【数据结构】初识数据结构之复杂度与链表

🔥个人主页:大白的编程日记
🔥专栏:c语言学习之路
文章目录
前言
一.数据结构和算法
1.1数据结构
1.2算法
1.3数据结构和算法的重要性
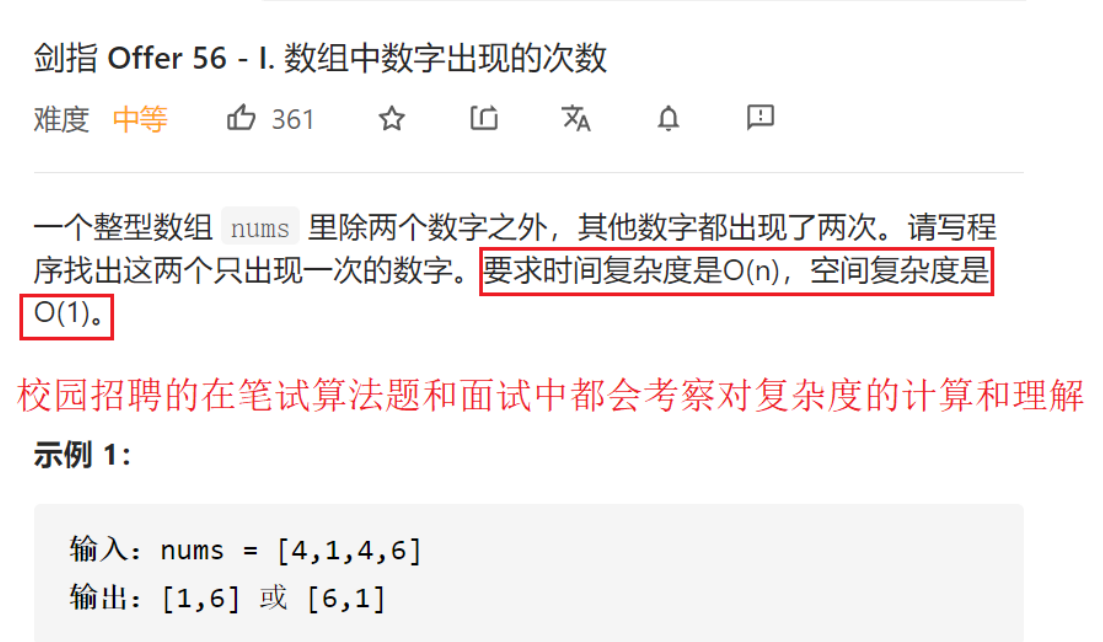
二.时间与空间复杂度
2.1算法效率
long long fib(int n)
{
if(n < 3)
return 1;
return fib(n-1) + fib(n-2);
}
2.2算法的复杂度
-
时间复杂度
时间复杂度主要衡量一个算法的运行快慢 -
空间复杂度
空间复杂度主要衡量一个算法运行所需要的额外空间。
在计算机发展的早期,计算机的存储容量很小。所以对空间复杂度很是在乎。但是经过计算机行业的迅速发展,计算机的存储容量已经达到了很高的程度。所以我们如今已经不需要再特别关注一个算法的空间复杂度。所以我们现在更关注算法的时间复杂度。
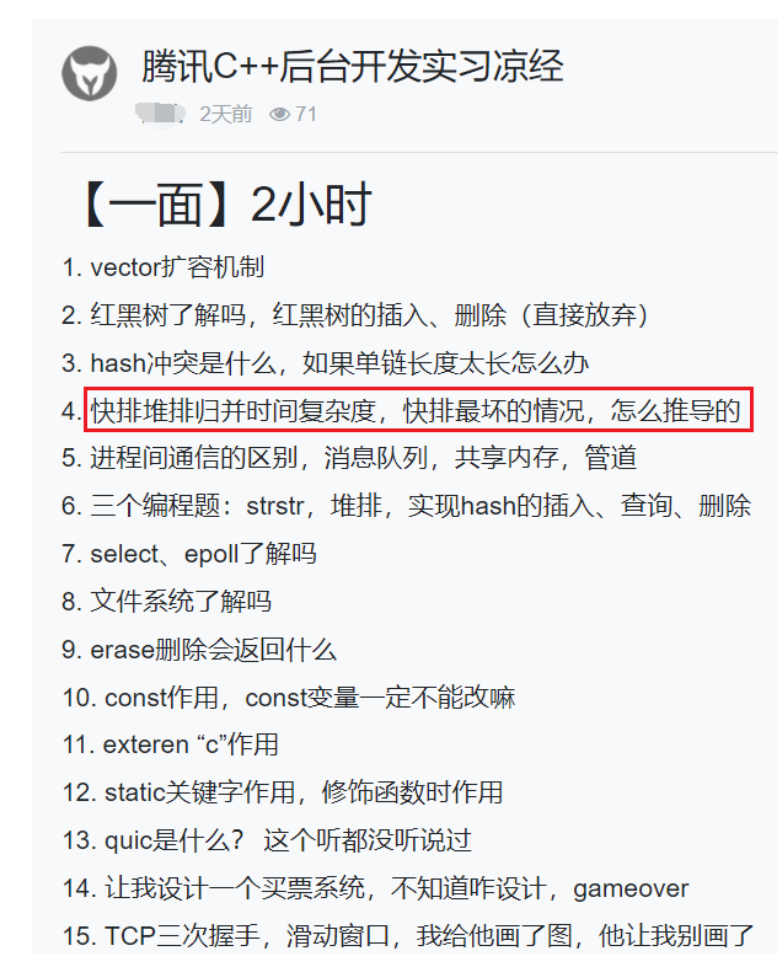
