注:本文是小编学习实战心得分享,欢迎交流讨论!话不多说,直接附上代码和图示说明。
目录
4.对列名进行分类,便于后面的操作,其中最后一列为预测标签数据
一、分段示例
1.导入必要的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import sklearn2.读取数据,查看数据基本信息
可以看到,该数据文件大小为731*7,具体信息如图所示,并发现没有缺失值
df=pd.read_csv('c:/users/27812/desktop/2-day.csv')
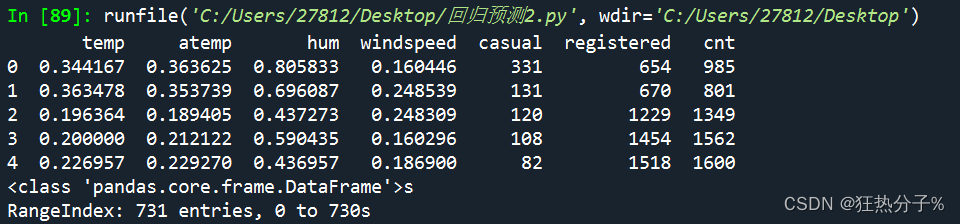
print(df.head(5))
print(df.info())#查看后发现没有缺失值
print(df.nunique())#除了前两列,其余每列都有重复值
print(df.describe())#查看数据的描述性信息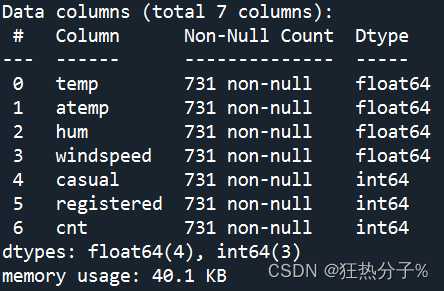
3.简单查看有无重复值
print(df[all_colums].nunique())
#提取重复值
print(df[df.duplicated()])#结果发现无重复值4.对列名进行分类,便于后面的操作,其中最后一列为预测标签数据
x_colums=['temp','atemp','hum','windspeed','casual','registered']
y_colums=['cnt']
all_colums=['temp','atemp','hum','windspeed','casual','registered','cnt']5.对数据进行初步可视化
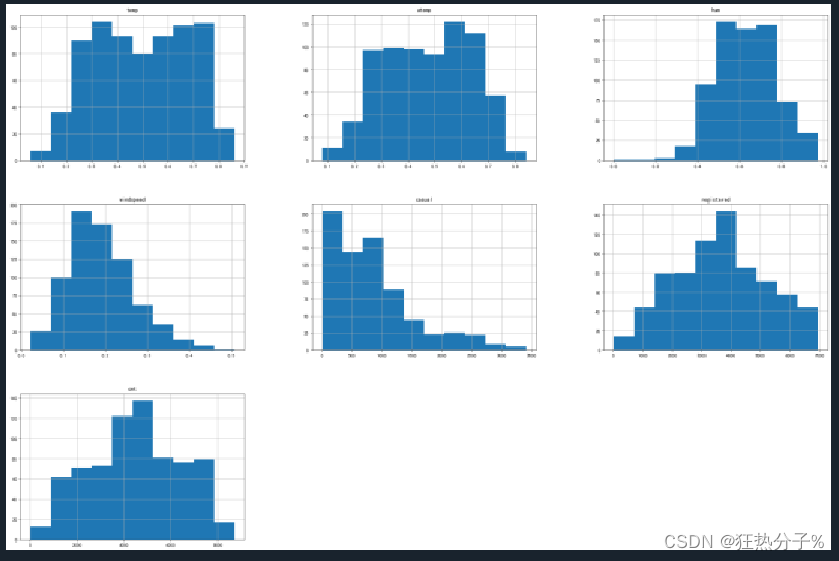
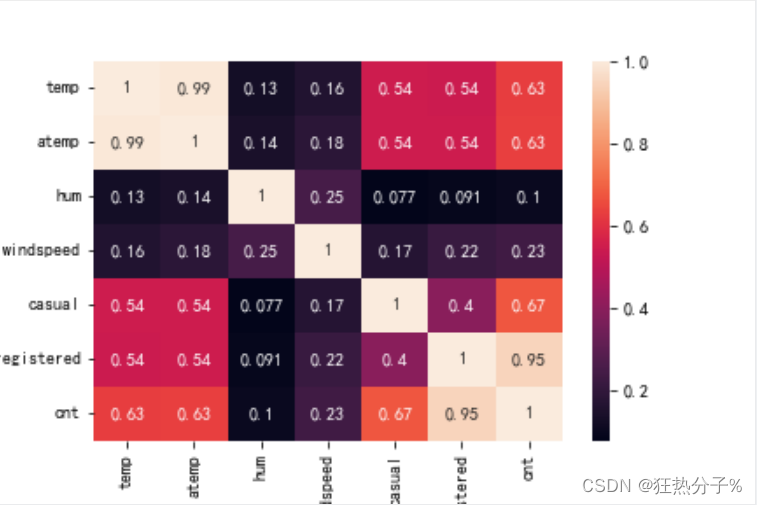
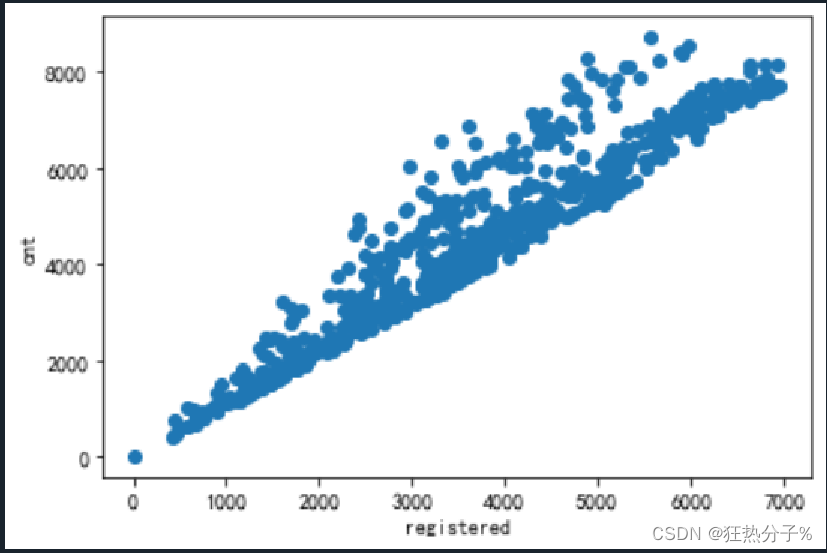
