gpr tutorial
1. 高斯过程回归原理
高斯过程回归(gaussian process regression,gpr)是一个随机过程(按时间或空间索引的随机变量集合),这些随机变量的每个有限集合都服从多元正态分布,即它们的每个有限线性组合都是正态分布。高斯过程的分布是所有这些(无限多)随机变量的联合概率分布。
1.1 高斯过程
定义:一个高斯过程是一组随机变量的集合,这组随机变量的每个有限子集构成的联合概率分布都服从多元高斯分布,即:
f
∼
g
p
(
μ
,
k
)
(
1
−
1
)
f \sim gp(\mu,k) \qquad(1-1)
f∼gp(μ,k)(1−1)
其中
μ
(
x
)
\mu(x)
μ(x)和
k
(
x
,
x
′
)
k(x,x')
k(x,x′)分别为随机变量x的均值函数和协方差函数。因此可看出,一个高斯过程实际是由随机变量的均值和协方差函数所决定。
1.2 高斯过程回归
在传统回归模型中,定义
y
=
f
(
x
)
y=f(x)
y=f(x),而在高斯过程回归中,设f(x)服从高斯分布。通常假设均值为0,则:
y
=
f
(
x
)
∼
n
(
0
,
σ
)
(
1
−
2
)
y=f(x)\sim n(0,\sigma) \qquad(1-2)
y=f(x)∼n(0,σ)(1−2)
其中
σ
\sigma
σ是协方差函数。使用核技巧,令
σ
i
j
=
k
(
x
i
,
x
j
)
\sigma_{ij}=k(\mathbf{x}_i,\mathbf{x}_j)
σij=k(xi,xj),则可由求核函数k来计算协方差函数。如核函数k使用rbf核,则
σ
i
j
=
τ
e
−
∥
x
i
−
x
j
∥
2
σ
2
\sigma_{ij}=\tau e^\frac{-\|\mathbf{x}_i-\mathbf{x}_j\|^2}{\sigma^2}
σij=τeσ2−∥xi−xj∥2。如使用多项式核,则
σ
i
j
=
τ
(
1
+
x
i
⊤
x
j
)
d
\sigma_{ij}=\tau (1+\mathbf{x}_i^\top \mathbf{x}_j)^d
σij=τ(1+xi⊤xj)d。
因此,协方差函数
σ
\sigma
σ可分解为
(
k
,
k
∗
k
∗
⊤
,
k
∗
∗
)
\begin{pmatrix} k, k_* \\k_*^\top , k_{**} \end{pmatrix}
(k,k∗k∗⊤,k∗∗)。其中k是训练核矩阵,
k
∗
k_*
k∗是训练-测试核矩阵,
k
∗
t
k_*^t
k∗t是测试-训练核矩阵。
隐函数f的条件概率分布可表示为:
f
∗
∣
(
y
1
=
y
1
,
.
.
.
,
y
n
=
y
n
,
x
1
,
.
.
.
