一、前言
ai工具的使用让数据检索的需求场景变得越来越多,也越来越复杂,传统的关系型数据库尽管可以满足日常各类关系数据的存储,但是遇到一些文档类型,非结构化的数据时,其作用和效果就会打折扣,而且数据不仅仅是存储的需要,也需要能够满足数据分析的场景,这种情况下,就可以考虑使用向量数据库了。
二、向量数据库介绍
2.1 什么是向量数据库
向量数据库是一种优化后的数据库系统,专门设计用于高效地存储和检索高维向量数据。这些向量数据通常是从原始数据(如文本、图像、音频等)中提取的特征表示。向量数据库的核心优势在于其能够快速地进行相似性搜索,即找到与给定向量最相似的向量。
2.2 向量数据库特点
向量数据库主要具备如下特征:
- 高效相似性搜索
- 支持多种相似性度量,如欧氏距离(l2)、余弦相似度、jaccard 相似度等。
- 使用特殊的索引结构(如局部敏感哈希lsh、近似最近邻ann等)来加速相似性搜索。
- 高维数据处理:
- 优化了高维向量数据的存储和检索,能够在大规模数据集中高效地进行相似性搜索。
- 支持分布式存储和计算,能够轻松扩展到多个节点。
- 灵活的数据模型:
- 通常采用无模式或半结构化数据模型,允许灵活地存储和处理不同类型的向量数据。
- 支持元数据存储,可以将向量数据与相关的元数据(如标签、时间戳等)一起存储。
- 实时和批量处理:
- 支持实时插入和查询,适用于在线推荐系统等实时应用场景。
- 也支持批量数据插入和查询,适用于离线数据分析和处理。
2.3 向量数据库使用场景
在下面的一些场景中可以考虑使用向量数据库
- 推荐系统:
- 通过用户行为数据生成用户和物品的向量表示,用于推荐相似的物品或用户。
- 例如,电商网站可以根据用户的浏览和购买历史生成用户向量,推荐相似的商品。
- 图像搜索:
- 将图像转换为向量表示,用于相似图像的搜索和检索。
- 例如,搜索引擎可以根据上传的图片找到相似的图片。
- 生物信息学:
- 将dna序列或其他生物数据转换为向量表示,用于基因相似性搜索和分析。
- 例如,研究人员可以使用向量数据库来寻找与已知基因序列相似的新基因。
- 自然语言处理:
- 将文本转换为向量表示,用于文本相似性搜索、情感分析、机器翻译等任务。
- 例如,聊天机器人可以根据用户输入的文本生成向量,找到最合适的回复。
- 广告推荐:
- 根据用户的兴趣和行为生成用户向量,推荐相关的广告。
- 例如,社交媒体平台可以根据用户的兴趣生成用户向量,推荐相关的广告内容。
三、常用的向量数据库解决方案
向量数据库的选择也比较多,下面列举几种常用的向量数据库解决方案。
3.1 milvus
3.1.1 milvus是什么
milvus 是一个高性能的向量数据库,由 zilliz 开发并维护。它支持多种相似性度量(如欧氏距离、余弦相似度等),并使用高效的索引结构(如 ivf、hnsw 等)来加速相似性搜索。milvus 可以处理大规模的向量数据集,并支持分布式部署,适用于多种应用场景。milvus 在推荐系统、图像搜索、自然语言处理等领域表现出色,能够快速地进行相似性搜索,找到与给定向量最相似的向量。
3.1.2 milvus主要特点
milvus具有如下特点:
- 高效的相似性搜索
- 多种相似性度量:支持欧氏距离(l2)、余弦相似度、内积等相似性度量。
- 高效的索引结构:支持多种索引结构,如 ivf(inverted file)、hnsw(hierarchical navigable small world)等,能够显著加速相似性搜索。
- 使用简单
- 丰富的 api 和 sdk:提供多种编程语言的 sdk,包括 python、java、c++、go 等,方便开发者集成。
- 详细的文档和社区支持:提供详细的文档和活跃的社区支持,帮助开发者快速上手。
- 多样化的数据源支持
- 多种数据源:支持多种数据源,可以与 tensorflow、pytorch 等深度学习框架集成,方便数据预处理和特征提取。
- 扩展性和可伸缩性好
- 分布式部署:支持分布式部署,能够处理大规模数据集,支持水平扩展。
- 高可用性:支持自动故障恢复和数据备份,保证系统的高可用性。
3.2 faiss
3.2.1 faiss是什么
faiss 是一个开源库,专注于大规模向量相似性搜索和聚类。它支持多种相似性度量(如欧氏距离、余弦相似度等),并使用高效的索引结构(如 ivf(inverted file)、hnsw(hierarchical navigable small world)等)来加速搜索过程。faiss 可以在 cpu 和 gpu 上运行,适用于多种应用场景。
3.2.2 faiss主要特点
faiss具有如下特点:
- 高效的相似性搜索
- 多种相似性度量:支持欧氏距离(l2)、余弦相似度、内积等相似性度量。
- 高效的索引结构:支持多种索引结构,如 ivf(inverted file)、hnsw(hierarchical navigable small world)、pq(product quantization)等,能够显著加速相似性搜索。
