场景
当我们需要存入一个string类型的键值对到redis中,如下:
(缓存接口)
public interface cacheservice {
/**
* 添加一个字符串键值对
* @param key 键
* @param value 值
*/
void setstring(string key, string value);
}
(redis实现)
import com.hezy.service.cacheservice;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.data.redis.core.redistemplate;
import org.springframework.stereotype.service;
@service
public class redisserviceimpl implements cacheservice {
@autowired
private redistemplate<string, string> redistemplate;
@override
public void setstring(string key, string value) {
redistemplate.opsforvalue().set(key, value);
}
}
(使用)
import com.hezy.service.impl.redisserviceimpl;
import org.junit.jupiter.api.test;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.boot.test.context.springboottest;
@springboottest
public class redisserviceimpltest {
@autowired
private redisserviceimpl redisservice;
@test
public void test1() {
string key = "content";
string value = "这是一段分非常大非常大的字符串…………………………非常大";
redisservice.setstring(key, value);
}
}
(查看redis)
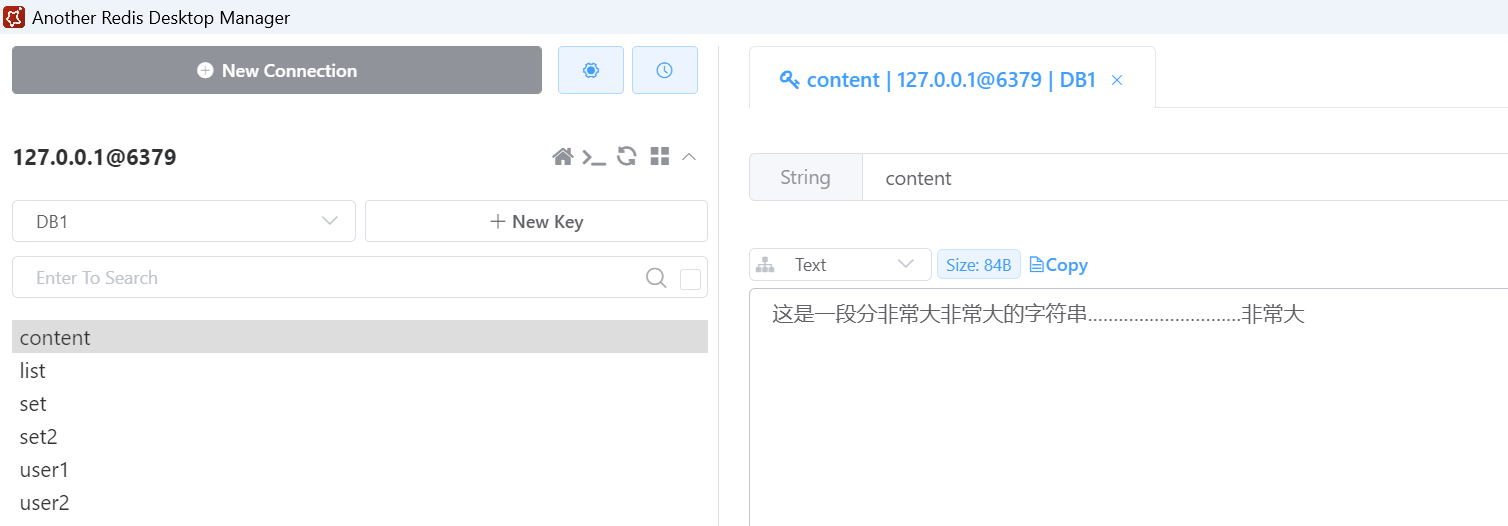
有时候,我们存入的字符串可能过长,过大,有可能来自于一个大对象的序列化。这时候存入的key-value,会造成value过大,会触发一些预警。