,
x
n
,
x
t
)
∼
n
(
k
∗
⊤
k
−
1
y
,
k
∗
∗
−
k
∗
⊤
k
−
1
k
∗
)
(
1
−
3
)
f_*|(y_1=y_1,...,y_n=y_n,\mathbf{x}_1,...,\mathbf{x}_n,\mathbf{x}_t)\sim \mathcal{n}(k_*^\top k^{-1}y,k_{**}-k_*^\top k^{-1}k_* ) \qquad(1-3)
f∗∣(y1=y1,...,yn=yn,x1,...,xn,xt)∼n(k∗⊤k−1y,k∗∗−k∗⊤k−1k∗)(1−3)
2. python实现高斯过程回归
2.1 参数详解
基于机器学习库sklearn实现高斯过程回归。sklearn中gaussianprocessregressor模块实现了高斯过程回归模型,从模型参数、属性和方法等方面介绍该模型,其主要参数包括:
| 参数名 | 参数含义 | 备注 |
|---|---|---|
| kernel | 核函数形式的高斯过程的协方差函数 | 常用核函数有:rbf、constantkernel;核函数的常见超参数有核的长度尺寸、长度尺寸的上下限 |
| alpha | 在模型拟合过程中加入核矩阵对角线位置的值 | (1)确保计算值形成正定矩阵,防止拟合过程中出现潜在的数值问题;(2)也可以解释为训练观测值上附加高斯测量噪声的方差;(3)如果alpha参数传递的是一个数组,它必须与用于拟合的数据具有相同的条目数,并用作依赖于数据点的噪声级 |
| random_state | 随机状态数 | 决定用于初始化中心的随机数的生成,在多次函数调用时,指定此参数保证可复现性 |
gaussianprocessregressor回归模型的主要属性包括:
| 属性名称 | 尺寸 |
|---|---|
| x_train_ | array-like of shape (n_samples, n_features) or list of object |
| y_train_ | array-like of shape (n_samples,) or (n_samples, n_targets) |
gaussianprocessregressor回归模型的常用方法包括:
| 方法名称 | 参数 | 返回值 |
|---|---|---|
| predict(x, return_std=false, return_cov=false) | x是高斯过程要拟合的样本点 | 用gpr模型进行预测,返回样本点预测概率分布的均值、标准差和预测联合概率分布的协方差 |
| score(x, y, sample_weight=none) | x是测试样本, y是x对应的真值 | 返回gpr模型预测的 r 2 r^2 r2系数, r 2 r^2 r2系数计算方法为 1 − ( ( ( y t r u e − y p r e d ) ∗ ∗ 2 ) . s u m ( ) ( y t r u e − y t r u e . m e a n ( ) ) ∗ ∗ 2 ) . s u m ( ) 1-\frac{(((y_{true} - y_{pred})** 2).sum()}{(y_{true} - y_{true}.mean()) ** 2).sum()} 1−(ytrue−ytrue.mean())∗∗2).sum()(((ytrue−ypred)∗∗2).sum() |
2.2 核函数cookbook
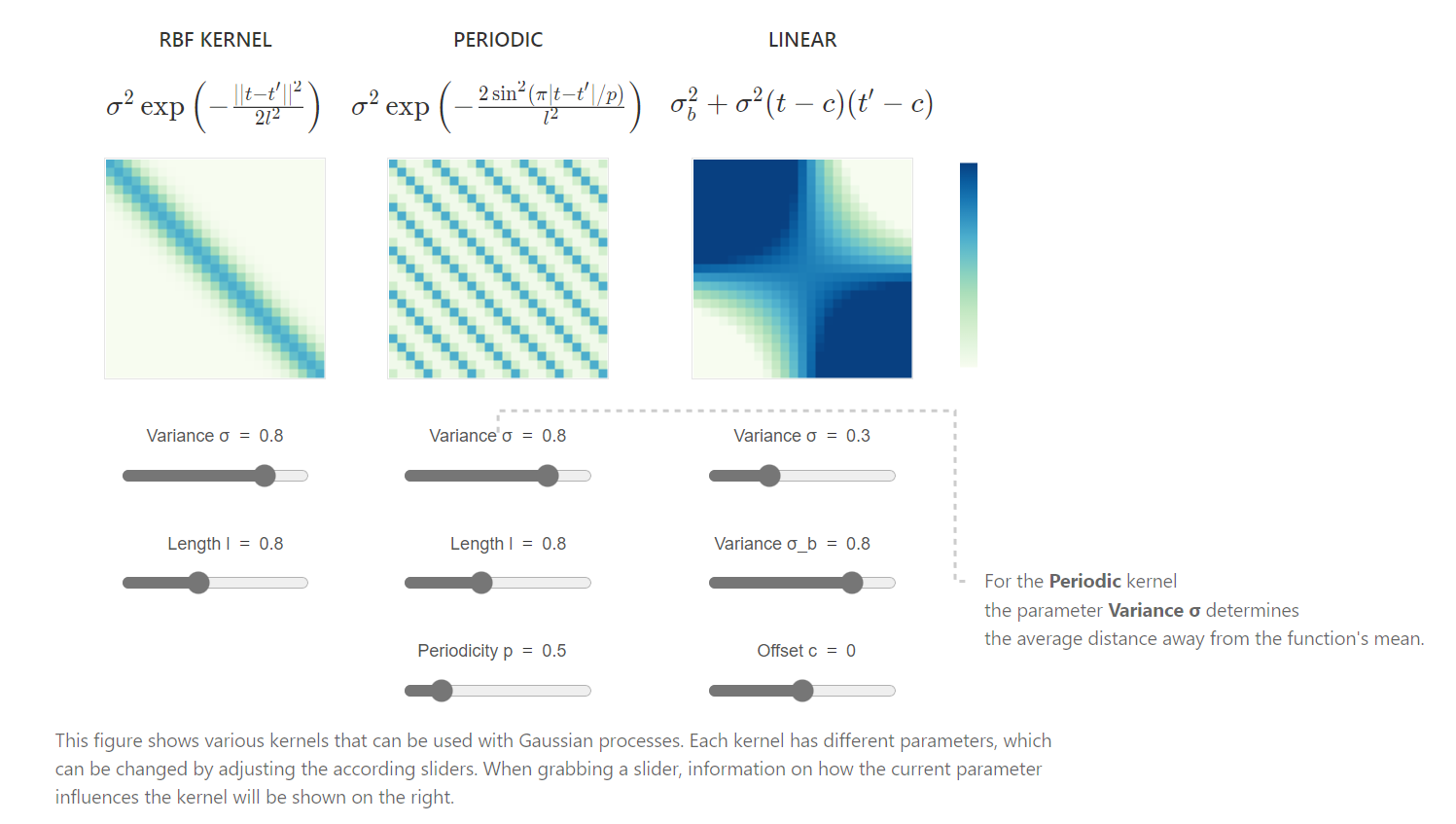
