引言
在现代微服务架构中,redis被广泛应用于缓存、消息队列及其他场景。为了确保redis集群的高可用性和性能,我们需要实时监控其状态与指标。本文将全面讲解如何通过prometheus监控redis运行的各项指标,让数据实时可知。
1、安装配置redis
1)安装redis
yum install redis -y
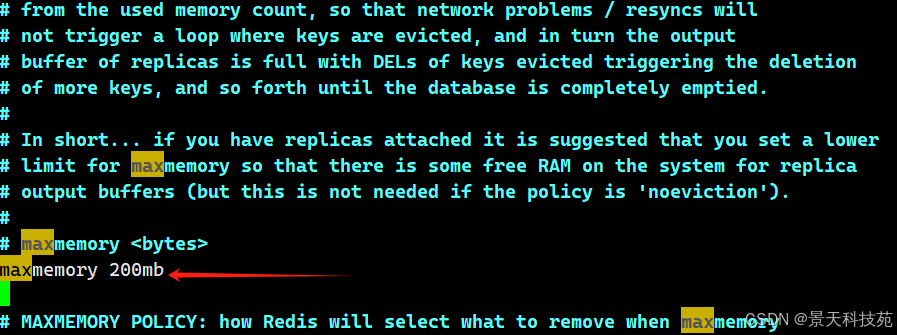
2)调整redis内使用的最大内存
vim /etc/redis/redis.conf maxmemory 200mb
3)启动redis
systemctl start redis
redis本身就有info命令,可以哦查看redis状态,但是并不兼容prometheus的数据格式
因此,需要借助exporter来暴露指标
2、安装配置redis_exporter
1)访问redis_exporter的github地址
https://github.com/oliver006/redis_exporter
下载redis_exporter
直接下载最新版
2)解压redis_exporter
tar xf redis_exporter-v1.67.0.linux-amd64.tar.gz -c /etc/ ln -s /etc/redis_exporter-v1.67.0.linux-amd64/ /etc/redis_exporter
3)配置redis_exporter启动文件
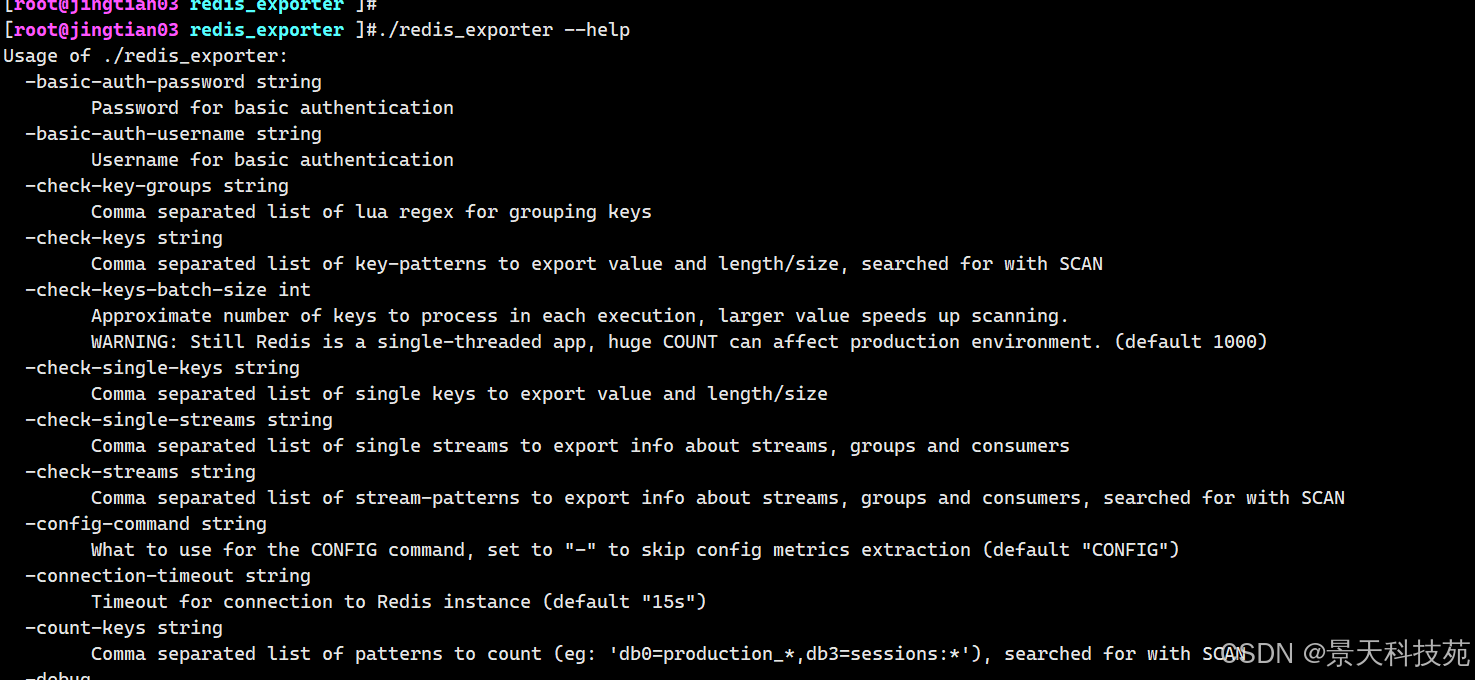
先看下redis_exporter启动参数
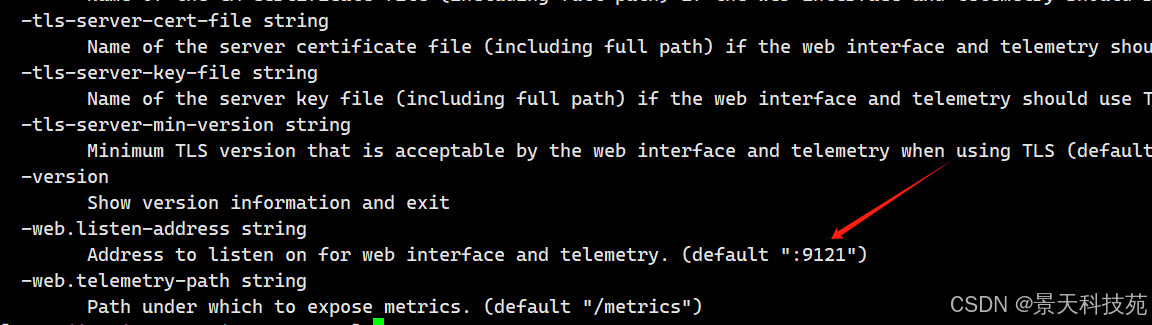
默认监听地址是9121
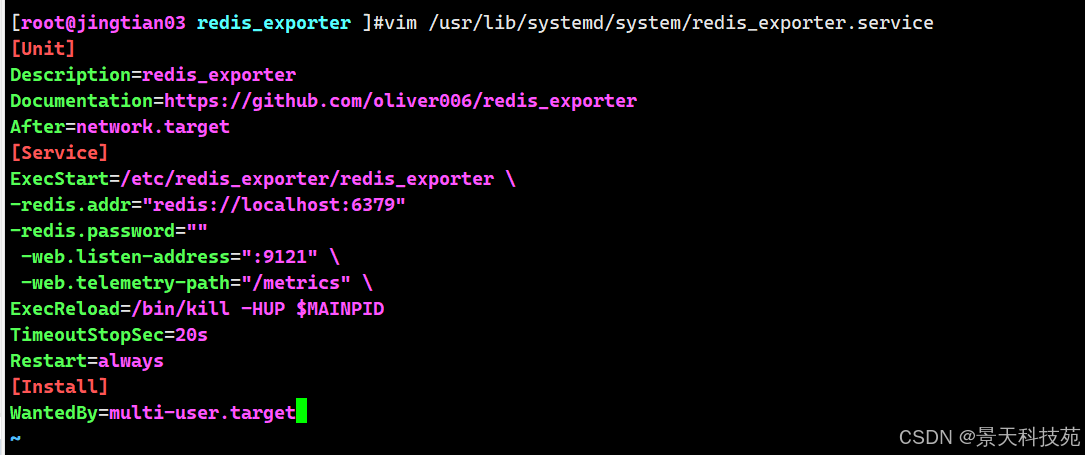
systemd启动配置文件