- 复杂度在校招中的考察
2.3时间复杂度的概念
- 运行时间衡量
为啥不用运行时间衡量。因为算法运行的环境不同,跑出来的时间性能自然不同。我的电脑性能更好,相同因素下,表现的性能自然更好,但是我们衡量的是代码本身。
即:找到某条基本语句与问题规模n之间的数学表达式,就是算出了该算法的时间复杂度。
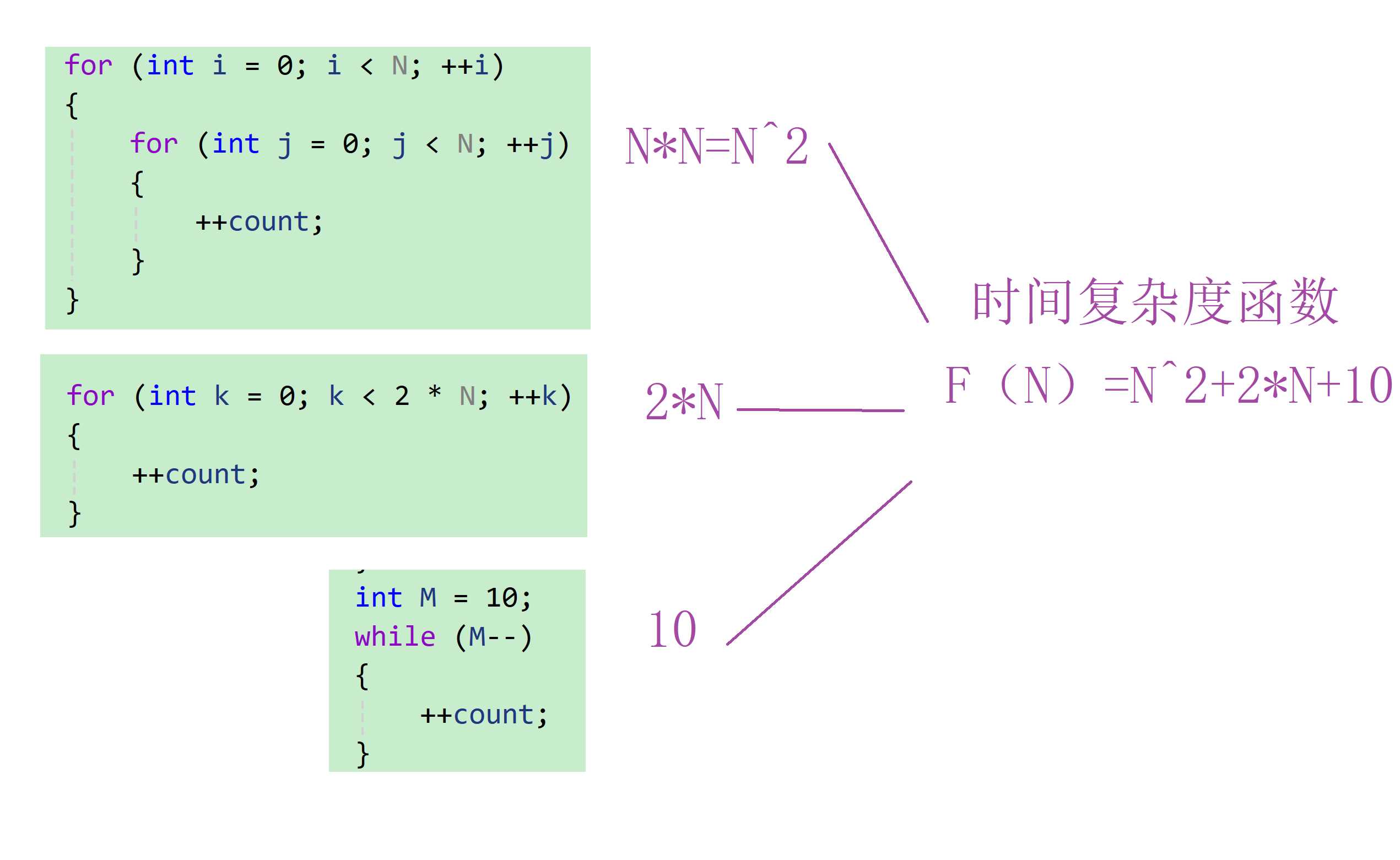
// 请计算一下func1中++count语句总共执行了多少次?
void func1(int n)
{
int count = 0;
for (int i = 0; i < n ; ++ i)
{
for (int j = 0; j < n ; ++ j)
{
++count;
}
}
for (int k = 0; k < 2 * n ; ++ k)
{
++count;
}
int m = 10;
while (m--)
{
++count;
}
我们计算出来的函数就是:

那如果现在我们要比较这三个算法的优略,该怎么比呢?