核函数在sklearn.gaussian_process.kernels模块中,常用的核函数有:
- rbf核函数(radial basis function kernel)
rbf核函数又被称为平方指数核,其计算方式为:
k ( x i , x j ) = exp ( − d ( x i , x j ) 2 2 l 2 ) ( 2 − 1 ) k(x_i,x_j)=\exp(-\frac{d(x_i,x_j)^2}{2l^2}) \qquad(2-1) k(xi,xj)=exp(−2l2d(xi,xj)2)(2−1)
式中 l l l是核函数的长度尺寸, d d d是距离度量函数,这里采用欧式距离度量。
在sklearn中rbf函数有两个参数:
rbf(length_scale=1.0, length_scale_bounds=(1e-05, 100000.0))
# length_scale:核函数的长度尺寸,float or ndarray of shape (n_features,), default=1.0
# length_scale_bounds:核函数长度尺寸的上下限,若设为'fixed',则无法在超参数调整期间修改核函数长度尺寸。
- 常数核(constantkernel)
常数核可以作为乘积核(product kernel)的一部分,用于缩放其他因子(核)的大小,也可以用作和核的一个部分,用于修改高斯过程的平均值。其数学形式表示为:
k ( x 1 , x 2 ) = c o n s t a n t , ∀ x 1 , x 2 ( 2 − 2 ) k(x_1,x_2)=constant, \forall x_1,x_2 \qquad(2-2) k(x1,x2)=constant,∀x1,x2(2−2)
同样,在skelearn中有constantkernel函数两个参数,含义与rbf的参数类似。
kernel = rbf() + constantkernel(constant_value=2,constant_value_bounds=(1e-5, 1e5))
# 作用等价于:kernel = rbf() + 2
2.2 代码模版
导入库:
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.gaussian_process import gaussianprocessregressor
from sklearn.gaussian_process.kernels import rbf, constantkernel as c, whitekernel
import sklearn.gaussian_process.kernels as k
训练gpr模型:
def gpr_regressor(x_train,y_train,x_test,y_test,kernel=c(constant_value=1) * rbf(length_scale=1, length_scale_bounds=(1e-2, 1e2))):
"""
gpr model for regression
:param x_train: (n_samples, n_features)
:param y_train: (n_samples,)
:param x_test: (n_samples, n_features)
:param y_test: (n_samples,)
:param kernel: kernel of gpr
:return:
y_pred: mean predictions
y_pred_std: std predictions
