数组索引哈希表(array indexed hash table)
哈希表:散列表,通过建立key与value之间的映射关系,实现高效的元素查询。


哈希表,数组,链表的查询效率
- 数组:
- 查询效率:对于已知索引的位置,数组提供的是常数时间复杂度 o(1) 的查询速度,这是最快的。数组通过下标直接访问,无需遍历。
- 注意:如果进行的是顺序查找(比如查找特定值而不是索引),则数组的查询效率降为线性时间复杂度 o(n),需要遍历整个数组。
- 链表:
- 查询效率:链表的查询效率通常较低,因为它们不具备随机访问特性。在单链表中,为了找到某个特定元素,必须从头结点开始沿着指针逐个遍历节点,其查询时间复杂度为 o(n),其中 n 是链表中元素的数量。
- 哈希表:
- 查询效率:哈希表的理想查询时间复杂度也是 o(1),这是基于理想哈希函数的前提下,能够将输入的关键字均匀地映射到哈希表的不同槽位,且没有冲突发生。当发生哈希冲突并采用链地址法解决冲突时(例如java中的hashmap),即使存在冲突,只要哈希函数设计得较好,实际查询性能仍然接近 o(1)。
- 实际上,随着哈希表负载因子增大,冲突概率增加,查询性能可能会退化至接近 o(n),但一般情况下,好的哈希函数配合动态调整大小等机制,能将这种影响降到最低。
哈希表的常用操作
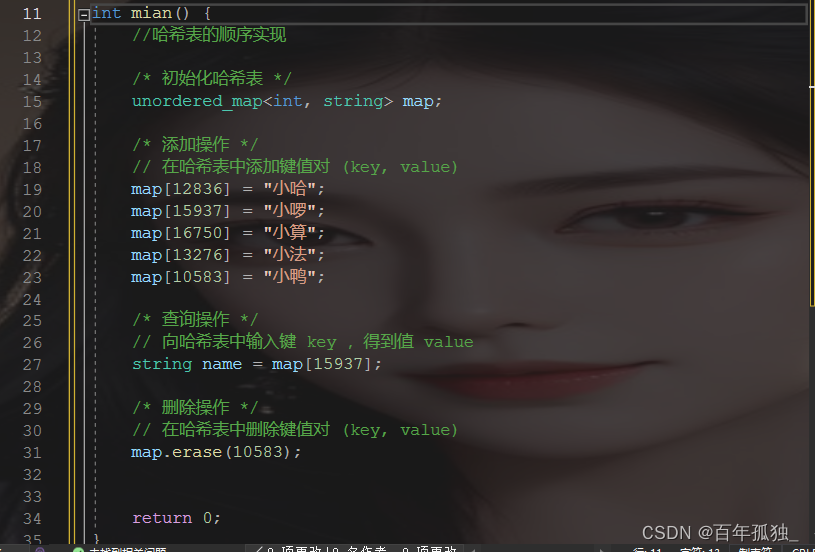
哈希表的遍历:(c++/java)
/* 遍历哈希表 */
// 遍历键值对 key->value
for (auto kv: map) {
cout << kv.first << " -> " << kv.second << endl;
}
// 使用迭代器遍历 key->value
for (auto iter = map.begin(); iter != map.end(); iter++) {
cout << iter->first << "->" << iter->second << endl;
}
/* 遍历哈希表 */
// 遍历键值对 key->value
for (map.entry <integer, string> kv: map.entryset()) {
system.out.println(kv.getkey() + " -> " + kv.getvalue());
}
// 单独遍历键 key
for (int key: map.keyset()) {
system.out.println(key);
}
// 单独遍历值 value
for (string val: map.values()) {
system.out.println(val);
}
数组实现哈希散列(通俗易懂)
在哈希表中,我们将数组中的每个空位称为桶(bucket),每个桶可存储一个键值对。因此,查询操作就是找到 key 对应的桶,并在桶中获取 value 。
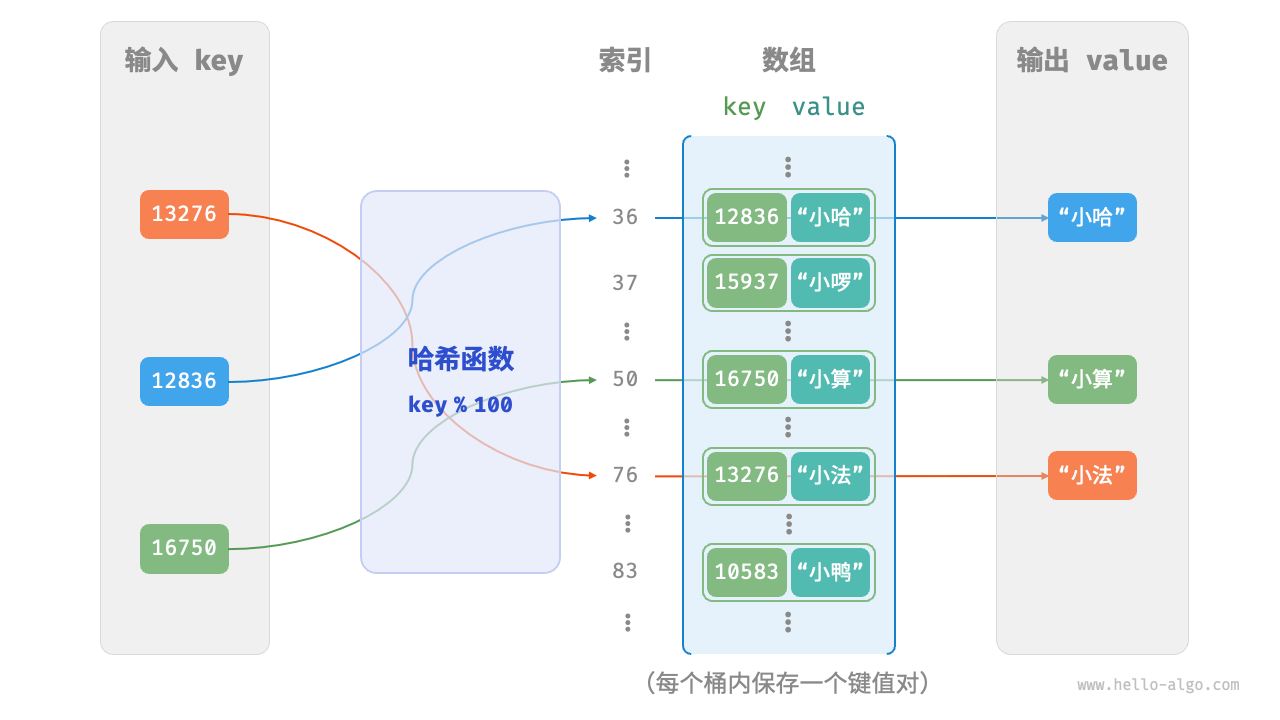
- 当向哈希表插入一个键值对 (key, value) 时,首先会使用哈希函数计算出 key 的哈希值,该哈希值通常会经过某种处理以适应数组的索引范围。
- 计算得到的索引对应的数组位置就是一个“桶”。如果该“桶”为空,则直接将键值对存入;如果不为空,且仅有一个元素(即没有哈希冲突),则同样直接存放;若已有多个元素(发生了哈希冲突),则可能采用链地址法(linked list)或开放寻址法等方式解决冲突,即将新的键值对添加到该“桶”内适当的位置。
