redis秒杀优化方案(阻塞队列+stream流的消息队列)
下面是我们的秒杀流程:
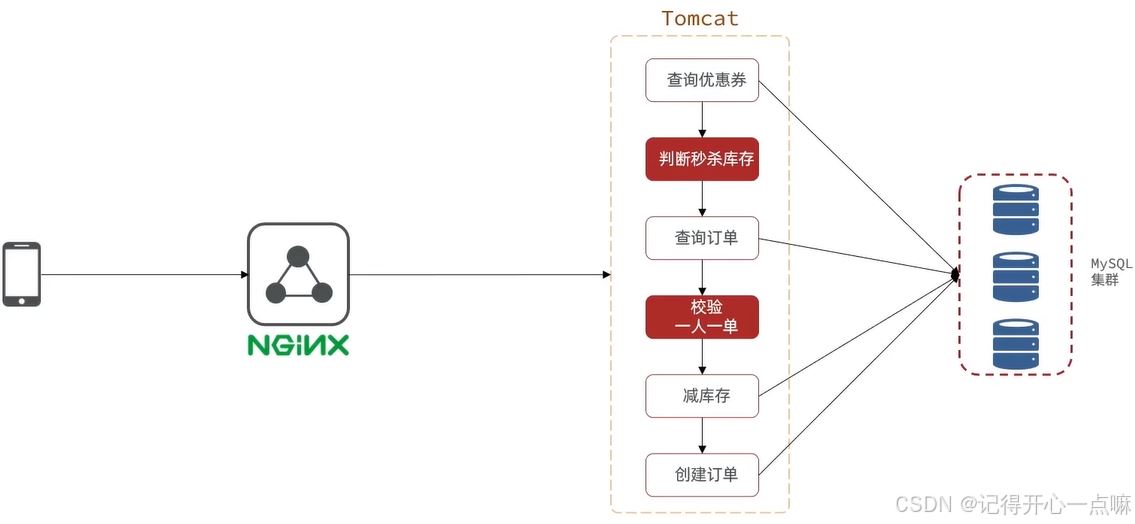
对于正常的秒杀处理,我们需要多次查询数据库,会给数据库造成相当大的压力,这个时候我们需要加入缓存,进而缓解数据库压力。
在上面的图示中,我们可以将一条流水线的任务拆成两条流水线来做,如果我们直接将判断秒杀库存与校验一人一单放在流水线a上,剩下的放在另一条流水线b,那么如果流水线a就可以相当于服务员直接判断是否符合资格,如果符合资格那么直接生成信息给另一条流水线b去处理业务,这里的流水线就是咱们的线程,而流水线a也是基于数据库进行查询,也会压力数据库,那么这种情况我们就可以将待查询信息保存在redis缓存中。
但是我们不能再流水线a判断完成后去直接调用流水线b,这样的效率是大打折扣的,这种情况我们需要开启独立线程去执行流水线b的操作,如何知道给哪个用户创建订单呢?这个时候就要流水线a在判断成功后去生成信息给独立线程。
最后的业务就变成,用户直接访问流水线a,通过流水线a去判断,如果通过则生成信息给流水线b去创建订单,过程如下图:
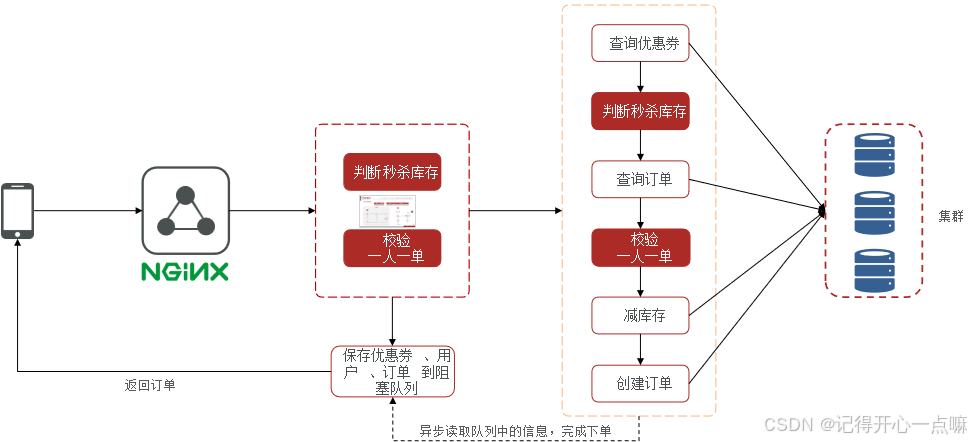
那么什么样的数据结构满足下面条件:
- ① 一个key能够保存很多值
- ②唯一性:一人一单需要保证用户id不能重复。
所以我们需要使用set:

那么如何判断校验用户的购买资格呢?
