目录
大模型的热度使得向量数据库和embedding也成了ai领域的热门话题,有别于从头开始训练一个大模型或基于基础模型进行微调的方式,embedding检索相关上下文是对大模型进行定制的各种方法中成本最低、技术实现最便捷的方式。
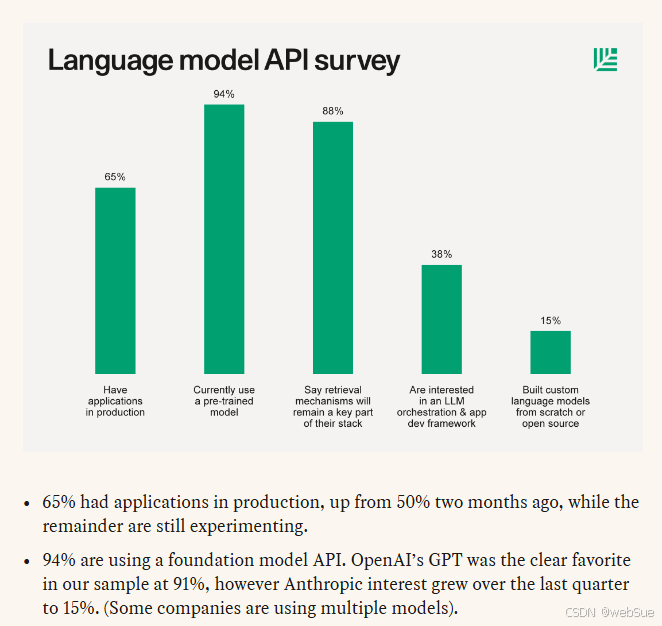
从技术实现的角度,embedding检索相关上下文是预先将要检索的文本内容使用embedding转换成向量数组,然后保存在向量数据库,检索的时候,将检索的内容也使用embedding转换成向量数组,然后去向量数据库做相似度检索,找出最相关的前若干条内容,再和问题一起提供给大语言模型,以保证大语言模型能获取到正确的信息。
向量搜索领域,现在有很多专业的向量数据库可供选择,但在预研阶段,elasticsearch8.x提供的向量搜索功能已足够我们进行试验探索。接下来将对 如何基于es 8.x进行向量搜索进行介绍。
前置知识
elasticsearch早在7.2.0版本就引入了dense_vector字段类型,支持存储高维向量数据,如词嵌入或文档嵌入,可以利用向量函数使用script_score查询来执行精确knn。
从8.0版本开始,新增了knn向量近邻检索可以使用近似knn搜索,此外通过python eland库,支持用户自定义上传机器学习模型至es,使用pipeline自动生成指定字段向量(白金版功能,免费版不可用)。
dense_vector:用于存储浮点类型的密集向量,其最大维度为2048。该字段不支持聚合和排序
knn搜索:一种分类和回归方法,是监督学习方法里的一种常用方法。k近邻算法假设给定一个训练数据集,其中的实例类别已定。分类时,对新的实例,根据其k个最近邻的训练实例类别,通过多数表决等方式进行预测。k近邻法三要素:距离度量、k值的选择和分类决策规则。其中,k值和距离度量在es参数中可设置调整。
操作
生成向量
根据需要,可以借助bert模型、glove 、word2vec或者chatgpt embedding api等将文本转为向量,网络上很多相关文章,这里就不赘述了
建立索引
put test-index
{
"mappings": {
"properties": {
"title-vector": {
"type": "dense_vector",
"dims": 3,
"index": true,
"similarity": "l2_norm"
},
"title": {
"type": "text"
},
"file-type": {
"type": "keyword"
}
}
}
}注意:1.使用近似knn,dense_vector字段必须开启索引,即 index要设置为true;
2.similarity用来定义文档间的相似度算法,l2_norm为欧式距离,其他可选项可参见官方文档;
3.dims是向量维度大小,当index为true时,不能超过1024,当index为false,不能超过2048。且该值必须与后续写入的向量维度一致!!需根据事先确定生成好的向量维度来定义dims
查询
post test-index/_search
{
"knn": {
"field": "title-vector",
"query_vector": [-5, 9, -12],
"k": 10,
"num_candidates": 100
},
"fields": [ "title", "file-type" ]
}文档的分数由查询和文档的向量决定,具体怎么计算,参考similarity参数。
knn api 会先去每个分片找num_candidates个最近邻候选者,然后每个分片计算最优的k个。最后把每个分片的结果合并,在计算出k个全局最优。
每个分片要考虑的最近邻候选者的数量,不能超过 10000。num_candidates往往可以提高最后k个结果的精确度,但是更好的结果会带来更多的消耗。k值必须比num_candidates要小
过滤后knn搜索
post test-index/_search
{
"knn": {
"field": "title-vector",
"query_vector": [54, 10, -2],
"k": 5,
"num_candidates": 50,
"filter": {
"term": {
"file-type": "article"
}
}
},
"fields": ["title"],
"_source": false
}knn搜索和query混合使用
post test-index/_search
{
"query": {
"match": {
"title": {
"query": "mountain lake",
"boost": 0.9
}
}
},
"knn": {
"field": "title-vector",
"query_vector": [54, 10, -2],
"k": 5,
"num_candidates": 50,
"boost": 0.1
},
"size": 10
}注意!!!