cat /usr/lib/systemd/system/redis_exporter.service [unit] description=redis_exporter documentation=https://github.com/oliver006/redis_exporter after=network.target [service] execstart=/etc/redis_exporter/redis_exporter \ -redis.addr="redis://localhost:6379" -redis.password="" -web.listen-address=":9121" \ -web.telemetry-path="/metrics" \ execreload=/bin/kill -hup $mainpid timeoutstopsec=20s restart=always [install] wantedby=multi-user.target
4)启动redis_exporter
systemctl enable redis_exporter.service --now
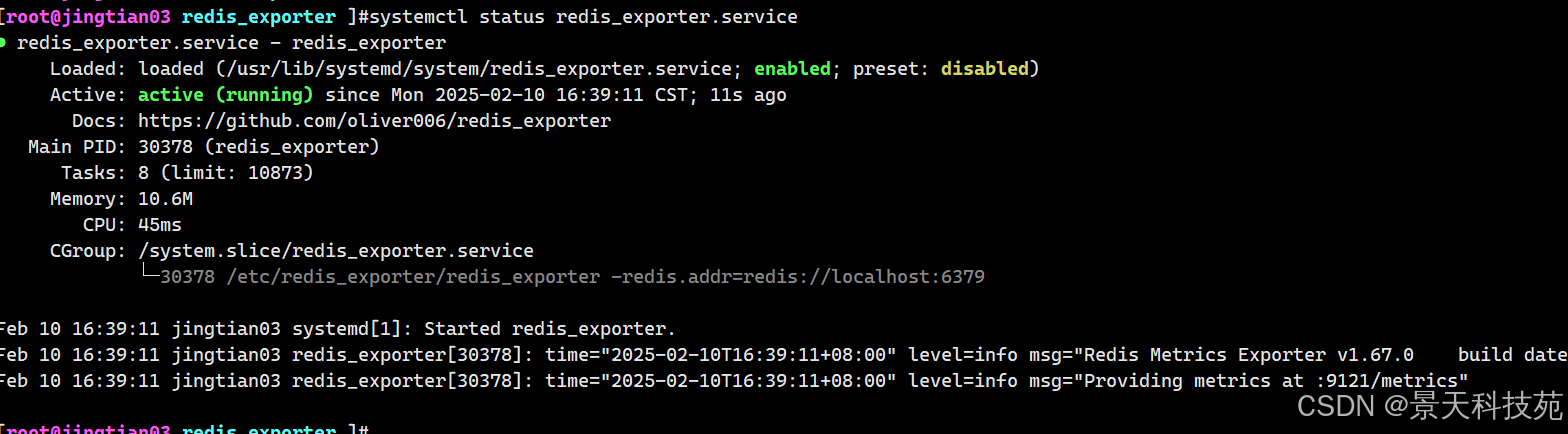
5)访问redis_exporter的metrics
http://10.10.0.32:9121/metrics
3、配置prometheus
1)修改prometheus配置
vim /etc/prometheus/prometheus.yml
- job_name: "redis_exporter"
static_configs:
- targets: ["jingtian03:9121"]
2)加载prometheus配置文件
curl -x post http://localhost:9090/-/reload
3)检查prometheus的status->targets页面
验证 redis_exporter 是否已经成功纳入监控中