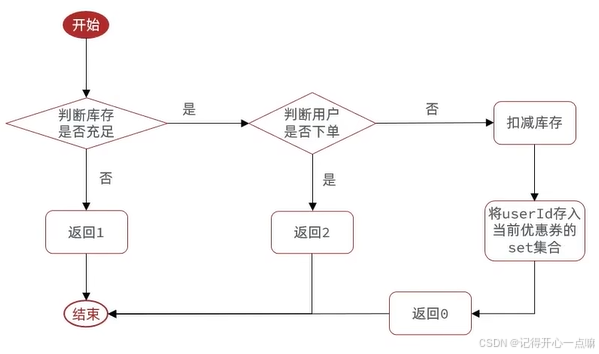
而上述判断需要保证原子性,所以我们需要使用lua脚本进行编写:
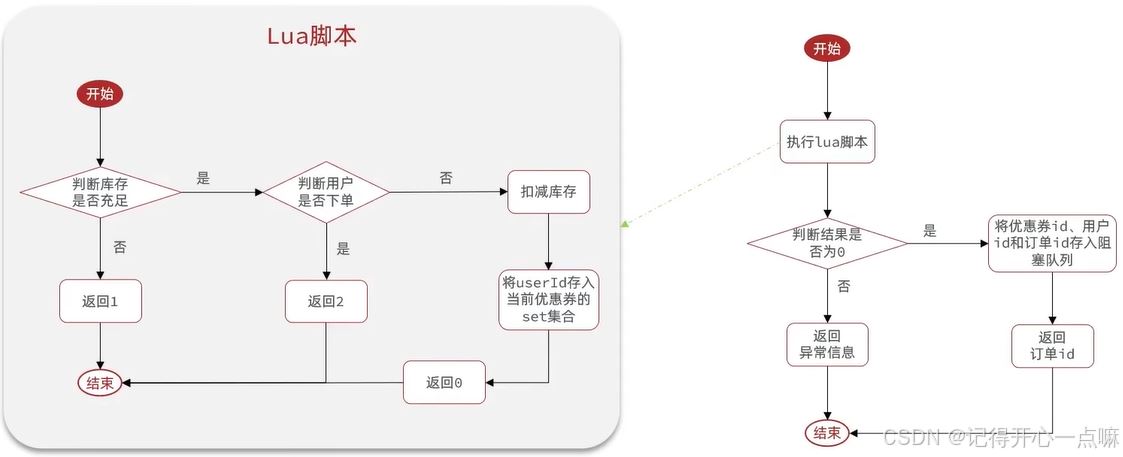
local voucherid = argv[1]; -- 优惠劵id
local userid = argv[2]; -- 用户id
-- 库存key
local stockkey = 'seckill:stock' .. voucherid; -- 拼接
-- 订单key
local stockkey = 'seckill:stock' .. voucherid; -- 拼接
-- 判断库存是否充足
if(tonumber(redis.call('get',stockkey) <= 0)) then
-- 库存不足,返回1
return 1;
end;
-- 判断用户是否下单
if(redis.call('sismember',orderkey,userid)) then
-- 存在,说明重复下单,返回2
return 2;
end
-- 扣减库存 incrby stockkey -1
redis.call('incrby',stockkey,-1);
-- 下单(保存用户) sadd orderkey userid
redis.call('sadd',orderkey,userid);
return 0;之后我们按照下面步骤来实现代码:
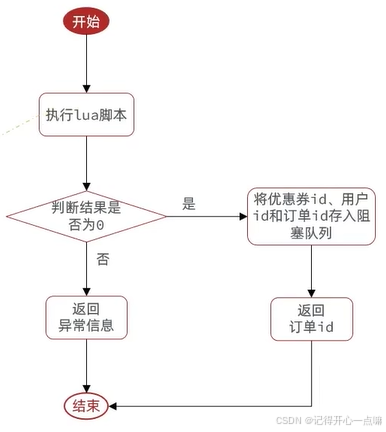
在方法体内执行lua脚本来原子性判断,然后判断是否能够处理并传入阻塞队列:
@slf4j
@service
public class voucherorderserviceimpl extends serviceimpl<voucherordermapper, voucherorder> implements ivoucherorderservice {
@autowired
private iseckillvoucherservice seckillvoucherservice;
@autowired
private redisidworker redisidworker;
@resource
private stringredistemplate stringredistemplate;
@resource
private redissonclient redissonclient;
private static final defaultredisscript<long> seckill_script; // 泛型内填入返回值类型
static { // 静态属性要使用静态代码块进行初始化
seckill_script = new defaultredisscript<>();
seckill_script.setresulttype(long.class);
seckill_script.setlocation(new classpathresource("unlock.lua"));
}
public result seckillvouchermax(long voucherid) {
// 获取用户信息
long userid = userholder.getuser().getid();
// 1.执行lua脚本来判断用户资格
long result = stringredistemplate.execute(
seckill_script,
collections.emptylist(), // lua无需接受key
voucherid.tostring(),
userid.tostring()
);
// 2.判断结果是否为0
int r = result.intvalue();
if(r != 0) {
// 不为0代表无资格购买
return result.fail(r == 1 ? "库存不足" : "不能重复下单");
}
// 3.有购买资格则将下单信息保存到阻塞队列中
// ...
return result.ok();
}
}接下来我们创建阻塞队列,线程池以及线程方法,随后使用springboot提供的注解在@postconstruct去给线程池传入线程方法:
@slf4j
@service
public class voucherorderserviceimpl extends serviceimpl<voucherordermapper, voucherorder> implements ivoucherorderservice {
@autowired
private iseckillvoucherservice seckillvoucherservice;
