7系列fpga数据手册:概述------中文翻译版
- 7系列fpga功能摘要
- spartan-7系列fpga功能摘要
- artix-7系列fpga功能摘要
- kintex-7系列fpga功能摘要
- virtex-7系列fpga功能摘要
- 堆叠式硅互联(ssi)技术
- clbs, slices, and luts
- block ram
- digital signal processing---dsp slice
- 低功耗g比特收发器
-
- 用于pci express设计的集成接口模块
- xadc(数模转换器)
- 7 series fpga ordering information
总体介绍
xilinx®7系列fpga包括四个系列(spartan®,artix®-7,kintex®-7,virtex®-7),能够满足系统全部范围的要求,价格低廉,尺寸小,对成本敏感,超高端的连接带宽,逻辑容量及信号处理能力的大量应用,满足了系统对高性能的要求。7系列的fpga包括:
- spartan®-7系列:价格低廉,供电电源低,i/o性能高。可提供低成本,非常小的外形尺寸封装,以实现最小的pcb占地面积。
- artix®-7系列:针对需要串行收发器以及高dsp和逻辑吞吐量的低功耗应用进行了优化。为高吞吐量、成本敏感型应用提供最低的总物料成本。
- kintex®-7系列:针对最佳性价比进行了优化,与上一代产品相比提高了两倍,支持新一代的fpga。
- virtex®-7系列:针对最高系统性能和容量进行了优化,系统性能提高了两倍。通过硅堆叠技术(ssi)实现的最高性能器件。
7系列fpga采用最先进的高性能、低功耗(hpl)、28nm、高k金属栅(hkmg)工艺技术,i/o带宽为2.9tb/s,逻辑单元容量为200万个,dsp定点运算性能为5.3tmac/s,[其中virtex-7系列的dsp处理能力为5,335 gmac/s(gmac/s:每秒10亿次乘加运算)],实现了无与伦比的性能提升,同时功耗比前一代器件低50%,为assp(application specific standard parts 专用标准产品)和asic提供了完全可编程的替代方案。
7系列fpga功能摘要
- 先进的高性能fpga逻辑,基于可配置为分布式内存的实6输入查找表(lut)技术;
- 36kb双端口块ram 内置fifo逻辑,用于片上数据缓冲;
- 高性能selectiotm技术,支持高达1866mb/s的ddr3接口;
- 内置多千兆收发器实现高速串行连接,最高可达600mb/s。
- 针对6.6gb/s至28.05gb/s的速率,提供特殊的低功耗模式,并对芯片间的接口做了优化。
- 用户可配置模拟接口(xadc),集成12位1msps带片上热传感器和电源传感器的模数转换器;
- 带有25×18乘法器、48位累加器和前值加法器的dsp片可实现高性能滤波,包括优化的对称系数滤波;
- 强大的时钟管理模块(cmt),结合锁相环(pll)和混合模式时钟管理器(mmcm),可实现高精度和低抖动;
- 利用microblazetm处理器快速部署嵌入式处理器;
- 适用于pci express®(pcie)的集成块,最多可支持×8 gen3端点和根端口设计;
- 多种配置选项,包括支持商用存储器、带hmav/sha-256(加密算法)身份验证的256位aes(advanced encryption standard高级加密标准)加密,内置seu检测和纠正。
- 低成本、线耦合、裸芯倒片封装和高信号完整性倒片封装,可在同一封装系列的产品之间轻松移植。所有封装均提供无铅封装和精选含铅封装选项;
- 专为高性能和低功耗而设计,具有28nm、hkmg、hpl工艺、1.0v核心电压工艺技术和0.9v电压选项,可实现更低功耗。
