一、flink sql概述
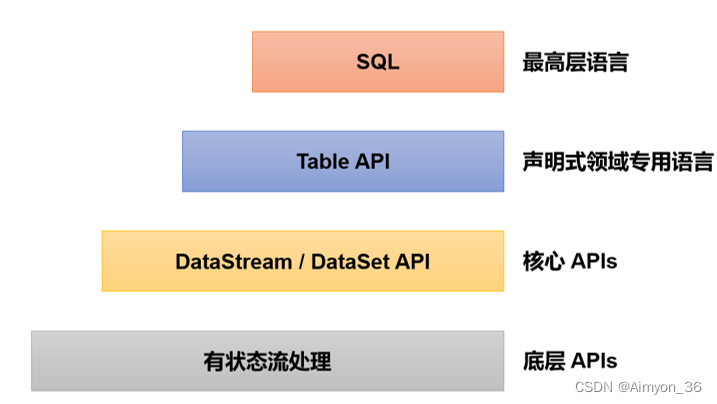
table api和sql是最上层的api,在flink中这两种api被集成在一起,sql执行的对象也是flink中的表(table),所以我们一般会认为它们是一体的。flink是批流统一的处理框架,无论是批处理(dataset api)还是流处理(datastream api),在上层应用中都可以直接使用table api或者sql来实现;这两种api对于一张表执行相同的查询操作,得到的结果是完全一样的。
需要说明的是,table api和sql最初并不完善,在flink 1.9版本合并阿里巴巴内部版本blink之后发生了非常大的改变,此后也一直处在快速开发和完善的过程中,直到flink 1.12版本才基本上做到了功能上的完善。而即使是在目前最新的1.17版本中,table api和sql也依然不算稳定,接口用法还在不停调整和更新。所以这部分希望大家重在理解原理和基本用法,具体的api调用可以随时关注官网的更新变化。
1.流处理中的表
我们可以将关系型表/sql与流处理做一个对比,如表所示。

关系型表和sql,主要就是针对批处理设计的,这和流处理有着天生的隔阂。接下来我们就来深入探讨一下流处理中表的概念。
流处理面对的数据是连续不断的,这导致了流处理中的“表”跟我们熟悉的关系型数据库中的表完全不同;而基于表执行的查询操作,也就有了新的含义。
动态表(dynamic tables)
动态表是flink在table api和sql中的核心概念,它为流数据处理提供了表和sql支持。我们所熟悉的表一般用来做批处理,面向的是固定的数据集,可以认为是“静态表”;而动态表则完全不同,它里面的数据会随时间变化。
持续查询(continuous query)
动态表可以像静态的批处理表一样进行查询操作。由于数据在不断变化,因此基于它定义的sql查询也不可能执行一次就得到最终结果。这样一来,我们对动态表的查询也就永远不会停止,一直在随着新数据的到来而继续执行。这样的查询就被称作“持续查询”(continuous query)。对动态表定义的查询操作,都是持续查询;而持续查询的结果也会是一个动态表。
