jmx_exporter 主要用于从 java 应用程序中提取 jmx 指标,通常包括 jvm级别的信息,如内存使用情况、线程状态、垃圾回收次数等。
对于传统的springboot应用,由于它默认没有内置 prometheus 监控的指标,因此使用 jmx_exporter来抓取基础的jvm相关指标。
如果想要获取更细粒度的应用级别的业务指标,例如 http 请求数、处理时间或业务操作的计数,则需要在应用中集成 prometheus 客户端库,并自定义相应的指标。
1、下载jmx-exporter
1. 访问github下载
下载地址:https://github.com/prometheus/jmx_exporter
在release里面下载jar包即可,如下是最新版本
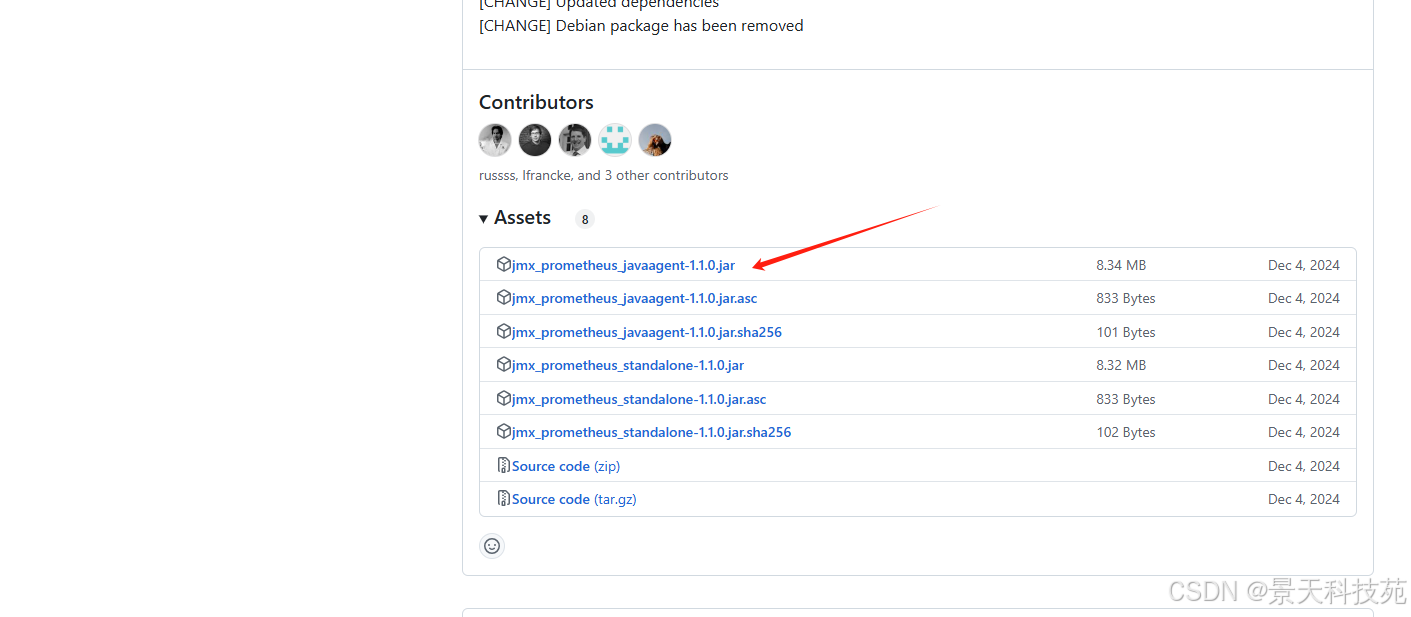
我们使用0.20.0版本
创建个目录
mkdir /etc/jmx_exporter
将下载好的jar包上传上来

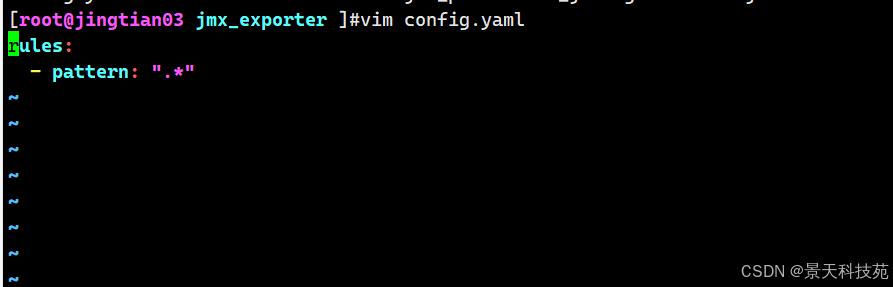
2. 准备config.yml配置文件
规则文件可以定义要暴露哪些指标给prometheus
[root@jingtian03 jmx_exporter ]#vim config.yaml rules: - pattern: ".*"
2、运行springboot应用