查看下指标

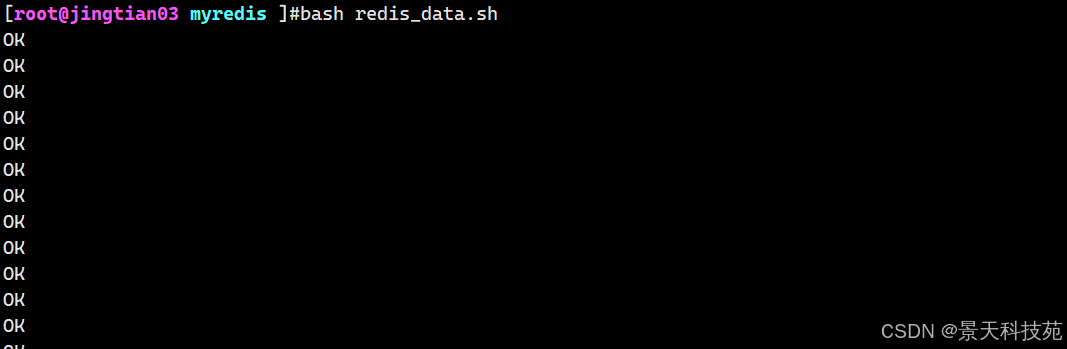
4)模拟产生redis相关数据
执行如下脚本
1、redis向db0库,插入了50个key,然后尝试随机获取100个key。由于总共的key只有50个,因此会有一半查询命中一半miss。
2、redis向db1库,插入了100个key,但有60个key设定了过期时间;
[root@jingtian03 myredis ]#cat redis_data.sh
#!/bin/bash
# 定义redis主机和端口
redis_host=localhost
redis_port=6379
# redis数据库定义
db0=0
db1=1
# 定义key的总数
total_keys=100
# 计算应设置过期时间的键的数量
expiring_keys_count=$(( total_keys * 60 / 100 ))
# 向redis db0插入一半的key
for i in {1..50}
do
key="test-$i"
value="test-$i"
redis-cli -h $redis_host -p $redis_port -n $db0 set $key $value
done
# 随机获取100个key,一部分将获取成功,一部分将miss
for i in {1..100}
do
random_key_index=$(( ( random % total_keys ) + 1 ))
key="test-$random_key_index"
result=$(redis-cli -h $redis_host -p $redis_port -n $db0 get $key)
if [ "$result" == "" ]
then
echo "miss: $key"
else
echo "hit: $key"
fi
done
# 向redis db1插入100个key,其中60%设置过期时间为10分钟
for i in {1..100}
do
key="expire-test-$i"
value="value-$i"
# 对前60%的键设置过期时间
if [ $i -le $expiring_keys_count ]
then
redis-cli -h $redis_host -p $redis_port -n $db1 set $key $value ex 600
else
redis-cli -h $redis_host -p $redis_port -n $db1 set $key $value
fi
done
执行脚本
4、redis常用指标与示例
针对redis服务,我们可以利用google的四个黄金信号来监控其健康状况。
这些信号包括:
延迟:监控平均命令响应时间,以评估处理请求的效率。
流量:跟踪每秒处理的命令数量、以及网络的输入/输出速度,以便理解服务负载。
错误:统计命令失败次数和连接被拒绝的情况,以识别潜在的服务问题。
饱和度:监测内存使用率和客户端连接数,以判断服务的负载情况和容量限制。
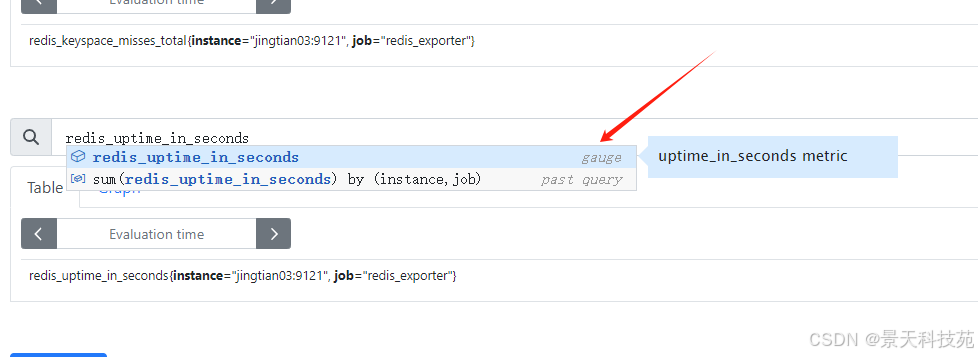
1)redis健康状态相关指标

