目录
第一章 知识图谱的概述
1.1 什么是知识图谱
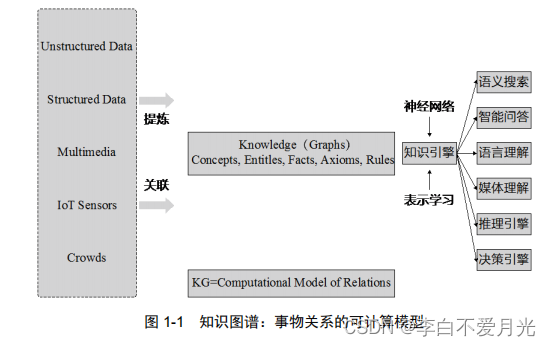
1)知识图谱是一种用图模型来描述知识和建模世界万物之间的关联关系的技术方法。
2)知识图谱由节点和边组成。
- 节点可以是实体,如一个人、一本书等,或是抽象的概念,如人工智能等。
- 边可以是实体的属性,如姓名、书名,或是实体之间的关系,如朋友、配偶。
3)知识图谱旨在从数据中识别、发现和推断事物与概念之间的复杂关系,是事物关系的可计算模型。
1.2 知识图谱的发展史
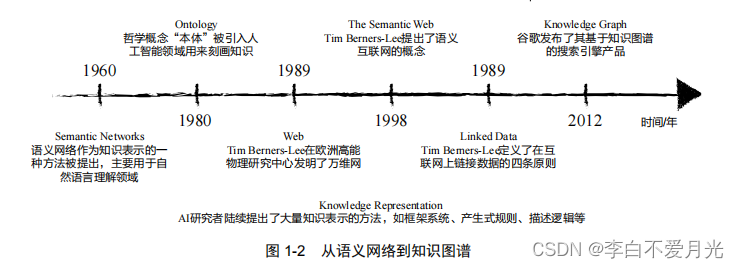
1)知识图谱并非突然出现的新技术,而是历史上很多相关技术相互影响和继承发展的结果。
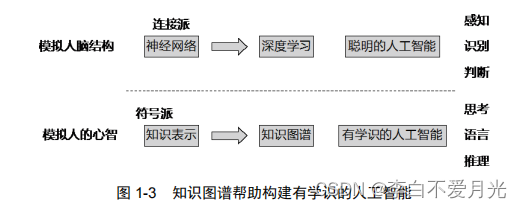
2) 知识图谱发展流派
- 符号派(symbolism)侧重于模拟人的心智,研究怎样用计算机符号表示人脑中的知识并模拟心智的推理过程;
- 连接派(connectionism)侧重于模拟人脑的生理结构,即人工神经网络。
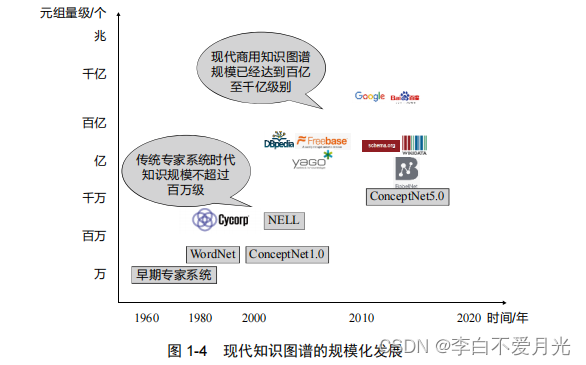
3)知识图谱规模发展
1.3 知识图谱的价值
1)辅助搜索
- 传统搜索引擎依靠网页之间的超链接实现网页的搜索
- 语义搜索是直接对事物进行搜索,如人物、机构、地点等。
- 知识图谱和语义技术提供了关于这些事物的分类、属性和关系的描述,使得搜索引擎可以直接对事物进行索引和搜索
2)辅助问答
- 人与机器通过自然语言进行问答与对话是人工智能实现的关键标志之一。
- 典型的基于知识图谱的问答技术或方法包括:基于语义解析、基于图匹配、基于模板学习、基于表示学习和深度学习以及基于混合模型等。
3)辅助大数据处理
- 知识图谱被广泛用来作为先验知识从文本中抽取实体和关系,如在远程监督中的应用。
- 知识图谱也被用来辅助实现文本中的实体消歧(entity disambiguation)、指代消解和文本理解等
4)辅助语言理解
- 背景知识,特别是常识知识,被认为是实现深度语义理解(如阅读理解、人机问答等)必不可少的构件。
5)辅助设备关联
- 一个设备产生的原始数据在封装了语义描述之后,可以更加容易地与其他设备的数据进行融合、交换和互操作,并可以进一步链接进入知识图谱中,以便支持搜索、推理和分析等任务。
1.4 国内外典型的知识图谱项目
1.4.1 早期的知识库项目
- cyc 知识库主要由术语(term)和断言(assertion)组成。术语包含概念、关系和实体的定义。断言用来建立术语之间的关系,既包括事实(fact)描述,也包含规则(rule)描述。
- wordnet 是最著名的词典知识库,wordnet 主要定义了名词、动词、形容词和副词之间的语义关系。
- conceptnet 最早源于 mit 媒体实验室的 omcs(open mind common sense)项目。
1.4.2 互联网时代的知识图谱
1)涌现出了大量以互联网资源为基础的新一代知识库。这类知识库的构建方法可以分为三类:互联网众包、专家协作和互联网挖掘。
1.4.3 中文开放知识图谱
1)openkg 是一个面向中文域开放知识图谱的社区项目,主要目的是促进中文领域知识图谱数据的开放与互联。
2)知识图谱 schema 定义了知识图谱的基本类、术语、属性和关系等本体层概念。
3)openbase.ai 是 openkg 实现的类似于 wikidata 的开放知识图谱众包平台。
1.4.4 垂直领域知识图谱
1)领域知识图谱是相对于 dbpedia、yago、wikidata、百度和谷歌等搜索引擎在使用的知识图谱等通用知识图谱而言的,它是面向特定领域的知识图谱,如电商、金融、医疗等。
2)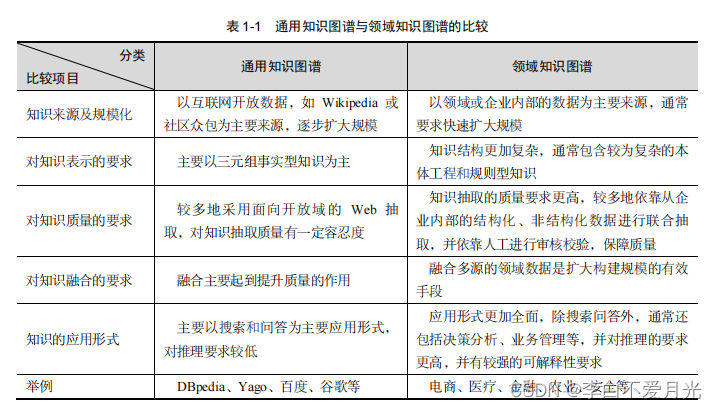 3) 领域知识图谱的主要特点及技术难点:领域知识图谱具有规模巨大、知识结构更加复杂、来源更加多样、知识更加异构、具有高度的动态性和时效性、更深层次的推理需求等特点。