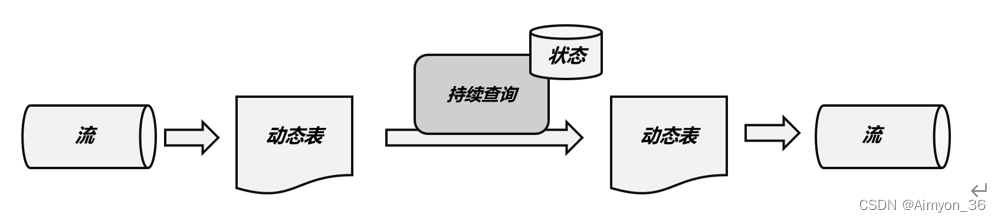
持续查询的步骤如下:
(1)流(stream)被转换为动态表(dynamic table);
(2)对动态表进行持续查询(continuous query),生成新的动态表;
(3)生成的动态表被转换成流。
这样,只要api将流和动态表的转换封装起来,我们就可以直接在数据流上执行sql查询,用处理表的方式来做流处理了。
2.将流转换成动态表
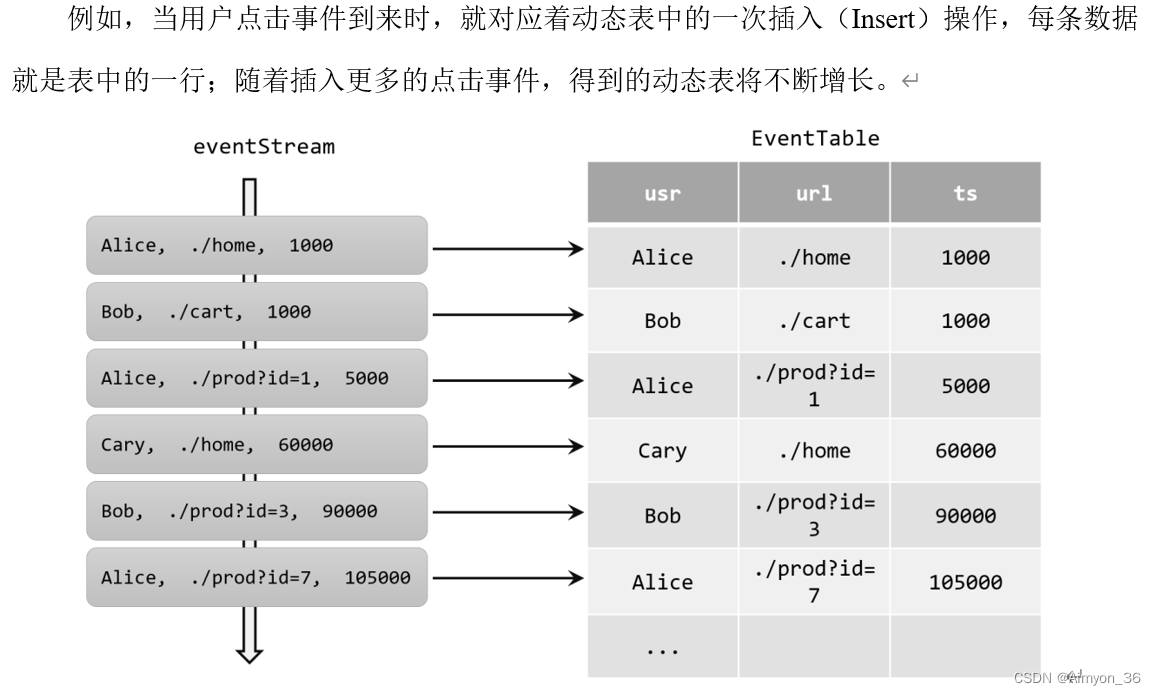
如果把流看作一张表,那么流中每个数据的到来,都应该看作是对表的一次插入(insert)操作,会在表的末尾添加一行数据。因为流是连续不断的,而且之前的输出结果无法改变、只能在后面追加;所以我们其实是通过一个只有插入操作(insert-only)的更新日志(changelog)流,来构建一个表。
更新(update)查询
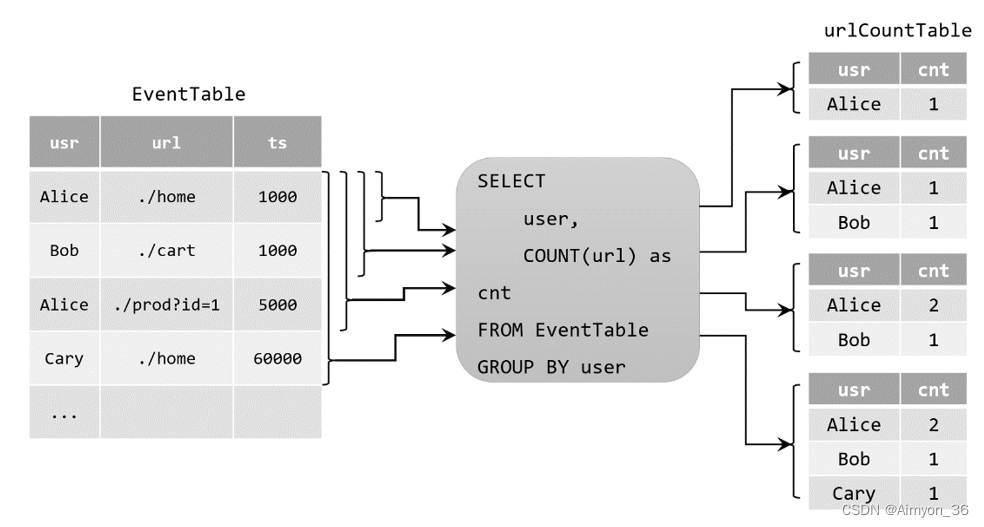
table urlcounttable = tableenv
.sqlquery("select user, count(url) as cnt from eventtable group by user");
当原始动态表不停地插入新的数据时,查询得到的urlcounttable会持续地进行更改。由于count数量可能会叠加增长,因此这里的更改操作可以是简单的插入(insert),也可以是对之前数据的更新(update)。这种持续查询被称为更新查询(update query),更新查询得到的结果表如果想要转换成datastream,必须调用tochangelogstream()方法。
追加(append)查询
上面的例子中,查询过程用到了分组聚合,结果表中就会产生更新操作。如果我们执行一个简单的条件查询,结果表中就会像原始表eventtable一样,只有插入(insert)操作了。
table alicevisittable = tableenv
.sqlquery("select url, user from eventtable where user = 'cary'");
