hdfs(the hadoop distributed file system) 是最初由yahoo提出的分布式文件系统,它主要用来:
1)存储大数据
2)为应用提供大数据高速读取的能力
重点是掌握hdfs的文件读写流程,体会这种机制对整个分布式系统性能提升带来的好处。
hdfs工作流程与机制
⚫ hdfs集群角色与职责
⚫ hdfs写数据流程(上传文件)
⚫ hdfs读数据流程(下载文件)
官方架构图
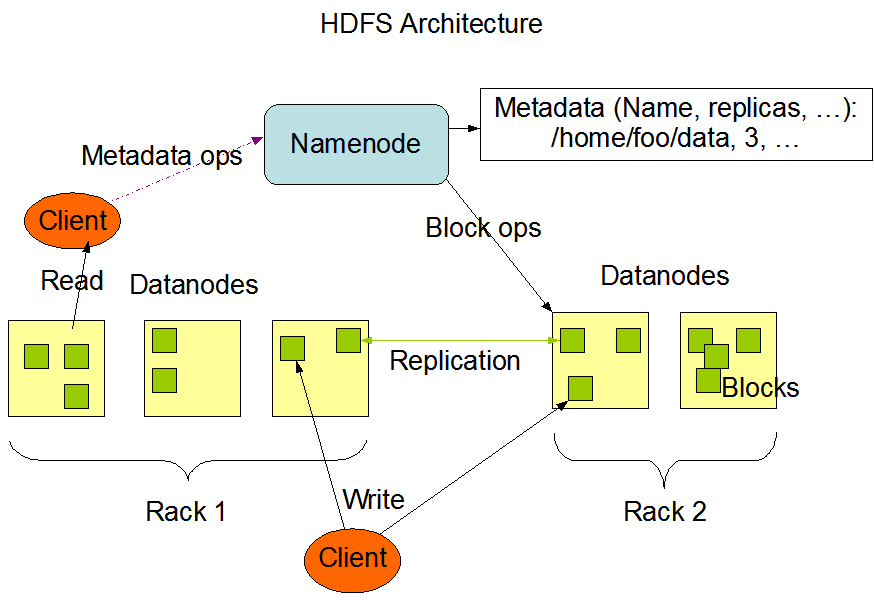
主角色:namenode
⚫ namenode是hadoop分布式文件系统的核心,架构中的主角色。
⚫ namenode维护和管理文件系统元数据,包括名称空间目录树结构、文件和块的位置信息、访问权限等信息。
⚫ 基于此,namenode成为了访问hdfs的唯一入口。
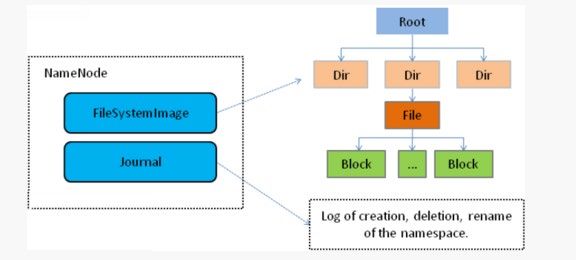
namenode内部通过内存和磁盘文件两种方式管理元数据。
⚫ 其中磁盘上的元数据文件包括fsimage内存元数据镜像文件和edits log(journal)编辑日志。
从角色:datanode
⚫ datanode是hadoop hdfs中的从角色,负责具体的数据块存储。
⚫ datanode的数量决定了hdfs集群的整体数据存储能力。通过和namenode配合维护着数据块。
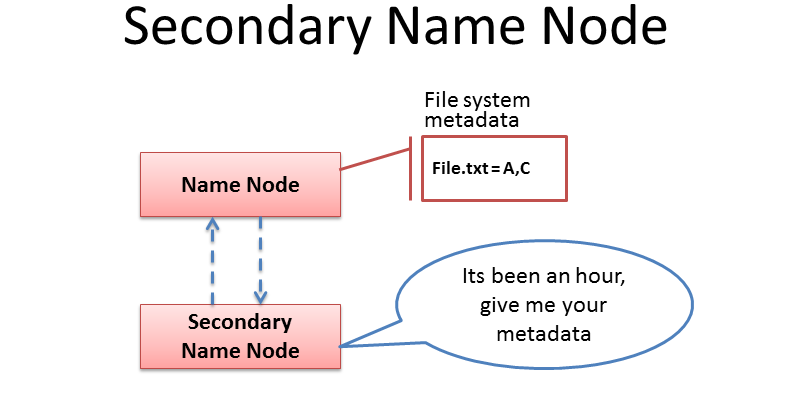
主角色辅助角色: secondarynamenode
⚫ secondary namenode充当namenode的辅助节点,但不能替代namenode。
⚫ 主要是帮助主角色进行元数据文件的合并动作。可以通俗的理解为主角色的“秘书”。
namenode职责