@autowired
private redisidworker redisidworker;
@resource
private stringredistemplate stringredistemplate;
@resource
private redissonclient redissonclient;
private static final defaultredisscript<long> seckill_script; // 泛型内填入返回值类型
static { // 静态属性要使用静态代码块进行初始化
seckill_script = new defaultredisscript<>();
seckill_script.setresulttype(long.class);
seckill_script.setlocation(new classpathresource("unlock.lua"));
}
private blockingqueue<voucherorder> ordertasks = new arrayblockingqueue<>(1024 * 1024); // 创建阻塞队列
private static final executorservice seckill_order_executor = executors.newsinglethreadexecutor(); // 创建线程池
// 让大类在开始初始化时就能够执行线程任务
@postconstruct
private void init() {
seckill_order_executor.submit(new voucherordertask());
}
// 创建线程任务
private class voucherordertask implements runnable {
@override
public void run() {
while(true){
try {
// 获取队列中的订单信息
voucherorder voucherorder = ordertasks.take();// 取出头部信息
// 创建订单
handlevoucherorder(voucherorder);
} catch (exception e) {
log.error("处理订单异常",e);
}
}
}
}
// 创建订单
private void handlevoucherorder(voucherorder voucherorder) {
rlock lock = redissonclient.getlock("lock:order:" + voucherorder.getuserid().tostring());
boolean islock = lock.trylock();
// 判断是否获取锁成功
if (!islock) {
// 获取锁失败,返回错误或重试
log.error("不允许重复下单");
return ;
}
try {
proxy.createvoucherordermax(voucherorder);
} finally {
lock.unlock();
}
}
@override
public void createvoucherordermax(voucherorder voucherorder) {
// 一人一单
long userid = voucherorder.getuserid();
// 查询订单
int count = query().eq("user_id",userid).eq("voucher_id", voucherorder.getvoucherid()).count();
// 判断是否存在
if(count > 0){
// 用户已经购买过
log.error("用户已经购买过");
return ;
}
// cas改进:将库存判断改成stock > 0以此来提高性能
boolean success = seckillvoucherservice.update()
.setsql("stock= stock -1") // set stock = stock - 1
.eq("voucher_id", voucherorder.getvoucherid()).eq("stock",0) // where id = ? and stock > 0
.update();
if (!success) {
//扣减库存
log.error("库存不足!");
return ;
}
//6.创建订单
save(voucherorder);
}
private ivoucherorderservice proxy; // 代理对象
public result seckillvouchermax(long voucherid) {