表1:7系列fpga比较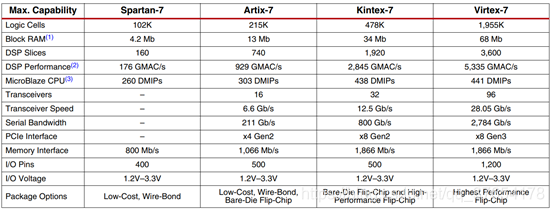
注释:
- 以分布式ram形式提供额外内存。
- 峰值dsp性能是基于对称滤波器实现的。
- microblaze cpu的峰值性能是基于微控制器预置来实现的。
spartan-7系列fpga功能摘要
表2:按型号划分的spartan-7 fpga功能摘要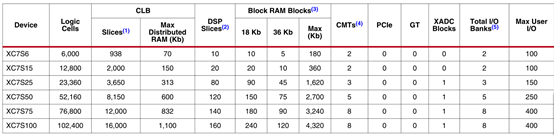
注释:
1.每个7系列fpga包含4个lut和8个触发器;只有某些片可以将它们的lut用作分布式ram或srl(移位寄存器)。
2.每个dsp片包括一个前置加法器、一个25×18乘法器、一个加法器和一个累加器。
3.block ram的大小基本上为36kb;每个bram也可以用作两个独立的18kb blocks。
4.每一个cmt包含一个mmcm和一个pll。
5.不包括配置库0。
表3 spartan-7 fpga封装组合及最大i/o数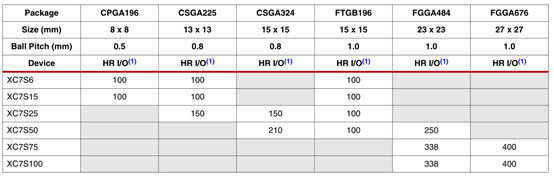
注释:
1.hr=高范围i/o,支持1.2v到3.3v的i/o电压。
artix-7系列fpga功能摘要
表四:按型号划分的artix-7 fpga功能摘要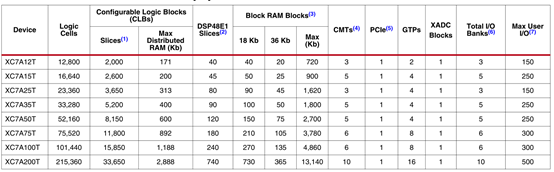
注释:
- 每个7系列fpga包含4个lut和8个触发器;只有某些片可以将它们的lut用作分布式ram或srl(移位寄存器)。
- 每个dsp片包括一个前置加法器、一个25×18乘法器、一个加法器和一个累加器。
- block ram的大小基本上为36kb;每个bram也可以用作两个独立的18kb blocks。
- 每一个cmt包含一个mmcm和一个pll。
- artix-7系列fpga接口块用作pcie时,最多支持x4 gen 2。
- 不包括配置库0。
- 此数字不包括gtp收发器。
表五:artix-7 fpga封装组合及最大i/o数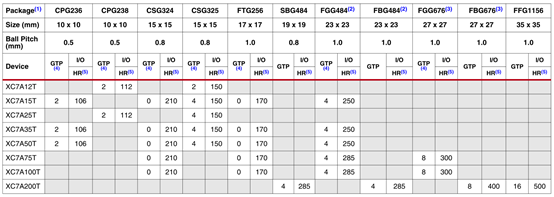
1.所有列出的封装均为无铅封装(sbg、fbg、ffg、除了15)。一些封装在有铅选项中可用。
2.fgg484和fbg484引脚兼容。
3.fgg676和fbg676引脚兼容。
4.cp、cs、ft、fg封装的gtp收发器支持最高6.25gb/s的数据速率。
5.hr=高范围i/o,支持1.2v到3.3v的i/o电压。
kintex-7系列fpga功能摘要
表六:按型号划分的kintex-7 fpga功能摘要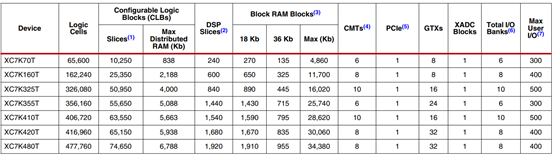
1.每个7系列fpga包含4个lut和8个触发器;只有某些片可以将它们的lut用作分布式ram或srl(移位寄存器)。
2.每个dsp片包括一个前置加法器、一个25×18乘法器、一个加法器和一个累加器。
3.block ram的大小基本上为36kb;每个bram也可以用作两个独立的18kb blocks。
4.每一个cmt包含一个mmcm和一个pll。
5.kintex-7系列fpga接口块用作pcie时,最多支持x8 gen 2。
6.不包括配置库0。
7.此数字不包括gtx收发器。
表七:kintex-7 fpga封装组合及最大i/o数
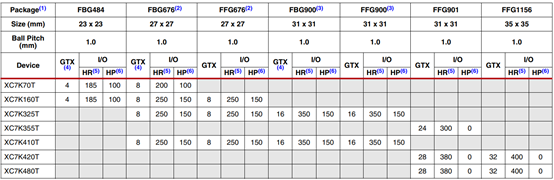
注释:
1.所有列出的封装均为无铅封装(fbg、ffg、除了15)。一些封装在有铅选项中可用。
2.fbg676和ffg676引脚兼容。
3.ffg900和fbg900引脚兼容。
