-
deep crossing模型(微软,搜索引擎,广告推荐)
前置知识:推荐算法学习笔记1.3:传统推荐算法-逻辑回归算法,推荐算法学习笔记1.4:传统推荐算法-自动特征的交叉解决方案:fm→ffm
本文含残差块反向传播梯度推导 (最后附录)背景概述:用户搜索关键词 → 返回搜索结果以及相关广告。
导出问题:如何提高广告的点击率?
输入:混合类型(类别型,数值型)特征。
输出:点击概率。

细化问题:
①如何解决类别型特征进行one-hot或multi-hot编码后的稀疏问题?
②如何进行自动特征组合?
③如何将得到理想的输出?
解决方案:
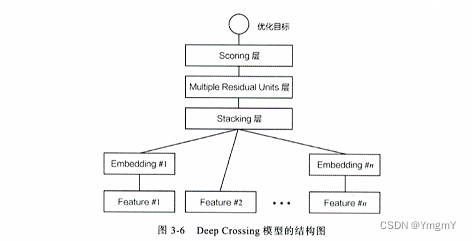
①对类别型特征进行嵌入表示(引入了embedding层)。
②通过stacking层将多个特征进行堆叠(concatenate),利用神经网络的非线性特征组合能力进行自动特征组合(multiple residual units层, 残差结构)。
③通过scoring层输出点击概率(分类层)。
附录:
附1:残差结构
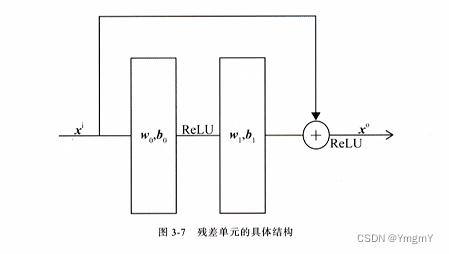
残差结构通过让模型拟合残差而不是映射从而减少网络过拟合的现象发生。即前向传播如下
h ( i + 1 ) = h ( i ) + σ i + 1 ( w i + 1 h ( i ) + b i + 1 ) \mathbf{h}^{(i+1)} = \mathbf{h}^{(i)}+\sigma^{i+1}(\mathbf{w}^{i+1}\mathbf{h}^{(i)}+b^{i+1}) h(i+1)=h(i)+σi+1(wi+1h(i)+bi+1)
其中假设 h ( i ) = σ i ( w i h ( i − 1 ) + b i ) \mathbf{h}^{(i)} = \sigma^{i}(\mathbf{w}^{i}\mathbf{h}^{(i-1)}+b^{i}) h(i)=σi(wih(i−1)+bi),则 w i \mathbf{w}^i wi的反向传播如下
∂ l o s s ∂ w i = ∂ l o s s ∂ h i + 1 ( ∂ h i ∂ w i + ∂ σ i + 1 ∂ ( w i + 1 h ( i ) + b i + 1 ) ( w i + 1 ) t ∂ h i ∂ w i ) = ∂ l o s s ∂ h i + 1 ∂ h i ∂ w i + ∂ l o s s ∂ h i + 1 ∂ σ i + 1 ∂ ( w i + 1 h ( i ) + b i + 1 ) ( w i + 1 ) t ∂ h i ∂ w i \frac{\partial loss}{\partial \mathbf{w}^i}= \frac{\partial loss}{\partial \mathbf{h}^{i+1}} (\frac{\partial \mathbf{h}^{i}}{\partial \mathbf{w}^i}+\frac{\partial \sigma^{i+1}}{\partial (\mathbf{w}^{i+1}\mathbf{h}^{(i)}+b^{i+1})}(\mathbf{w}^{i+1})^t\frac{\partial \mathbf{h}^{i}}{\partial \mathbf{w}^i}) \\ =\frac{\partial loss}{\partial \mathbf{h}^{i+1}} \frac{\partial \mathbf{h}^{i}}{\partial \mathbf{w}^i}+\frac{\partial loss}{\partial \mathbf{h}^{i+1}} \frac{\partial \sigma^{i+1}}{\partial (\mathbf{w}^{i+1}\mathbf{h}^{(i)}+b^{i+1})}(\mathbf{w}^{i+1})^t\frac{\partial \mathbf{h}^{i}}{\partial \mathbf{w}^i} ∂wi∂loss=∂hi+1∂loss(∂wi∂hi+∂(wi+1h(i)+bi+1)∂σi+1(wi+1)t∂wi∂hi)=∂hi+1∂loss∂wi∂hi+∂hi+1∂loss∂(wi+1h(i)+bi+1)∂σi+1(wi+1)t∂wi∂hi
从反向传播过程可以看出 w i \mathbf{w}^i wi的梯度中第一项不会引入后续的参数矩阵 w i + 1 \mathbf{w}^{i+1} wi+1,所以在一定程度避免了梯度消失的产生。
- 站内搜索



发表评论