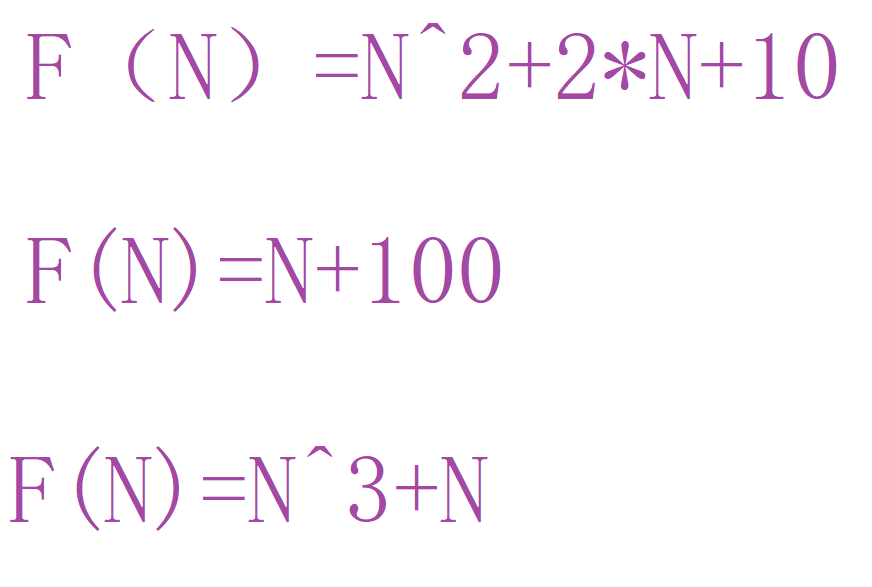
2.4大o的渐进表示法
推导大o阶方法:
- 用常数1取代运行时间中的所有加法常数。
我们想对函数进行大概的估算,那我们就需要保留影响最大的项,所以我们对常数项进行忽略。因为当n很大时,常数项对整个函数式结果的影响不大。
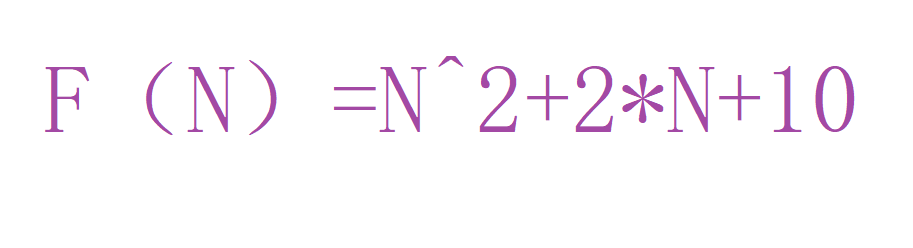
可是当n很小时,常数项的影响反而时更大的。
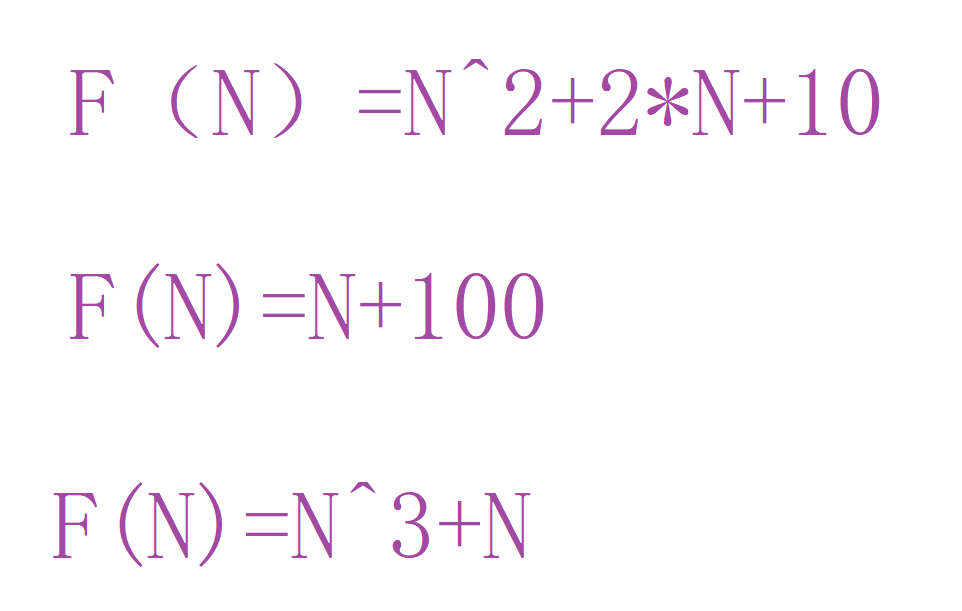
- 验证:
clock函数可以捕捉程序启动到某处执行的时间,单位时毫秒。
#include<stdio.h>
#include<time.h>
int main()
{
int sum = 0;
int begin = clock();//程序启动开始执行到这里的时间,单位时毫秒
for (int i = 0; i < 100000000; i++)
{
sum++;
}
int end = clock();
printf("%d time:%d", sum,end-begin);
}
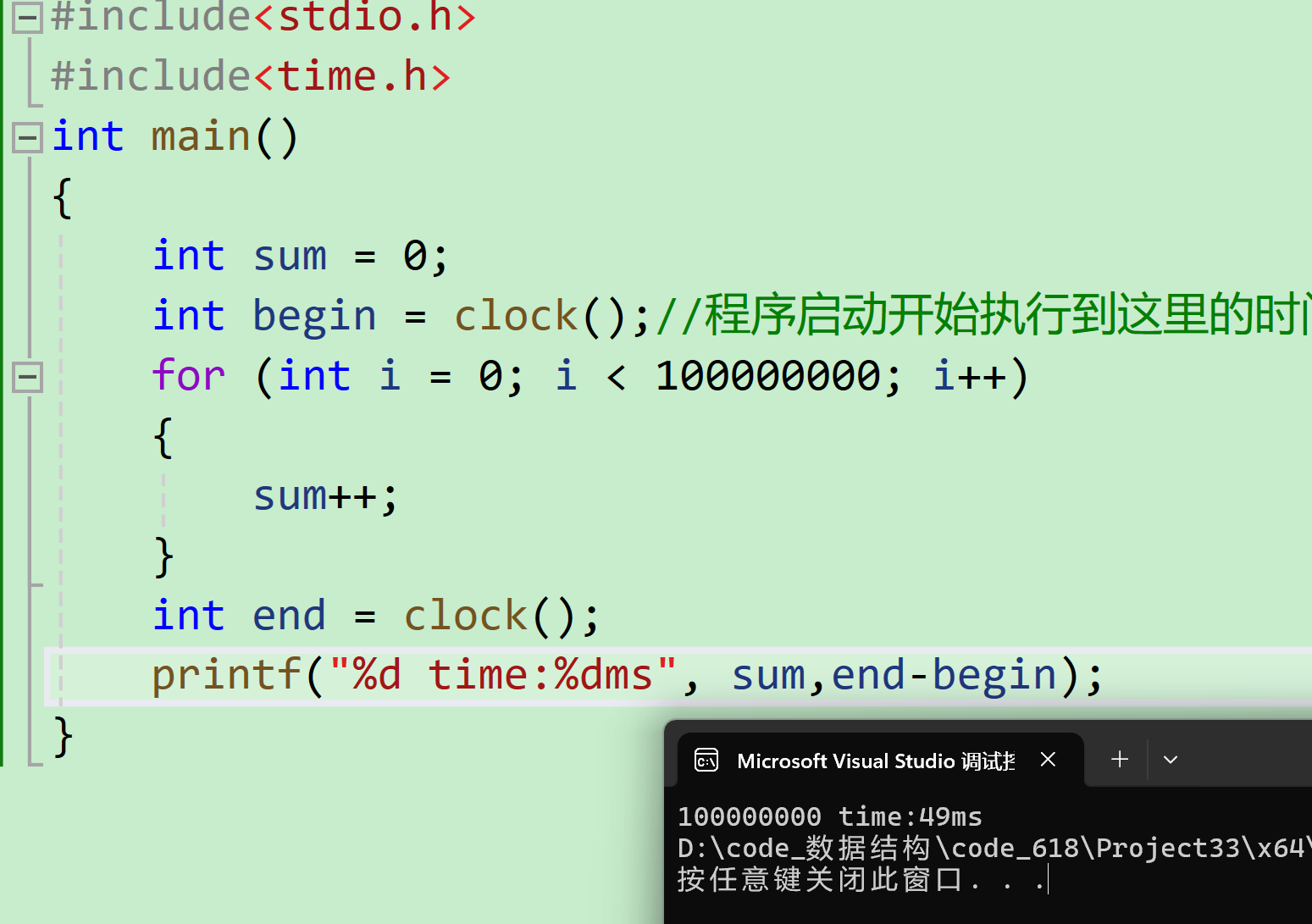
大家发现我们循环一亿次只用了40ms。
-
在修改后的运行次数函数中,只保留最高阶项。
忽略常数项后,我们只保留最高阶的项,也就是影响最大的项。 -
如果最高阶项存在且不是1,则去除与这个项目相乘的常数。得到的结果就是大o阶。
因为当n趋向于无穷大的时候,系数可以忽略。我们只关注n很大的情况,n很小的时候没有意义,因为cup运算速度太快了。可以理解为无穷的倍数还是无穷大。
- 在一个长度为n数组中搜索一个数据x
最好情况:1次找到
最坏情况:n次找到
平均情况:n/2次找到
2.5时间复杂度计算举例
- 题目一
// 计算func3的时间复杂度?
void func3(int n, int m)
{
int count = 0;
for (int k = 0; k < m; ++ k)
{
++count;
}
for (int k = 0; k < n ; ++ k)
{
++count;
}
printf("%d\n", count);
}
这里我们看两个循环分别是n和m次,所以用大o的渐进表示法就是o(n+m).如果一个远远小于另外一个未知数,可以忽略掉。
- 题目二:
// 计算func4的时间复杂度?
