逐个添加到pdf
for (int row = 1; row <= rowcount; row++)
{
for (int column = 1; column <= columncount; column++)
{
string value = sheet.range[row, column].text;
if (value != null)
// 绘制单元格内容到pdf页面
{
pdfpage.canvas.drawstring(value, fonts, pdfbrushes.black, column * 70, row * 20);
}
}
}
}
// 保存pdf文件
pdfdocument.savetofile(pdffilepath);
console.writeline("pdf转换完成。");
}
//调用方法跟上面一样
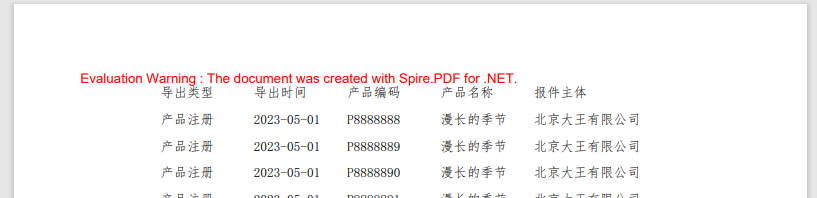
此方法需要注意的是spire默认不支持中文,需要我们单独引用中文字库,在代码的13行就是引用字库的地方,大家可以把字库拷贝到自己的项目引用。
缺点:默认不支持中文字库,需要单独引用;另外输出格式不带表格(可能可以调);免费版本有水印,这个网上有解决方案,大家可以去搜索。
效果如下:
三、npoi和itextsharp组件实现
逻辑是通过使用npoi库读取excel文件,然后使用itextsharp库创建pdf文档。
使用方法
1、首先使用“nuget 包管理器”安装npoi和itextsharp。
2、在代码页面引用
using npoi.ss.usermodel; using npoi.xssf.usermodel; using itextsharp.text; using itextsharp.text.pdf;
3、需要建二个方法,convertexceltopdf和getchinesefont方法,getchinesefont主要作业是字符格式转换。convertexceltopdf传入要转的excel路径和输出的路径,代码如下:
public static void convertexceltopdf2(string excelfilepath, string pdffilepath)
{
encoding.registerprovider(codepagesencodingprovider.instance);
// 加载excel文件
using (filestream filestream = new filestream(excelfilepath, filemode.open, fileaccess.read))
{
iworkbook workbook = new xssfworkbook(filestream);
isheet sheet = workbook.getsheetat(0);
// 创建pdf文档
document document = new document();
// 创建pdf写入器
pdfwriter writer = pdfwriter.getinstance(document, new filestream(pdffilepath, filemode.create));
// 打开pdf文档
document.open();
// 添加excel表格内容到pdf
pdfptable table = new pdfptable(sheet.getrow(0).lastcellnum);
table.widthpercentage = 100;
foreach (irow row in sheet)
{
foreach (icell cell in row)
{
string value = cell.tostring();
pdfpcell pdfcell = new pdfpcell(new phrase(value, getchinesefont()));
table.addcell(pdfcell);
}
}
document.add(table);
// 关闭pdf文档
document.close();
}
console.writeline("pdf转换完成。");
}
static font getchinesefont()
{
var basefont = basefont.createfont(@"c:\windows\fonts\simfang.ttf", basefont.identity_h, basefont.embedded);
return new font(basefont, 12);
}
//调用方法跟方法一一样
//欢迎关注公众号:dotnet开发跳槽,领取海量面试题。加微信号xbhpnet入群交流
此方法跟spire一样默认不支持中文,需要我们单独引用中文字库,方法getchinesefont就是处理引用中文字库。另外需要需要在 nuget 里添加 system.text.encoding.codepages并注册,否则会报错,注册如下。
encoding.registerprovider(codepagesencodingprovider.instance);
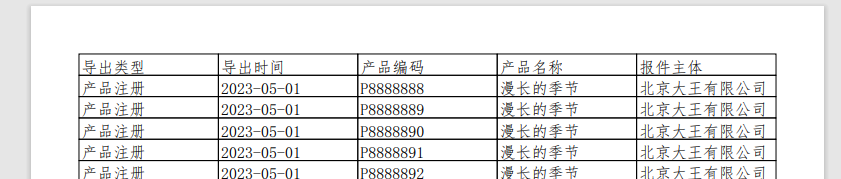
缺点:此方法也比较坑,不支持中文,还需要引用额外的字库支持组件codepages。
效果如下:
结语
本文介绍了.net三种方法实现excel转pdf,他们各有优点,第一种可以自定义样式,第二种依赖独立组件,第三种显示效果更佳,从使用效果来看小编推荐第三种。其实还有很多组件实现excel转pdf,比如aspose.cells,有的需要授权收取费用、大家自己可以研究一下。本项目是基于.net7在windows下测试运行,在linux下没有实验过,大家可以尝试一下。
到此这篇关于.net轻松实现excel转pdf的三种方法详解的文章就介绍到这了,更多相关.net excel转pdf内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论