- 在查询操作时,我们同样使用哈希函数计算待查询 key 的哈希值,然后根据此哈希值找到相应的“桶”。
- 查找“桶”后,如果桶内只有一个元素,或者可以直接找到匹配的 key,那么就可以立即返回对应的 value。如果桶内有多个元素(因哈希冲突),则需要进一步在桶内进行查找,直到找到匹配的 key 或确定不存在为止。
哈希函数
####是一种特殊的数学函数,接受任意长度的输入(通常是字符串或者其他类型的数据),通过一定的算法将其转化为固定长度的输出,这个输出的值通常被称为哈希值(hash value) ,散列值或者消息摘要。
哈希函数的主要特点包括:
- 唯一性(尽可能):不同的输入应该产生不同的输出,理想的哈希函数使得任何两个不同的输入映射到同一个输出的概率极低。
- 确定性:相同的输入总是会产生相同的输出。
- 固定长度输出:不论输入数据的大小如何变化,哈希函数产生的输出长度都是固定的。
- 不可逆性:一个好的哈希函数应当很难通过其输出反推回原始输入,也就是说它是非对称、不可逆的。
- 雪崩效应:输入数据稍作改动,输出的哈希值应该会有很大变化,这样即便两个输入很相近,它们的哈希值也应该看起来毫无关联。
###在计算机科学和密码学中,哈希函数有多种应用场景,如:
- 数据完整性验证:通过计算文件或数据块的哈希值,可以在传输前后比较哈希值来确认数据是否被篡改。
- 密码存储:在安全领域,用户的密码通常不会明文存储,而是存储其哈希值,并结合盐值(salt)防止彩虹表攻击。
- 数据索引:在数据结构如哈希表中,哈希函数用于快速定位数据项在表中的位置,实现高效查找和插入操作。
- 区块链技术:在比特币和其他加密货币中,哈希函数用于生成区块哈希,确保交易的安全性和账本的一致性。
哈希表(hash table) 在编程中,哈希函数用于创建和查询哈希表。例如,假设我们有一个简单的电话簿程序,需要快速查找联系人姓名对应的电话号码。
- 假设我们设计了一个简单的哈希函数
hash(key),它接受一个字符串作为键(即姓名),并返回一个整数索引。 - 当添加新的联系人时,我们首先使用哈希函数计算姓名的哈希值,然后将其存入相应索引的位置(如果发生冲突,则采用解决冲突的方法如链地址法或开放寻址法)。
- 查找联系人时,同样对姓名应用哈希函数获取索引,然后从哈希表中对应位置找到电话号码。
密码存储 在用户注册系统中,不直接存储用户的密码原文,而是存储密码经过哈希运算后的值。当用户登录时,系统会对用户输入的密码做同样的哈希运算,然后与数据库中存储的哈希值进行比对。
例如:
- 用户设定的密码是
"myp@ssword123"。 - 系统使用一个强壮的哈希函数(如bcrypt或argon2)对该密码进行处理,得到哈希值
"$2b$12$sgvq2yvydqjz..jrruh/wo/gpgzwu/exxqo8a.ylxnldtkwqzi/"并存储此值。 - 当用户下次登录时,输入相同密码
"myp@ssword123",系统再次应用同一哈希函数并检查生成的哈希值是否与存储值匹配。
代码实现
/* 键值对 */
struct pair {
public:
int key;
string val;
pair(int key, string val) {
this->key = key;
this->val = val;
}
};
/*构造函数 pair(int key, string val):这是结构体的一个成员函数,用于初始化新创建的pair实例。当通过pair构造函数创建一个新对象时,需要传入一个整数和一个字符串作为参数。构造函数内部通过this->key = key; 和 this->val = val;语句将传入的实参赋值给结构体内的成员变量。*/