4.fb封装下的gtx收发器支持以下最大数据速率:fbg484:10.3gb/s;fbg676和fbg900:6.6gb/s。详细信息可以参考kintex-7 fpga数据手册:直流和交流开关特性(ds182)
5. hr=高范围i/o,支持1.2v到3.3v的i/o电压。
6.hp=高性能i/o,支持1.2v到1.8v的i/o电压。
virtex-7系列fpga功能摘要
表8:virtex-7 fpga功能摘要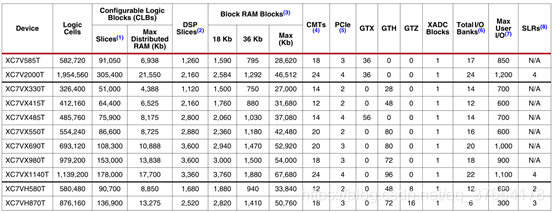
注释:
1.每个7系列fpga包含4个lut和8个触发器;只有某些片可以将它们的lut用作分布式ram或srl(移位寄存器)。
2.每个dsp片包括一个前置加法器、一个25×18乘法器、一个加法器和一个累加器。
3.block ram的大小基本上为36kb;每个bram也可以用作两个独立的18kb blocks。
4.每一个cmt包含一个mmcm和一个pll。
5.virtex-7系列fpga接口块用作pcie时,最多支持x8 gen 2。virtex-7 xt和virtex-7 ht接口块支持x8 gen 3,xc7vx485t除外,它支持x8 gen 2。
6.不包括配置库0。
7.此数字不包括gtx、gth、gtz收发器。
8.超逻辑域(slr)是使用ssi技术fpga的组成部分。virtex-7 ht利用ssi技术将slr和28.05gb/s的收发器连接起来。
表9:virtex-7 fpga封装组合及最大i/o数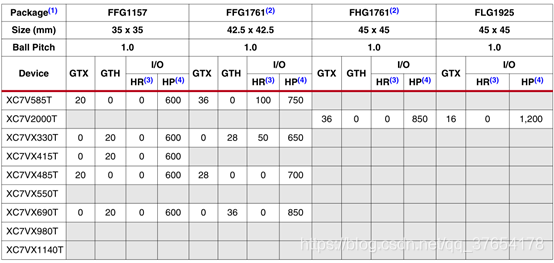
注释:
1.所有列出的封装均为无铅封装(ffg、flg、fhg除了15)。一些封装在有铅选项中可用。
2.ffg1761和fhg1761引脚兼容。
3. hr=高范围i/o,支持1.2v到3.3v的i/o电压。
4.hp=高性能i/o,支持1.2v到1.8v的i/o电压。
表10:virtex-7 fpga封装组合及最大i/o数
注释:
1.所有列出的封装均为无铅封装(ffg、flg除了15)。一些封装在有铅选项中可用。
2.ffg1926和flg1926引脚兼容。
3.ffg1928和flg1928引脚兼容。
4.ffg1930和flg1930引脚兼容。
5.hp=高性能i/o,支持1.2v到1.8v的i/o电压。
表11: virtex-7 fpga封装组合及最大i/o数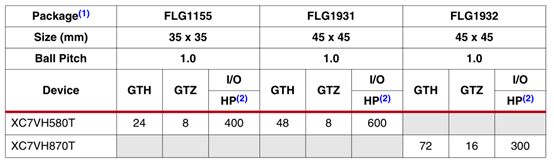
1.所有列出的封装均为无铅封装,除了15。一些封装在有铅选项中可用。
2.hp=高性能i/o,支持1.2v到1.8v的i/o电压。
堆叠式硅互联(ssi)技术
xilinx利用ssi技术解决了与创建高容量fpga相关的许多挑战。ssi技术使得多个超逻辑域(slr)能够组合在无源插入器层上,使用业界领先的成熟制造和组装技术,来创建具有超过一万个slr内连接的单个fpga,来提供超低延迟和低功耗的超高带宽连接。virtex-7 fpga中使用了两种类型的slr:virtex-7 t中使用的是逻辑密集型slr;virtex-7 xt和virtex-7 ht中使用的是dsp/block ram/多收发器型slr。与传统制造方法相比,ssi技术能够生产更高性能的fpga,使有史以来最大容量和最高性能的fpga能够更快地投产,风险也更小。数千条超长线路(sll)布线资源和跨越slr的超高性能时钟线路确保设计能够无缝跨越这些高密度的可编程逻辑器件。
clbs, slices, and luts
clb架构的一些主要功能包括:
- 实6输入查找表
- lut中的内存功能
- 寄存器和移位寄存器功能