- 高性能
- cpu 和 gpu 支持:可以在 cpu 和 gpu 上运行,利用硬件加速提高搜索性能。
- 内存优化:对内存使用进行了优化,能够在有限的内存中处理大规模数据集。
- 灵活性好
- 多种索引方法:提供了多种索引方法,可以根据具体需求选择合适的索引结构。
- 自定义索引:支持自定义索引结构和搜索算法,满足特定应用的需求。
- 易于使用
- 丰富的 api:提供了 c++ 和 python api,方便开发者集成。
- 详细的文档和社区支持:提供详细的文档和活跃的社区支持,帮助开发者快速上手。
3.3 pinecone
3.3.1 pinecone是什么
pinecone 是一个云原生的向量数据库,专为高效地存储和检索大规模向量数据而设计。它旨在简化向量数据的存储和检索过程,提供高性能的相似性搜索功能。pinecone 提供了高性能的相似性搜索功能,支持实时和批量处理,适用于推荐系统、图像搜索、自然语言处理等多种应用场景。
官方地址:the vector database to build knowledgeable ai | pinecone
3.3.2 pinecone主要特点
pinecone具备如下特点:
- 高性能
- 高效的相似性搜索:支持多种相似性度量,如余弦相似度、欧氏距离等,使用高效的索引结构(如 hnsw、ivf 等)来加速搜索过程。
- 低延迟:优化了搜索性能,能够在毫秒级别内返回结果,适用于实时应用场景。
- 使用简单
- 简单的 api 和 sdk:提供丰富的 api 和 sdk,支持多种编程语言(如 python、javascript 等),方便开发者集成。
- 详细的文档和社区支持:提供详细的文档和活跃的社区支持,帮助开发者快速上手。
- 扩展性和可伸缩性好
- 云原生:提供托管服务,支持自动扩展和故障恢复,保证系统的高可用性。
- 水平扩展:支持水平扩展,能够处理大规模数据集,适用于企业级应用。
- 多样化的数据源支持
- 多种数据源:支持多种数据源,可以与 tensorflow、pytorch 等深度学习框架集成,方便数据预处理和特征提取。
3.4 weaviate
3.4.1 weaviate介绍
weaviate 是一个开源的向量搜索引擎,由 semitechnologies 开发并维护。它不仅支持高效的向量数据存储和检索,还结合了图数据模型,使其在处理复杂数据关系方面表现出色。weaviate 适用于推荐系统、图像搜索、自然语言处理等多种应用场景。weaviate 支持多种相似性度量(如余弦相似度、欧氏距离等),并使用高效的索引结构来加速搜索过程。weaviate 提供了丰富的 api 和 sdk,支持多种编程语言,方便开发者集成。
3.4.2 weaviate主要特点
weaviate具备如下特点
- 图数据模型
- 图数据模型:支持图数据模型,可以表示和查询复杂的数据关系。
- 灵活的数据模型:支持多种数据类型和格式,可以轻松适应各种用例。
- 高效的相似性搜索
- 多种相似性度量:支持余弦相似度、欧氏距离等相似性度量。
- 高效的索引结构:使用高效的索引结构(如 hnsw)来加速相似性搜索。
- 使用简单
- 丰富的 api 和 sdk:提供丰富的 api 和 sdk,支持多种编程语言(如 python、javascript、go 等),方便开发者集成。
- 详细的文档和社区支持:提供详细的文档和活跃的社区支持,帮助开发者快速上手。
- 扩展性和可伸缩性好
- 云原生支持:提供托管服务,支持自动扩展和故障恢复,保证系统的高可用性。
- 水平扩展:支持水平扩展,能够处理大规模数据集,适用于企业级应用。
- 查询语言
- 支持 graphql:提供强大的 graphql 查询功能,支持复杂的查询和过滤条件。
3.5 redis stack
3.5.1 redis stack介绍
redis stack 是 redis 的一个扩展版本,它不仅包含了 redis 的核心功能,还增加了多个模块,如 redisearch(全文搜索)、redisgraph(图数据库)、redistimeseries(时间序列数据库)和 redisai(ai推理)。这些模块使得 redis stack 成为一个功能更加强大的数据库系统,适用于多种应用场景。
3.5.2 redis stack核心模块
- redis stack核心模块主要包括下面几块
- redisearch
- 全文搜索:提供全文搜索功能,支持复杂的查询和过滤条件。
- 向量搜索:支持向量数据的存储和相似性搜索,适用于推荐系统、图像搜索等场景。
- 性能优化:使用倒排索引和 bm25 算法优化搜索性能。
- redisgraph
- 图数据库:提供图数据模型,支持节点和边的存储和查询。
- cypher 查询语言:支持 cypher 查询语言,方便进行复杂的图数据查询。
- 高性能:优化了图数据的存储和查询性能。
- redistimeseries
- 时间序列数据:提供时间序列数据的存储和查询功能,适用于监控、日志分析等场景。