1. 安装java基础环境
注意,下载的java版本和maven版本要对应,并且spring boot程序的版本也要对应
yum install java-17-openjdk maven-openjdk17 -y
替换下maven的配置文件,连到阿里云,编译项目会快一些
git clone https://github.com/littlefun91/mavendata.git cd mavendata/ cp settings.xml /etc/maven/
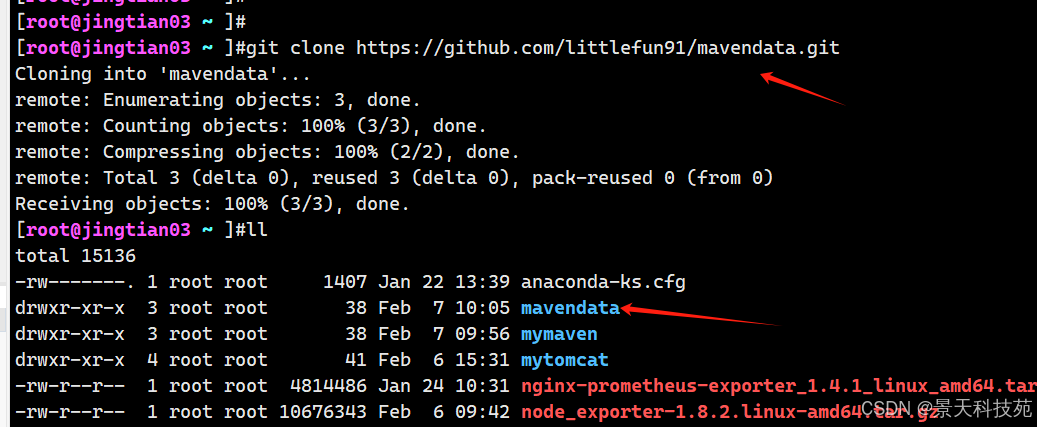
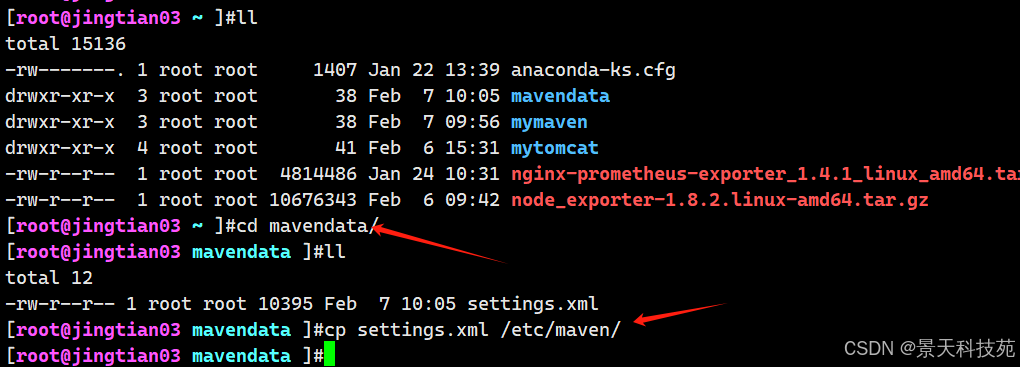
2. 下载java应用然后进行编译
如果自己有,也可以用自己的java应用测试
git clone https://github.com/littlefun91/springbootdemo.git
解压,打包
tar xf springboot-devops-myapp-java11-jar.tar.gz cd springboot-devops-demo-jar-java17/ mvn package
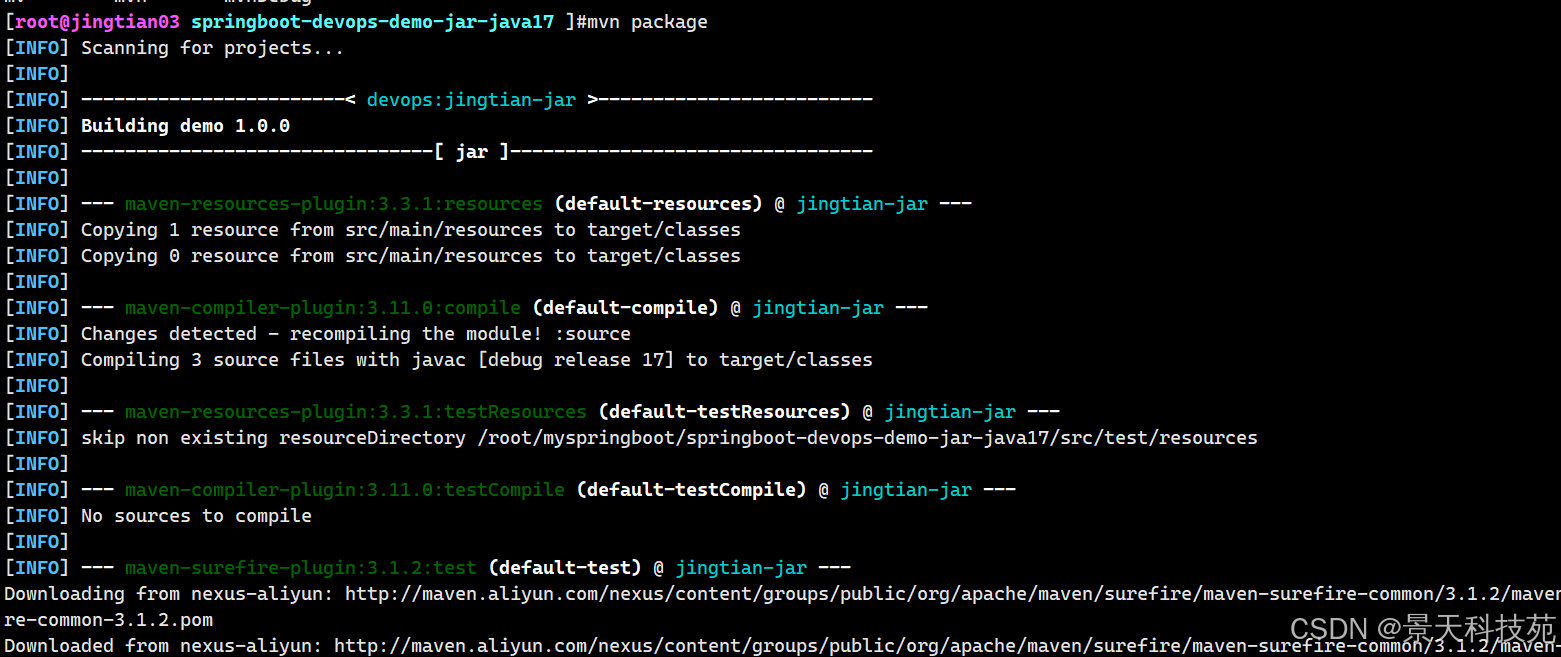
编译成功标志
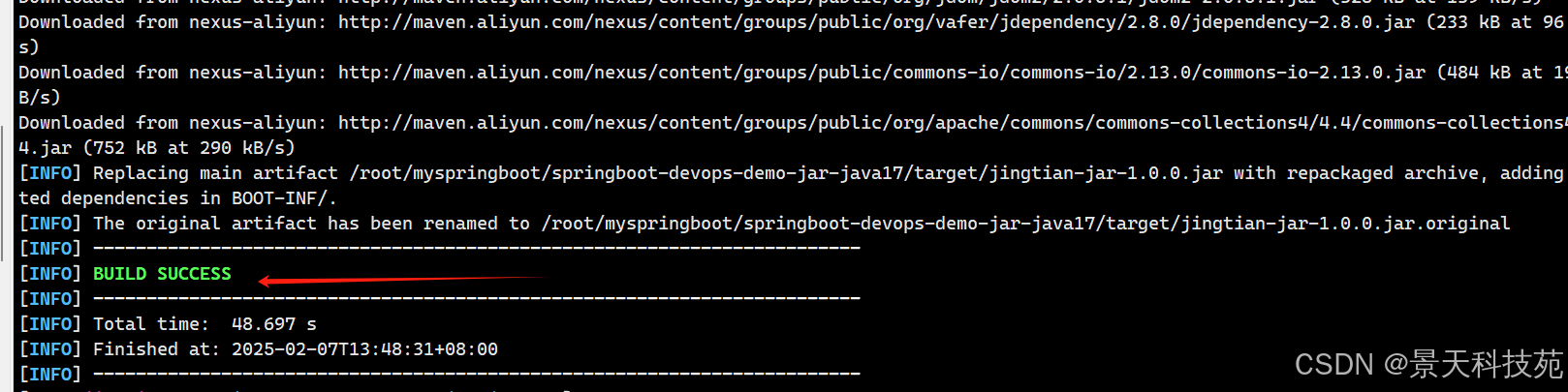