启动多少秒是累加的,不断增大的,counter类型的,exporter将其标为gauge是错误的
案例1:检查redis是否存活
sum(redis_up) by (instance,job)

案例2:检查redis是否出现过重启,只需要判断启动时间是否小于1分钟即可。
sum(redis_uptime_in_seconds) by (instance,job) < 60 # redis运行了多长时间 sum(redis_uptime_in_seconds) by (instance,job) / 3600 # 小时 sum(redis_uptime_in_seconds) by (instance,job) / 86400 # 天
2)redis连接数相关指标

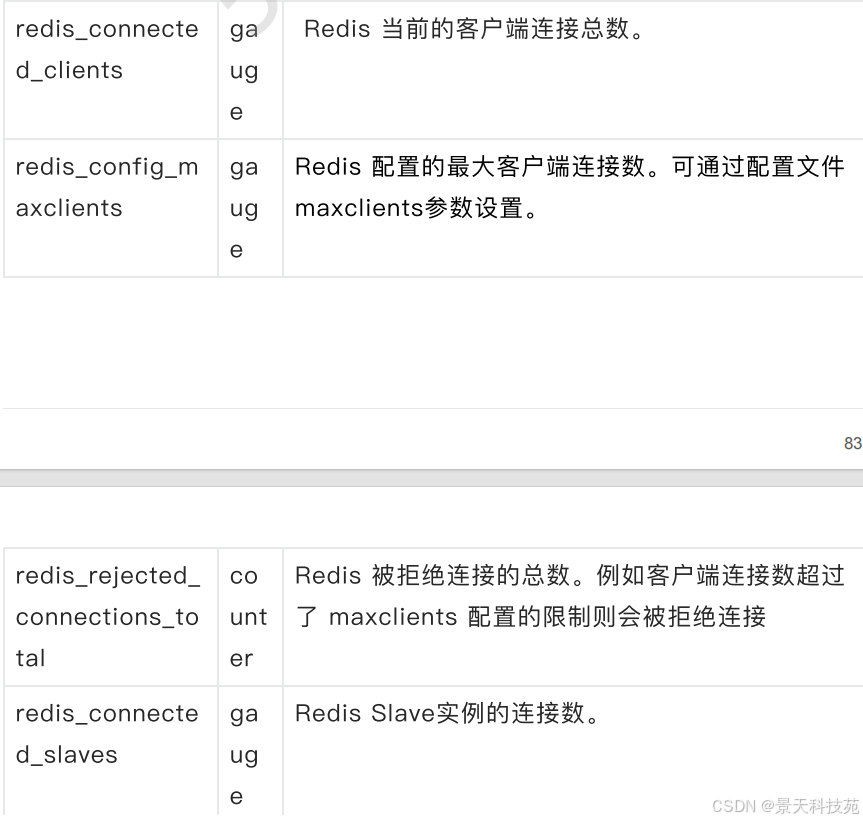
默认允许的最大连接数为10000

案例1:查询当前 redis 连接数与最大配置连接数的比率。
计算公式:( 当前客户端连接数 / 最大支持的客户端连接数 * 100 )
redis_connected_clients /redis_config_maxclients *100

案例2:查询过去1小时内是否有连接被拒绝,直接使用increase获取一个小时的增量数据
increase(redis_rejected_connections_total[1h])

3)redis内存相关指标

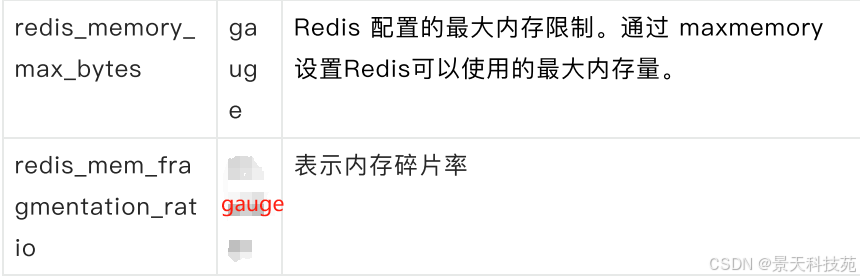
案例:redis当前使用的内存达到最大内存的比率。计算公式:( 当前内存 /最大内存 * 100 )
redis_memory_used_bytes / redis_memory_max_bytes * 100