void func4(int n)
{
int count = 0;
for (int k = 0; k < 100; ++ k)
{
++count;
}
printf("%d\n", count);
}
基本操作执行了10次,通过推导大o阶方法,时间复杂度为 o(1)。注意o(1)不是代表一次,代表常数次。
- 题目三:
// 计算bubblesort的时间复杂度?
void bubblesort(int* a, int n)
{
assert(a);
for (size_t end = n; end > 0; --end)
{
int exchange = 0;
for (size_t i = 1; i < end; ++i)
{
if (a[i-1] > a[i])
{
swap(&a[i-1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
break;
}
}
这里我们要分最好情况和最坏情况看:

最好遍历一遍,最坏遍历n-1遍。而我们只关注最坏情况,所以就是(n-1)*n/2。再用大o的渐进表示法即可。
- 题目四:
// 计算binarysearch的时间复杂度?
int binarysearch(int* a, int n, int x)
{
assert(a);
int begin = 0;
int end = n - 1;
// [begin, end]:begin和end是左闭右闭区间,因此有=号
while (begin <= end)
{
int mid = begin + ((end - begin) >> 1);
if (a[mid] < x)
begin = mid + 1;
else if (a[mid] > x)
end = mid - 1;
else
return mid;
}
return -1;
}

三.空间复杂度
空间复杂度练习:
- 题目一:
// 计算bubblesort的空间复杂度?
void bubblesort(int* a, int n)
{
assert(a);
for (size_t end = n; end > 0; --end)
{
int exchange = 0;
for (size_t i = 1; i < end; ++i)
{
if (a[i - 1] > a[i])
{
swap(&a[i - 1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
break;
}
}

使用了常数个额外空间,所以空间复杂度为 o(1)
- 题目二:
// 计算fibonacci的空间复杂度?
// 返回斐波那契数列的前n项
long long* fibonacci(size_t n)
{
if (n == 0)
return null;
long long* fibarray = (long long*)malloc((n + 1) * sizeof(long long));
fibarray[0] = 0;
fibarray[1] = 1;
for (int i = 2; i <= n; ++i)
{
fibarray[i] = fibarray[i - 1] + fibarray[i - 2];
