redis使用zset处理排行榜和计数
在处理计数业务时,我们一般会使用一个数据结构,既是集合又可以保证唯一性,所以我们会选择redis中的set集合:
业务逻辑
用户点击点赞按钮,需要再set集合内判断是否已点赞,未点赞则需要将点赞数+1并保存用户信息到集合中,已点赞则需要将数据库点赞数-1并移除set集合中的用户。
@service
public class blogserviceimpl extends serviceimpl<blogmapper, blog> implements iblogservice {
@autowired
private iuserservice userservice;
@resource
private stringredistemplate stringredistemplate;
@override
public result likeblog(long id) {
// 获取登录用户
long userid = userholder.getuser().getid();
// 判断当前登录用户是否已经点赞
string key = "blog:like:" + id;
boolean ismember = stringredistemplate.opsforset().ismember(key, userid.tostring());
if(booleanutil.isfalse(ismember)){
// 未点赞
// 数据库点赞数+1
boolean issuccess = update().setsql("like = like + 1").eq("id",id).update();
// 保存用户到redis集合中
if(issuccess){
stringredistemplate.opsforset().add(key, userid.tostring());
}
} else {
// 已点赞,取消点赞
// 数据库点赞数-1
boolean issuccess = update().setsql("like = like - 1").eq("id",id).update();
// 移除set集合中的用户
stringredistemplate.opsforset().remove(key, userid.tostring());
}
return result.ok();
}
}那么我们想要实现按照点赞时间的先后顺序排序,返回top5的用户,这个时候set无法保证数据有序,所以我们需要换一个数据结构满足业务需求:
redis 的 zset(有序集合) 是一个非常适合用于处理 排行榜 和 计数问题 的数据结构。
在高并发的点赞业务中,使用 zset 可以帮助我们高效地管理点赞的排名,并且由于 zset 的排序特性,我们可以轻松实现根据点赞数实时排序的功能。
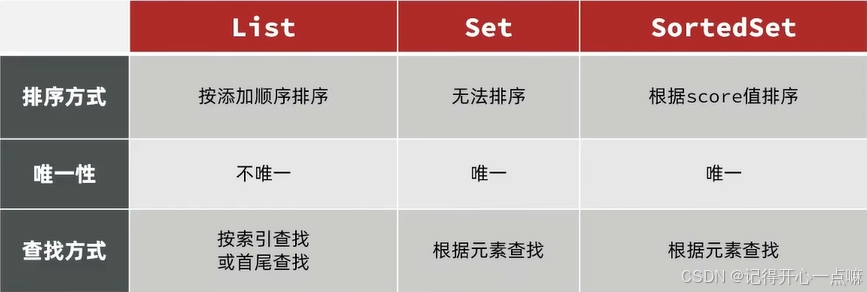
zset 数据结构
redis 的 zset 是一个集合,它的每个元素都会关联一个 分数(score),这个分数决定了元素在集合中的排序。zset 保证集合中的元素是按分数排序的,并且可以在 o(log(n)) 的时间复杂度内进行添加、删除和查找操作。
在高并发的点赞业务中,zset 可以帮助我们轻松地进行以下几项操作:
- 记录每个用户对某个内容(如文章、评论等)的点赞数。
- 通过分数进行实时排序,获取点赞数最多的内容。
优化高并发的点赞操作
在高并发情况下,当多个用户同时对某个内容进行点赞时,我们需要高效地更新该内容的点赞数,并保证数据一致性。zset 提供了很好的支持,具体步骤如下:
- 用户点赞操作:使用
zincrby命令来对某个元素的分数进行增量操作,表示对该内容的点赞数增加。 - 查看点赞数:可以通过
zscore命令获取某个内容的当前点赞数。 - 查看排行榜:使用
zrange或zrevrange命令来获取点赞数排名前 n 的内容,按分数进行排序。
zset 结构设计
key:表示某个内容的点赞的 id。value:表示点赞用户的 id。score:根据点赞时间排序。
下面是修改后的点赞逻辑:
@service
public class blogserviceimpl extends serviceimpl<blogmapper, blog> implements iblogservice {
@autowired
private iuserservice userservice;
@resource
private stringredistemplate stringredistemplate;
@override
public result likeblog(long id) {
// 获取登录用户
long userid = userholder.getuser().getid();
// 判断当前登录用户是否已经点赞
string key = "blog:like:" + id;
double score = stringredistemplate.opsforzset().score(key, userid.tostring());
if(score == null){
// 未点赞
// 数据库点赞数+1
boolean issuccess = update().setsql("like = like + 1").eq("id",id).update();
// 保存用户到redis集合中
if(issuccess){
stringredistemplate.opsforzset().add(key, userid.tostring(), system.currenttimemillis());
}
} else {
// 已点赞,取消点赞
// 数据库点赞数-1
boolean issuccess = update().setsql("like = like - 1").eq("id",id).update();
// 移除set集合中的用户
stringredistemplate.opsforzset().remove(key, userid.tostring());
}
return result.ok();
}
}而点赞排行榜代码如下:
@service
public class blogserviceimpl extends serviceimpl<blogmapper, blog> implements iblogservice {
@autowired
private iuserservice userservice;
@resource
private stringredistemplate stringredistemplate;
@override
public result querybloglikes(long id) {
string key = "blog:like:" + id;
// 查询top5的点赞用户 zrange key 0 4
set<string> top5 = stringredistemplate.opsforzset().range(key, 0, 4);
if (top5 == null || top5.isempty()) {
return result.ok(collections.emptylist());
}
// 解析出集合中的用户的id
list<long> ids = top5.stream().map(long::valueof).collect(collectors.tolist());
// 根据id查询用户,并将类型由user转为userdto,随后转换为list集合
string idstr = strutil.join(",",ids);
// list<userdto> userdtos = userservice.listbyids(ids).stream()
// .map(user -> beanutil.copyproperties(user, userdto.class))
// .collect(collectors.tolist());
list<userdto> userdtos = userservice.query()
.in("id",ids).last("order by field(id," + idstr +")").list()
.stream()
.map(user -> beanutil.copyproperties(user, userdto.class))
.collect(collectors.tolist());
return result.ok(userdtos);
}
}使用
userservice.query().in("id", ids).last("order by field(id," + idstr + ")") 来查询用户信息,并且使用 order by field(id, ...) 语句来保证查询结果的顺序与 top5 中的用户顺序一致。
这里的 order by field(id, ...) 是关键,它确保了从数据库返回的数据顺序和 redis 返回的 top5 用户顺序完全匹配。因为 redis 中的 zset 是有顺序的,top5 会按照点赞数量进行排序。
如果直接使用 listbyids 方法,可能会导致结果顺序不一致。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。



发表评论