- 压缩和聚合:支持数据压缩和聚合,节省存储空间和提高查询性能。
- redisai
- ai 推理:提供 ai 推理功能,支持 tensorflow、pytorch 等深度学习框架。
- 模型管理和执行:支持模型的加载、管理和执行,适用于实时推理和预测。
3.5.3 redis stack主要特点
- redis stack主要具备如下特点:
- 高性能
- 内存优化:redis stack 优化了内存使用,能够在有限的内存中处理大规模数据集。
- 低延迟:redis stack 提供低延迟的数据访问,适用于实时应用场景。
- 使用简单
- 丰富的 api 和 sdk:提供丰富的 api 和 sdk,支持多种编程语言(如 python、java、c++、go 等),方便开发者集成。
- 详细的文档和社区支持:提供详细的文档和活跃的社区支持,帮助开发者快速上手。
- 多样化的数据源支持
- 多种数据源:支持多种数据源,可以与 tensorflow、pytorch 等深度学习框架集成,方便数据预处理和特征提取。
- 扩展性和可伸缩性
- 分布式部署:支持分布式部署,能够处理大规模数据集,支持水平扩展。
- 高可用性:支持自动故障恢复和数据备份,保证系统的高可用性。
3.5.4 redis stack应用场景
redis stack主要有下面的应用场景
- 全文搜索
- 电子商务:支持商品搜索和推荐。
- 内容管理系统:支持文章和文档的搜索和管理。
- 图数据库
- 社交网络:支持用户关系和社交图谱的存储和查询。
- 推荐系统:支持基于图数据的推荐算法。
- 时间序列数据
- 监控系统:支持系统监控和日志分析。
- 物联网:支持 iot 设备的数据收集和分析。
- ai 推理
- 实时推荐:支持基于 ai 的实时推荐系统。
- 图像识别:支持图像识别和分类。
四、redis向量数据库介绍
4.1 redis向量数据库是什么
redis 是一个开源(bsd 许可)的内存数据结构存储,用作数据库、缓存、消息代理和流式处理引擎。redis 提供数据结构,例如字符串、哈希、列表、集合、带范围查询的有序集合、位图、超对数日志、地理空间索引和流。
redis 搜索和查询, 扩展了 redis oss 的核心功能,因此可以将 redis 用作向量数据库
- 在哈希或 json 文档中存储向量和关联的元数据
- 检索向量
- 执行向量搜索
4.2 向量检索核心原理
向量检索(vector search)的核心原理是通过将文本或数据表示为高维向量,并在查询时根据向量的相似度进行搜索。具体来说,向量检索过程涉及以下核心几点。
4.2.1 匹配原理
- 检索的核心是将文本或数据转换成向量,在高维向量空间中查找与查询最相似的向量。
- 在存储数据时将指定的字段通过嵌入模型生成了向量。
- 在检索时,查询文本被向量化,然后与 redis 中存储的向量进行相似度比较,找到相似度最高的向量(即相关的文档)。
技术关键点:
- 嵌入模型
- 将文本转换成向量。
- 相似度计算
- 通过余弦相似度或欧几里得距离来度量相似性。
- top k
- 返回相似度最高的 k 个文档。
4.2.2 具体实现过程
在代码中操作时,主要包括下面几步:
- 向量化数据:
- 当你将 json 中的字段存入 redis 时,向量化工具(例如 vectorstore)会将指定的字段转换为高维向量。每个字段的内容会通过某种嵌入模型(如 word2vec、bert、openai embeddings 等)转换成向量表示。每个向量表示的是该字段内容的语义特征。
- 搜索时向量生成:
- 当执行 searchrequest.query(message) 时,系统会将输入的 message 转换为一个查询向量。这一步是通过同样的嵌入模型,将查询文本转换为与存储在 redis 中相同维度的向量。
- 相似度匹配:
- vectorstore.similaritysearch(request) 函数使用了一个向量相似度计算方法来查找最相似的向量。这通常是通过 余弦相似度 或 欧几里得距离 来度量查询向量和存储向量之间的距离。然后返回与查询最相似的前 k 个文档,即 withtopk(topk) 所指定的 k 个最相关的结果。
- 返回匹配的文档:
- 匹配的结果是根据相似度得分排序的 list<document>。这些文档是你最初存储在 redis 中的记录,包含了 json 中指定的字段。
五、整合springboot 实现向量数据库相似性搜索
接下来使用redis stack作为向量数据库,并整合springboot 实现向量数据库相似性搜索的过程。
5.1 前置准备
5.1.1 docker搭建redis-stack
使用下面的docker命令搭建redis-stack
docker run -d --name redis-stack -v /redis-data:/data -p 6379:6379 -p 8001:8001 redis/redis-stack:latest