编译好之后会生成一个target目录
里面有生成的jar包文件
3. 运行java应用,并加载jmx监控,监听12345端口
<path_to_jmx_exporter.jar>=<exporter_port>:<path_to_config.yaml>
因此,工作中,我们如果需要监控java程序,则在java运行时加上jmx监控端口即可暴露出metrics
nohup java \ -javaagent:/etc/jmx_exporter/jmx_prometheus_javaagent-0.20.0.jar=12345:/etc/jmx_exporter/config.yaml \ -jar -xms50m -xmx50m target/jingtian-jar-1.0.0.jar \ --server.port=8081 &>/var/log/springboot.log &
4. 检查对应的端口是否正常
查看metrics
3、配置prometheus
1)修改prometheus配置
vim /etc/prometheus/prometheus.yml
- job_name: "jmx_exporter"
static_configs:
- targets: ["jingtian03:12345"]
2)重新加载prometheus配置文件
curl -x post http://localhost:9090/-/reload
3)检查prometheus的status->targets页面,验证 jmx_exporter 是否已经成功纳入监控中

4、jvm常用指标与示例 1)jvm内存使用相关指标(tomcat也有这些指标)
初始堆内存和最大堆内存都是启动java程序的时候设置的

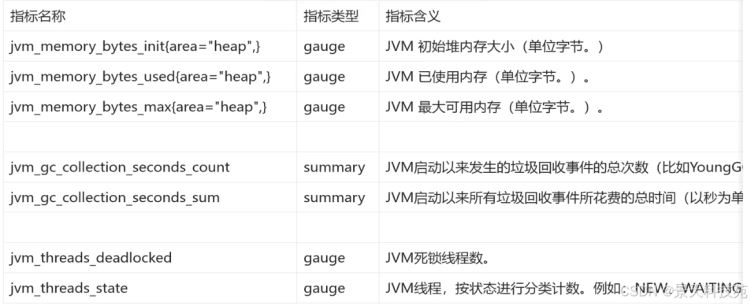
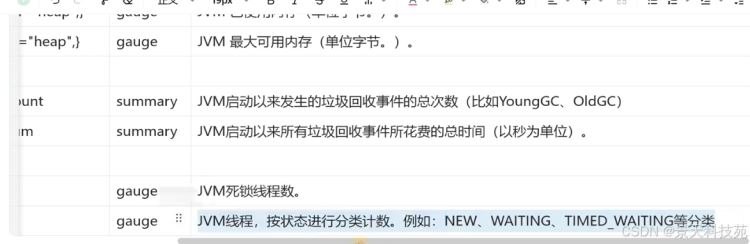
注意:最新版的jmx中的指标对应的是
jvm_memory_init_bytes{area=“heap”}
jvm_memory_used_bytes{area=“heap”}
jvm_memory_max_bytes{area=“heap”}
area=“heap” 为堆内存
area=“nonheap” 为非堆内存
我们主要看堆内存
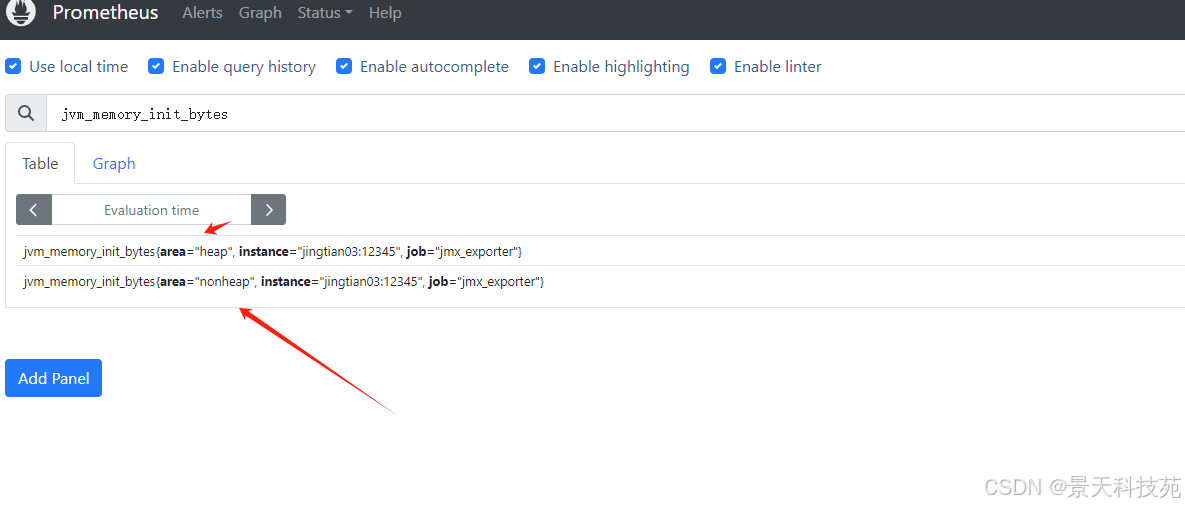
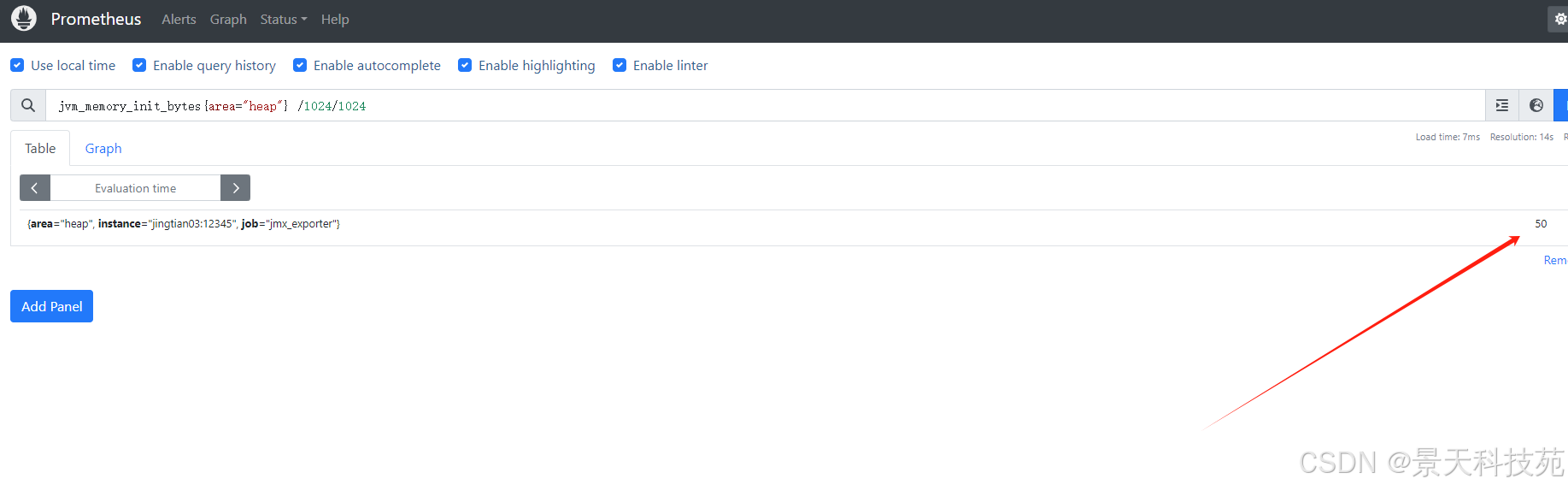
案例1:jvm堆内存使用率。计算公式:已用堆内存 / 总的堆内存 * 100
jvm_memory_used_bytes{<!--{c}%3c!%2d%2d%20%2d%2d%3e-->area="heap"} / jvm_memory_max_bytes{<!--{c}%3c!%2d%2d%20%2d%2d%3e-->area="heap"} *100

