简介
商品超卖现象,即销售数量超过了实际库存量,通常是由于未能正确判断库存状况而发生的。在常规的库存管理系统中,我们会在扣减库存之前进行库存充足性检验:仅当库存数量大于零时,系统才会执行扣减动作;若库存不足,则即时返回错误提示。然而,在高并发的销售场景下,传统的处理方法往往难以确保库存扣减的准确性。为了解决这一问题,我们可以采用线程加锁机制或利用redis等内存数据结构来同步库存状态,从而保证即使在大量同时交易的情况下,库存扣减也能保持准确无误。
数据库校验
商品类
/**
* @description 商品类
* @author yiridancan
* @date 2024/3/23 9:06
*/
public class goods {
private int id;
/**
* 商品名称
*/
private string name;
/**
* 库存数量
*/
private int inventorycount;
public int getid() {
return id;
}
public void setid(int id) {
this.id = id;
}
public string getname() {
return name;
}
public void setname(string name) {
this.name = name;
}
public int getinventorycount() {
return inventorycount;
}
public void setinventorycount(int inventorycount) {
this.inventorycount = inventorycount;
}
}
实现类
import com.yiridancan.reduceinventory.entity.goods;
import com.yiridancan.reduceinventory.mapper.goodsmapper;
import com.yiridancan.reduceinventory.service.igoodsservice;
import lombok.extern.slf4j.slf4j;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.stereotype.service;
import java.util.objects;
/**
* 商品实现类
* @author yiridancan
* @date 2024/3/23 18:35
*/
@slf4j
@service
public class goodsserviceimpl implements igoodsservice {