⚫ namenode仅存储hdfs的元数据:文件系统中所有文件的目录树,并跟踪整个集群中的文件,不存储实际数据。
⚫ namenode知道hdfs中任何给定文件的块列表及其位置。使用此信息namenode知道如何从块中构建文件。
⚫ namenode不持久化存储每个文件中各个块所在的datanode的位置信息,这些信息会在系统启动时从datanode 重建。
⚫ namenode是hadoop集群中的单点故障。
⚫ namenode所在机器通常会配置有大量内存(ram)。
datanode职责
⚫ datanode负责最终数据块block的存储。是集群的从角色,也称为slave。
⚫ datanode启动时,会将自己注册到namenode并汇报自己负责持有的块列表。
⚫ 当某个datanode关闭时,不会影响数据的可用性。 namenode将安排由其他datanode管理的块进行副本复制 。
⚫ datanode所在机器通常配置有大量的硬盘空间,因为实际数据存储在datanode中。
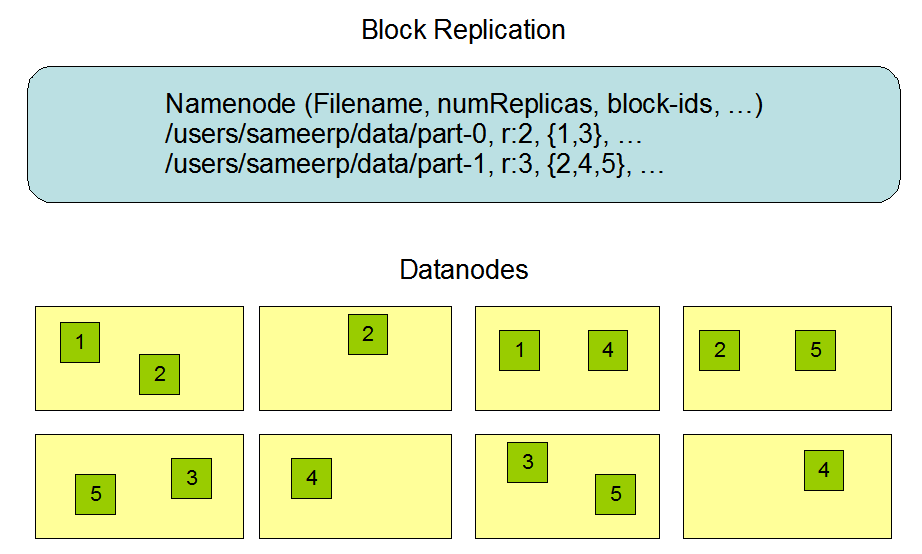
hdfs写数据流程(上传文件)
写数据完整流程图
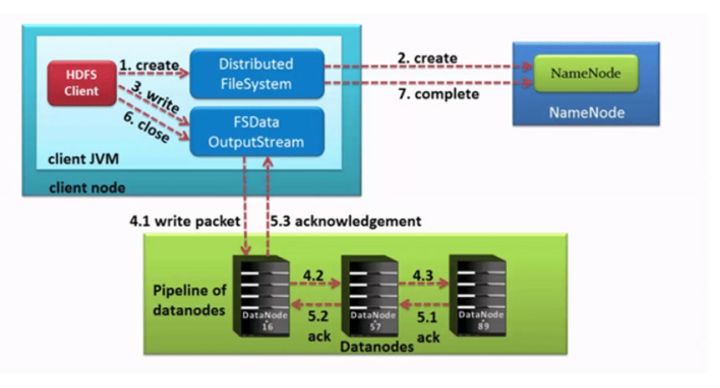
核心概念--pipeline管道
pipeline,中文翻译为管道。这是hdfs在上传文件写数据过程中采用的一种数据传输方式。
⚫ 客户端将数据块写入第一个数据节点,第一个数据节点保存数据之后再将块复制到第二个数据节点,后者保存后将其复制到第三个数据节点。
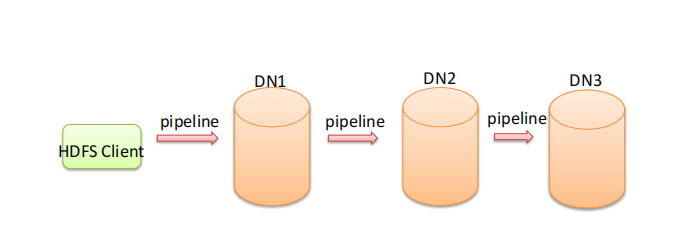
为什么datanode之间采用pipeline线性传输,而不是一次给三个datanode拓扑式传输呢?