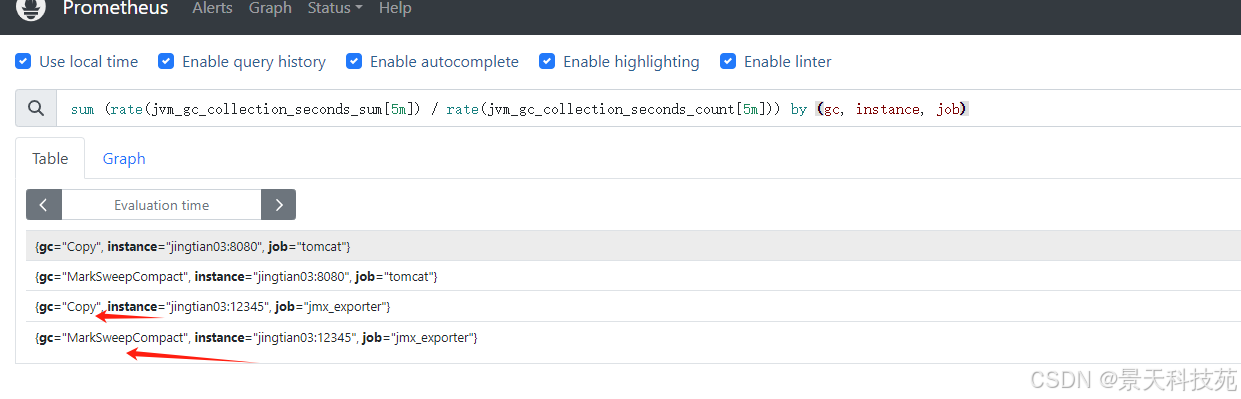
案例2:计算jvm,新生代和老年代,每次gc所需时间,因为这两个指标是不断累积的,因此计算公式:rate(jvmgc花费总时间[1m]) / rate(jvmgc总次数[1m])
java采用分代回收,分为年轻代、老年代、永久代。年轻代又分为e区、s1区、s2区。
到jdk1.8,永久代被元空间取代了。
年轻代都使用复制算法,老年代的收集算法看具体用什么收集器。默认是ps收集器,采用标记-整理算法。
# 如果jvm_gc_collection_seconds_count是100次,而jvm_gc_collection_seconds_sum是50秒,那么平均每次gc耗时是0.5秒。 sum (rate(jvm_gc_collection_seconds_sum[5m]) / rate(jvm_gc_collection_seconds_count[5m])) by (gc, instance, job)
案例3:计算jvm最近5分钟,最小的死锁线的程数,是否高于10
min_over_time(jvm_threads_deadlocked[5m])

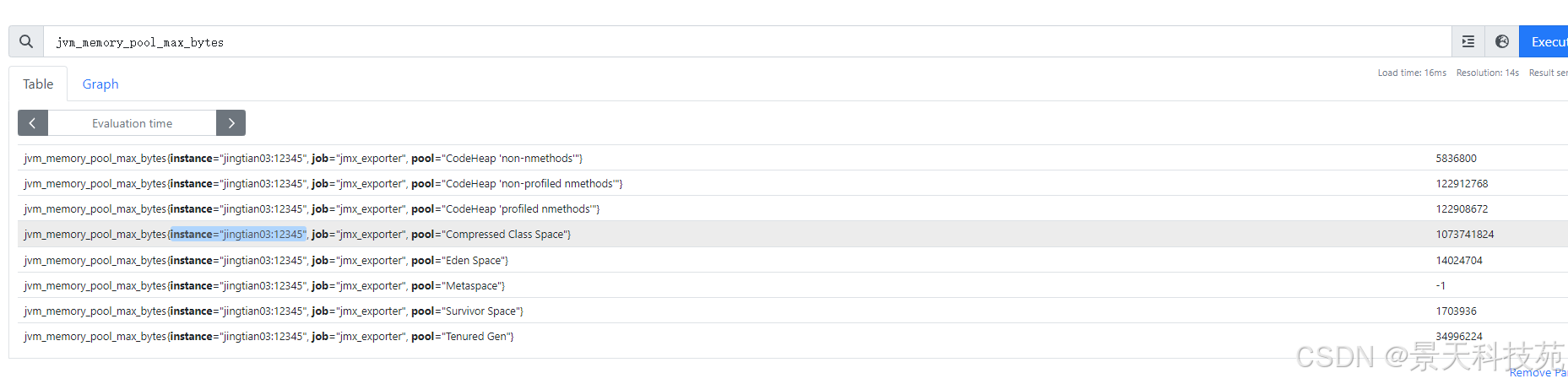