也可以使用下面的docker compose命令启动容器
version: '3'
services:
redis-stack:
image: redis/redis-stack
ports:
- 6379:6379
redis-insight:
image: redislabs/redisinsight:latest
ports:
- 5540:5540
可以通过 ip:8001 访问 redis-stack 的web控制台,这里在后面将会用于存储程序中的文本嵌入数据

5.1.2 导入maven依赖
在你的maven工程中导入如下依赖
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceencoding>utf-8</project.build.sourceencoding>
</properties>
<parent>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-parent</artifactid>
<version>3.2.4</version>
<relativepath/>
</parent>
<dependencies>
<dependency>
<groupid>com.alibaba.cloud.ai</groupid>
<artifactid>spring-ai-alibaba-starter</artifactid>
<version>1.0.0-m2.1</version>
</dependency>
<dependency>
<groupid>com.alibaba</groupid>
<artifactid>fastjson</artifactid>
<version>2.0.35</version>
</dependency>
<dependency>
<groupid>com.squareup.okhttp3</groupid>
<artifactid>okhttp</artifactid>
<version>4.12.0</version>
</dependency>
<dependency>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-web</artifactid>
</dependency>
<dependency>
<groupid>org.projectlombok</groupid>
<artifactid>lombok</artifactid>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba/dashscope-sdk-java -->
<dependency>
<groupid>com.alibaba</groupid>
<artifactid>dashscope-sdk-java</artifactid>
<version>2.16.9</version>
</dependency>
<dependency>
<groupid>org.apache.httpcomponents</groupid>
<artifactid>httpclient</artifactid>
<version>4.5.13</version>
</dependency>
<!-- https://mvnrepository.com/artifact/io.milvus/milvus-sdk-java -->
<dependency>
<groupid>io.milvus</groupid>
<artifactid>milvus-sdk-java</artifactid>
<version>2.4.6</version>
</dependency>
</dependencies>
<repositories>
<repository>
<id>spring-milestones</id>
<name>spring milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>5.1.3 获取apikey
下文中将会先演示使用云厂商提供的向量数据库,所以这里使用百炼平台的,需要先获取apikey
获取apikey,可以去阿里云的百炼平台获取,然后在模型广场中向量模型那里选择一种文本向量使用
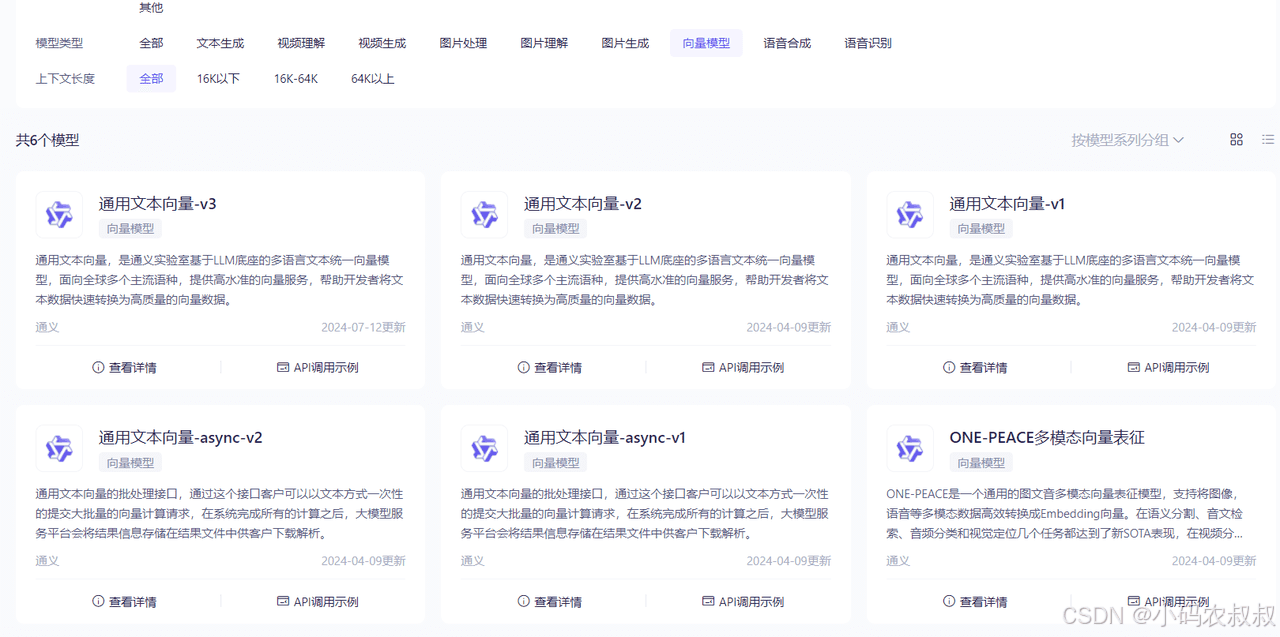
5.1.4 添加配置文件
在工程的配置文件中增加下面的配置内容
server:
port: 8081
spring:
ai:
dashscope:
api-key: 你的apikey
embedding:
options:
model: text-embedding-v25.2 文本嵌入代码实现过程