4)redis命中率相关指标

案例1:查询最近5分钟,命令率和未命中率qps
irate(redis_keyspace_hits_total[5m]) irate(redis_keyspace_misses_total[5m])
案例2:查询redis最近5分钟,缓存成功命中率低于90% ,计算公式:(rate(5分钟成功的命中率) / ( 5分钟成功的命中率 + 5分钟失败的命中率) *100 )
irate(redis_keyspace_hits_total[5m]) / ( irate(redis_keyspace_hits_total[5m]) + irate(redis_keyspace_misses_total[5m]) ) * 100 < 90
5)redis key相关指标


案例1:计算redis中,每个库即将过期的key,占每个库总key的比率。计算公式:( 每个库过期的key / 每个库总的key * 100 )
redis_db_keys_expiring / redis_db_keys * 100

案例2:计算redis最近5分钟,即将被驱逐的key,占总key的比率。计算公式:( rate(最近5分钟被驱逐的key) / 总的key * 100 )
# 计算不同命令的失败率。 irate(redis_commands_failed_calls_total[5m]) / irate(redis_commands_total[5m]) * 100 # 计算总的失败比率 sum (irate(redis_commands_failed_calls_total[5m])) by (instance,job) / sum (irate(redis_commands_total[5m])) by (instance,job) * 100

6)redis执行命令操作相关指标
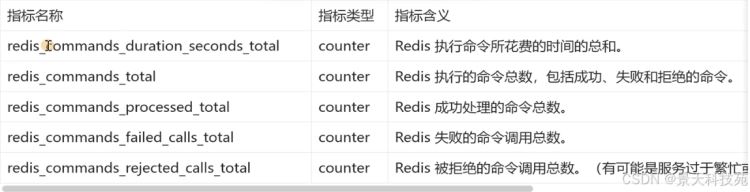

案例1:计算redis每分钟,成功处理命令的qps
irate(redis_commands_processed_total[1m])
# 模拟redis的qps小脚本 while true;do redis-cli keys "*" redis-cli set a b redis-cli get a sleep 0.1 done
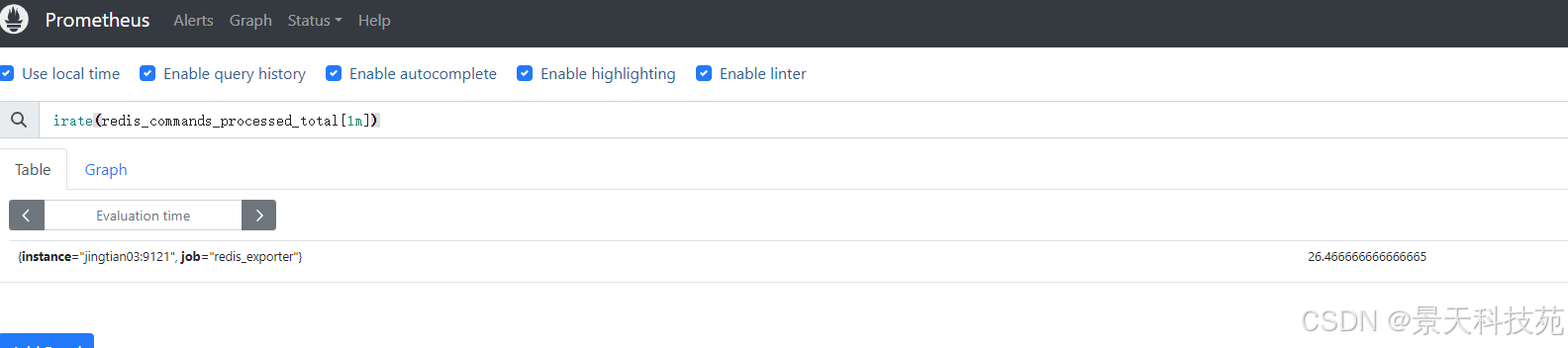
案例2:计算redis最近5分钟,命令执行失败占执行命令总数的比率。
计算公式:( irate(最近5分钟失败的命令数量) / irate(最近5分钟执行命令的总数量) * 100 )
# 计算不同命令的失败率。 irate(redis_commands_failed_calls_total[5m]) / irate(redis_commands_total[5m]) * 100 # 计算总的失败比率 sum (irate(redis_commands_failed_calls_total[5m])) by (instance,job) / sum (irate(redis_commands_total[5m])) by (instance,job) * 100
案例3:计算redis最近5分钟,被拒绝执行的命令占执行命令总数的比率。
计算公式:( irate(最近5分钟拒绝的命令数量) / irate(最近5分钟执行命令的总数量) * 100 )
# 计算不同命令的拒绝率。 irate(redis_commands_rejected_calls_total[5m]) / irate(redis_commands_total[5m]) * 100 # 计算总的拒绝率 sum (irate(redis_commands_rejected_calls_total[5m])) by (instance,job) / sum (irate(redis_commands_total[5m])) by (instance,job) * 100
案例4:计算redis在过去5分钟内每个成功执行的命令,平均响应时间。
计算公式:( irate(5分钟所花费总的时间) / rate(5分钟执行成功命令的次数))
sum(rate(redis_commands_duration_seconds_total[5m])) by (instance,job) / sum (rate(redis_commands_processed_total[5m])) by (instance,job)
7)redis备份相关指标
rdb方式备份