@autowired
private goodsmapper goodsmapper;
/**
* 扣减库存
* @param goodsid 商品id
* @author yiridancan
* @date 2024/3/23 18:33
*/
@override
public void reduceinventory(int goodsid) {
//1.根据商品id获取商品库存数量
goods goods = goodsmapper.findgoodsinventory(goodsid);
if(objects.isnull(goods)){
log.error("未获取到商品信息");
return;
}
//2.如果库存数量大于0则扣减库存,如果等于0代表没有货物打印错误信息
if(goods.getinventorycount() > 0 ){
//默认扣减库存1
goods.setinventorycount(goods.getinventorycount()-1);
goodsmapper.updategoodsinventory(goods);
log.info("{}扣减库存成功,扣减后库存为:{}",goods.getname(),goods.getinventorycount());
}else {
log.error("{}库存为0",goods.getname());
}
}
}
首先,我们需要根据商品id获取商品数据。如果无法获取到数据,则打印异常并终止执行。接着,通过查询库存数量进行校验判断:若库存大于0,则扣减库存;反之,若库存为0,则打印异常信息。
数据库
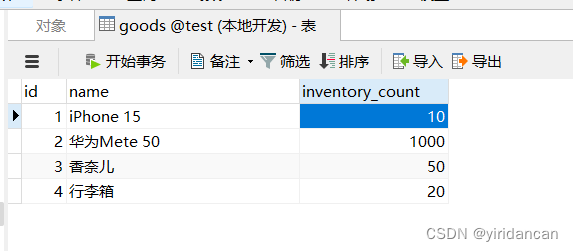
测试代码
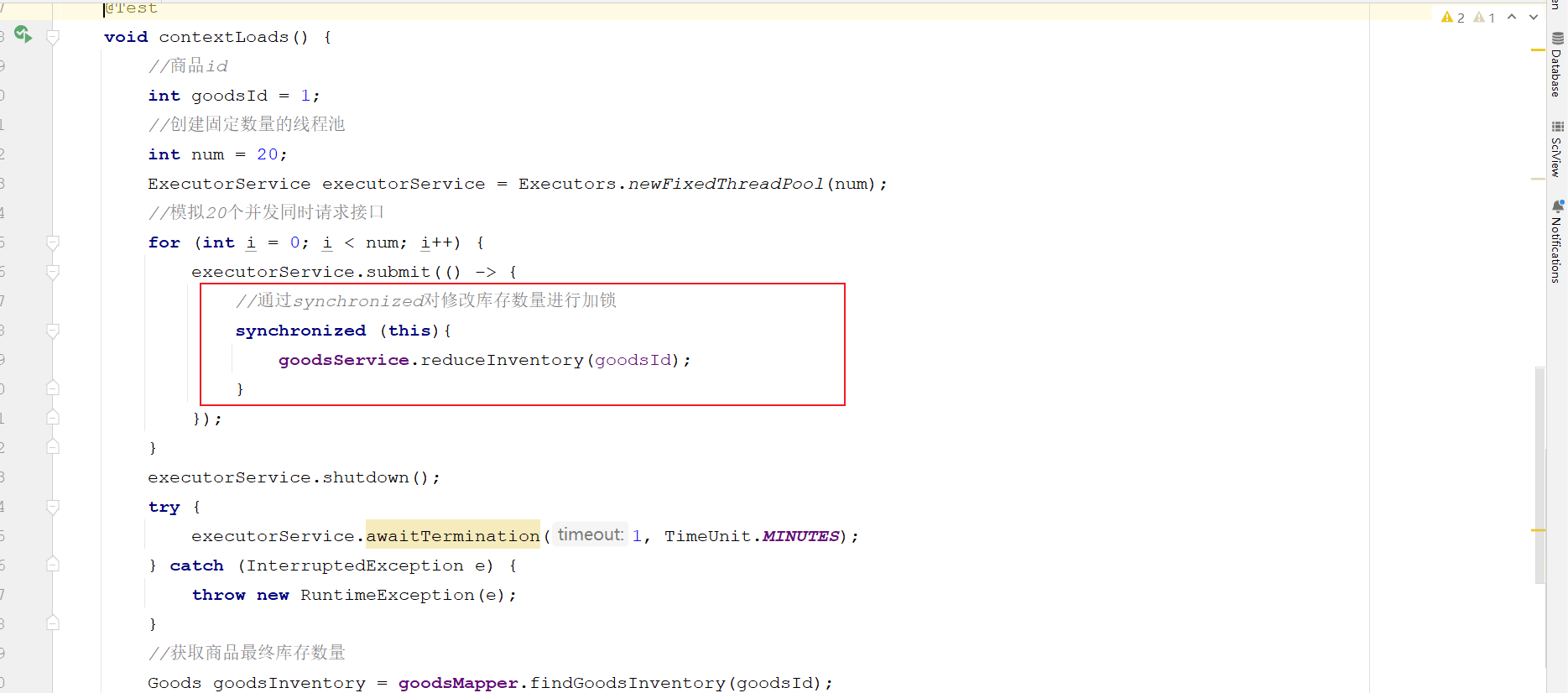
@test
void contextloads() {
//商品id
int goodsid = 1;
//创建固定数量的线程池
int num = 20;
executorservice executorservice = executors.newfixedthreadpool(num);
//模拟20个并发同时请求接口
for (int i = 0; i < num; i++) {
executorservice.submit(() -> {
goodsservice.reduceinventory(goodsid);
});
}
executorservice.shutdown();
try {
executorservice.awaittermination(1, timeunit.minutes);