如何用一段话去数据库查找数据?答案是向量求相似度。相似度越高,返回的数据就越靠前,比如大家熟知的搜索引擎es,你输入一段文本去查询,es会根据算分将得分最高的文档放在前面返回给你,在大模型中,嵌入模型就可以帮我们做到这件事,所以第一件事情需要将文本中的句子向量化,然后和向量数据库中的向量进行比较,找到最相似的向量。下面使用代码演示下这个过程。
5.2.1 添加一个测试接口
添加一个测试接口,参考下面的代码
package com.congge.web;
import jakarta.annotation.resource;
import lombok.extern.slf4j.slf4j;
import org.springframework.ai.embedding.embeddingmodel;
import org.springframework.ai.embedding.embeddingresponse;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.web.bind.annotation.getmapping;
import org.springframework.web.bind.annotation.requestparam;
import org.springframework.web.bind.annotation.restcontroller;
import java.util.list;
import java.util.map;
@restcontroller
@slf4j
public class documentcontroller {
private final embeddingmodel embeddingmodel;
@autowired
public documentcontroller(embeddingmodel embeddingmodel) {
this.embeddingmodel = embeddingmodel;
}
@getmapping("/ai/embedding")
public map embed(@requestparam(value = "message", defaultvalue = "tell me a joke") string message) {
embeddingresponse embeddingresponse = this.embeddingmodel.embedforresponse(list.of(message));
return map.of("embedding", embeddingresponse);
}
//localhost:8081/embedding
@getmapping("/embedding")
public object embeddingtest() {
// 文本嵌入
float[] embed = embeddingmodel.embed("你好,我是小码农叔叔");
log.info("文本转换得到的向量: {}", embed);
return embed;
}
}两个接口均可用于测试,选择第二个测试,请求之后,返回了很多向量的参数
5.3 etl pipeline
etl是提取、转换、加载的缩写,从原始的文档到数据库需要经历提取(.doc、.ppt、.xlsx等)、转换(数据结构化、清理数据、数据分块)、写入向量数据库。这个过程可以进行多种处理,确保最后的数据适合ai问答。
springai提供了etl框架。它是搭建知识库框架的基石。
5.3.1 spring ai etl 介绍
在ai应用程序中,数据处理是至关重要的一部分。spring ai提供了一个强大的etl框架,帮助开发者高效地进行数据提取、转换和加载操作。通过这个框架,你可以轻松地将数据准备好用于ai模型的训练和推理。
5.3.2 spring ai 处理etl完整过程
与传统的etl过程稍有不同,springai 中etl 的完整过程如下:
- 数据提取
- 数据提取是etl流程的第一步。在这个阶段,你需要从各种数据源中提取原始数据。spring ai支持多种数据源,包括数据库、文件系统、api等。
- 数据转换
- 数据转换是etl流程的第二步。在这个阶段,你需要将原始数据转换为适合ai模型使用的格式。spring ai提供了多种数据转换工具,帮助你高效地处理数据。
- 向量化数据
- 对于ai模型来说,向量化数据是必不可少的步骤。只有经过向量化之后的数据才能在后续的检索中正常检索出结果。
- 数据加载
- 数据加载是etl流程的最后一步。在这个阶段,你需要将转换后的数据加载到目标存储系统中,以便ai模型使用。spring ai支持将数据加载到多种目标存储系统中。
5.3.3 spring ai etl 技术框架
5.3.3.1 读取器 documentreader
documentreader ,文档读取器:
- 用于读取文档,比如pdf、word、excel等