// 获取用户信息
long userid = userholder.getuser().getid();
// 1.执行lua脚本来判断用户资格
long result = stringredistemplate.execute(
seckill_script,
collections.emptylist(), // lua无需接受key
voucherid.tostring(),
userid.tostring()
);
// 2.判断结果是否为0
int r = result.intvalue();
if(r != 0) {
// 不为0代表无资格购买
return result.fail(r == 1 ? "库存不足" : "不能重复下单");
}
// 3.有购买资格则将下单信息保存到阻塞队列中
long orderid = redisidworker.nextid("order");
// 创建订单
voucherorder voucherorder = new voucherorder();
voucherorder.setid(orderid);
voucherorder.setuserid(userid);
voucherorder.setvoucherid(voucherid);
// 放入阻塞队列
ordertasks.add(voucherorder);
// 4.获取代理对象(线程异步执行,需要手动在方法内获取)
proxy = (ivoucherorderservice)aopcontext.currentproxy(); // 获取当前类的代理对象 (需要引入aspectjweaver依赖,并且在实现类加入@enableaspectjautoproxy(exposeproxy = true)以此来暴露代理对象)
return result.ok();
}
}在上面代码中,我们使用下面代码创建了一个单线程的线程池。它保证所有提交的任务都按照提交的顺序执行,每次只有一个线程在工作。
private static final executorservice seckill_order_executor = executors.newsinglethreadexecutor();
下面代码是一个常见的阻塞队列实现,具有固定大小(在这里是 1024 * 1024),它的作用是缓冲和排队任务。arrayblockingqueue 是一个线程安全的队列,它会自动处理线程之间的同步问题。当队列满时,调用 put() 方法的线程会被阻塞,直到队列有空间;当队列为空时,调用 take() 方法的线程会被阻塞,直到队列中有数据。
private blockingqueue<voucherorder> ordertasks = new arrayblockingqueue<>(1024 * 1024);
在下面代码中,ordertasks 阻塞队列用于存放需要处理的订单对象,每个订单的处理逻辑都由 voucherordertask 线程池中的线程异步执行:
voucherorder voucherorder = ordertasks.take(); handlevoucherorder(voucherorder);
之后我们需要调用 runnable 接口去实现voucherordertask类以此来创建线程方法:
private class voucherordertask implements runnable {
@override
public void run() {
while (true) {
try {
// 获取队列中的订单信息
voucherorder voucherorder = ordertasks.take(); // 获取订单
// 创建订单
handlevoucherorder(voucherorder);
} catch (exception e) {
log.error("处理订单异常", e);
}
}
}
}随后将线程方法通过 submit() 方法将 voucherordertask 提交到线程池中,这个任务是一个无限循环的任务,它会不断从阻塞队列中取出订单并处理,直到线程池关闭。
这种方式使得订单处理任务可以异步执行,而不阻塞主线程,提高了系统的响应能力:
@postconstruct
private void init() {
seckill_order_executor.submit(new voucherordertask());
}但是在高并发的情况下就会产生大量订单,就会超出jvm阻塞队列的上线,并且每当服务重启或者宕机的情况发生,阻塞队列的所有订单任务就都会丢失。
所以为了解决这种情况,我们就要使用消息队列去解决这个问题:
什么是消息队列?