7系列fpga中的lut既可以配置为一个输出的6输入lut(64位rom),也可以配置为两个独立输出但地址或逻辑输入相同的5输入lut(32位rom)。每片8个触发器中的4个(每个lut一个)可以选择性的配置成为锁存器。
25%-50%的slice还可以将它们的lut用作分布式64位ram或者32位的移位寄存器(srl32),或者两个16位的srl16。现代综合工具利用了这些高效的逻辑、算术和存储器功能。
时钟管理
时钟管理体系结构的一些主要亮点包括:
- 用于低时滞分布的高速缓冲器和布线。
- 频率合成及移相。
- 产生低抖动时钟和抖动滤波。
每个7系列fpga都有多达24个时钟管理片(cmt),每个片由一个混合模式时钟管理器(mmcm)和一个锁相环(pll)组成。
混合模式时钟管理器与锁相环
mmcm和pll有许多特性。两者都可用作宽频率范围的频率合成器和输入时钟的抖动滤波器。在这两个组件的中心是一个压控振荡器(vco),根据从相位频率检测器(pfd)接收到的输入电压来加快或减慢振荡频率。
有三组可编程分频器:d、m和o。预分频器d(通过配置,然后通过drp来编程)降低输入频率,反馈给传统锁相环相位/频率比较器的一个输入。反馈分频器m(可通过配置,然后通过drp编程)充当乘法器,因为它在反馈给相位比较器的另一个输入之前对压控振荡器输出频率进行分频。必须合适地选择d和m,来将压控振荡器保持在指定的频率范围内。
压控振荡器有8个等距输出相位(0°、 45°、 90°、135°、180°、225°、270°和315°)。每一个都可以选择驱动其中一个输出分频器(六个用于锁相环,o0至o5,七个用于mmcm,o0至o6),每个都可以通过配置来编程,来除以1至128之间的任何整数。
mmcm和pll有三种输入抖动滤波器选项:低带宽、高带宽或者优化模式。低带宽模式的抖动衰减最好,但相位偏移最小。高带宽模式具有最佳相位偏移,但不具有最佳抖动衰减。优化模式允许工具找到最佳的设置。
mmcm附加的可编程功能
mmcm可以在反馈回路(充当乘法器)或者一个输出路径中有一个小数计数器。小数计数器允许1/8的非整数增量,因此可以将频率合成能力提高8倍。
mmcm还可以根据压控振荡器频率,以小增量提供固定或者动态相移。在1600mhz条件下,相移时序增量为11.2ps。
时钟分配
每个7系列fpga都提供六种不同类型的时钟线路(bufg、bufr、bufio、bufh、bufmr和高性能时钟),以满足高扇出、短传播延迟和极低偏差的不同时钟的要求。
全局时钟线
在每个7系列fpga(xc7s6和xc7s15除外)中,32条全局时钟线具有最高的扇出,可以达到每个触发器的时钟、时钟使能、置位/复位端口及许多逻辑电路的输入端口。在由水平时钟缓冲器(bufh)驱动的任何时钟区域内有12条全局时钟线。每个bufh可以独立地使能/禁用,从而允许在一个区域内关闭时钟,从而提供对那些时钟区域消耗功率的细粒度控制。全局时钟线可以由全局缓冲器驱动,全局缓冲器还可以执行无故障多路复用和时钟使能功能。全局时钟通常由cmt驱动,这可以完全消除基本时钟的分布延迟。
区域时钟
区域时钟可以驱动其区域内的所有时钟目的地。区域定义为:i/o数量为50,clb数量为50,芯片宽度为一半的区域。7系列fpga有2到24个区域。每个区域都有4个时钟,每个区域时钟缓冲器可以由四个支持时钟的输入引脚中的任何一个来驱动,其频率可以选择1到8之间的任意整数。
i/o时钟
i/o时钟通常特别快,仅服务于i/o逻辑和串行/解串器电路,这部分将在i/o逻辑章节讲述。7系列器件mmcm和i/o之间有之间连接的通路,来实现低抖动、高性能接口。
block ram
block ram的一些主要功能包括:
- 双端口36kb数据块ram,端口宽度最高可达72.
