1、什么是tika
tika是一款apache开源的,跨平台,支持多品种文本类型的内容检测和提取工具。apache官方的介绍如下:apache tika™ 工具包可检测并提取一千多种不同文件类型(如 ppt、xls 和 pdf)中的元数据和文本。所有这些文件类型都可以通过一个界面进行解析,这使得 tika 可用于搜索引擎索引、内容分析、翻译等。

2、基本特性
跨平台:tika 可以在多种操作系统上运行,包括 windows、linux 和 mac os。
支持多种格式:tika 支持多种文件格式,包括常见的文档、图片、音频和视频格式。
可扩展性:tika 的设计是模块化的,允许开发者添加新的解析器来支持新的文件格式。
安全性:tika 提供了防止文件注入攻击的机制,确保在处理用户上传的文件时保持安全性。
3、tika可视化提取
tika提供了可视化界面工具,可以直接通过可视化工具手动提取我们想要的文本内容。可视化工具需要下载tika-app.jar包,下载后,直接执行java -jar tika-app-2.9.2.jar,即可唤起程序主页面:
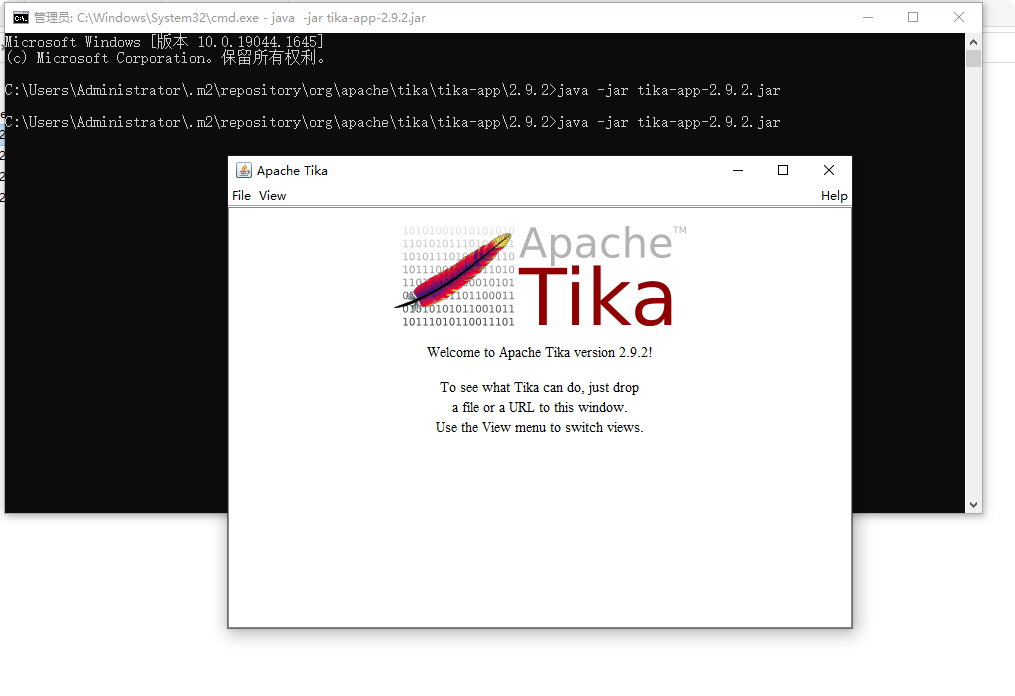
打开我们需要提取的文本,点击view -> 即可提取我们想要的格式。
4、springboot集成
4.1、maven依赖
<dependencies>
<dependency>
<groupid>org.apache.tika</groupid>
<artifactid>tika-core</artifactid>
<version>2.9.2</version>
</dependency>
<dependency>
<groupid>org.apache.tika</groupid>
<artifactid>tika-parsers-standard-package</artifactid>
<version>2.9.2</version>
</dependency>
</dependencies>4.2、tika配置文件
tika-config.xml:
<?xml version="1.0" encoding="utf-8"?>
<properties>
<encodingdetectors>
<!-- 检测 html 文件的字符编码,它会根据 html 元素(如 <meta> 标签)中的声明来判断编码。 -->
<encodingdetector class="org.apache.tika.parser.html.htmlencodingdetector">
<params>
<!-- 读取的最大字节数(这里是 64,000 字节)用于判断编码 -->
<param name="marklimit" type="int">64000</param>
</params>
</encodingdetector>
<!-- tika 的通用编码检测器 -->
<encodingdetector class="org.apache.tika.parser.txt.universalencodingdetector">
<params>
<param name="marklimit" type="int">64000</param>
</params>
</encodingdetector>