} catch (interruptedexception e) {
throw new runtimeexception(e);
}
//获取商品最终库存数量
goods goodsinventory = goodsmapper.findgoodsinventory(goodsid);
if(objects.isnull(goodsinventory)){
return;
}
log.info("{}商品最终库存为:{}",goodsinventory.getname(),goodsinventory.getinventorycount());
}运行结果
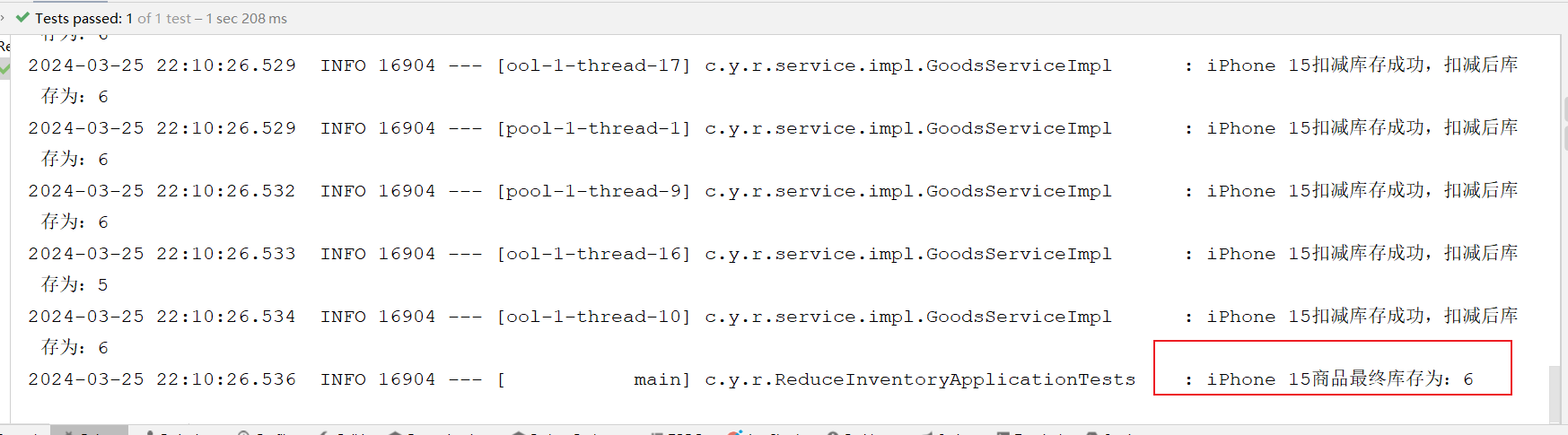
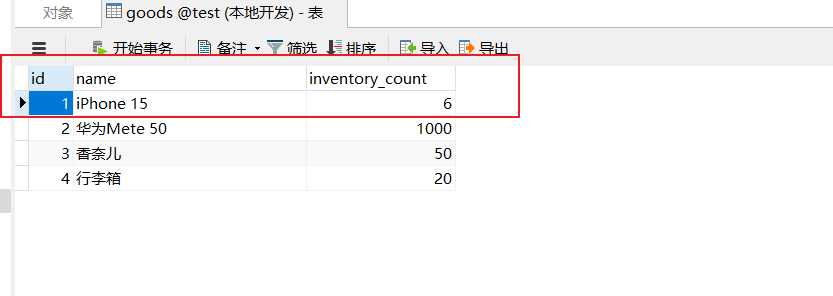
测试中,系统面临了20个同时发出的请求,而可用库存量仅为10个。理论上,这意味着应当有10个请求能够成功完成库存扣减,而另外10个请求则需被妥善拒绝。为解决此并发操作导致的数据不一致性问题,我们可以通过引入锁机制来确保数据访问的同步性,从而保障系统的正确性和稳定性。
悲观锁
可以通过synchronized、reentrantlock等悲观锁来保证原子性和一致性
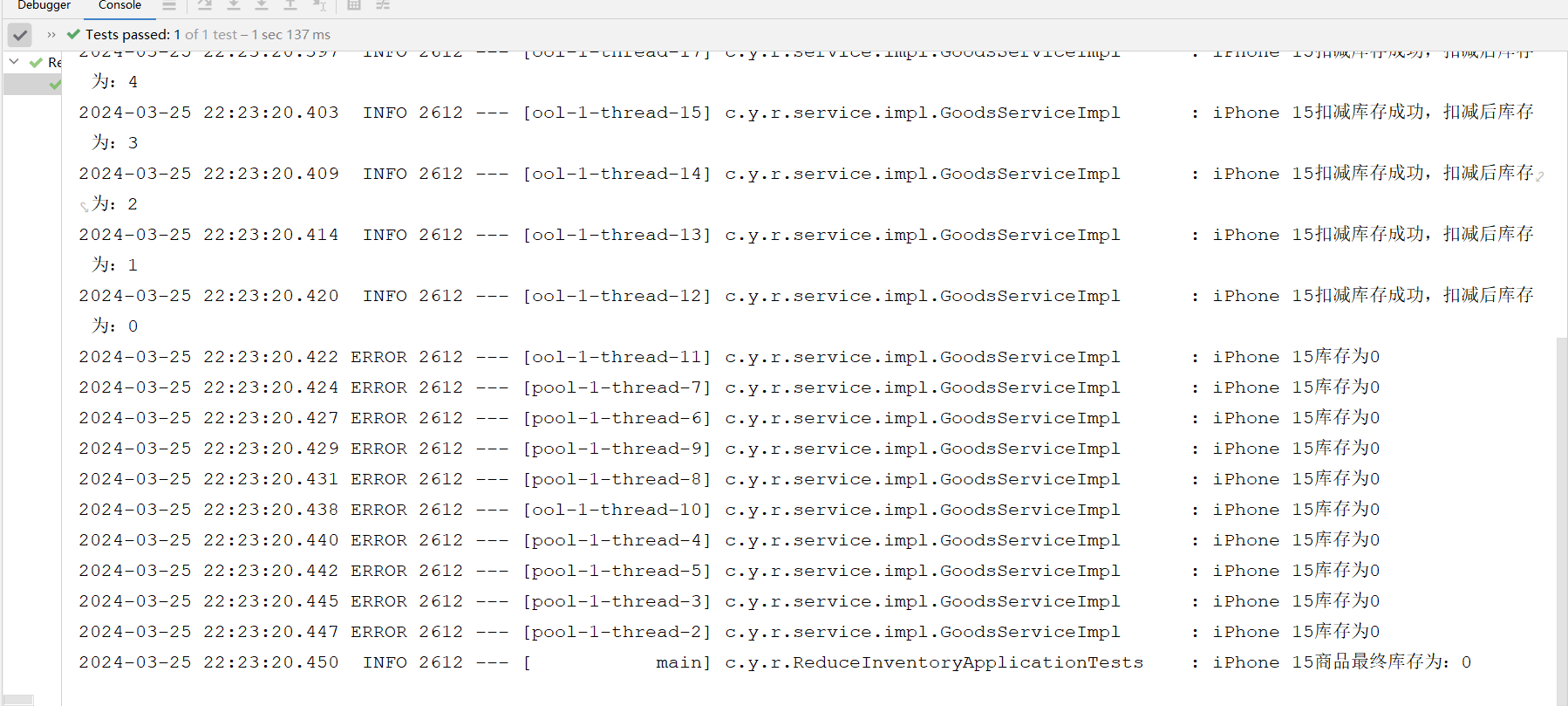
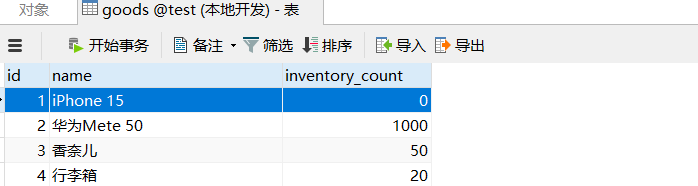
我们发现,在20次并发请求的测试场景中,仅有10次能够成功减少库存量,而另外10次则遭到拒绝。这种机制确保了数据一致性的严密守护。然而,若我们选择采用悲观锁的策略,虽然可以强化数据完整性,但却可能导致大量请求进入阻塞队列,尤其是在高并发的环境下,这种重量级的同步处理可能会对服务性能和数据库响应能力造成显著负担,甚至有可能引发系统瓶颈。因此,在设计高并发系统时,我们需要权衡锁机制的选择,以优化系统性能,保证服务的高效流畅。
乐观锁
乐观锁采用了一种比较宽松的并发控制策略。它允许多个线程同时读取和修改共享数据,但在数据提交时会检查是否有其他线程在此期间修改过相同的数据。如果检测到冲突,通常需要重新尝试操作,直到成功为止。乐观锁的核心在于它认为冲突不太可能发生,或者冲突发生的概率较低,因此不一开始就对数据加锁,从而避免了锁机制可能带来的性能开销。一般通过数据库版本号或者时间戳来进行实现
定义一个抽象接口:
/**
* 通过乐观锁实现扣减库存
* @author yiridancan
* @date 2024/3/25 22:33
* @param goodsid 商品id
*/
void casreduceinventory(int goodsid);实现类:
/**
