本文介绍将s3兼容的对象存储用作数据库备份目标所需的概念、要求和组件。 数据库备份和恢复功能在概念上类似于使用sql server备份到azure blob存储的url作为备份设备类型。
要注意的是,不只是amazon s3对象存储,只要兼容s3协议的对象存储都可以备份。
对象存储集成功能
sql server 2022(16.x)引入了对象存储集成功能,使您可以将sql server与s3兼容的对象存储集成。为了提供这种集成,sql server支持一个s3连接器,它使用s3 rest api连接到任何s3兼容的对象存储提供商。sql server 2022(16.x)通过增加对使用rest api的新s3连接器的支持,扩展了现有的backup/restore to/from url命令的语法。
指向s3兼容资源的url以s3://为前缀,表示正在使用s3连接器。以s3://开头的url始终假定底层协议为https。
文件编号和文件大小限制 为了存储数据,s3兼容对象存储提供商必须将文件分割成多个称为“部分”的块,这类似于微软azure blob存储中的块blob。
s3端点的前提条件
s3端点必须按以下方式配置:
1、必须配置tls。假定所有连接将通过https而非http进行安全传输。端点通过安装在sql server操作系统主机上的证书进行验证。
2、在s3兼容的对象存储中创建凭据,具有执行操作所需的适当权限。在存储层上创建的用户和密码被称为访问密钥id(access key id)和秘密密钥id(secret key id)。您需要这两个密钥才能对s3端点进行身份验证。
3、至少配置了一个存储桶。
linux平台支持
sql server使用 winhttp 实现其所使用的http rest api客户端。它依赖操作系统证书存储来验证由http(s)端点提供的tls证书。然而,在linux平台上运行的sql server的ca证书必须放置在一个预定义的位置,即/var/opt/mssql/security/ca-certificates 文件夹中,且该文件夹最多只能存储和支持前50个证书。在启动sql server进程之前,必须将ca证书放置在该位置。sql server在启动时从该文件夹读取证书,并将它们添加到信任存储中。
示例
- 创建凭据
凭据的名称应提供存储路径,并且根据存储平台的不同有多个标准。
当使用s3连接器时,identity应始终为 's3 access key'。 access key id和secret key id中不得包含冒号。 access key id和secret key id是在s3兼容的对象存储上创建的用户名和密码。 access key id 必须具有适当的权限来访问s3兼容的对象存储中的数据。 使用create credential创建服务器级凭据以进行与s3兼容的对象存储端点的身份验证。
aws s3 支持两种不同的 url 标准。
s3://<bucket_name>.s3.<region>.amazonaws.com/<folder>(默认) s3://s3.<region>.amazonaws.com/<bucket_name>/<folder>
代码如下:
use [master];
go
create credential [s3://<endpoint>:<port>/<bucket>]
with
identity = 's3 access key',
secret = '<accesskeyid>:<secretkeyid>';
go
backup database [sqltestdb]
to url = 's3://<endpoint>:<port>/<bucket>/sqltestdb.bak'
with format ,stats = 10, compression;有多种方法可以为aws的s3对象存储创建凭据。
- s3 存储桶名称:datavirtualizationsample
- s3 存储桶区域:us-west-2
- s3 存储桶文件夹:backup
create credential [s3://datavirtualizationsample.s3.us-west-2.amazonaws.com/backup]
with
identity = 's3 access key'
, secret = 'accesskey:secretkey';
go
backup database [adventureworks2022]
to url = 's3://datavirtualizationsample.s3.us-west-2.amazonaws.com/backup/adventureworks2022.bak'
with compression, format, maxtransfersize = 20971520;
go
--或者
create credential [s3://s3.us-west-2.amazonaws.com/datavirtualizationsample/backup]
with
identity = 's3 access key'
, secret = 'accesskey:secretkey';
go
backup database [adventureworks2022]
to url = 's3://s3.us-west-2.amazonaws.com/datavirtualizationsample/backup/adventureworks2022.bak'
with compression, format, maxtransfersize = 20971520;
go备份到 url和从 url 恢复
备份到 url
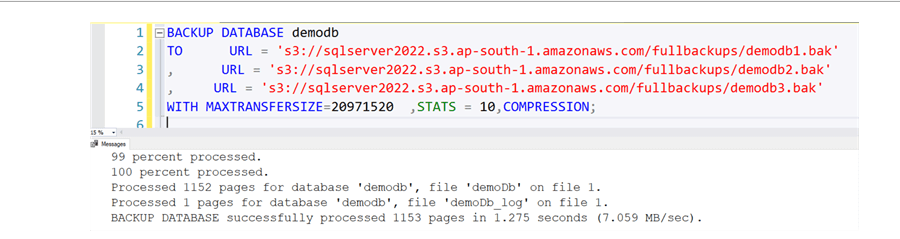
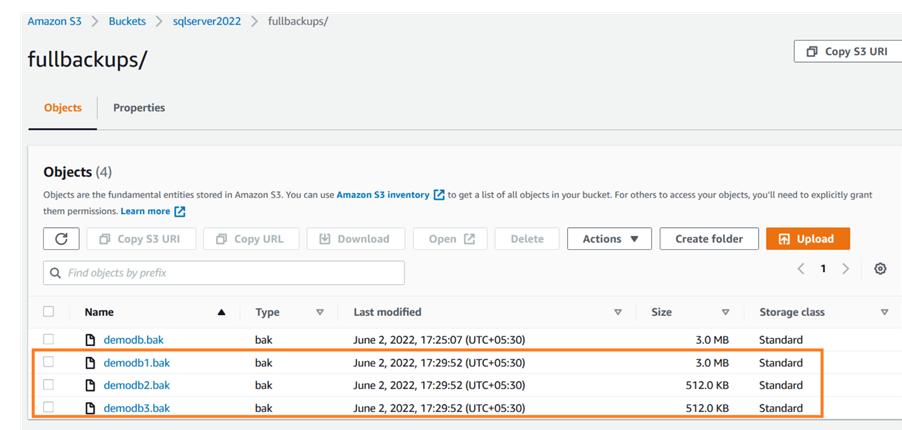