<!-- 基于 icu4j 库的编码检测器。icu4j 是一个强大的国际化库,能够更准确地检测多语言文本的编码。 -->
<encodingdetector class="org.apache.tika.parser.txt.icu4jencodingdetector">
<params>
<param name="marklimit" type="int">64000</param>
</params>
</encodingdetector>
</encodingdetectors>
</properties>4.3、注入tika bean
@configuration
public class applicationtikaconfig {
@autowired
private resourceloader resourceloader;
@bean
public tika tika() throws tikaexception, ioexception, saxexception {
resource resource = resourceloader.getresource("classpath:tika-config.xml");
inputstream inputstream = resource.getinputstream();
tikaconfig config = new tikaconfig(inputstream);
detector detector = config.getdetector();
parser autodetectparser = new autodetectparser(config);
return new tika(detector, autodetectparser);
}
}4.4、service类
@service
public class tikaparserservice {
@autowired
private tika tika;
public void parser(path srcpath) throws tikaexception, ioexception {
string result = tika.parsetostring(srcpath);
system.out.println(result);
}
}4.5、测试类tikaparserdemotest
@springboottest(classes = main.class)
@runwith(springrunner.class)
public class tikaparserdemotest {
@autowired
private tikaparserservice tikaparserservice;
@test
public void testtikaparser() throws tikaexception, ioexception {
tikaparserservice.parser(paths.get("f:", "java开发手册(黄山版).pdf"));
}
}运行结果:
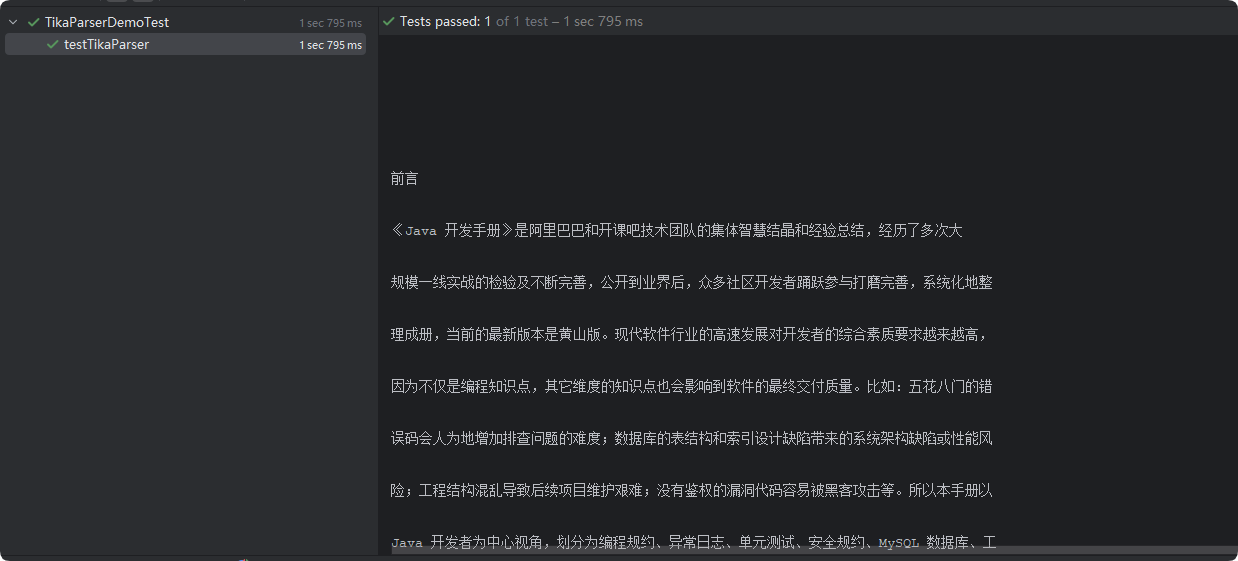
到此这篇关于springboot集成tika实现文档解析的文章就介绍到这了,更多相关springboot tika文档解析内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论