消息队列(message queue, mq)是一种用于在应用程序之间传递消息的通信方式。它允许应用程序通过发送和接收消息来解耦,从而提高系统的可扩展性、可靠性和灵活性。消息队列通常用于异步通信、任务队列、事件驱动架构等场景。
消息队列的核心概念 :
- 生产者(producer):发送消息到消息队列的应用程序。
- 消费者(consumer):从消息队列中接收并处理消息的应用程序。
- 队列(queue):消息的存储区域,生产者将消息发送到队列,消费者从队列中获取消息。
- 消息(message):在生产者与消费者之间传递的数据单元。
- broker:消息队列的服务器,负责接收、存储和转发消息。

消息队列是在jvm以外的一个独立的服务,能够不受jvm内存的限制,并且存入mq的信息都可以做持久化存储。
详细教学可以查询下面链接:微服务架构 --- 使用rabbitmq进行异步处理
但是这样的方式是需要额外提供服务的,所以我们可以使用redis提供的三种不同的方式来实现消息队列:
- list 结构实现消息队列
- pub/sub(发布/订阅)模式
- stream 结构(redis 5.0 及以上版本)(推荐使用)(详细介绍)
使用 list 结构实现消息队列:
redis 的 list 数据结构是一个双向链表,支持从头部或尾部插入和弹出元素。我们可以利用 lpush 和 brpop 命令实现一个简单的消息队列。
实现步骤:
- 生产者:使用
lpush将消息推入队列。 - 消费者:使用
brpop阻塞地从队列中获取消息。
生产者代码:
import redis.clients.jedis.jedis;
public class listproducer {
public static void main(string[] args) {
jedis jedis = new jedis("localhost", 6379); // 连接 redis
string queuename = "myqueue";
// 发送消息
for (int i = 1; i <= 5; i++) {
string message = "message " + i;
jedis.lpush(queuename, message); // 将消息推入队列
system.out.println("sent: " + message);
}
jedis.close(); // 关闭连接
}
}消费者代码:
import redis.clients.jedis.jedis;
public class listconsumer {
public static void main(string[] args) {
jedis jedis = new jedis("localhost", 6379); // 连接 redis
string queuename = "myqueue";
while (true) {
// 阻塞获取消息,超时时间为 0(无限等待)
var result = jedis.brpop(0, queuename);
string message = result.get(1); // 获取消息内容
system.out.println("received: " + message);
}
}
}- 优点:简单易用,适合轻量级场景。
- 缺点:不支持消息确认机制,消息一旦被消费(从队列内取出)就会从队列中删除。并且只支持单消费者(一个消息只能拿出一次)
使用 pub/sub 模式实现消息队列:
redis 的 pub/sub 模式是一种发布-订阅模型,生产者将消息发布到频道,消费者订阅频道以接收消息。
实现步骤:
- 生产者:使用
publish命令向频道发布消息。 - 消费者:使用
subscribe命令订阅频道。
生产者代码:
import redis.clients.jedis.jedis;
public class pubsubproducer {
public static void main(string[] args) {
jedis jedis = new jedis("localhost", 6379); // 连接 redis
string channelname = "mychannel";
// 发布消息
for (int i = 1; i <= 5; i++) {
string message = "message " + i;
jedis.publish(channelname, message); // 发布消息到频道
system.out.println("published: " + message);
}
jedis.close(); // 关闭连接
}
}消费者代码:
import redis.clients.jedis.jedis;
import redis.clients.jedis.jedispubsub;
public class pubsubconsumer {
public static void main(string[] args) {
jedis jedis = new jedis("localhost", 6379); // 连接 redis
string channelname = "mychannel";
// 创建订阅者