- 如:jsonreader(读取json),textreader(读取文本),pagepdfdocumentreader(读取pdf),tikadocumentreader(读取各种文件,大部分都可以支持.pdf,.xlsx,.docx,.pptx,.md,.json等)。
- 这些reader都是documentreader的实现类。
5.3.3.2 文档转换器 documenttransformer
文档转换器,处理文档:
- textsplitter(文档切割成小块),contentformattransformer(将文档变成键值对),summarymetadataenricher(使用大模型总结文档),keywordmetadataenricher(使用大模型提取文档关键词)
5.3.3.3 文档写入器 documentwriter
文档写入器:
- 将文档写入向量数据库或者本地文件。
- vectorstore(向量数据库写入器),filedocumentwriter(文件写入器)。
使用这几个组件,完整的执行流程如下:

5.4 spring ai 文档读取操作演示
5.4.1 文件读取代码演示
tikadocumentreader 比较全能,大部分文件都可读取,支持的文件格式可以参考官方文档。如果是比较个性化文档的场景,最好自己实现一个reader,便于业务扩展。pom文件中导入下面的依赖。
<dependency>
<groupid>org.springframework.ai</groupid>
<artifactid>spring-ai-tika-document-reader</artifactid>
</dependency>从输入流读取文件,参考下面的接口代码
@sneakythrows
@postmapping("read/multipart-file")
public void readmultipartfile(@requestparam multipartfile file) {
// 从io流中读取文件
resource resource = new inputstreamresource(file.getinputstream());
list<document> documents = new tikadocumentreader(resource)
.read();
}上传一个本地的文档,接口测试效果,可以看到被分割成很多片段了

从本地文件读取,参考下面的接口代码
/**
* 从本地文件读取
* @return
*/
@getmapping("/read/from-local-file")
public object readlocalfile() {
filesystemresource resource = new filesystemresource("e:\\工作空间\\wzlocal\\java编码规范v1.0.pdf");
list<document> documents = new tikadocumentreader(resource)
.read();
return documents;
}调用一下接口,使用相同的文件,得到类似的效果

5.5 spring ai 文档转换操作演示
在上一步的操作中,读取返回的是document对象,而是documentetl pipeline的核心对象,它包含了文档的元数据和内容。接下来就需要对文档进行转换。此时就要用到内容转换器。包括内容转换器和元数据转换器。
内容转换器
- tokentextsplitter:可以把内容切割成更小的块方便rag的时候提升响应速度节省token。
- contentformattransformer:可以把元数据的内容变成键值对字符串。
元数据转换器
- summarymetadataenricher:使用大模型总结文档。会在元数据里面增加一个summary字段。
- keywordmetadataenricher:使用大模型提取文档关键词。可以在元数据里面增加一个keywords字段。
5.5.1 添加测试接口
参考下面的代码
/**
* 分割后的文档列表 localhost:8081/doc/split
* @param file
* @return
* @throws exception
*/
@postmapping("/doc/split")
public object docsplit(@requestparam multipartfile file) throws exception{
inputstreamresource inputstreamresource = new inputstreamresource(file.getinputstream());
list<document> documentlist = new tikadocumentreader(inputstreamresource).read();
// 分割后的文档列表
list<document> splitdoclist = new tokentextsplitter().split(documentlist);