r2: r2 score of gpr
"""
gp = gaussianprocessregressor(kernel=kernel)
gp.fit(x_train, y_train) # instantiated gaussian regression model
print("the learned kernel parameters:\t {}".format(gp.kernel_)) # the learned kernel parameters
y_pred, y_pred_std = gp.predict(x_test, return_std=true)
r2 = gp.score(x_test, y_test)
print('r2 coefficient is {:.2f}'.format(r2))
return y_pred,y_pred_std,r2
预测结果可视化:
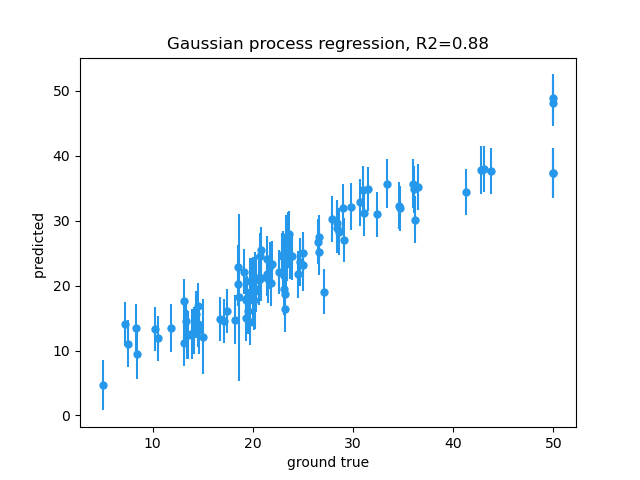
def plot_errorbar_gpr(y_pred,y_pred_std,r2,y_test):
"""
plot errorbar for gpr predictions
:param y_pred:
:param y_pred_std:
:param r2:
:param y_test: one-dimension
:return:
"""
plt.errorbar(x=y_test, y=y_pred, yerr=y_pred_std, fmt="o", label="samples", markersize=5,color='#2698eb')
#x, y define the data locations, xerr, yerr define the errorbar sizes
plt.xlabel("ground true")
plt.ylabel("predicted ")
plt.title("gaussian process regression, r2=%.2f" % (r2))
print("finished!")
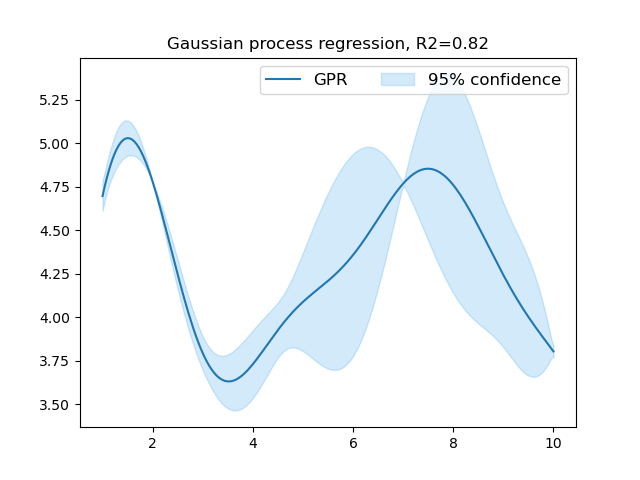
def plot_intervel_gpr(y_pred,y_pred_std,r2,x_test):
"""
plot confidence interval for gpr predictions
:param y_pred:
:param y_pred_std:
:param r2:
:param x_test: should be one-dimension shape
:return:
"""
# 1.96 sigma = 95% confidence interval for a normal distribution
upper, lower = y_pred + 1.96 * y_pred_std, y_pred - 1.96 * y_pred_std
plt.plot(x_test, y_pred, label="gpr", ls="-")
plt.fill_between(x_test, y1=upper, y2=lower, alpha=0.2, label="95% confidence", color="#2698eb")
plt.legend(ncol=4, fontsize=12)
plt.title("gaussian process regression, r2=%.2f" %(r2))
print("finished!")