这样的持续查询,就被称为追加查询(append query),它定义的结果表的更新日志(changelog)流中只有insert操作。
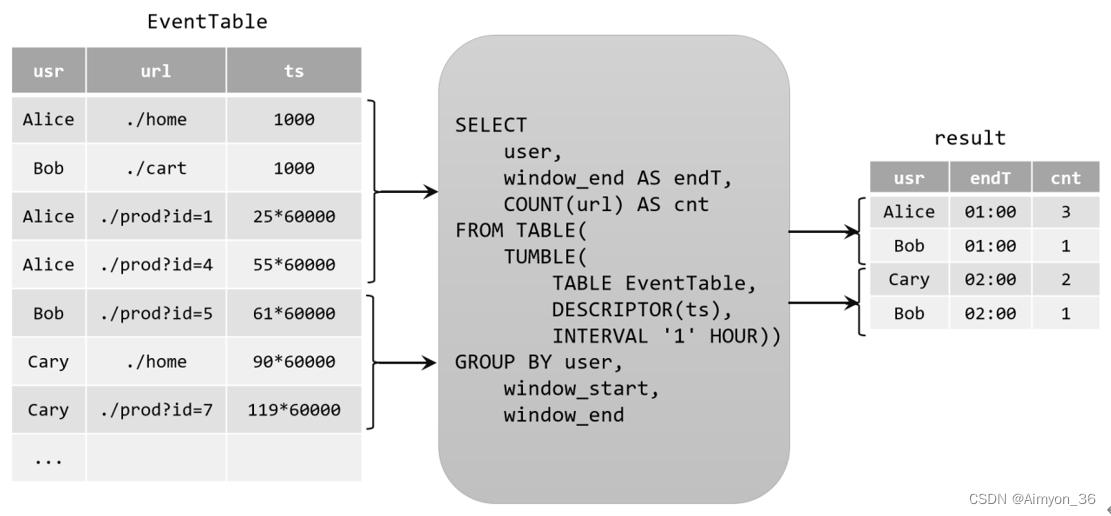
由于窗口的统计结果是一次性写入结果表的,所以结果表的更新日志流中只会包含插入insert操作,而没有更新update操作。所以这里的持续查询,依然是一个追加(append)查询。结果表result如果转换成datastream,可以直接调用todatastream()方法。
3.将动态表转换为流
与关系型数据库中的表一样,动态表也可以通过插入(insert)、更新(update)和删除(delete)操作,进行持续的更改。将动态表转换为流或将其写入外部系统时,就需要对这些更改操作进行编码,通过发送编码消息的方式告诉外部系统要执行的操作。在flink中,table api和sql支持三种编码方式:
仅追加(append-only)流
仅通过插入(insert)更改来修改的动态表,可以直接转换为“仅追加”流。这个流中发出的数据,其实就是动态表中新增的每一行。
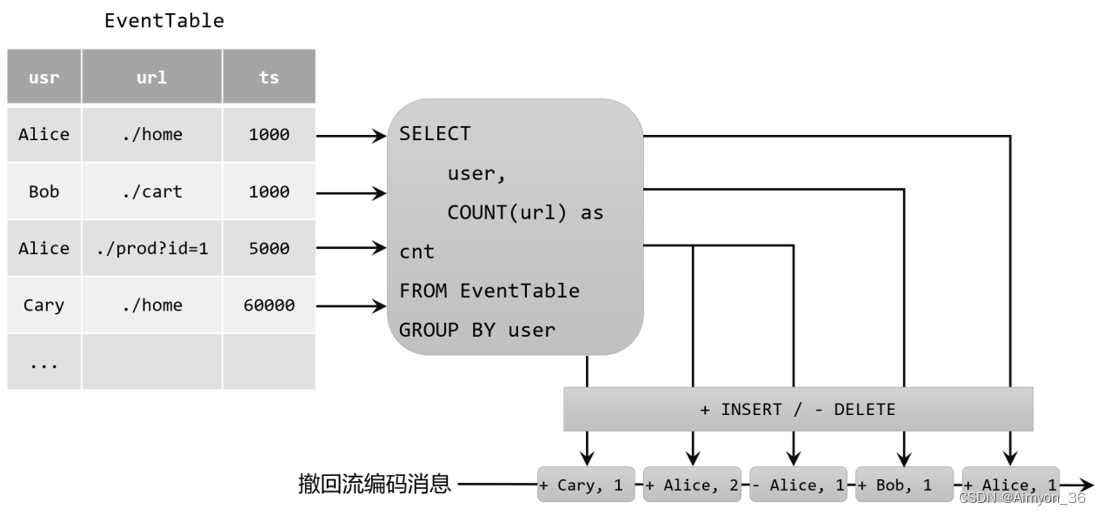
撤回(retract)流
撤回流是包含两类消息的流,添加(add)消息和撤回(retract)消息。
具体的编码规则是:insert插入操作编码为add消息;delete删除操作编码为retract消息;而update更新操作则编码为被更改行的retract消息,和更新后行(新行)的add消息。这样,我们可以通过编码后的消息指明所有的增删改操作,一个动态表就可以转换为撤回流了。
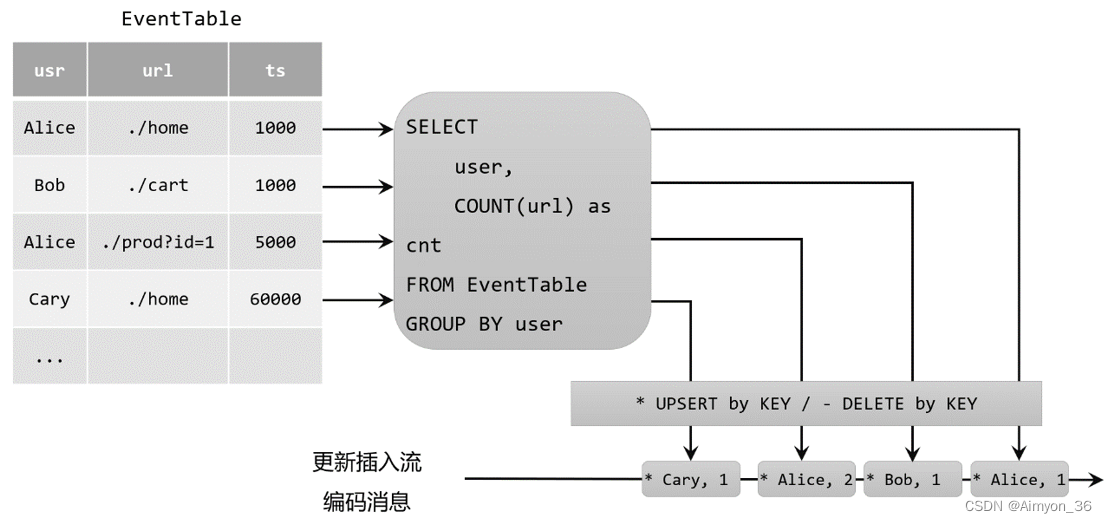
更新插入(upsert)流
更新插入流中只包含两种类型的消息:更新插入(upsert)消息和删除(delete)消息。
所谓的“upsert”其实是“update”和“insert”的合成词,所以对于更新插入流来说,insert插入操作和update更新操作,统一被编码为upsert消息;而delete删除操作则被编码为delete消息。