list<string> contentlist = splitdoclist.stream().map(document::getcontent).collect(collectors.tolist());
return contentlist;
}测试一下接口,可以看到被转换后的文档分割成多个片段

5.6 文档存储
经过前面的步骤,我们得到了一个文档列表,为了方便后续的文档搜索,需要将文档进行存储,文档存储到哪里去呢?即向量数据库。上面准备阶段搭建的redis-stack即是用于做向量数据库使用的。下面看代码中的操作过程。
5.6.1 导入依赖文件
导入下面的依赖坐标
<dependency>
<groupid>org.springframework.ai</groupid>
<artifactid>spring-ai-tika-document-reader</artifactid>
<version>1.0.0-m3</version>
</dependency>
<dependency>
<groupid>org.springframework.ai</groupid>
<artifactid>spring-ai-redis-store</artifactid>
<version>1.0.0-m3</version>
</dependency>
<dependency>
<groupid>redis.clients</groupid>
<artifactid>jedis</artifactid>
</dependency>5.6.2 配置redis信息
在配置文件中添加redis的信息
spring:
ai:
dashscope:
api-key: 你的apikey
embedding:
options:
model: text-embedding-v2
vectorstore:
redis:
uri: redis://ip:6379
data:
redis:
database: 0
timeout: 10s
lettuce:
pool:
# 连接池最大连接数
max-active: 200
# 连接池最大阻塞等待时间(使用负值表示没有限制)
max-wait: -1ms
# 连接池中的最大空闲连接
max-idle: 10
# 连接池中的最小空闲连接
min-idle: 0
repositories:
enabled: false
host: redis地址5.6.3 增加一个redis的向量数据库配置类
如果在你的项目里面有用到redis,需要先禁用redisvectorstoreautoconfiguration。这是springai自动配置redisstack的向量数据库连接,会导致redis的连接配置冲突。参考下面的代码。
package com.congge.config;
import lombok.allargsconstructor;
import org.springframework.ai.autoconfigure.vectorstore.redis.redisvectorstoreautoconfiguration;
import org.springframework.ai.autoconfigure.vectorstore.redis.redisvectorstoreproperties;
import org.springframework.ai.embedding.embeddingmodel;
import org.springframework.ai.vectorstore.redisvectorstore;
import org.springframework.ai.vectorstore.vectorstore;
import org.springframework.boot.autoconfigure.enableautoconfiguration;
import org.springframework.boot.autoconfigure.data.redis.redisconnectiondetails;
import org.springframework.boot.context.properties.enableconfigurationproperties;
import org.springframework.context.annotation.bean;
import org.springframework.context.annotation.configuration;
import redis.clients.jedis.jedispooled;
@configuration
// 禁用springai提供的redisstack向量数据库的自动配置,会和redis的配置冲突。
@enableautoconfiguration(exclude = {redisvectorstoreautoconfiguration.class})