⚫ 因为数据以管道的方式,顺序的沿着一个方向传输,这样能够充分利用每个机器的带宽,避免网络瓶颈和高延迟时 的连接,最小化推送所有数据的延时。
⚫ 在线性推送模式下,每台机器所有的出口宽带都用于以最快的速度传输数据,而不是在多个接受者之间分配宽带。
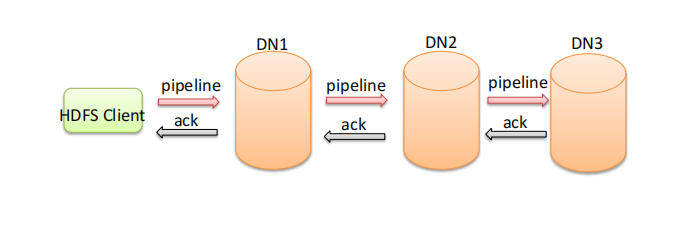
核心概念--ack应答响应
⚫ ack (acknowledge character)即是确认字符,在数据通信中,接收方发给发送方的一种传输类控制字符。表示发来的数据已确认接收无误。
⚫ 在hdfs pipeline管道传输数据的过程中,传输的反方向会进行ack校验,确保数据传输安全。
核心概念--默认3副本存储策略
⚫ 默认副本存储策略是由
blockplacementpolicydefault指定。
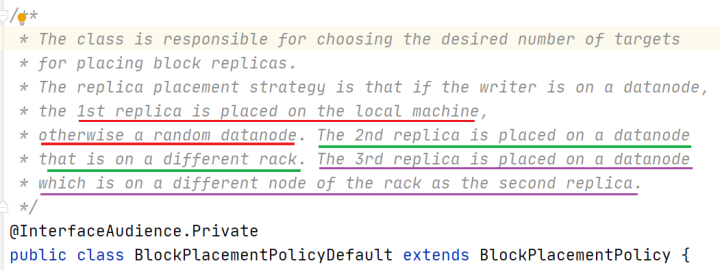
核心概念--默认3副本存储策略
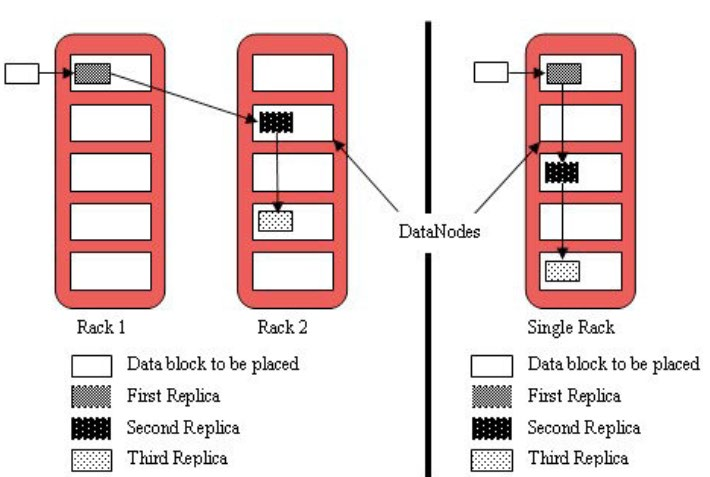
⚫ 第一块副本:优先客户端本地,否则随机
⚫ 第二块副本:不同于第一块副本的不同机架。
⚫ 第三块副本:第二块副本相同机架不同机器。
1、hdfs客户端创建对象实例distributedfilesystem, 该对象中封装了与hdfs文件系统操作的相关方法。
2、调用distributedfilesystem对象的create()方法,通过rpc请求namenode创建文件。
namenode执行各种检查判断:目标文件是否存在、父目录是否存在、客户端是否具有创建该文件的权限。检查通过 ,namenode就会为本次请求记下一条记录,返回fsdataoutputstream输出流对象给客户端用于写数据。

3、客户端通过fsdataoutputstream输出流开始写入数据。
4、客户端写入数据时,将数据分成一个个数据包(packet 默认64k), 内部组件datastreamer请求namenode挑选出适合存储数据副本的一组datanode地址,默认是3副本存储。
datastreamer将数据包流式传输到pipeline的第一个datanode,该datanode存储数据包并将它发送到pipeline的第二个datanode。同样,第二个datanode存储数据包并且发送给第三个(也是最后一个)datanode。
5、传输的反方向上,会通过ack机制校验数据包传输是否成功;
6、客户端完成数据写入后,在fsdataoutputstream输出流上调用close()方法关闭。
7、distributedfilesystem联系namenode告知其文件写入完成,等待namenode确认。
因为namenode已经知道文件由哪些块组成(datastream请求分配数据块),因此仅需等待最小复制块即可成功返回 。
最小复制是由参数
dfs.namenode.replication.min指定,默认是1.
