前言
找到位置,签名的话见:java操作itextpdf实现pdf添加文字,图片和签名
新项目可以尝试一下 itext 7 , 我这边是老项目所以还是继续使用 itext 5,主打够用
itext 5 没有直接提供获取文本精确位置的功能。它只能提取文本内容,而文本位置通常需要通过额外的解析和计算来确定。
思路:在同一行,且一些词是连续的,前后没有空白字符串,即认为是一个词
需要特殊处理:
- “姓 名:” 中间有空格
- 读取pdf时,有些肉眼看上去是一行的字,可能会被解析为多个,导致找不到满足条件的关键字
效果如下
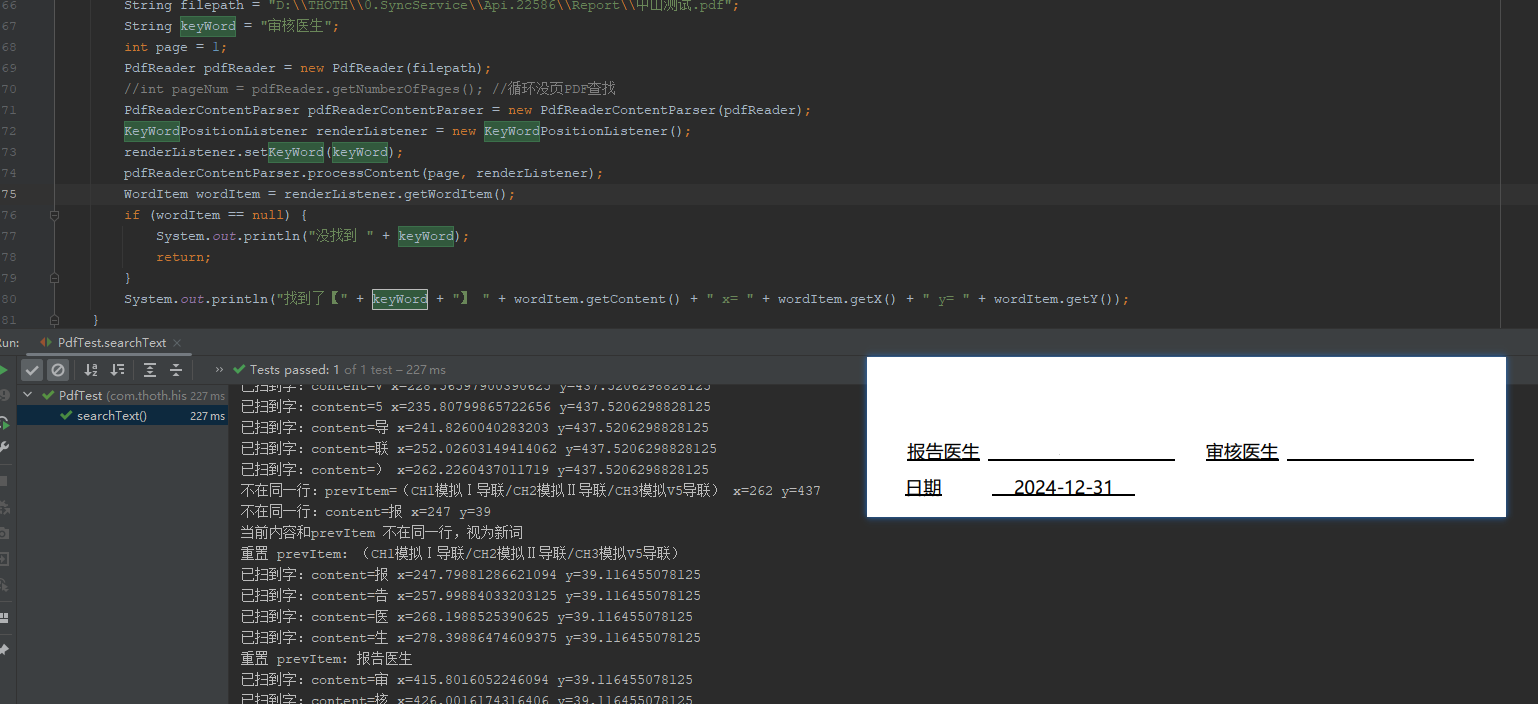
添加引用
<itextpdf.version>5.5.13</itextpdf.version>
<itext-asian.version>5.2.0</itext-asian.version>
<dependency>
<groupid>com.itextpdf</groupid>
<artifactid>itextpdf</artifactid>
<version>${itextpdf.version}</version>
</dependency>
<!--没有这个的话,添加文字会报错-->
<dependency>
<groupid>com.itextpdf</groupid>
<artifactid>itext-asian</artifactid>
<version>${itext-asian.version}</version>
</dependency>
添加工具类
package com.vipsoft.web;
import cn.hutool.core.util.strutil;
import com.itextpdf.text.pdf.parser.imagerenderinfo;
import com.itextpdf.text.pdf.parser.renderlistener;
import com.itextpdf.text.pdf.parser.textrenderinfo;
import com.itextpdf.awt.geom.rectangle2d.float;
import java.util.arraylist;
import java.util.list;
public class keywordpositionlistener implements renderlistener {
/**
* 用来存储页面上所有的词
* - 排除连续空格
*/
private list<worditem> allitems = new arraylist<worditem>();
/**
* 搜索关键词
*/
private string keyword;
/**
* 是否是新的词
*/
private boolean newword = false;
/**
* 记录上一个字符 -- 用于判断是否是一组词
*/
private worditem previtem = new worditem();
/**
* 已找到的词信息
*/
private worditem worditem;
public worditem getworditem() {
return worditem;
}
public void setkeyword(string keyword) {
this.keyword = keyword;
}
@override
public void begintextblock() {
// todo auto-generated method stub
}
/**
* 方法会在解析文本时被调用,它检查每个文本片段是否包含关键词,并记录其位置。
*
* @param renderinfo
*/
@override
public void rendertext(textrenderinfo renderinfo) {
if (worditem != null || strutil.isempty(keyword)) {
return;
}
// 读取pdf时,有些肉眼看上去是一行的字,可能会被解析为多个,导致找不到满足条件的关键字,这里做了简单的处理
// 即如果一些词是连续的,前后没有空白字符串,即认为是一个词
string content = renderinfo.gettext().trim();
float textrectangle = renderinfo.getbaseline().getboundingrectange();
if (strutil.isempty(content)) {
// 当前扫出来的是空字符串,视新一个新的词即将开始
newword = true;
// system.out.println("扫出空的,跳过 x=" + textrectangle.getx() + " y=" + textrectangle.gety());
return;
}
if (strutil.isempty(previtem.getcontent())) {
// 这段可以不需要
// previtem 中还没有存内容的,当前文字也视为新的词
newword = true;
// system.out.println("previtem 中还没有存内容的,视为新词");