预测概率区间图如下:
以标准差为尺度的误差线图如下:
附录-数学基础知识
这里列出了高斯过程回归涉及到的数学基础知识,方便大家参考。
a1 高斯分布的基本性质
高斯分布的四大属性:标准化(normalization)、边缘化(marginalization)、可加性(summation)、条件性(conditioning),具体数学表示如下图所示:
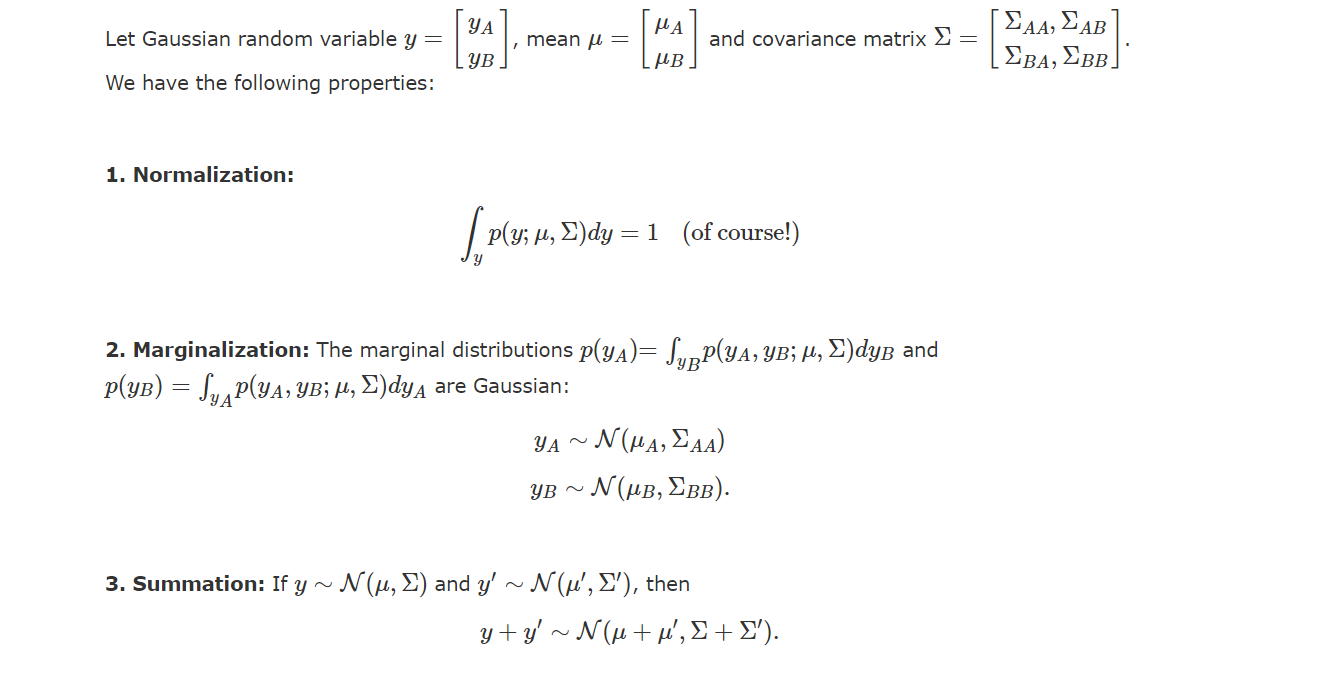

a2 贝叶斯框架
贝叶斯框架的基础概念包括条件概率、乘积法则、加和法则、贝叶斯定理等。
(1)条件概率
条
件
概
率
分
布
=
联
合
概
率
分
布
边
缘
概
率
分
布
(
a
−
1
)
条件概率分布=\frac{联合概率分布}{边缘概率分布} \qquad(a-1)
条件概率分布=边缘概率分布联合概率分布(a−1) i.e.
p
(
y
∣
x
)
=
p
(
x
,
y
)
p
(
x
)
p(y|x)=\frac{p(x,y)}{p(x)}
p(y∣x)=p(x)p(x,y).