- 可编程的fifo逻辑
- 内置可选纠错电路
每个7系列fpga都有5到1880个双端口数据块ram,每个存储36kb。每个块ram都有两个完全独立的端口,除了共享数据,其他什么都不共享。
同步操作
每次存储器访问(读或写)都由时钟控制。所有输入、数据、地址、时钟使能和写入使能都被锁存。时钟到来之前,所有的动作都是无效的。输入地址始终计时,保留数据直到下一次操作。可选的输出数据流水线寄存器允许更高的时钟速率,但代价是额外的延迟周期。
在写入操作期间,数据输出可以反映先前存储的数据。新写入的数据、或者可以保持不变
可编程数据宽度
每个端口可以配置为32k×1、16k×2、8k×4、4k×9(或8)、2k×18(或16)、1k×36(或32)或512×72(或64)。两个端口可以没有任何限制地具有不同的长宽比。每个块ram可以分为两个完全独立的18kbram,每个块ram可以配置为16k×1到512×36之间的任意长宽比。
只有在简单双端口模式(sdp)下才能访问大于18位(18kb ram)或36位(36kb ram)的数据宽度。在该模式下,一个端口用于读操作,另一个端口用于写操作。在sdp模式下,一侧(读取或写入)可以可变,而另一侧固定为32/36或64/72。
双端口36kbram的两侧宽度可以可变。
两个相邻的36kb 块ram可以配置为一个级联的64k×1双端口ram,不需要任何额外的逻辑。
错误检测和纠正
每个64位宽的块ram可以生成、存储和利用8比特额外的汉明码,并在读取过程中执行单比特纠错和双比特纠错。在写入或读取外部64位至72位宽的存储器时,也可以使用ecc逻辑。
fifo控制器
用于单时钟(同步)或双时钟(异步或多速率)操作的内置fifo控制器递增内部地址,并提供四个握手标志:full, empty, almost full and almost empty。almost full和almost empty标志可自由编程 。与块ram类似,fifo的宽度和深度是可编程的,但写入端口和读取端口始终具有相同的宽度。
first word fall through 模式在第一个读取操作之前将第一个写入的数据输出,在第一个数据被读出之后,标准模式与first word fall through模式没有什么区别。
digital signal processing—dsp slice
dsp功能的一些亮点包括:
- 25×18二进制补码乘法器/累加器,高分辨率(48位)信号处理器。
- 优化对称滤波器应用的节电前置加法器。
- 高级功能:可选的流水线、可选的alu和用于级联的专用总线。
dsp应用中使用的许多二进制乘法器和累加器,最好在专用的dsp片中实现。所有7系列的fpga都有许多专用、全定制、低功耗的dsp芯片,在保持系统设计灵活性的同时,兼顾高速和小型化。
每个dsp芯片基本上由一个专用的25×18位二进制补码乘法器和一个48位累加器组成,两者的工作频率都高达741mhz。乘法器可以动态旁路,两个48位输入可馈送单指令多数据(simd)算术单元(双24位加/减/累加或4个12位加/减/累加),或可生成两个操作数的十个不同逻辑函数中的任何一个逻辑单元。
dsp包括一个额外的前置加法器,通常用于对称滤波器。这种前置加法器提高了密集型封装设计的性能,将dsp片的数量减少了高达50%。dsp还包括一个48位宽的模式检测器,可用于收敛或对称舍入。当与逻辑单元结合使用时,模式检测器还可以实现96位宽的逻辑功能。
dsp slice提供广泛的流水线和扩展功能,可提高数字信号处理以外的许多应用的速度和效率,例如宽动态总线移位器、内存地址生成器、宽总线多路复用器和内存映射i/o寄存器堆。累加器还可以用作同步加减计数器。
输入/输出
输入输出功能的一些亮点包括:
- 高性能selectio技术,支持1866mb/s ddr3。
- 封装内的高频去耦电容器可增强信号的完整性。
- 数字控制阻抗,可为最低功耗、高速i/o操作提供三种状态。
i/o引脚的数量因型号和封装大小而异。每个i/o都是可配置的,并且符合许多的i/o标准。除了电源引脚和专用配置引脚外,所有其他封装的引脚都具有相同的i/o性能,仅受某些分组规则的限制。7系列fpga中的i/o分为高范围(hr)和高性能(hp)。hr i/o提供最大范围的电压支持,从1.2v到3.3v。hp i/o针对1.2v到1.8v的最高性能操作做了优化。