案例1:上一次rdb备份失败。
redis_rdb_last_bgsave_status == 0
案例2:上一次rdb备份成功,但是备份时长超过了3s
redis_rdb_last_bgsave_duration_sec > 3 and redis_rdb_last_bgsave_status ==1
案例3:超过10小时没有生成新的rdb备份文件。
计算公式:( (当前时间戳- 上一次rbd备份文件时间戳 ) > 36000 ),10小时等于36000秒( 60 *60 * 10 )
(time() - redis_rdb_last_save_timestamp_seconds) > 36000
aof备份
redis_aof_enabled:1 aof日志是否启用 redis_aof_rewrite_in_progress:0 表示当前是否在进行写入aof日志操作 redis_aof_rewrite_scheduled:0 是否有aof操作等待执行。 redis_aof_last_rewrite_time_sec:-1 表示上次写入aof日志的时间戳 redis_aof_current_rewrite_time_sec:-1 当前正在执行的aof重写操作已经消耗的时间。 redis_aof_last_bgrewrite_status:ok 表示上次执行aof日志重写的状态 redis_aof_last_write_status:ok 表示上次写入aof日志的状态 redis_aof_last_cow_size:0 aof执行中父进程与子进程相比执行了多少修改 redis_aof_current_size:0 aof日志的当前大小 redis_aof_base_size:0 最近一次重写后aof日志的大小。 redis_aof_pending_rewrite:0 是否有aof操作在等待执行。 redis_aof_buffer_length:0 aof缓冲区的大小。 redis_aof_rewrite_buffer_length:0 aof重写缓冲区的大小。 redis_aof_pending_bio_fsync:0 在等待执行的fsync操作的数量。 redis_aof_delayed_fsync:0 fsync操作延迟执行的次数。
5、redis告警规则文件
1)编写redis告警规则文件
cat /etc/prometheus/rules/redis_rules.yml
groups:
- name: redis告警规则
rules:
- alert: redis实例宕机
expr: sum(redis_up) by (instance, job) == 0
for: 1m
labels:
severity: critical
annotations:
summary: "redis实例宕机, {{ $labels.instance }} "
description: "redis实例 {{ $labels.instance }} 在过去1分钟内无法连接。"
- alert: redis实例重启
expr: sum(redis_uptime_in_seconds) by (instance, job) < 60
for: 0m
labels:
severity: warning
annotations:
summary: "redis实例 {{ $labels.instance }} 重启"
description: "redis实例 {{ $labels.instance }} 出现重启。当前运行时间:{{ $value }} 秒。"
- alert: redis连接数过高
expr: redis_connected_clients / redis_config_maxclients * 100 > 80
for: 5m
labels:
severity: warning
annotations:
summary: "redis实例 {{ $labels.instance }} 连接数超过80%"
description: "redis实例 {{ $labels.instance }} 当前连接数占最大连接数的比率超过80%。当前比率: {{ $value }}%。"
- alert: redis连接被拒绝
expr: increase(redis_rejected_connections_total[1h]) > 0
for: 5m
labels:
severity: warning
annotations:
summary: "redis实例 {{ $labels.instance }} 有连接被拒绝"