hdfs读数据流程(下载文件)
读数据完整流程图
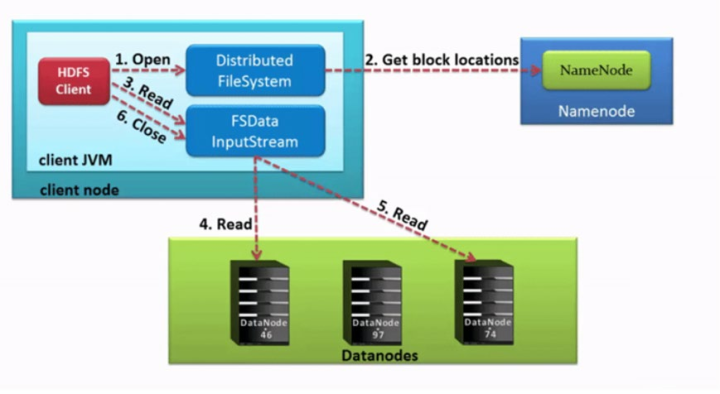
1、hdfs客户端创建对象实例distributedfilesystem, 调用该对象的open()方法来打开希望读取的文件。
2、distributedfilesystem使用rpc调用namenode来确定文件中前几个块的块位置(分批次读取)信息。
对于每个块,namenode返回具有该块所有副本的datanode位置地址列表,并且该地址列表是排序好的,与客户端的网络拓扑距离近的排序靠前。
3、distributedfilesystem将fsdatainputstream输入流返回到客户端以供其读取数据。
4、客户端在fsdatainputstream输入流上调用read()方法。然后,已存储datanode地址的inputstream连接到文件中第一个块的最近的datanode。数据从datanode流回客户端,结果客户端可以在流上重复调用read()
5、当该块结束时,fsdatainputstream将关闭与datanode的连接,然后寻找下一个block块的最佳datanode位置。
这些操作对用户来说是透明的。所以用户感觉起来它一直在读取一个连续的流。
客户端从流中读取数据时,也会根据需要询问namenode来检索下一批数据块的datanode位置信息。
6、一旦客户端完成读取,就对fsdatainputstream调用close()方法。
大数据基础:
开发入门linux入门→mysql数据库
核心基础hadoop
数仓技术hive数仓项目
pb内存计算python入门→python进阶→pyspark框架→hive+spark项目
python+大数据开发
linux入门:
新版linux零基础快速入门到精通,全涵盖linux系统知识、常用软件环境部署、shell脚本、云平台实践、大数据集群项目实战等
mysql数据库:mysql知识精讲+mysql实战案例_零基础mysql数据库入门到高级全套教程
hadoop入门:大数据hadoop入门视频教程,适合零基础自学的大数据hadoop教程
hive数仓项目:大数据项目实战教程_大数据企业级离线数据仓库,在线教育项目实战(hive数仓项目完整流程)
pb内存计算
python入门:python教程,8天python从入门到精通,学python看这套就够了
python编程进阶:python高级语法进阶教程_python多任务及网络编程,从零搭建网站全套教程
spark3.2从基础到精通:spark全套视频教程,4天spark3.2快速入门到精通,基于python语言的spark教程
hive+spark离线数仓工业项目实战:全网首次披露大数据spark离线数仓工业项目实战,hive+spark构建企业级大数据平台
注意事项:大数据学习要业务驱动,不要技术驱动:数据科学的核心能力是解决问题。
大数据的核心目标是数据驱动的智能化,要解决具体的问题,不管是科学研究问题,还是商业决策问题,抑或是政府管理问题。
所以学习之前要明确问题,理解问题,所谓问题导向、目标导向,这个明确之后再研究和选择合适的技术加以应用,这样才有针对性,言必hadoop,spark的大数据分析是不严谨的。


发表评论