7系列fpga中的hr和hp i/o引脚按组进行分组,每50个引脚一组。每一组都有一个共同的v_cco输出电源,该电源还为某些输入缓冲器供电。一些单端输入缓冲器需要内部产生或外部施加的参考电压v_ref。每一组有两个v_ref引脚,而且一组中只能有一个v_ref电压值。
xilinx 7系列fpga采用多种封装类型来满足客户需求,包括可实现最低成本的小型引线键合封装;传统高性能倒装芯片封装;以及平衡最小外形尺寸和高性能的裸片倒装芯片封装。在倒装芯片封装中,硅器件使用高性能倒装芯片工艺连接到封装基板上。受控esr离散去耦合电容器安装在封装基板上,在输出同时切换的条件下,优化信号的完整性。
i/o电气特性
单端输出采用传统的cmos推挽输出结构,将高电平驱动到v_cco,将低电平驱动到地,并且可以置于高阻态。系统设计者可以指定转换速率和输出强度。输入始终处于活跃状态,但在输出处于活跃状态时通常会被忽略。每个引脚都有可选的一个弱上拉电阻和一个弱下拉电阻。
大多数信号引脚对可以配置为差分输入对或输出对。差分输入引脚对可以选择使用100 的端电阻。所有7系列器件均支持lvds以外的差分标准:rsd、blvd、差分sstl和差分hstl。
每一个i/o都支持内存i/o标准,例如单端和差分hstl以及单端和差分sstl。对于ddr3接口应用,sstl i/o标准最高可支持1866mb/s的数据速率。
三态数控阻抗和低功耗i/o特性
三态数字控制阻抗(t_dci)可以控制输出驱动阻抗(串联终端),或者可以为v_cco提供输入信号的并行终端,或者为v_cco/2提供split(戴维南)终端。这样,用户就可以使用t_dci消除信号的片外端接。除了节省电路板空间外,端子在输出模式或三态时自动关闭,与片外端子相比可节省相当大的功耗。i/o还具有ibuf和idelay的低功耗模式,特别是在用于实现存储器接口时,可进一步节省能量。
i/o逻辑
输入输出延迟
所有输入输出均可配置成组合逻辑或者寄存器。所有输入输出均支持双倍数据数率(ddr)。所有的输入和某些输出可以分别延迟最多32个增量,分别为78ps、52ps或39ps。这样的延迟被实现为idelay和odelay。延迟步进值可以通过配置设置,也可以在使用时递增或递减。
iserdes和oserdes
许多应用将高速位串行i/o与器件内部较慢的并行操作结合在一起。这需要i/o结构内的串行器和解串行器。每个i/o引脚都有一个8位ioserdes(iserded和oserdes),能够执行可编程宽度为2、3、4、5、6、7、或8位的串并或并串转换。通过从两个相邻引脚(默认来自差分i/o)级联两个ioserde,还可以支持10位和14位的更宽宽度转换。iserdes具有特殊的过采样模式,能够对基于1.25gb/slvds i/o的sgmii接口等应用进行异步数据恢复。
低功耗g比特收发器
低功耗g比特收发器的一些亮点包括:
- 根据系列的不同,高性能收发器最高可支持6.6gb/s(gtp)、12.5gb/s(gtx)、13.1gb/s(gth)、28.05gb/s(gtz)的线速,实现了首个适用于400g的单一器件。
- 针对芯片到芯片接口优化的低功耗模式 。
- 适用于长距离或背板应用的高级传输预加重和后加重,接收机线性均衡(ctle)和判决反馈均衡(dfe)。在接收机均衡和片上眼睛扫描时自动适应,轻松进行串行链路调谐。
超高速串行数据传输到光模块、在同一pcb板上的ic之间、通过背板或者通过更长的距离传输变得越来越流行,并且对于使客户线卡能够扩展到100gb/s和更高的400gb/s变得越来越重要。它需要专门的专用 片上电路和差分i/o,能够在如此高的数据速率下处理信号完整性问题。
7系列fpga中的收发器数量从artix-7系列中的多达16个收发器电路、kintex-7系列中的多达32个收发器电路以及virtex-7系列中的多达96个收发器电路不等。每个串行收发器都有发送器和接收器组成。各种7系列串行收发器使用环形振荡器和电容电感谐振回路的组合,或者在gtz情况下使用单个电容电感谐振回路结构,以实现灵活性和性能的完美结合,同时实现了ip核在同一系列的可移植性。不同的7系列型号支持不同的高端数据速率。gtp的运行速度高达6.6 gb/s,gtx的运行速度高达12.5 gb/s,gth的运行速度高达13.1 gb/s,gtz的运行速度高达28.05 gb/s。使用基于fpga逻辑的过采样可以实现较低的数据速率。串行发生器和接收器有独立的电路,使用先进的pll架构,将输入的参考频率乘以某些可编程数字,最高可达100,从而成为位串行时钟。每个收发器具有大量用户可定义的特征和参数。所有这些都可以在器件配置过程中定义,也可以在操作过程中进行修改。