}
return fibarray;
}
动态开辟了n个空间,空间复杂度为 o(n)
- 题目三:
// 计算阶乘递归fac的空间复杂度?
long long fac(size_t n)
{
if(n == 0)
return 1;
return fac(n-1)*n;
}
递归调用了n次,开辟了n个栈帧,每个栈帧使用了常数个空间。空间复杂度为o(n)
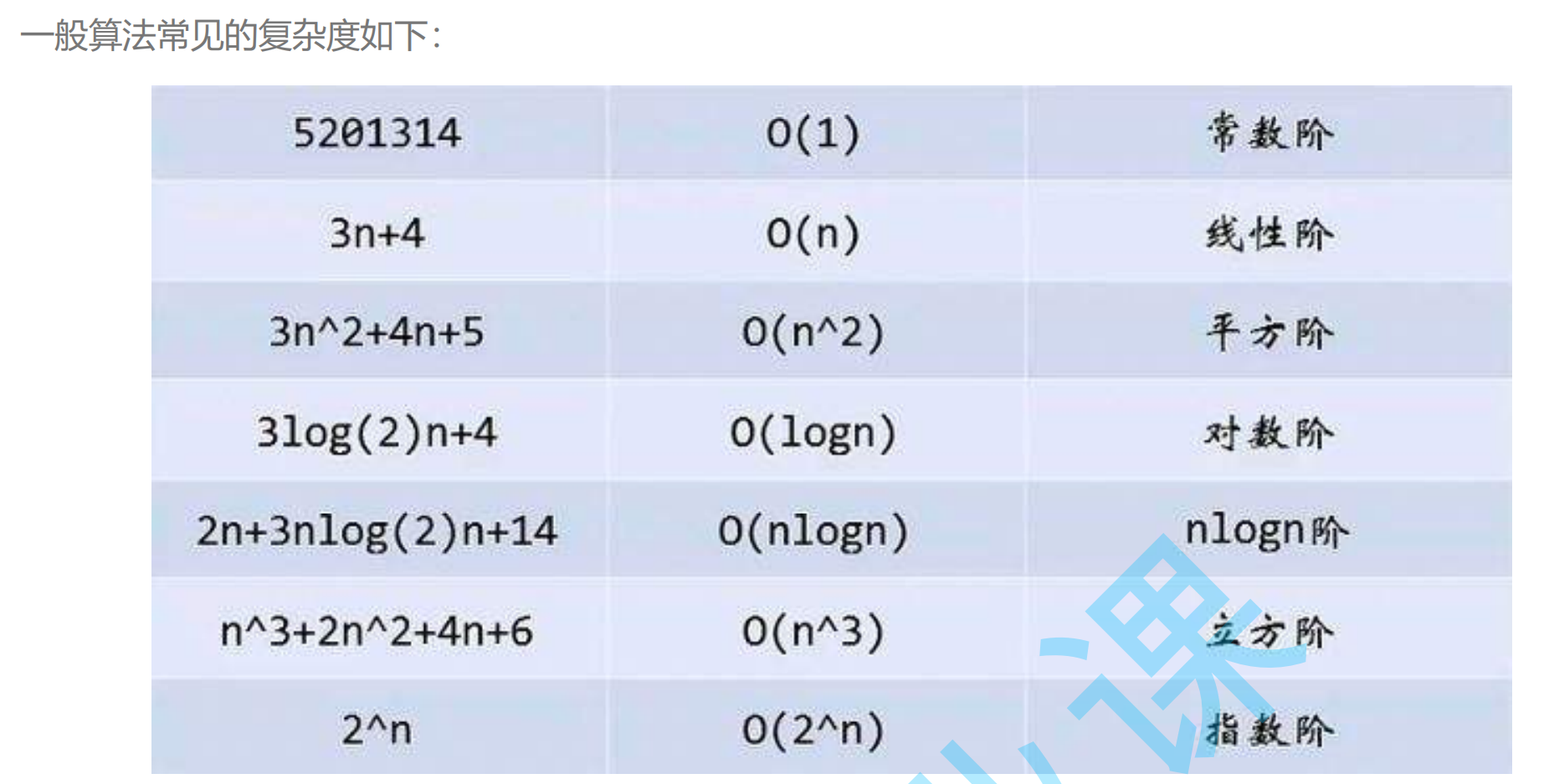
常见复杂度对比:
四.链表
4.1链表的概念及结构
在链表里,每节“车厢”是什么样的呢?
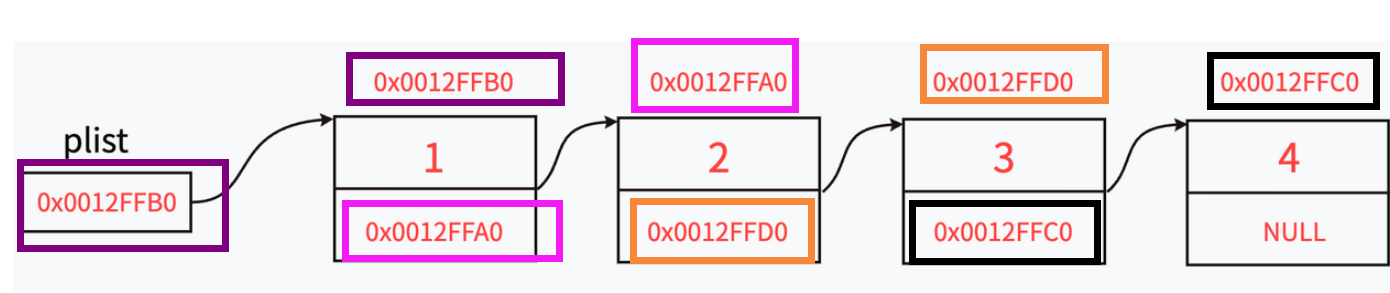
- 为什么还需要指针变量来保存下⼀个节点的位置?
链表中每个节点都是独立申请的(即需要插入数据时才去申请⼀块节点的空间),我们需要通过指针变量来保存下⼀个节点位置才能从当前节点找到下⼀个节点。
结合前面学到的结构体知识,我们可以给出每个节点对应的结构体代码:
struct slistnode
{
int data; //节点数据假设当前保存的节点为整型:
struct slistnode* next; //指针变量⽤保存下⼀个节点的地址
};
当我们想要从第⼀个节点⾛到最后⼀个节点时,只需要在前⼀个节点拿上下⼀个节点的地址(下⼀个节点的钥匙)就可以了。这就是链表的遍历。
- 链表在逻辑上是连续的,在物理结构上不⼀定连续
- 节点⼀般是从堆上申请的,动态开辟的。
- 从堆上申请来的空间,是按照⼀定策略分配出来的,每次申请的空间可能连续,可能不连续
- 哨兵位节点
哨兵位时一个链表的节点,但是这个链表什么也不用做,相当于一个放哨的,可以方便我们头插。
4.2链表的分类
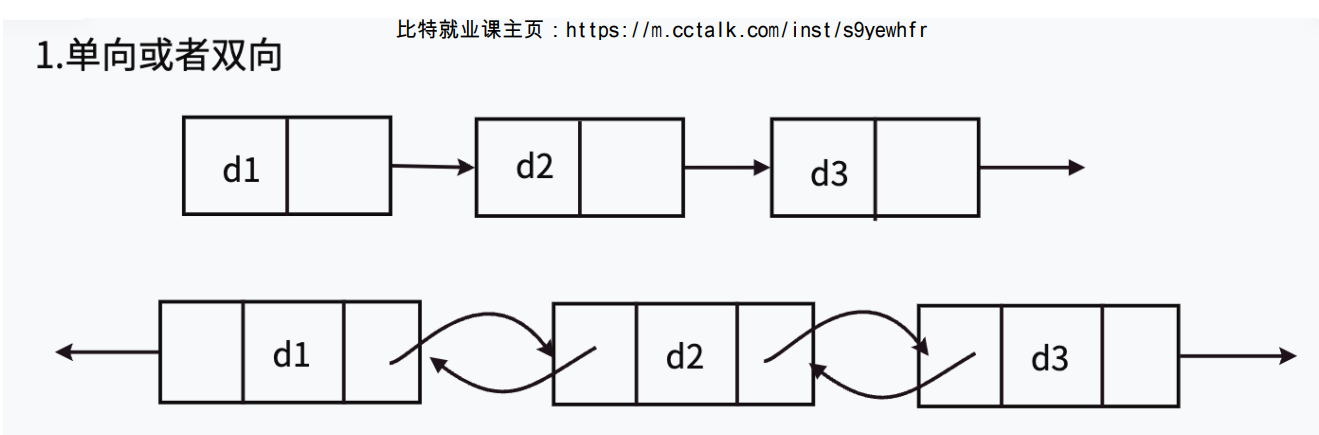
链表的结构非常多样,以下情况组合起来就有8种(2 x 2 x 2)链表结构:

- 单向或双向
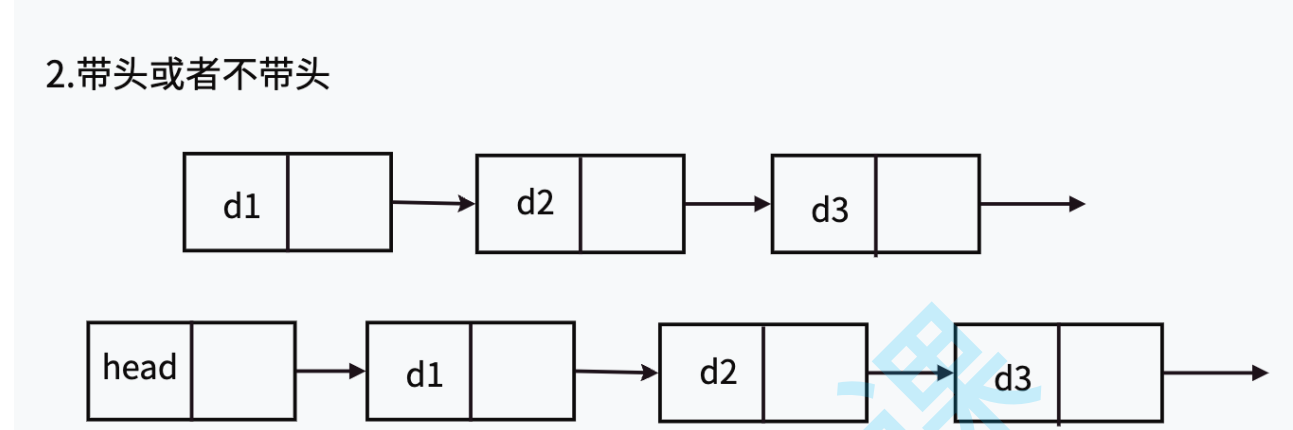
- 带头或不带头
- 循环不循环
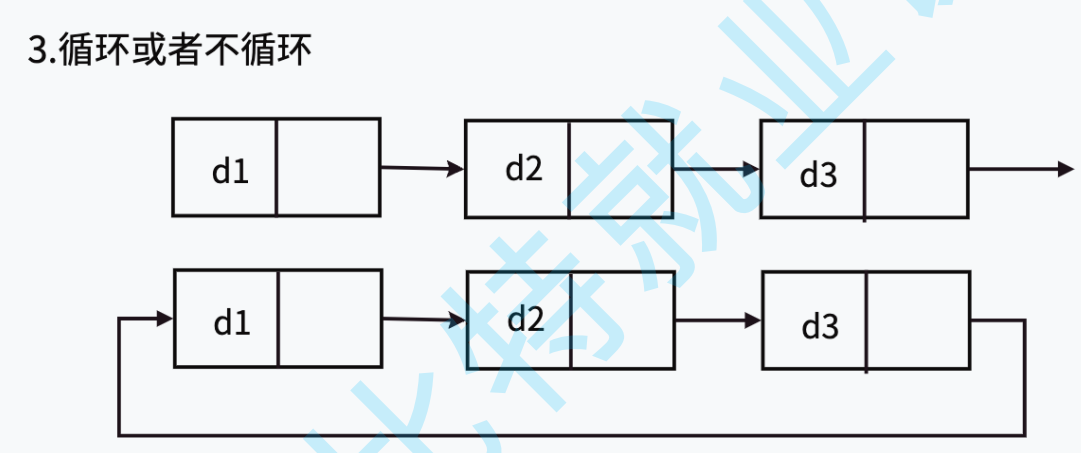
虽然有这么多的链表的结构,但是我们实际中最常⽤还是两种结构:
单链表和双向带头循环链表
4.3单链表的实现
- 定义链表节点
定义链表节点,同时重命名节点结构体和数据类型。
typedef int sldatatype;
typedef struct slistnode
{
int sldatatype;
struct slistnode* next;
}sltnode;
- 链表节点开辟
我们malloc开辟一个节点,然后判空。
sltnode* sltbuynode(sldatatype x)
{
sltnode* newnode = (sltnode*)malloc(sizeof(sltnode));//创建新节点
if (newnode)//判断是否为空
{
newnode->next = null;//置空
newnode->sldatatype = x;//赋值
return newnode;
}
else
{