* 通过乐观锁实现扣减库存
* @param goodsid 商品id
* @author yiridancan
* @date 2024/3/25 22:33
*/
@override
public void casreduceinventory(int goodsid) {
int retrycount = 0;
//重试次数设置为3,避免无休止的重试占用紫鸢
while (retrycount <=3){
//1.根据商品id获取商品信息
goods goods = goodsmapper.findgoodsinventory(goodsid);
if(objects.isnull(goods) || goods.getinventorycount() == 0){
log.error("未获取到商品信息或库存数量不足");
return;
}
//默认扣减库存1
goods.setinventorycount(goods.getinventorycount()-1);
int updaterow = goodsmapper.updategoodsinventorybycas(goods);
//如果修改条数大于0代表扣减库存成功
if(updaterow > 0 ){
log.info("{}扣减库存成功,扣减后库存为:{}",goods.getname(),goods.getinventorycount());
return;
}
retrycount++;
log.error("{}商品被修改过,进行重试!!版本号:{}",goods.getname(),goods.getdataversion());
}
}首先会先定义一个重试次数,避免一直重试占用资源。然后获取到具体的商品信息,默认扣减库存为1(实际可以根据用户设置的数量进行扣减),然后根据查询出来的版本号和id去数据库中更新数据,如果返回更新数量代表扣减库存成功,则打印相关打印进行结束,否则进行重试,直到库存数量不足或扣减库存成功才结束
<update id="updategoodsinventorybycas">
update goods set inventory_count=#{inventorycount},data_version=data_version+1 where id=#{id} and data_version=#{dataversion}
</update>
redis
借助redis单线程的特性,再加上lua脚本执行过程原子性的保障。我们可以在redis中通过lua脚本进行库存扣减操作
因为lua脚本在执行过程中,可以避免被打断,并且redis执行的过程也是单线程的,所以在脚本中进行判断,再扣减,这个过程是可以避免并发的。所以也就可以实现前面我们说的原子性+有序性了。
