需求来源
今天甲方这边要查看一个机车的周时数据(就是一个机车从到我的管辖范围内,到出我的管辖内所用的时间),那这个它会跑很多次,我们要查询这一天的周时数据,锚定一个点比如出管辖区的时间,那么根据查询到今天所有这个时间范围内出去的车信息,然后去数据表里找这个机车进来的数据且时最新的一条就行了。
实现思路
分两次查询的第一次查询出来所有的当天出管辖区的机车信息,第二个查询是根据第一个查询小小的改动,把时间范围去掉就好,然后根据机车信息进行组取时间每个机车时间最新的数据就好。直接使用group by,但是这个并不能取出其它的信息所以就pass掉了。gptl了一下给的方案是使用partition这个功能。
实施
就不看项目数据了就看一下我写的小demo的结果吧。我有一个student表,这个表里有10个班的学生,每个班的学生有20个,我现在要取出每个班的学生id最大的这个记录,就可以使用这个partition了。
select * from (select *, row_number() over (partition by classes_id order by id desc) as rn from `student`) a where rn=1
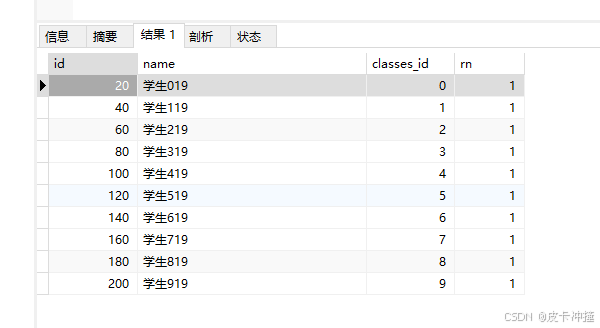
解释一下这个啊。
这条 sql 语句使用了窗口函数 row_number() 来为每个 classes_id 组中的行编号,并在外部查询中只选择每个 classes_id 组中的最新一行(根据 id 倒序排序)。以下是对这条 sql 语句的详细解释:
sql 语句结构
select *
from (
select *,
row_number() over (partition by classes_id order by id desc) as rn
from `student`
) a
where rn = 1;内部查询(子查询)
select *,
row_number() over (partition by classes_id order by id desc) as rn
from `student`select *:
选择 student 表中的所有列。
row_number() over (partition by classes_id order by id desc) as rn:
row_number()是一个窗口函数,它为结果集中的每一行分配唯一的行号。over子句定义了窗口的分区和排序规则:partition by classes_id:将结果集按classes_id列进行分组。对于每个classes_id,将重新开始编号。order by id desc:在每个classes_id分区中,按照id列的降序排序。
as rn:将生成的行号列命名为rn。
这部分查询为每个 classes_id 组中的行编号,编号从1开始,按照 id 倒序排列。因此,rn 为1的行是每个 classes_id 组中 id 最大的行。
外部查询
select *
from (
select *,
row_number() over (partition by classes_id order by id desc) as rn
from `student`
) a
where rn = 1;from (...) a:
将内部查询的结果作为一个临时表 a。
where rn = 1:
筛选出临时表 a 中 rn 等于 1 的行,即每个 classes_id 组中 id 最大的行。 结果
整个查询的作用是:
- 对
student表进行分组(按classes_id)。 - 在每个
classes_id组中,按id倒序排列,并为每行分配一个行号rn。 - 选择每个
classes_id组中rn等于 1 的行(即每个classes_id组中id最大的行)。
partition的升级使用
partition不仅仅可以在日常查询中使用,还可以在表的数据结构上进行优化,比如在建表的时候创建分区或者后期添加分区,这个分区操作是在物理上的操作,可以看我下面这张表的结构,有一部分注释说明就是分区的设置,
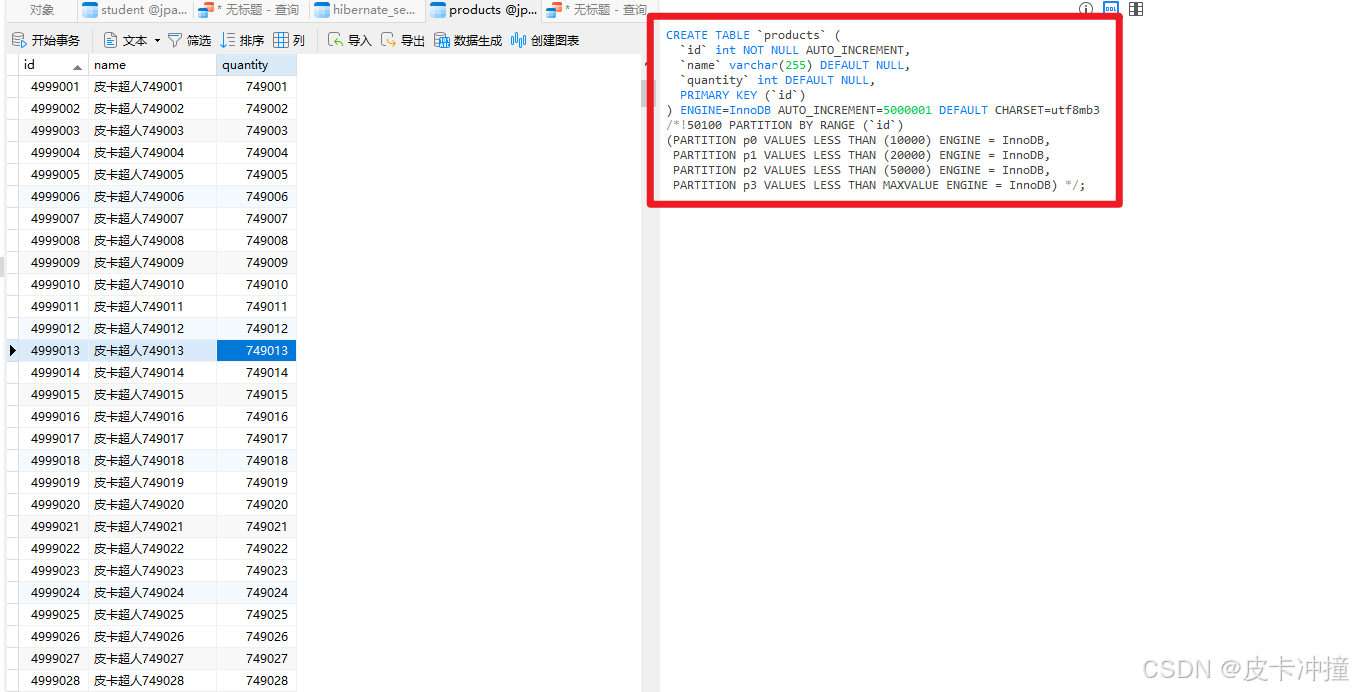
对表进行分区可以提升查询性能和数据管理的效率。由于 engine=myisam 不支持分区,我们需要将表的存储引擎更改为 innodb,因为 innodb 支持分区。
假设我们要根据 id 列进行范围分区,将数据划分为四个分区:
p0:包含id小于 10000的数据。p1:包含id小于 20000的数据。p2:包含id小于 50000的数据。p3:包含其余的数据。
partition by range (id) (
partition p0 values less than (10000),
partition p1 values less than (20000),
partition p2 values less than (50000),
partition p3 values less than maxvalue
);解释
partition by range (id): 根据id列进行范围分区。partition p0 values less than (10000): 第一个分区,包含id小于 10000的数据。partition p1 values less than (20000): 第二个分区,包含id小于 20000的数据。partition p2 values less than (50000): 第三个分区,包含id小于 50000的数据。partition p3 values less than maxvalue: 第四个分区,包含id大于等于 50000的数据。
这样,表 products 就被划分为四个分区,每个分区包含一定范围的 id 值的数据。
验证一下看看分区
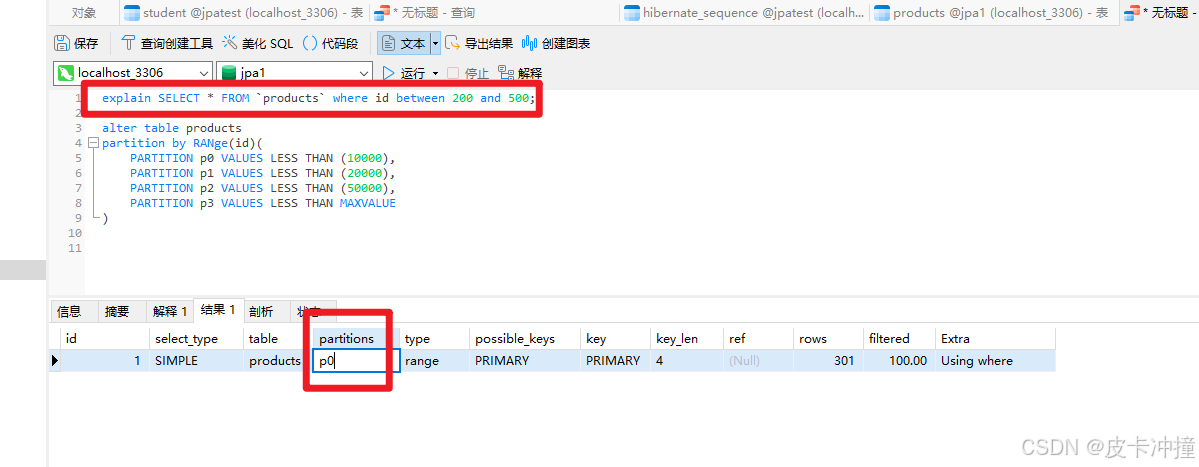
上面说了创建分区了,但是怎么才能确定我们的查询sql使用到了分区呢?使用explain来查看执行的sql有没有在分区的范围呢,
下面是使用了explain查看执行的sql有没有用到分区,partition的值为p0对应了上面设置的分区。
分区的一些操作
创建分区后,数据库管理系统会自动处理分区的数据存储和检索,用户在日常操作中并不需要特殊处理分区。不过,你可以通过一些特定的查询和操作来利用分区的优势。以下是一些常见的用法示例:
1. 普通查询
普通的查询不需要特别处理分区,数据库管理系统会自动根据分区优化查询:
select * from student where id < 50;
2. 分区表上的查询优化
当你的查询条件包含分区键时,数据库会自动选择相关的分区进行查询,从而提高查询性能。例如:
select * from student where id between 50 and 100;
3. 插入数据