以下示例将执行完整的数据库进行备份文件分割,然后备份到对象存储端点: backup database <db_name> to url = 's3://<endpoint>:<port>/<bucket>/<database>_01.bak' , url = 's3://<endpoint>:<port>/<bucket>/<database>_02.bak' , url = 's3://<endpoint>:<port>/<bucket>/<database>_03.bak' with format ,stats = 10, compression;
从 url 恢复
以下示例将从对象存储端点位置执行数据库恢复: restore database <db_name> from url = 's3://<endpoint>:<port>/<bucket>/<database>_01.bak' , url = 's3://<endpoint>:<port>/<bucket>/<database>_02.bak' , url = 's3://<endpoint>:<port>/<bucket>/<database>_03.bak' with replace , stats = 10;
加密和压缩备份选项
以下示例展示如何使用加密和压缩来备份和恢复 adventureworks2022 数据库:
create master key encryption by password = <password>;
go
create certificate adventureworks2022cert
with subject = 'adventureworks2022 backup certificate';
go
-- 备份数据库
backup database adventureworks2022
to url = 's3://<endpoint>:<port>/<bucket>/adventureworks2022_encrypt.bak'
with format, compression,
encryption (algorithm = aes_256, server certificate = adventureworks2022cert)
go
-- 恢复数据库
restore database adventureworks2022
from url = 's3://<endpoint>:<port>/<bucket>/adventureworks2022_encrypt.bak'
with replace使用区域参数进行备份和恢复
以下示例展示如何使用region_options选项进行备份和恢复 adventureworks2022 数据库:
您可以在每个backup / restore命令中添加区域参数。 请注意,在backup_options和restore_options中使用了s3存储特定的区域字符串, 例如 '{"s3": {"region":"us-west-2"}}'。默认区域是 us-east-1。
-- 备份数据库
backup database adventureworks2022
to url = 's3://<endpoint>:<port>/<bucket>/adventureworks2022.bak'
with backup_options = '{"s3": {"region":"us-west-2"}}'
-- 恢复数据库
restore database adventureworks2022
from url = 's3://<endpoint>:<port>/<bucket>/adventureworks2022.bak'
with restore_options = '{"s3": {"region":"us-west-2"}}'sql server 2008的压缩备份是一个新特性,根据实际使用中的观察,压缩比至少在1:5左右,也就是备份时增加了压缩选项(compression)后可以至少压缩到数据文件大小的20%甚至更低,
可以很大程度上加快备份执行时间,减轻io压力和节省备份服务器的磁盘存储空间。
-- 备份数据库 backup database sqltestdb to disk = 'c:\tmp\sqltestdb.bak' with stats =5 , compression go
总结
sql server 2022通过新引入的s3连接器,sql server能够支持通过rest api与s3兼容存储集成。用户可以配置存储桶和凭据,通过url指向存储位置进行备份和恢复。此外,还提供了加密、压缩等备份选项,以及在linux平台上的特殊配置要求。示例展示了如何创建凭据、执行备份和恢复操作,支持区域参数指定备份和恢复的地域。
参考文章
https://learn.microsoft.com/en-us/sql/relational-databases/backup-restore/sql-server-backup-to-url-s3-compatible-object-storage?view=sql-server-ver16&viewfallbackfrom=sql-server-ver15
https://aws.amazon.com/cn/blogs/modernizing-with-aws/backup-sql-server-to-amazon-s3/
https://www.mssqltips.com/sqlservertip/7302/backup-sql-server-2022-database-aws-s3-storage/
到此这篇关于sql server 2022新功能:将数据库备份到s3兼容的对象存储的文章就介绍到这了,更多相关sql server数据库备份到s3兼容的对象存储内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!


发表评论