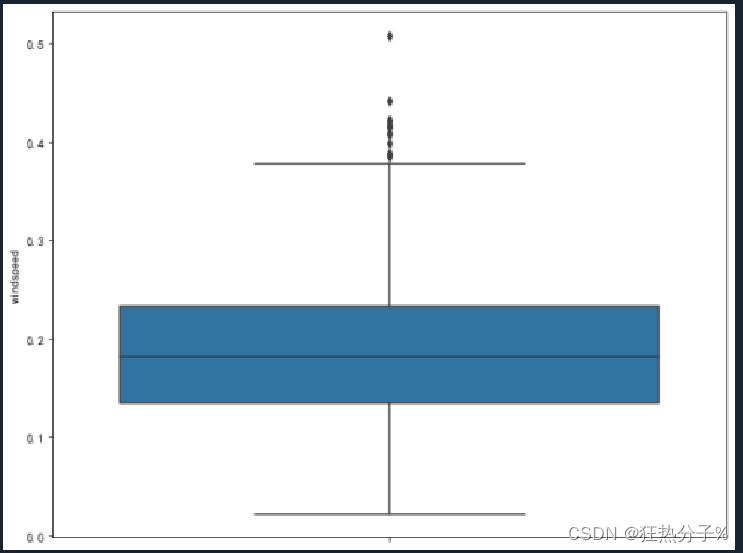
分别绘制直方图、散点图以及特征之间的相关表示图,对数据的分布以及特征之间的关系有了初步的了解或判断;同时检测异常值,并通过箱线图可视化。(展示部分图片)
#数据初步可视化
#绘制直方图
def hist(df):
df.hist(figsize=(30,20))
plt.show()
plt.savefig('a.png')
hist(df[all_colums])
#绘制散点图
def scatter(df):
for i in all_colums[:6]:
plt.scatter(df[i],df['cnt'])
plt.xlabel(i)
plt.ylabel('cnt')
plt.show()
scatter(df)
#相关系数查看特征与特征,特征与响应的线性关系
def corr_view():
data_corr=df.corr()
data_corr=data_corr.abs()
sns.heatmap(data_corr,annot=true)
plt.savefig('b.png')
corr_view()
#异常值可视化
plt.rcparams['font.sans-serif'] = ['simhei'] # 用来正常显示中文标签
plt.rcparams['axes.unicode_minus'] = false # 用来正常显示负号
for i in all_colums:
f,ax=plt.subplots(figsize=(10,8))
sns.boxplot(y=i,data=df,ax=ax)
plt.show()
plt.savefig('c.png', dpi=500)
#经发现,'hum','windspeed','casual'这三列中有异常值 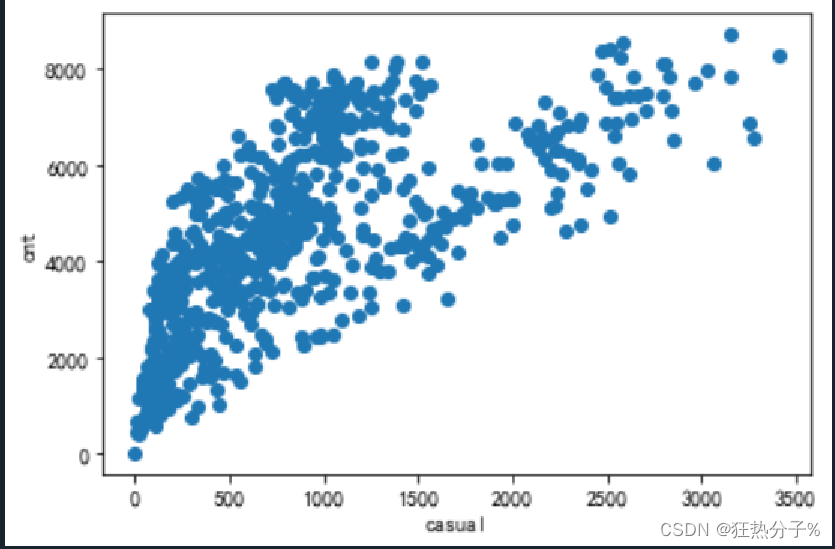

发表评论