并且redis是一个高性能的分布式缓存,使用lua脚本扣减库存的方案也非常的高效
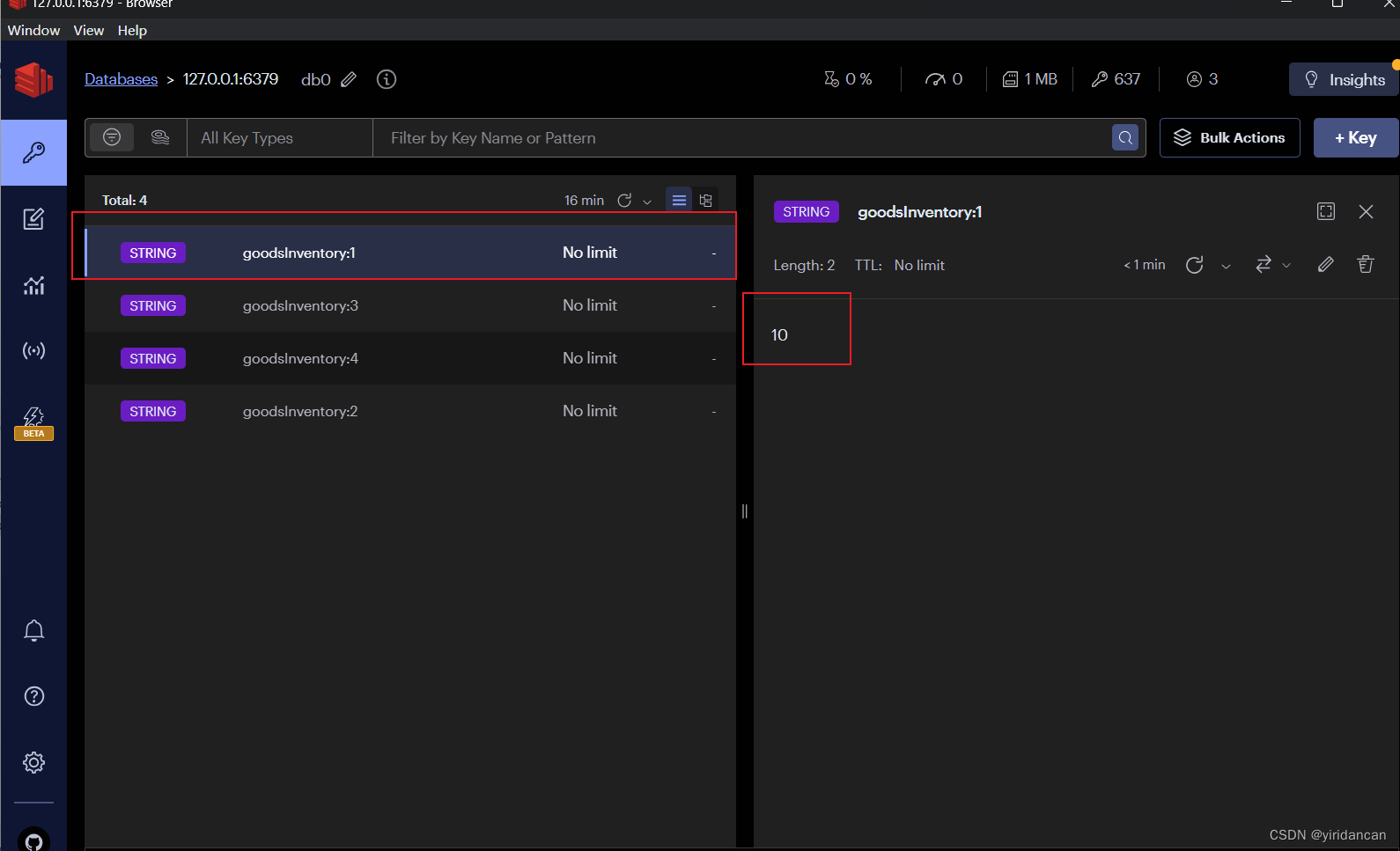
首先将商品库存初始化到redis中,然后后续对redis进行库存扣减
local key = keys[1] -- 商品的键名
local amount = tonumber(argv[1]) -- 扣减的数量
-- 获取商品当前的库存量
local stock = tonumber(redis.call('get', key))
-- 如果库存足够,则减少库存并返回新的库存量
if stock >= amount then
redis.call('decrby', key, amount)
return redis.call('get', key)
else
return "insufficient stock"
end
编写lua脚本,通常是单独放在一个文件中。这里偷了一个懒直接声明成字符串了
/**
* 通过redis扣减库存
*
* @param goodsid 商品id
* @author yiridancan
* @date 2024/3/27 15:48
*/
@override
public void redisreduceinventory(int goodsid) {
string prefix = "goodsinventory:";
//将商品数据缓存到redis中,key是商品id,value是商品库存数量
goodsmapper.findgoodsall().foreach(goods -> {
stringredistemplate.opsforvalue().set(prefix+goods.getid(),string.valueof(goods.getinventorycount()));
});
//lua脚本,一般放在文件中
string script = "local key = keys[1] -- 商品的键名\n" +
"local amount = tonumber(argv[1]) -- 扣减的数量\n" +
"\n" +
"-- 获取商品当前的库存量\n" +
"local stock = tonumber(redis.call('get', key))\n" +
"\n" +
"-- 如果库存足够,则减少库存并返回新的库存量\n" +
"if stock >= amount then\n" +
" redis.call('decrby', key, amount)\n" +
" return redis.call('get', key)\n" +