插入数据时,数据库会根据分区键自动将数据插入到相应的分区:
insert into student (name, classes_id) values ('alice', 1);4. 删除分区中的数据
可以通过分区键删除特定分区中的数据:
delete from student where id < 50;
5. 分区维护操作
你可以进行一些特定的分区维护操作,例如合并分区、拆分分区、删除分区等:
添加新的分区
alter table student add partition (
partition p4 values less than (200)
);删除分区
alter table student drop partition p0;
重组分区
可以将多个分区合并为一个分区:
alter table student reorganize partition p1, p2 into (
partition p1_2 values less than (150)
);6. 检查分区信息
你可以使用 show 语句查看表的分区信息:
show create table student;
总结
综合示例展示了如何创建分区表、插入数据以及进行查询和维护操作:
-- 创建分区表
create table `student` (
`id` int not null auto_increment,
`name` varchar(255) default null,
`classes_id` int default null,
primary key (`id`),
key `fk4l5dnicegnvpmu0pv6vdvrmb6` (`classes_id`)
) engine=innodb auto_increment=201 default charset=utf8mb3
partition by range (id) (
partition p0 values less than (50),
partition p1 values less than (100),
partition p2 values less than (150),
partition p3 values less than maxvalue
);
-- 插入数据
insert into student (name, classes_id) values ('alice', 1);
insert into student (name, classes_id) values ('bob', 2);
-- 查询数据
select * from student where id < 50;
-- 删除分区中的数据
delete from student where id < 50;
-- 添加新分区
alter table student add partition (
partition p4 values less than (200)
);
-- 删除分区
alter table student drop partition p0;
-- 检查分区信息
show create table student;目前先整理这么多,以后有深入学习使用了再继续!!!
到此这篇关于sql中的partition分区功能使用的文章就介绍到这了,更多相关sql partition分区内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论