jedispubsub subscriber = new jedispubsub() {
@override
public void onmessage(string channel, string message) {
system.out.println("received: " + message);
}
};
// 订阅频道
jedis.subscribe(subscriber, channelname);
}
}- 优点:支持一对多的消息广播。
- 缺点:消息是即时的,如果消费者不在线,消息会丢失。
但是上面两方式都是有缺点的:
- 不支持消息确认机制,消息一旦被消费(从队列内取出)就会从队列中删除。并且只支持单消费者(一个消息只能拿出一次)
- 消息是即时的,如果消费者不在线,消息会丢失。
所以根据上面的两种方式,我们推出一款全新的方式 ->
使用 stream 结构实现消息队列:
redis stream 是一种强大的数据结构,用于管理消息流。它将消息存储在 redis 中,并允许消费者按顺序获取消息。stream 具有以下特点:
- 有序消息:消息按插入顺序排列。
- 消费者组:一个消费者组可以有多个消费者,每个消费者可以独立消费不同的消息。
- 消息 id:每条消息都有唯一的 id(如:
1588890470850-0),id 按时间戳生成。 - 自动分配消息:多个消费者可以从 stream 中并行消费消息,保证消息不会重复消费。


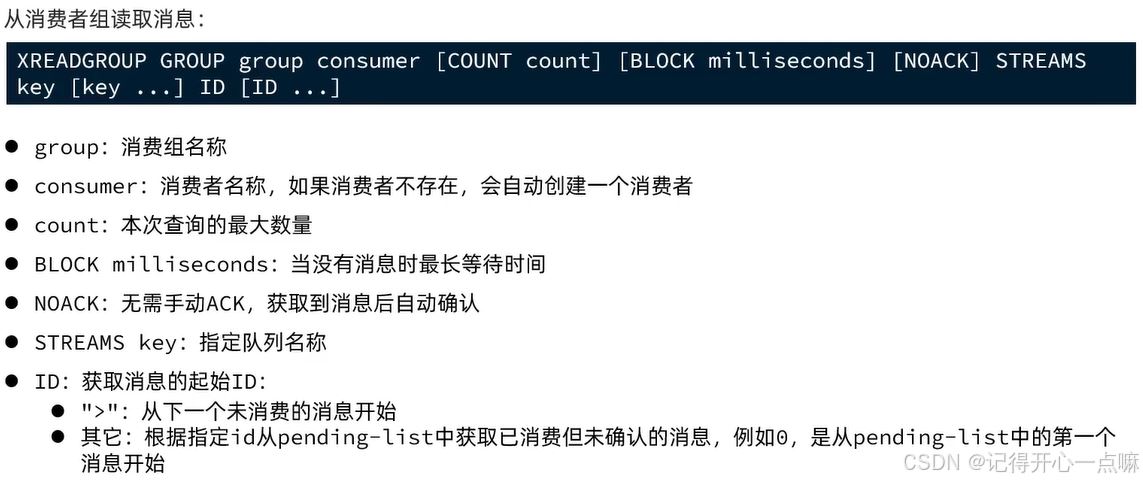
在 redis stream 中,一个队列可以有多个消费者组,每个消费者组可以独立地消费队列中的消息。每个消费者组内有多个消费者,而消费者是基于 消费者名称 进行识别的。
消费者组的工作方式
- 每个消费者组拥有自己的 消费进度,也就是每个消费者组会从 自己独立的消息 id 开始消费。
- 多个消费者组之间是相互独立的,即使它们消费的是同一个队列,它们也可以从不同的位置开始消费队列中的消息。
- 每个消费者组都可以有多个 消费者(在同一个组内,多个消费者可以并行消费同一个队列的消息,但每个消息在消费者组内只能被一个消费者处理一次)。
假设有一个队列(stream)mystream,可以为它创建多个消费者组:
xgroup create mystream group1 $ mkstream xgroup create mystream group2 $ mkstream
这样,mystream 队列上就有了两个消费者组:group1 和 group2。每个消费者组可以有自己的消费者并从该队列中读取消息。此时,group1 和 group2 都在消费同一个队列 mystream,但它们的消费进度是独立的,它们各自有自己的消息 id 记录。
每个消费者组可以有多个消费者,而每个消费者通过一个 唯一的消费者名称 来标识。
每个消费者组有独立的消费进度
每个消费者组会记录自己的消费进度,也就是它消费到队列中的 哪个消息 id。即使多个消费者组在消费同一个消息队列,它们每个组都会从 不同的消费位置(消息 id)开始读取消息。
例如,假设有一个队列 mystream,同时有两个消费者组 group1 和 group2,它们都从 mystream 队列中读取消息:
group1从mystream队列中的消息id1开始消费,group1的进度会记录在 redis 中。group2从mystream队列中的消息id2开始消费,group2的进度也会记录在 redis 中。
消费进度互不干扰,即便 group1 和 group2 都在消费 mystream 队列,它们的消费位置是独立的。
消费者组内部的消息消费
一个消费者组内的消费者会 共享 组内的消息。即使有多个消费者,每条消息 在消费者组内部只会被 一个消费者 消费。消费者之间会并行处理消息,但每条消息只会被一个消费者处理。
举个例子:假设 group1 中有三个消费者 consumer1、consumer2、consumer3,如果队列 mystream 有 6 条消息,那么它们会如下消费:
consumer1处理消息1、2consumer2处理消息3、4consumer3处理消息5、6
但对于消费者组 group2,如果它有自己的消费者,group2 内的消费者也会并行消费 mystream 中的消息,而 group1 和 group2 之间没有直接关系。
首先初始化一个消息队列:
在项目启动时,确保 redis 中存在对应的 stream 和消费者组。可以通过程序在启动时检查并创建(如果不存在的话)。
@configuration
public class redisstreamconfig {
@autowired
private stringredistemplate redistemplate;
private static final string stream_key = "mystream";
private static final string group_name = "mygroup";
@postconstruct
public void init() {
// 检查消费者组是否存在,若不存在则创建
try {
// 如果消费者组不存在则会抛出异常,我们捕获异常进行创建