可以采用我下面这种分段存储的方法。
优化
思路:将字符串分段,每一段生成一个key,然后将这些分段key再用redis的list类型存储;获取时就先获取这些分段key,再循环去get对应的字符串,拼接起来就是完整的字符串。
如下:分段存,增加一个参数,设置每段字符串的长度
(缓存接口)
/**
* 分段存储
* @param key 键
* @param value 值
* @param chunksize 每个分段大小
*/
void setstrsub(string key, string value, int chunksize);
(redis实现)
@override
public void setstrsub(string key, string value, int chunksize) {
// 将value,按照length,分成多个部分
int totalchunks = (int) math.ceil((double) value.length() / chunksize);
// 定义一个分段数据key集合
list<string> subkeys = new arraylist<>(totalchunks);
// 将字符串分成多段
for (int i = 0; i < totalchunks; i++) {
// 计算分段起止位置
int startindex = i * chunksize;
int endindex = math.min(startindex + chunksize, value.length());
// 获取对应分段数据
string chunkvalue = value.substring(startindex, endindex);
// 拼接分段key
string subkey = key + "_" + i;
// 存储分段数据
setstring(subkey, chunkvalue);
// 将分段key添加到集合
subkeys.add(subkey);
}
// 分段key添加到集合
setlist(key, subkeys);
}
(添加一个集合到redis)
@override
public void setlist(string key, list value) {
redistemplate.opsforlist().rightpushall(key, value);
}
启动,测试
@test
public void test2() {
string key = "content";
string value = "这是一段分非常大非常大的字符串…………………………非常大";