description: "redis实例 {{ $labels.instance }} 在过去1小时内有连接被拒绝。当前被拒绝的连接数: {{ $value }}。"
- alert: redis内存使用率过高
expr: redis_memory_used_bytes / redis_memory_max_bytes * 100 > 80
for: 5m
labels:
severity: critical
annotations:
summary: "redis实例 {{ $labels.instance }} 内存使用率超过80%"
description: "redis实例 {{ $labels.instance }} 当前内存使用率超过配置的最大内存值的80%。当前内存使用率: {{ $value }}%。"
- alert: redis缓存命中率低
expr: |
irate(redis_keyspace_hits_total[5m]) /
(irate(redis_keyspace_hits_total[5m]) + irate(redis_keyspace_misses_total[5m])) * 100 < 90
for: 10m
labels:
severity: warning
annotations:
summary: "redis实例 {{ $labels.instance }} 缓存命中率低于90%"
description: "redis实例 {{ $labels.instance }} 最近5分钟内的缓存命中率低于90%。当前命中率: {{ $value }}%。"
- alert: redis即将过期的key数量过多
expr: |
sum(redis_db_keys_expiring) by (instance, job, db) /
sum(redis_db_keys) by (instance, job, db) * 100 > 50
for: 5m
labels:
severity: warning
annotations:
summary: "redis实例 {{ $labels.instance }} 中的数据库 {{ $labels.db}} 有过多即将过期的key"
description: "redis实例 {{ $labels.instance }} 中的数据库 {{ $labels.db }} 有超过50%的key即将过期。当前比率: {{ $value }}%。"
- alert: redisrdb备份失败
expr: redis_rdb_last_bgsave_status == 0
for: 1m
labels:
severity: critical
annotations:
summary: "redis实例 {{ $labels.instance }} rdb备份失败"
description: "redis实例 {{ $labels.instance }} 最近的rdb备份尝试失败。"
- alert: redisrdb备份时间过长
expr: redis_rdb_last_bgsave_duration_sec > 3 and redis_rdb_last_bgsave_status == 1
for: 1m
labels:
severity: warning
annotations:
summary: "redis实例 {{ $labels.instance }} rdb备份成功但耗时超过3秒"
description: "redis实例 {{ $labels.instance }} rdb备份成功,但备份耗时超过了3秒。持续时间: {{ $value }}秒。"
- alert: redisrdb备份过期
expr: (time() - redis_rdb_last_save_timestamp_seconds) > 36000
for: 5m
labels:
severity: critical
annotations:
summary: "redis实例 {{ $labels.instance }} 超过10小时未进行rdb备份"
description: "redis实例 {{ $labels.instance }} 已超过10小时没有生成新的rdb备份文件。"
- alert: redis命令拒绝率过高
expr: |
sum(irate(redis_commands_rejected_calls_total[5m])) by (instance, job) /
sum(irate(redis_commands_total[5m])) by (instance, job) * 100 > 25
for: 5m