发送器
发送器基本上是一个转换比为16、20、 32、 40 、64或80的并串转换器。此外,gtz发送器支持高达160位的数据宽度。这允许设计者在高性能设计中在数据路劲宽度和时序裕度之间进行权衡。这些发送器输出用单通道差分输出信号驱动pc板。txoutclk是经过适当分割的串行数据时钟,可直接用于锁存来自内部逻辑的并行数据。传入的并行数据通过可选的fifo馈送,并具有对8b/10b,64b/66b或64b/67b编码方案的额外硬件支持,以提供足够数量的转换。位串行输出信号用差分信号驱动两个封装引脚。该输出信号对具有可编程的信号摆幅以及可编程的前后加重,来补偿pc板的损耗和其他互连特性。对于较短的通道,可以减小摆幅以降低功耗。
接收器
接收器基本上市串并转换器,将传入的位串行信号转换为并行字流,每个字16、 20、 32 、40、 64或80位。此外,gtz接收器支持高达160位的数据宽度。这允许fpga设计者在内部数据路径宽度和逻辑时序裕度之间进行权衡。接收器接收传入的差分数据流,将其通过可编程线性和判断反馈均衡器馈送(以补偿pc板和其他互连特性),并使用参考时钟输入来初始换时钟识别。不需要单独的时钟线路。数据模式使用不归零(nrz)编码,并且可选地使用所选编码方案来保证足够的数据转换。然后使用rxusrclk时钟将并行数据传输到fpga逻辑。对于较短的通道,收发器提供了一种特殊的低功耗模式(lpm),可将功耗降低约30%。
带外信号传输
收发器提供带外信号(oob)传输,通常用于在高速串行数据传输处于非活跃状态时将低速信号从发送器发送到接收器。这通常在链路处于断电状态或尚未初始化时执行。这使pcie和sata/sas应用程序收益。
用于pci express设计的集成接口模块
pcie集成块的亮点包括:
- 符合具有端点和根端口功能的pcie基本规范2.1或3.0(取决于那个系列)。
- 支持gen1(2.5 gb/s)、gen2(5 gb/s)和gen3(8 gb/s),具体取决于器件系列。
-高级配置选项、高级错误报告(aer)和端到端crc(ecrc)高级错误报告和ecrc功能。 - 多功能和单根i/o虚拟化(sr-iov)支持通过软件逻辑包装实现。或者嵌入到集成块中,具体取决于器件系列。
所有artix-7、kintex-7和virtex-7器件至少包括一个用于pcie技术的集成块,可配置为符合pci e基本规范修订版2.1或3.0的端点或根端口。
根端口可用于构建兼容根联合体的基础,允许通过pcie协议进行自定义fpga到fpga通信,以及将assp端点设备(如以太网控制器或光纤通道hba)连接到fpga。
此模块可根据系统设计要求进行配置,可在2.5 gb/s、5.0 gb/s和8.0 gb/s数据速率下运行1、2、4或8通道。对于高性能应用,块的高级缓冲技术提供了最高1024字节的灵活最大有效载荷大小。集成块与集成高速收发器接口连接以实现串行连接,并与块ram连接以进行数据缓冲。这些元素的结合,实现了pcie协议的物理层、数据链路层和事务层。
xilinx提供了一个轻量级、可配置。易于使用的logiccoretmip封装器,它将各种构建块(pcie集成块、收发器、块ram和时钟资源)绑定到一个端点或根端口解决方案中。系统设计人员可以控制许多可配置参数:通道宽度、最大有效载荷大小、fpga逻辑接口速度、参考时钟频率以及基址寄存器解码和滤波器。
xilinx位集成块提供了两个包装器:axi4-stream和axi4(内存映射)。请注意,传统的trn/local link在用于pcie集成块的7系列设备中不可用。axi4-stream专为集成块的现有用户设计,支持从trn轻松移植到axi-stream。axi4(内存映射)是为xilinx platform studio/edk设计流和基于microblazetm处理器的设计而设计的。
有关pcie设计解决方案的更多信息和文档,请访问pci express
配置
有许多高级的配置功能,包括:
- 高速spi和bpi(并行或非)配置
- 内置多重启动和安全更新功能
- 采用hmac/sha-256身份验证的256位aes加密
- 内置seu检测和校正功能