3) 领域知识图谱的主要特点及技术难点:领域知识图谱具有规模巨大、知识结构更加复杂、来源更加多样、知识更加异构、具有高度的动态性和时效性、更深层次的推理需求等特点。
1.5 知识图谱的技术流程
1)知识来源:可以从多种来源获取知识图谱数据,包括文本、结构化数据库、多媒体数据、传感器数据和人工众包等。
2)知识表示与 schema 工程:
- 知识表示是指用计算机符号描述和表示人脑中的知识,以支持机器模拟人的心智进行推理的方法与技术。
- schema 与本体定义知识图谱的类集、属性集、关系集和词汇集。
3)知识抽取
- 知识抽取按任务可以分为概念抽取、实体识别、关系抽取、事件抽取和规则抽取等。
- 在构建知识图谱时,可以从第三方知识库产品或已有结构化数据中获取知识输入。
- 数据层的融合是指实体和关系(包括属性)元组的融合,主要是实体匹配或者对齐
- 基于本体推理的补全方法;
- 基于图结构和关系路径特征的方法;
- 基于表示学习和知识图谱嵌入的链接预测;
- 文本信息也被用来辅助实现知识图谱的补全
6)知识检索与知识分析
- 基于知识图谱的知识检索的实现形式主要包括语义检索和智能问答。
- 知识图谱和语义技术也被用来辅助做数据分析与决策。
1.6 知识图谱的相关技术
1.6.1 知识图谱与数据库系统
1)由于传统关系数据库无法有效适应知识图谱的图数据模型,知识图谱领域形成了 rdf 数据的三元组库(triplestore),数据库领域开发了管理属性图的图数据库(graph database)。
- 知识图谱的主要数据模型有 rdf 图(rdf graph)和属性图(property graph)两种; 知识图谱查询语言可分为声明式(declarative)和导航式(navigational)两类。
- rdf 三元组库主要是由 semantic web 领域推动开发的数据库管理系统,其数据模型rdf 图和查询语言 sparql 均遵守 w3c 标准。
- 图数据库是数据库领域为更好地存储和管理图模型数据而开发的数据库管理系统,其数据模型采用属性图
2)目前,基于三元组库和图数据库能够提供的知识图谱数据存储方案可分为三类
- 基于关系的存储方案。包括三元组表、水平表、属性表、垂直划分、六重索引和db2rdf 等。
- 面向 rdf 的三元组库。主要的 rdf 三元组库包括:商业系统 virtuoso、 allegrograph、graphdb 和 blazegraph,开源系统 jena、rdf-3x 和 gstore
- 原生图数据库。neo4j 是用 java 实现的开源图数据库。
1.6.2 知识图谱与智能问答
- 基于知识图谱的问答(knowledge-based question answering,kbqa,下称“知识问答”)是智能问答系统的核心功能,是一种人机交互的自然方式。
- 攻克知识问答的关键在于理解并解析用户提出的自然语言问句。研究方法主要可分为三大类:基于语义解析(semanticparsing) 的方法、基于信息检(information retrieval)的方法和基于概率模型(probabilistic models)的方法。
1.6.3 知识图谱与机器推理
- 1.基于规则的推理
- 2.基于分布式表示学习的推理
- 3.基于神经网络的推理
- 4.混合推理
1.6.4 知识图谱与推荐系统
- 基于知识图谱中元路径的推荐模型
- 基于概率逻辑程序的推荐模型
- 基于知识图谱表示学习技术的推荐模型
1.6.5 区块链与去中心的知识图谱
1.7 本章小结
- 从数据维度上看,知识图谱要求用更加规范的语义提升企业数据的质量,用链接数据的思想提升企业数据之间的关联度
- 从技术维度上看,知识图谱的构建涉及知识表示、关系抽取、图数据存储、数据融合、推理补全等多方面的技术


发表评论