labels:
severity: warning
annotations:
summary: "redis实例 {{ $labels.instance }} 命令拒绝率超过25%"
description: "redis实例 {{ $labels.instance }} 的命令拒绝率超过了25%。当前拒绝率: {{ $value }}%。"
- alert: redis命令平均响应时间过长
expr: |
sum(rate(redis_commands_duration_seconds_total[5m])) by (instance,job) /
sum(rate(redis_commands_processed_total[5m])) by (instance, job) >0.250
for: 5m
labels:
severity: critical
annotations:
summary: "redis实例 {{ $labels.instance }} 命令平均响应时间超过250ms"
description: "redis实例 {{ $labels.instance }} 的执行命令平均响应时间超过了250毫秒。当前平均响应时间: {{ $value }}秒。"
2)查看告警规则
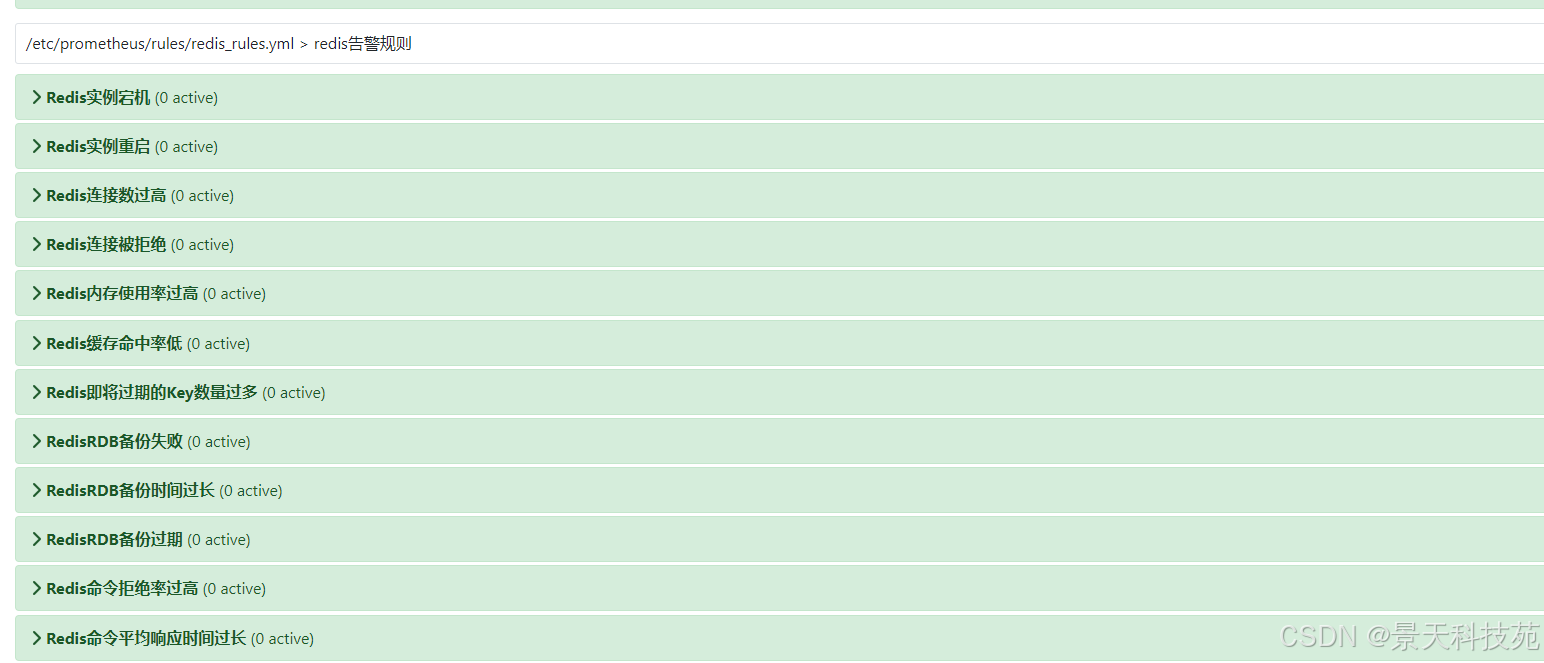
6、导入redis图形
1)导入一个redis的grafana的模板,id为763
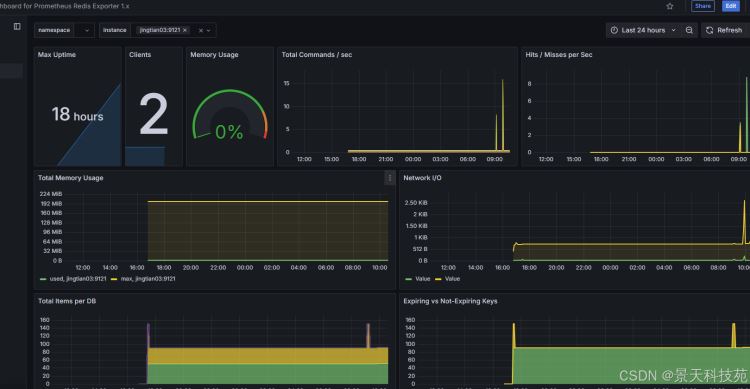
2)运行一个redis的模拟数据脚本
cat redis_basic_data.sh
#!/bin/bash
# 模拟的 redis 客户端数量
clients=199
# redis 服务器配置
redis_host="localhost"
redis_port=6379
redis_password="" # redis 密码
# 生成随机字符串的函数,用于键和值
# $1 是生成的字符串长度
generate_random_string() {
cat /dev/urandom | tr -dc 'a-za-z0-9' | fold -w ${1:-32} | head -n 1
}
# 模拟 redis 客户端的行为
simulate_redis_client() {
# 存储随机生成的键,用于后续的 get 操作
declare -a keys
# 打开 redis-cli 的交互式会话
(
# 如果设置了密码,先认证
if [[ -n "$redis_password" ]]; then
echo "auth $redis_password"
fi
# 持续发送命令
while true; do
# 生成随机键和值
key=$(generate_random_string 10)
value=$(generate_random_string 20)
# 随机的过期时间,介于10到60秒之间
ttl=$((random % 50 + 10))
# set 操作
echo "set $key $value ex $ttl"
# 将键存储在数组中,用于模拟 get
keys+=("$key")
# 随机决定是否执行 get
if [ $((random % 2)) -eq 0 ]; then
# 模拟命中和未命中
if [ $((random % 10)) -lt 8 ]; then # 80% 概率尝试获取一个存在的键,模拟命中
get_key="${keys[$((random % ${#keys[@]}))]}"
else # 20% 概率尝试获取一个不存在的键,模拟未命中
get_key=$(generate_random_string 10)
fi
# get 操作
echo "get $get_key"
fi
# 操作间隔,减少服务器压力
sleep 1
done
) | redis-cli -h $redis_host -p $redis_port --pipe
}
# 启动多个客户端
for ((i=0; i<clients; i++)); do
simulate_redis_client &
echo "started redis client simulation $i"
done
# 等待所有后台进程
wait
客户端数量增加
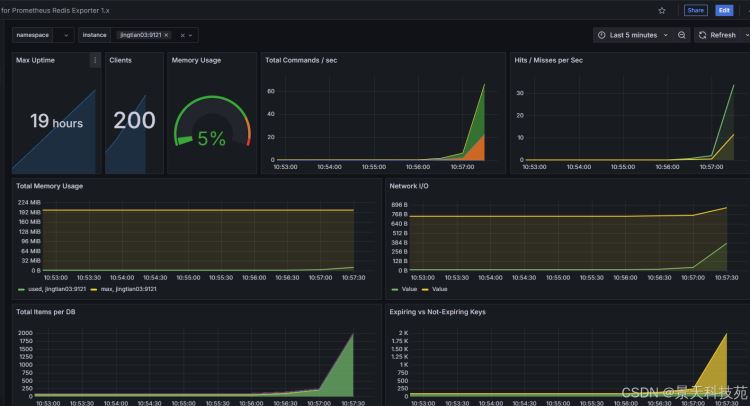
以上就是通过prometheus监控redis实时运行状态的操作方法的详细内容,更多关于prometheus监控redis运行状态的资料请关注代码网其它相关文章!




发表评论