// 读取redisstack的配置信息
@enableconfigurationproperties({redisvectorstoreproperties.class})
@allargsconstructor
public class redisvectorconfig {
/**
* 创建redisstack向量数据库
*
* @param embeddingmodel 嵌入模型
* @param properties redis-stack的配置信息
* @return vectorstore 向量数据库
*/
@bean
public vectorstore vectorstore(embeddingmodel embeddingmodel,
redisvectorstoreproperties properties,
redisconnectiondetails redisconnectiondetails) {
redisvectorstore.redisvectorstoreconfig config = redisvectorstore.redisvectorstoreconfig.builder().withindexname(properties.getindex()).withprefix(properties.getprefix()).build();
return new redisvectorstore(config, embeddingmodel,
new jedispooled(redisconnectiondetails.getstandalone().gethost(),
redisconnectiondetails.getstandalone().getport()
, redisconnectiondetails.getusername(),
redisconnectiondetails.getpassword()),
properties.isinitializeschema());
}
}5.6.4 增加嵌入文档接口
在上面的vectorstore配置中我们提供了embeddingmodel,调用vectorstore.add(splitdocuments)底层会把文档给embeddingmodel把文本变成向量然后再存入向量数据库。参考下面的代码。
/**
* 文档保存到向量数据库 localhost:8081/doc/embedding
* @param file
* @return
* @throws exception
*/
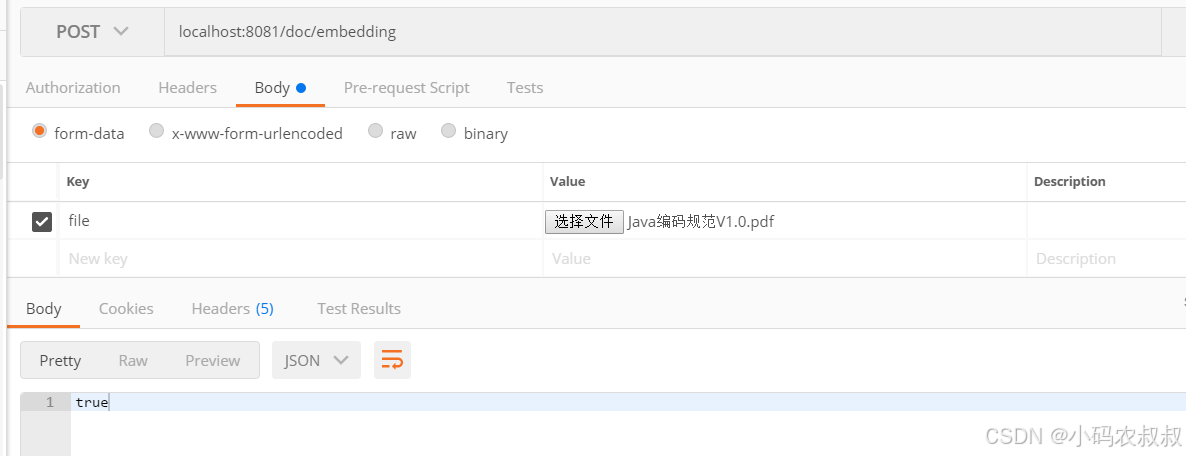
@postmapping("/doc/embedding")
public object docembedding(@requestparam multipartfile file) throws exception{
tikadocumentreader tikadocumentreader = new tikadocumentreader(new inputstreamresource(file.getinputstream()));
list<document> splitdocuments = new tokentextsplitter().apply(tikadocumentreader.read());
// 存入向量数据库,这个过程会自动调用embeddingmodel,将文本变成向量存入
vectorstore.add(splitdocuments);
return true;
}调用一下接口
接口执行成功后,在redis-stack的控制台界面可以看到数据存入了redis中

5.6.5 增加文档检索接口
数据存入进去之后接下来就可以进行搜索了,添加下面文档检索的接口
/**
* 关键字检索文档 localhost:8081/doc/query?keyword=面向对象
* @param keyword
* @return
*/
@getmapping("/doc/query")
public list<document> query(@requestparam string keyword) {
list<document> documentlist = vectorstore.similaritysearch(keyword);
return documentlist;
}六、写在文末
本文通过较大的篇幅详细介绍了常用的向量数据库解决方案,并通过搭建redis stack环境,结合代码演示了如何基于redis stack作为向量数据库进行使用,希望对看到的同学有用,本篇到此介绍,感谢观看。
到此这篇关于springboot 整合redis stack 构建本地向量数据库相似性查询的文章就介绍到这了,更多相关springboot 整合redis stack 内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论