perror("malloc fail!");//开辟空间失败
exit(1);
}
- 链表尾插
我们开辟一个节点后,对链表判空。
如果链表为空,则让新链表成为头节点。
否则遍历链表找到尾节点,然后让尾节点对接新节点。
void sltpushbak(sltnode** phead, sldatatype x)
{
assert(phead);//断言
sltnode* newnode = sltbuynode(x);//创建节点
if (*phead == null)//头节点为空
*phead = newnode;//新节点就是头节点
else//头节点不为空
{
sltnode* pcur = *phead;//保存头节点
while (pcur->next)//找尾
{
pcur = pcur->next;
}
pcur->next = newnode;//尾节点对接
}
}
- 链表头插
开辟新节点,让新节点指针指向头节点。修改新节点为头节点。
void sltpushprin(sltnode** phead, sldatatype x)
{
assert(phead);//断言
sltnode* newnode = sltbuynode(x);//开辟新结点
newnode->next = *phead;//指向头节点
*phead = newnode;//成为新结点
}
- 链表指定位置之后插入
开辟新节点,让新节点指向pos位置后的节点,
再让pos节点指向新节点。
void stlinserafter(sltnode* pos, sldatatype x)
{
assert(pos);//断言
sltnode* newnode = sltbuynode(x);//开辟新空间
newnode->next = pos->next;//新节点指向pos后的节点
pos->next = newnode;//pos节点指向新节点
}
- 链表尾删
断言检测链表时否为空。
如果只有一个节点,直接free删除后让头节点指向空
否则遍历链表找到倒数第二个节点,free删除尾节点,
再让倒数第二个节点指向空。
void stlpopback(sltnode** phead)
{
assert(phead && *phead);//断言,链表不能为空
sltnode* pcur = *phead;//复制头节点
if ((pcur)->next == null)//只有一个节点
{
free(pcur);
*phead= null;//删除节点
}
else
{
while (pcur->next->next)//找尾的前一个结点
{
pcur = pcur->next;
}
free(pcur->next);//删除尾节点
pcur->next = null;//置空
pcur = null;
}
}
- 链表头删
断言检测链表为空。
先保存当前头节点。
先让头节点的下一个节点成为头节点。
再free释放保存的头节点
void stlpopprin(sltnode** phead)
{
assert(phead&&*phead);//断言
sltnode** pcur = *phead;//复制头节点
*phead = (*phead)->next;//指向下一个节点