redisservice.setstrsub(key, value, 5);
}
查看redis
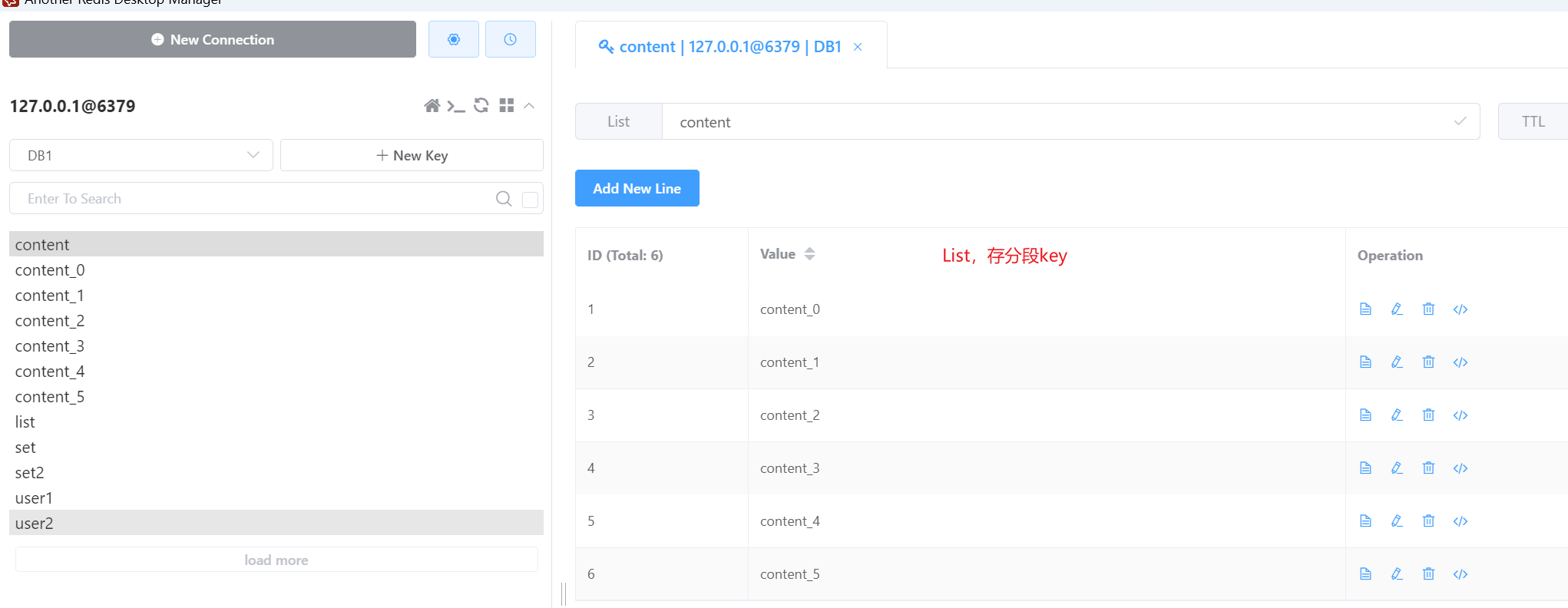
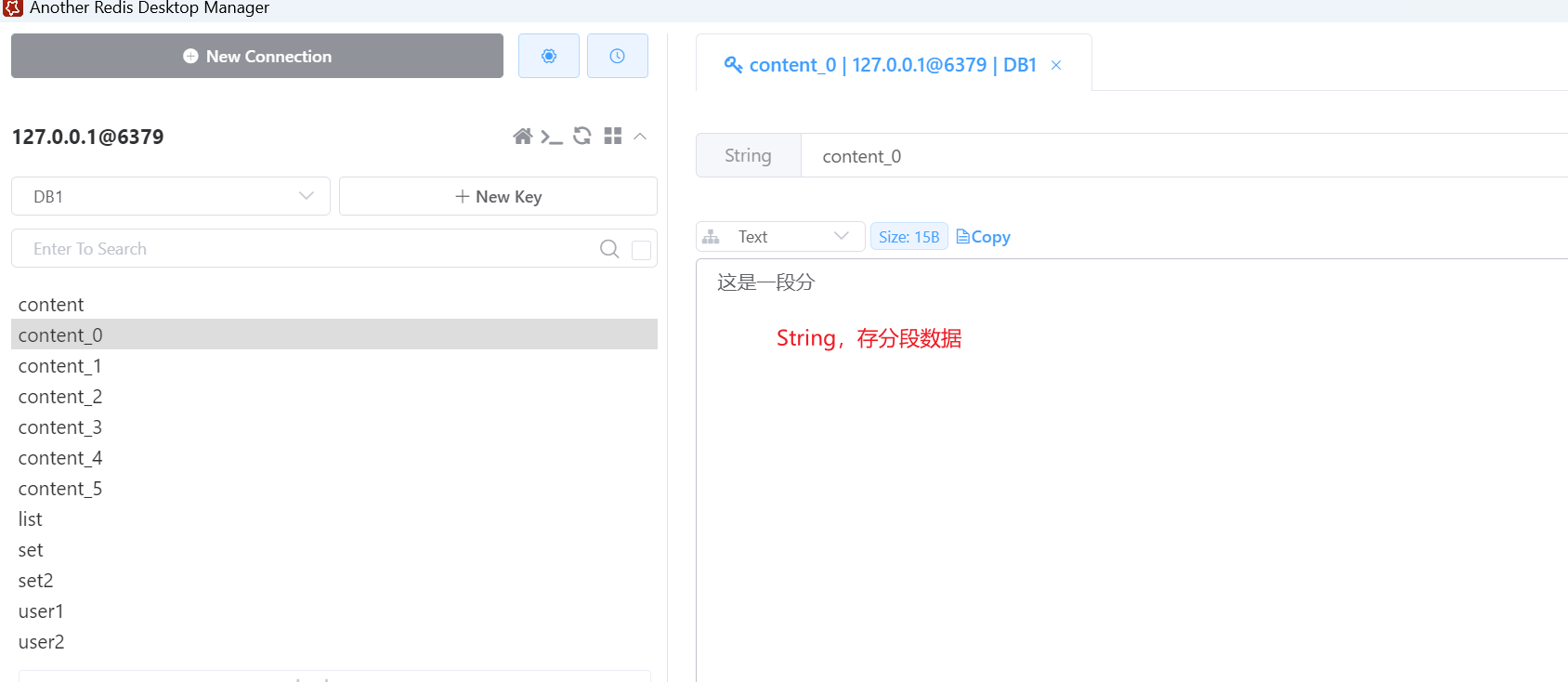
然后,要取数据,也很简单;
(缓存接口)
/**
* 获取字符串(分段)
* @param key
* @return
*/
string getstrsub(string key);
(redis实现)
@override
public string getstrsub(string key) {
// 先把分段key获取出来
list<string> list = getlist(key);
// 字符串拼接,用stringbuilder,线程安全
stringbuilder stringbuilder = new stringbuilder();
for (string subkey : list) {
string subvalue = getstring(subkey);
// 这里要跳过null,不然最后输出会把null转为字符串
if (subvalue == null) {
continue;
}
stringbuilder.append(subvalue);
}
// 如果没有数据,返回null
return "".contentequals(stringbuilder) ? null : stringbuilder.tostring();
}
(redis获取一个list)
@override
public list getlist(string key) {
return redistemplate.opsforlist().range(key, 0, -1);
}
(使用)
@test
public void test3() {
string content = redisservice.getstrsub("content");
system.out.println(content);
}
(打印)

总结
本文介绍了redis分段存储一个大键值对(string)的一种方式,看下来,实现并不复杂。使用上也可以很方便,可以考虑把分段的存取和普通的存取都兼容起来,这样对于使用者,只需要加一个参数(分段大小)。
到此这篇关于分段存储redis键值对的方法详解的文章就介绍到这了,更多相关redis键值对分段存储内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!


发表评论