(2)乘积法则(product rule)
任何联合概率分布,都可以表示为一维条件概率分布的乘积,i.e.
p
(
x
,
y
,
z
)
=
p
(
x
∣
y
,
z
)
p
(
y
∣
z
)
p
(
z
)
p(x,y,z)=p(x|y,z)p(y|z)p(z)
p(x,y,z)=p(x∣y,z)p(y∣z)p(z).
(3) 加和法则(sum rule)
任何边缘概率分布,都可以通过对联合概率分布的积分获得,i.e.
p
(
y
)
=
∫
p
(
x
,
y
)
d
x
p(y)=\int p(x,y)dx
p(y)=∫p(x,y)dx,
p
(
x
)
=
∫
p
(
x
,
y
)
d
y
p(x)=\int p(x,y)dy
p(x)=∫p(x,y)dy.
利用加和法则还可以估计条件概率分布,如已知一组随机变量
x
x
x,
y
y
y,
z
z
z构成的联合概率分布
p
(
x
,
y
,
z
)
p(x,y,z)
p(x,y,z),观测到
x
x
x,感兴趣预测
y
y
y,变量
z
z
z是未知的且与待解决的问题无关,如何只用联合概率分布
p
(
x
,
y
,
z
)
p(x,y,z)
p(x,y,z)去估计
p
(
y
∣
x
)
p(y|x)
p(y∣x)呢?
答案就是用加和法则对联合概率分布求积分:
p
(
y
∣
x
)
=
p
(
x
,
y
)
p
(
x
)
p(y|x)=\frac{p(x,y)}{p(x)}
p(y∣x)=p(x)p(x,y)=
∫
p
(
x
,
y
,
z
)
d
z
∫
p
(
x
,
y
,
z
)
d
z
d
y
\frac{\int p(x,y,z)dz}{\int p(x,y,z)dzdy}
∫p(x,y,z)dzdy∫p(x,y,z)dz
(4)贝叶斯定理(bayes theorem)
由乘积法则和加和法则可知,任何条件概率分布可由联合概率分布获得。进一步的,利用乘积法则和加和法则,可从条件概率的定义中推导出贝叶斯定理:
p
(
y
∣
x
)
=
p
(
x
,
y
)
p
(
x
)
=
p
(
x
∣
y
)
p
(
y
)
p
(
x
)
=
p
(
x
∣
y
)
p
(
y
)
∫
p
(
x
∣
y
)
p
(
y
)
d
y
(
a
−
2
)
p(y|x)=\frac{p(x,y)}{p(x)}=\frac{p(x|y)p(y)}{p(x)}=\frac{p(x|y)p(y)}{\int p(x|y)p(y)dy} \qquad(a-2)
p(y∣x)=p(x)p(x,y)=p(x)p(x∣y)p(y)=∫p(x∣y)p(y)dyp(x∣y)p(y)(a−2).
从式中可看出,贝叶斯定理定义了当新的信息出现时,不确定性的转化规则,即:
后
验
概
率
=
似
然
概
率
×
先
验
概
率
置
信
度
(
a
−
3
)
后验概率=\frac{似然概率\times 先验概率}{置信度} \qquad(a-3)
后验概率=置信度似然概率×先验概率(a−3)
(5)贝叶斯框架
统计推断方法有频率框架和贝叶斯框架两大流派,贝叶斯框架基于贝叶斯定理去估计后验概率。应用该框架进行推断的经典描述为,给定一组独立同分布的数据
x
=
(
x
1
,
x
2
,
.
.
.