}
if (strutil.isnotempty(previtem.getcontent()) && (math.abs((int) previtem.gety() - (int) textrectangle.gety()) > 5)) {
//y 正负2内,视为同一行
system.out.println("不在同一行:previtem=" + previtem.getcontent() + " x=" + (int) previtem.getx() + " y=" + (int) previtem.gety());
system.out.println("不在同一行:content=" + content + " x=" + (int) textrectangle.getx() + " y=" + (int) textrectangle.gety());
system.out.println("当前内容和previtem 不在同一行,视为新词");
newword = true;
}
if (newword) {
//重置
system.out.println("重置 previtem: " + previtem.getcontent());
previtem = new worditem();
}
system.out.println("已扫到字:content=" + content + " x=" + textrectangle.getx() + " y=" + textrectangle.gety());
string precontent = strutil.isnotempty(previtem.getcontent()) ? previtem.getcontent() : "";
previtem.setcontent(precontent + content);
previtem.setx(textrectangle.getx());
previtem.sety(textrectangle.gety());
if (previtem.getcontent().contains(keyword)) {
//system.out.println("找到了【" + keyword + "】 " + previtem.getcontent() + " x= " + previtem.getx() + " y= " + previtem.gety());
worditem = previtem;
}
newword = false;
}
@override
public void endtextblock() {
// todo auto-generated method stub
}
@override
public void renderimage(imagerenderinfo renderinfo) {
// todo auto-generated method stub
}
}
/**
* 存储一个词的信息
*/
class worditem {
private string content;
private double x;
private double y;
... getters and setters ...
}
调用
@test
void searchtext() throws exception {
string filepath = "d:\\report.pdf";
string keyword = "审核医生";
int page = 1;
pdfreader pdfreader = new pdfreader(filepath);
//int pagenum = pdfreader.getnumberofpages(); //循环没页pdf查找
pdfreadercontentparser pdfreadercontentparser = new pdfreadercontentparser(pdfreader);
keywordpositionlistener renderlistener = new keywordpositionlistener();
renderlistener.setkeyword(keyword);
pdfreadercontentparser.processcontent(page, renderlistener);
worditem worditem = renderlistener.getworditem();
if (worditem == null) {
system.out.println("没找到 " + keyword);
return;
}
pdfreader.close() //记得要关闭,否则文件想做其它操作会报被占用
system.out.println("找到了【" + keyword + "】 " + worditem.getcontent() + " x= " + worditem.getx() + " y= " + worditem.gety());
}到此这篇关于java使用itextpdf找出pdf中文字的坐标的文章就介绍到这了,更多相关java itextpdf找出pdf文字坐标内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论