/* 基于数组实现的哈希表 */
class arrayhashmap {
private:
vector<pair *> buckets;
public:
arrayhashmap() {
// 初始化数组,包含 100 个桶
buckets = vector<pair *>(100);
}
~arrayhashmap() {
// 释放内存
for (const auto &bucket : buckets) {
delete bucket;
}
buckets.clear();
}
/* 哈希函数 */
int hashfunc(int key) {
int index = key % 100;
return index;
}
/* 查询操作 */
string get(int key) {
int index = hashfunc(key);
pair *pair = buckets[index];
if (pair == nullptr)
return "";
return pair->val;
}
/* 添加操作 */
void put(int key, string val) {
pair *pair = new pair(key, val);
int index = hashfunc(key);
buckets[index] = pair;
}
/* 删除操作 */
void remove(int key) {
int index = hashfunc(key);
// 释放内存并置为 nullptr
delete buckets[index];
buckets[index] = nullptr;
}
/* 获取所有键值对 */
vector<pair *> pairset() {
vector<pair *> pairset;
for (pair *pair : buckets) {
if (pair != nullptr) {
pairset.push_back(pair);
}
}
return pairset;
}
/* 获取所有键 */
vector<int> keyset() {
vector<int> keyset;
for (pair *pair : buckets) {
if (pair != nullptr) {
keyset.push_back(pair->key);
}
}
return keyset;
}
/* 获取所有值 */
vector<string> valueset() {
vector<string> valueset;
for (pair *pair : buckets) {
if (pair != nullptr) {
valueset.push_back(pair->val);
}
}
return valueset;
}
/* 打印哈希表 */
void print() {
for (pair *kv : pairset()) {
cout << kv->key << " -> " << kv->val << endl;
}
}
};
##注意事项:
哈希函数的设计至关重要,它直接影响着哈希表的性能和空间利用率。
解决哈希冲突的策略会影响哈希表在高负载条件下的表现和内存使用效率。
安全考量:
在一些安全敏感的应用中(如密码存储),哈希函数不仅需要速度快,还需要具备足够的随机性和不可预测性,以抵抗碰撞攻击和预计算攻击




发表评论