,
x
n
)
x=(x_1,x_2,...,x_n)
x=(x1,x2,...,xn),欲用概率分布
p
(
x
∣
θ
)
p(x|\theta)
p(x∣θ)估计
θ
\theta
θ,贝叶斯框架提供了使用先验概率
p
(
θ
)
p(\theta)
p(θ)编码参数
θ
\theta
θ的不确定度的方法:
p
(
θ
∣
x
)
=
∏
i
=
1
n
p
(
x
i
∣
θ
)
p
(
θ
)
∫
∏
i
=
1
n
p
(
x
i
∣
θ
)
p
(
θ
)
d
θ
(
a
−
4
)
p(\theta|x)=\frac{\prod_{i=1}^np(x_i|\theta)p(\theta)}{\int \prod_{i=1}^np(x_i|\theta)p(\theta)d\theta} \qquad(a-4)
p(θ∣x)=∫∏i=1np(xi∣θ)p(θ)dθ∏i=1np(xi∣θ)p(θ)(a−4)
a3 后验预测分布
考虑一个回归问题:
y
=
f
(
x
)
+
ε
(
a
−
5
)
y=f(x)+\varepsilon \qquad(a-5)
y=f(x)+ε(a−5)
为从数据中求解概率,给定特定参数w,预测模型可利用后验预测分布(posterior predictive distribution)来求解。
对于数据集d和特征x,根据贝叶斯定理以及概率分布的加和、乘积法则,后验预测分布可表示为:
p
(
y
∣
d
,
x
)
=
∫
w
p
(
y
,
w
∣
d
,
x
)
d
w
p(y\mid d,x) = \int_{\mathbf{w}}p(y,\mathbf{w} \mid d,x) d\mathbf{w}
p(y∣d,x)=∫wp(y,w∣d,x)dw
=
∫
w
p
(
y
∣
w
,
d
,
x
)
p
(
w
∣
d
)
d
w
(
a
−
6
)
= \int_{\mathbf{w}} p(y \mid \mathbf{w}, d,x) p(\mathbf{w} \mid d) d\mathbf{w} \qquad(a-6)
=∫wp(y∣w,d,x)p(w∣d)dw(a−6)
然而上述公式的解析解(closed form)难以计算,但对于具有高斯似然和先验的特殊情况,我们可以求其高斯过程的均值和协方差,即:
p
(
y
∗
∣
d
,
x
)
∼
n
(
μ
y
∗
∣
d
,
σ
y
∗
∣
d
)
(
a
−
7
)
p(y_*\mid d,\mathbf{x}) \sim \mathcal{n}(\mu_{y_*\mid d}, \sigma_{y_*\mid d}) \qquad(a-7)
p(y∗∣d,x)∼n(μy∗∣d,σy∗∣d)(a−7)
其中均值函数
μ
y
∗
∣
d
\mu_{y_*\mid d}
μy∗∣d和协方差函数
σ
y
∗
∣
d
\sigma_{y_*\mid d}
σy∗∣d, 均可由核函数k计算得到:
μ
y
∗
∣
d
=
k
∗
t
(
k
+
σ
2
i
)
−
1
y
(
a
−
8
)
\mu_{y_*\mid d} = k_*^t (k+\sigma^2 i)^{-1} y \qquad(a-8)
μy∗∣d=k∗t(k+σ2i)−1y(a−8)
σ
y
∗
∣
d
=
k
∗
∗
−
k
∗
t
(
k
+
σ
2
i
)
−
1
k
∗
(
a
−
9
)
\sigma_{y_*\mid d} = k_{**} - k_*^t (k+\sigma^2 i)^{-1}k_* \qquad(a-9)
σy∗∣d=k∗∗−k∗t(k+σ2i)−1k∗(a−9)
参考资料
[1]cornell 高斯过程lecture
[2]https://cosmiccoding.com.au/tutorials/gaussian_processes
[3]sklearn gaussianprocessregressor文档
[4].高斯过程可视化展示网页
[5].http://gaussianprocess.org/gpml/chapters/rw.pdf
[6].https://towardsdatascience.com/getting-started-with-gaussian-process-regression-modeling-47e7982b534d

发表评论