5)jvm堆内存分配相关指标(可以查看新生代、老年代分别使用了多少内存,粒度更细一些)

最新版的jmx对应的指标是:
jvm_memory_pool_used_bytes
jvm_memory_pool_max_bytes
5、jmx告警规则文件
1)编写jvm告警规则文件
cat /etc/prometheus/rules/jvm_rules.yml
groups:
- name: "jvm告警规则"
rules:
- alert: jvm堆内存使用率过高
expr: jvm_memory_bytes_used{area="heap",} / jvm_memory_bytes_max{area="heap",} * 100 > 80
for: 1m
labels:
severity: critical
annotations:
summary: "jvm 堆内存使用率过高, 实例:{{ $labels.instance }}, job:{{ $labels.job }} "
description: "jvm堆内存使用率超过80%, 当前值 {{ $value }}%"
- alert: jvmgc时间过长
expr: sum (rate(jvm_gc_collection_seconds_sum[5m]) / rate(jvm_gc_collection_seconds_count[5m])) by (gc, instance, job) > 1
for: 1m
labels:
severity: critical
annotations:
summary: "jvm gc时间过长, 实例:{{ $labels.instance }}, job:{{ $labels.job }} "
description: "jvm {{ $labels.gc }} 的回收时间超过1s,当前值 {{ $value}}s"
- alert: jvm死锁线程过多
expr: min_over_time(jvm_threads_deadlocked[5m]) > 0
for: 1m
labels:
severity: critical
annotations:
summary: "jvm检测到死锁线程"
description: "在过去5分钟内jvm检测到存在死锁线程, 当前值 {{ $value }}。"
2)验证规则文件

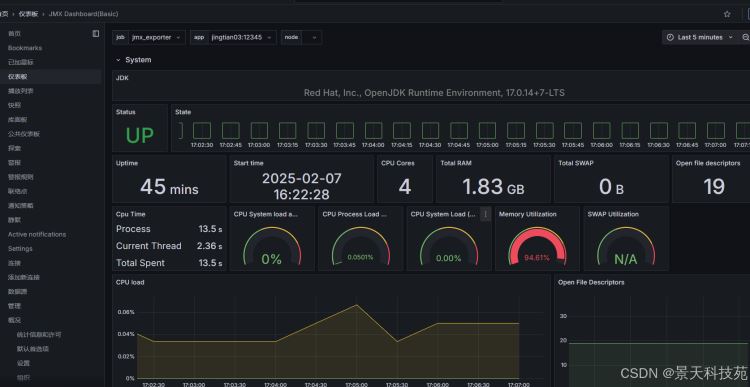
3)导入jmx图形
导入一个jvm的grafana模板。dashboard id为 14845
以上就是通过prometheus监控springboot程序运行状态的操作流程的详细内容,更多关于prometheus监控springboot运行状态的资料请关注代码网其它相关文章!




发表评论