redistemplate.opsforstream().groups(stream_key);
} catch (exception e) {
// 创建消费者组,起始位置为 $ 表示从末尾开始消费新消息
redistemplate.opsforstream().creategroup(stream_key, group_name);
}
}
}注意:
opsforstream().groups(stream_key):查询消费者组是否已存在。opsforstream().creategroup(stream_key, group_name):如果没有消费者组,则创建一个新的组。
随后我们生产者发送消息示例:
@service
public class redisstreamproducerservice { // 定义生产者服务类 redisstreamproducerservice
private static final string stream_key = "mystream"; // 定义 redis stream 的名称,这里指定队列名为 "mystream"
@autowired
private stringredistemplate redistemplate;
public void sendmessage(string content) { // 定义一个方法,发送消息到 redis stream,参数 content 是消息的内容
map<string, string> map = new hashmap<>(); // 创建一个 map 用来存储消息内容
map.put("content", content); // 将消息内容添加到 map 中,键是 "content",值是传入的内容
// 在消息队列中添加消息,调用 stringredistemplate 的 opsforstream 方法
recordid recordid = redistemplate.opsforstream() // 获取操作 redis stream 的操作对象
.add(streamrecords.objectbacked(map) // 创建一个 stream 记录,将 map 转化为对象记录
.withstreamkey(stream_key)); // 设置该记录属于的 stream(消息队列)的名称
// 输出记录的 id,表示消息已经成功发送
system.out.println("消息发送成功,id: " + recordid.getvalue()); // 打印消息的 id,表明该消息已经被成功加入到 stream 中
}
}recordid 是 spring data redis 中的一个类,用来表示 消息的唯一标识符。它对应 redis stream 中的 消息 id,该 id 是 redis stream 中每条消息的唯一标识。redis 中的消息 id 通常是由时间戳和序号组成的(如 1588890470850-0)。
主要功能:
- 表示消息 id:
recordid是一个封装类,表示 redis stream 中消息的 id。 - 用于识别和操作消息:在消费和确认消息时,
recordid用来标识每条消息的唯一性,并帮助 redis 确定消息是否已经被消费。
使用场景:
recordid 用来标识从 stream 中读取到的消息,我们可以通过 recordid 来进行消息的确认、删除或其他操作。
recordid recordid = redistemplate.opsforstream().add(streamrecords.objectbacked(map).withstreamkey("mystream"));通过 streamrecords.objectbacked(map) 将 map 对象作为消息内容,并用 add 方法将其写入 stream。
在然后编写消费者服务:
使用 redistemplate 的 read 方法(底层执行的是 xreadgroup 命令)从消费者组中拉取消息,并进行处理。消费者可以采用定时任务或后台线程不断轮询。
@slf4j
@service
public class redisstreamconsumerservice {
private static final string stream_key = "mystream"; // redis stream 的名称,这里指定队列名为 "mystream"
private static final string group_name = "mygroup"; // 消费者组的名称,多个消费者可以通过组名共享消费队列
private static final string consumer_name = "consumer-1"; // 消费者的名称,消费者名称在同一消费者组内必须唯一
@autowired
private stringredistemplate redistemplate;
@postconstruct // 使用该注解能让方法在 spring 完成依赖注入后自动调用,用于初始化任务
@async // 将该方法标记为异步执行,允许它在单独的线程中运行,不会阻塞主线程,@enableasync 需要在配置类中启用
public void start() { // 启动方法,在应用启动时执行