free(pcur);//删除头节点
pcur = null;//置空
}
- 链表指定位置删除
断言检测链表是否为空
如果pos位置时头节点,直接头删。
否则遍历找到pos的前节点,让pos前节点指向pos后节点,free删除pos节点
void stlerase(sltnode** phead, sltnode* pos)
{
assert(phead && *phead);//断言
assert(pos);
sltnode* pcur = *phead;//复制头节点
if (pcur== pos)//pos节点就是头节点
{
stlpopprin(phead);//头删
}
else
{
while (pcur->next != pos)//找pos前节点
{
pcur = pcur->next;
}
pcur->next = pos->next;//pos前节点指向pos后节点
free(pos);//删除pos节点
pos = null;//置空
}
}
- 链表指定位置之后删除
断言检测链表是否为空
保存pos后的节点,让pos节点指向pos的后后节点
free删除保存的pos后节点。
void stleraseafter(sltnode* pos)
{
assert(pos && pos->next);//断言
sltnode* pcur = pos->next;//保存pos后节点
pos->next = pcur->next;//pos指向pos后后节点
free(pcur);//删除pos后节点
pcur=null;
}
- 链表指定位置前插入
断言检测链表是否为空,开辟新结点
如果pos位置时头节点,直接头插
否则遍历找到pos前节点,让新节点指向pos节点
让pos前节点指向新节点。
void stlinser(sltnode** phead, sltnode* pos, sldatatype x)
{
assert(phead&&*phead);//断言
assert(pos);//断言
sltnode* newnode = sltbuynode(x);//开辟空间
sltnode* pcur = *phead;//复制头节点
if (pos == pcur)//头节点位前插
{
sltpushprin(phead, x);//头插
}
else
{
while (pcur->next != pos)//找pos前节点
{
pcur = pcur->next;//移动
}
newnode->next = pos;//新节点指向pos节点
pcur->next = newnode;//pos前节点指向新节点
}
}
- 链表的查找
遍历链表每次判断是否要查找的节点即可。
sltnode* stlfind(sltnode* phead, sldatatype x)
{
sltnode* pcur = phead;//复制头节点
while (pcur)//循环遍历
{
if (pcur->sldatatype == x)//判断是否为目标值
return pcur;//返回目标节点
pcur = pcur->next;//不是继续遍历
}
return null;
}
后言



发表评论