需要注意的是,在代码里将动态表转换为datastream时,只支持仅追加(append-only)和撤回(retract)流,我们调用tochangelogstream()得到的其实就是撤回流。而连接到外部系统时,则可以支持不同的编码方法,这取决于外部系统本身的特性。
二、时间属性
基于时间的操作(比如时间窗口),需要定义相关的时间语义和时间数据来源的信息。在table api和sql中,会给表单独提供一个逻辑上的时间字段,专门用来在表处理程序中指示时间。
所以所谓的时间属性(time attributes),其实就是每个表模式结构(schema)的一部分。它可以在创建表的ddl里直接定义为一个字段,也可以在datastream转换成表时定义。一旦定义了时间属性,它就可以作为一个普通字段引用,并且可以在基于时间的操作中使用。
按照时间语义的不同,可以把时间属性的定义分成事件时间(event time)和处理时间(processing time)两种情况。
1.事件时间
事件时间属性可以在创建表ddl中定义,增加一个字段,通过watermark语句来定义事件时间属性。具体定义方式如下:
create table eventtable(
user string,
url string,
ts timestamp(3), //timestamp(3)精确到毫秒级
watermark for ts as ts - interval '5' second
) with (
...
);
这里我们把ts字段定义为事件时间属性,而且基于ts设置了5秒的水位线延迟。
时间戳类型必须是 timestamp 或者timestamp_ltz 类型。但是时间戳一般都是秒或者是毫秒(bigint 类型),这种情况可以通过如下方式转换
ts bigint,
time_ltz as to_timestamp_ltz(ts, 3)
2.处理时间
在定义处理时间属性时,必须要额外声明一个字段,专门用来保存当前的处理时间。
在创建表的ddl(create table语句)中,可以增加一个额外的字段,通过调用系统内置的proctime()函数来指定当前的处理时间属性。
create table eventtable(
user string,
url string,
ts as proctime()
) with (
...
);

发表评论