knn搜索和dsl语法混合使用,采用的是多路归并的思路,即分别检索标签和向量再进行结果合并。虽可以解决部分问题,但多数情况下结果不甚理想。主要原因在于,向量检索无范围性,其目标是尽可能保证 topk 的准确性,topk 很大时,准确性容易下降,造成归并结果的不准确甚至为空的情况。

以列出的混合查询语句为例,这个查询是先得到全局5个最相邻结果,然后将他们与匹配查询匹配的结果组合,选出得分最高的前10个返回。分数的计算采取:
score = 0.9 * match_score + 0.1 * knn_score
近似knn还可以搭配聚合,它聚合的是top k个邻近文档的结果。如果还有query,那么聚合的是混合查询的结果。
其他注意点
knn搜索api的变动
在8.4版本前,es短暂提供过knn搜索api
post test-index/_knn_search但在8.4版本后,统一将knn搜索调整为搜索api _search的参数
post test-index/_search
{
"knn": {
"field": "test-vector",
"query_vector": [-5, 9, -12],
"k": 10,
"num_candidates": 100
},
"fields": [ "title", "file-type" ]
}所以如果在网络文章上看到该api但在搜索集群上无法使用请不要惊讶,搜索集群是8.7.0的,之前的_knn_search用法已经被取消了
script_score精确查询
在上述的操作过程中,我都默认使用了近似knn搜索而没有提及基于script_score的精确knn,这是因为精确knn本质上是使用脚本来重新定义score的计算方式,在分数中引入向量匹配的部分,script_score查询将扫描每个匹配的文档来计算向量函数。也自然会有使用脚本的最普遍问题:极易导致慢查询,搜索性能变差。
有效的改善方式是使用query来限制传递给向量函数的匹配文档集。但在实际业务应用中很难把性能提高到满意的程度,因此在大多数情况下不建议使用精确knn。
post test-index/_search
{
"query": {
"script_score": {
"query" : {
"bool" : {
"filter" : {
"term": {
"file-type": "article"
}
}
}
},
"script": {
"source": "cosinesimilarity(params.queryvector, 'title-vector') + 1.0",
"params": {
"queryvector": [90.0, -10, 14.8]
}
}
}
}
}应用瓶颈
将embedding和 llm 结合来解决上下文长度限制、私有数据安全等问题的应用有很多,例如chatpdf应用、langchain开源框架、bloop.ai产品、supabase技术文档等,大模型出现后很多ai产品都采用这套原理。
但正如网络上很多声量所讨论的那样,embedding或者说向量数据库的引入更多是一种工程层面的辅助,是迫于当前大模型的瓶颈(比如输入token长度的限制)而进行的“打补丁”操作。
embedding这一技术本身并不是新鲜事物,所以在使用时,会面临embedding固有的一些问题,最根本的就是 搜不准。embedding检索是基于语义的检索,与传统搜索基于关键词的检索相当不同。
举一个例子是:
假设数据库里有一段文字 “老鼠在寻找食物”。用户输入了"'奶酪’”的查询。文本搜索根本无法识别这段话,它不包含任何重叠部分。
但是通过embedding,这两段文字都变成了向量,然后可以对这段文字进行相似性搜索。因为“老鼠”和“奶酪”在某种程度上是相关的,所以尽管缺乏匹配的词,用户还是能够得到该段落的结果。
它的局限性在于,如果你在一段不相干的文字中突然记了一句“老鼠在寻找食物”,用向量很可能输入“老鼠”也搜不出来,而关键词又能找出来。
在embedding的具体使用中,文本转向量模型选择的不同和相似度搜索时nn选择的不同都会与向量搜索出的结果产生很大影响,表现在搜索结果上,就是在人看来风马牛不相及的内容会出现在结果集里。或许,将embedding搜索与传统搜索互补结合,能在一定程度上弥补这一问题,这也需要进一步探索了。
最后,尽管本文是介绍在es中使用向量搜索,但当前开源生态中最热门的向量数据存储工具应该是postgresql的拓展模块pg-vector,如果你想了解更多关于向量数据库的内容,推荐阅读:[向量数据库 ] 向量数据库
参考文章
[search api | elasticsearch guide [8.7] | elastic] search api | elasticsearch guide [8.7] | elastic
[es-knn搜索-csdn博客] es-knn搜索_es knn-csdn博客

发表评论