"else\n" +
" return \"insufficient stock\"\n" +
"end\n";
defaultredisscript<string> redisscript = new defaultredisscript<>(script, string.class);
// 创建一个包含库存key的列表
list<string> keys = collections.singletonlist(prefix + goodsid);
// 创建一个包含扣减数量的参数列表
list<string> args = collections.singletonlist(integer.tostring(1));
// 执行lua脚本,传入键列表和参数列表
string result = stringredistemplate.execute(redisscript, keys, args.toarray(new string[0]));
//如果不是库存不足代表扣减成功
if(!result.equals("insufficient stock")){
log.info("扣减库存成功,库存数量:{}",result);
}else {
log.error("库存数量不足");
}
}首先把商品数据统一缓存到redis中,然后编写一段lua脚本交给defaultredisscript,defaultredisscript可以自定义数据返回类型
创建两个集合,分别存放key和参数,通过stringredistemplate.execute执行lua脚本,如果返回的值是insufficient stock代表库存不足,打印错误日志,否则扣减库存成功
最后在任务执行完成后定时将redis中的库存同步到数据库中做持久化即可
其他方案
- redis+mq+数据库:利用redis来扛高并发流量。先在redis扣减库存,然后发送一个mq消息,消费者在接收到消息后做数据库库存的真正扣减和业务逻辑
把修改转换成新增,直接插入一次占用记录,然后异步统计剩余库存,或者通过sql统计流水方式计算剩余库存
通过redisson进行加锁处理
..............
总结
综合来说,实践中往往会根据业务需求和现有技术栈选择合适的方法,redis因其高性能和原子操作特性,在很多场景下成为首选方案之一。而具体实施时,可能还需要结合多种手段以及负载均衡、熔断、降级等策略来应对复杂的高并发挑战。
到此这篇关于redis高并发场景防止库存数量超卖少卖的文章就介绍到这了,更多相关redis防止超卖少卖内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论