- 部分重构
xilinx7系列fpga将其自定义配置存储在sram类型的内置锁存器中。配置位多达450mb,具体取决于器件大小和用户设计实现选项。配置存储是易失的,每当fpga通电时都必须重新加载。还可以随时通过将program_b引脚拉低来重新加载该存储。有几种加载配置的方法和数据格式可用,通过三个模式选择引脚来决定。
spi接口(×1、×2和×4模式)和bpi接口(并行或非×8和×16)是配置fpga的两种常用方法。用户可以将spi或bpi flash直接连接到fpga,fpga的内部配置逻辑从flash中读取位流并进行自我配置。fpga可动态自动检测总线宽度,无需任何外部控制或开关。spi支持总线宽度为×1、×2和×4,bpi支持的总线宽度为×8和×16。较宽的总线提高了配置速度,并减少了fpga在通电后启动所需的时间。并非所有的器件封装组合都支持某些配置选项,如bpi。有关详细信息,请参阅ug470。
在主模式下,fpga可以从内部生成的时钟驱动配置时钟,或者对于更高速度的配置,fpga可以使用外部配置时钟源。这允许利用主模式的易用特性进行高速配置。fpga还支持高达32位宽的从机模式,这对于处理器驱动配置特别有用。
fpga能够使用spi或bpi flash使用不同的映像对自身进行重新配置,不需要外部控制器。在数据传输任何错误的情况下,fpga可以重新加载其原始设计,从而确保在过程结束时fpga能够正常运行。这对于在最终产品上市前更新设计特别有用。客户可以将他们的产品与早期版本的设计一起上市,从而更快地将他们的产品推向市场。此功能允许客户在产品已在现场的情况下,使其最终客户获得最新的设计。动态重新配置端口(drp)使系统设计人员可以轻松访问mmcm、pll、xdc、收发器和pcie集成块等的配置和状态寄存器。drp的行为类似于一组内存映射寄存器,访问和修改特定于块的配置位以及状态和控制寄存器。
加密、回读和部分重配置
在所有7系列fpga(xc7s6和xc7s15除外)中,包含敏感客户ip的fpga位流可以通过256位aes加密和hmac/sha-256身份验证进行保护,以防止未经授权的复制设计。fpga在配置过程中使用内部存储上午256位密钥动态执行解密。该密钥可以驻留在电池后备ram或非易失性efuse位中。
大多数配置数据都可以回读,而不会影响系统的运行。通常,要么配置全,要么就不配置,但7系列fpga支持部分重新配置。这是一个极其强大和灵活的功能,允许用户更改fpga的部分,而其他部分保持不变。用户可以对这些部分进行时间分割,以便在较小的设备中容纳更多的ip,从而节省成本和功耗。在某些设计中适用的情况下,部分重新配置可以极大地提高fpga的通用性。
xadc(数模转换器)
xadc架构的亮点包括:
- 双12位1msps模数转换器(adc)。
- 多达17个且用户可配置的模拟输入。
- 片上或者外部基准电压选项。
- 片上温度(最大误差±4(_ ^∘)c)和电源(最大误差±1%)传感器。
- 通过jtag连续对adc测量的结果进行访问。
所有的xilinx7系列fpga(除了xc7s6和xc7s15)都集成了一种名为xadc的新型灵活模拟接口。当与7系列fpga的可编程逻辑功能相结合时,xadc可以满足广泛的数据采集和监控要求。更多信息,请访问:http://www.xilinx.com/ams
xadc包含两个12位1msps adc,带有独立的跟踪和保持放大器、一个片内模拟多路复用器(最多可支持17个外部模拟输入通道)以及片内热传感器和电源传感器。两个adc可以配置为同时对两个外部输入模拟通道进行采样。跟踪和保持放大器支持一系列模拟输入信号类型,包括单极性、双极性和差分。在1msps采样速率下,模拟输入可以支持至少500khz的信号带宽。使用具有专用模拟输入的外部模拟多路复用器模式可以支持更高的模拟带宽(参见ug480)。
xadc可选择使用片内基准电压源电路(±1%),因此无需任何外部有源元件即可对温度和供电进行基本的片内监控。要实现adc的全部12位性能,建议使用外部1.25v基准电压源芯片。
如果xadc未在设计中实例化,则默认情况下它会将所有片上传感器的输出数字化。最新的测量结果(包括最大和最小读数)存储在专用寄存器中,以便随时通过jtag接口访问。用户定义的报警阈值,可以自动指示超温事件和不可接受的电源变化。用户指定的阈值(如100(_ ^∘)c)可用于启动自动断电。

发表评论