// 无限循环,不断从 redis stream 中读取消息(可以改为定时任务等方式)
while (true) {
try {
// 设置 stream 读取的阻塞超时,设置最多等待 2 秒
streamreadoptions options = streamreadoptions.empty().block(duration.ofseconds(2));
// 从指定的消费者组中读取消息,">" 表示只消费未被消费过的消息
list<maprecord<string, object, object>> messages = redistemplate.opsforstream().read(
consumer.from(group_name, consumer_name), // 指定消费者组和消费者名称
options, // 设置读取选项,包含阻塞时间
streamoffset.create(stream_key, readoffset.lastconsumed()) // 从最后消费的消息开始读取
);
// 如果没有消息,继续循环读取
if (messages == null || messages.isempty()) {
continue;
}
// 处理每一条读取到的消息
for (maprecord<string, object, object> message : messages) {
string messageid = message.getid(); // 获取消息的唯一标识符(id)
map<object, object> value = message.getvalue(); // 获取消息内容(以 map 形式存储)
log.info("接收到消息,id={},内容={}", messageid, value); // 打印日志,记录消息 id 和内容
// 在这里加入业务逻辑处理
// 例如处理消息并执行相应的操作
// ...
// 消息处理成功后,需要确认消息已经被消费(通过 xack 命令)
redistemplate.opsforstream().acknowledge(stream_key, group_name, messageid); // 确认消费的消息
}
} catch (exception e) {
log.error("读取 redis stream 消息异常", e); // 异常捕获,记录错误日志
}
}
}
}maprecord<string, object, object> 是 spring data redis 用来表示 redis stream 中的 消息记录 的类。它不仅包含了消息的 id,还包含了消息的内容(即消息数据)。
在 redis 中,每条消息都存储为一个 key-value 对。
主要功能:
- 封装消息 id 和消息内容:
maprecord用来封装消息的 id 和消息的内容。 - 消息的内容:消息的内容通常是一个 键值对(
map<string, object>),可以是任意对象的数据结构(例如,json、map 或其他序列化对象)。
字段:
getid():返回消息的 id(recordid类型)。getvalue():返回消息的内容,以map<object, object>的形式。
使用场景:
maprecord 是用来表示从 stream 中读取到的消息,它将消息的 id 和内容(键值对)封装在一起。你可以使用 maprecord 来获取消息的 id 和内容并处理。
maprecord<string, object, object> message = redistemplate.opsforstream().read(consumer.from("mygroup", "consumer1"), options, streamoffset.create("mystream", readoffset.lastconsumed()));在这个例子中,message 是一个 maprecord 实例,它封装了从 mystream 队列中读取到的消息。我们可以通过 message.getid() 获取消息 id,通过 message.getvalue() 获取消息内容。
在消费者中,我们使用 maprecord<string, object, object> 来封装消息,获取 message.getid() 来获取消息的 id(recordid),以及通过 message.getvalue() 获取消息的内容。 随后在处理完消息后,调用 acknowledge() 来确认消息已经被消费。
最后启动异步支持:
@springbootapplication
@enableasync // 启动异步支持
public class myapplication {
public static void main(string[] args) {
springapplication.run(myapplication.class, args);
}
}通过这种方式,spring data redis 提供了高效且类型安全的接口来操作 redis stream,帮助我们在分布式系统中实现高效的消息队列。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。


发表评论