目录
6、设置root密码,一定要设置,创建用户看个人需要,可以在之后创建
三、搭建hadoop(在此次配置中以hadoop3.3.6进行演示)
1、登录hadoop官网下载hadoop压缩包、登录java官网下载jdk压缩包(jdk1.8.0_381),tip.下载jdk1.8.0_381需要注册oracle账号
5、生效环境变量在每个虚拟机中,使环境变量文件生效(使用finalshell可以同时发送命令到全部会话)
最后,祝大家配置hadoop都能一发入魂,good luck!!
迭子生吃虾滑
hadoop搭建
准备:
软件:vmare workstation 17 pro
镜像:centos 7 下载:centos-7-isos-x86_64安装包下载_开源镜像站-阿里云 (aliyun.com)
一、在虚拟机软件安装linux
1、新建虚拟机:
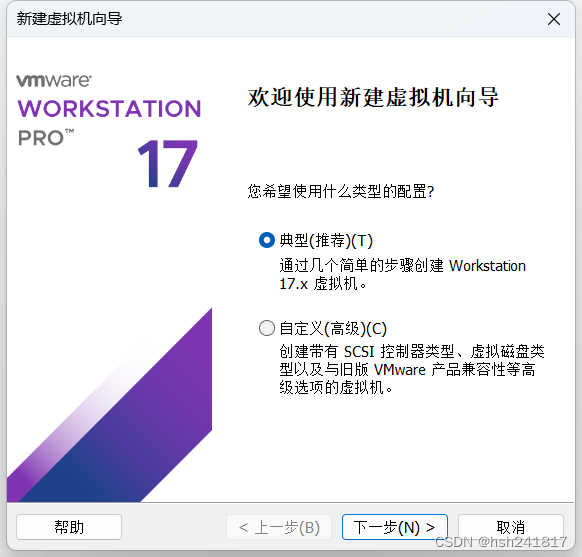
选择典型安装之后点击下一步
2、选择安装源:
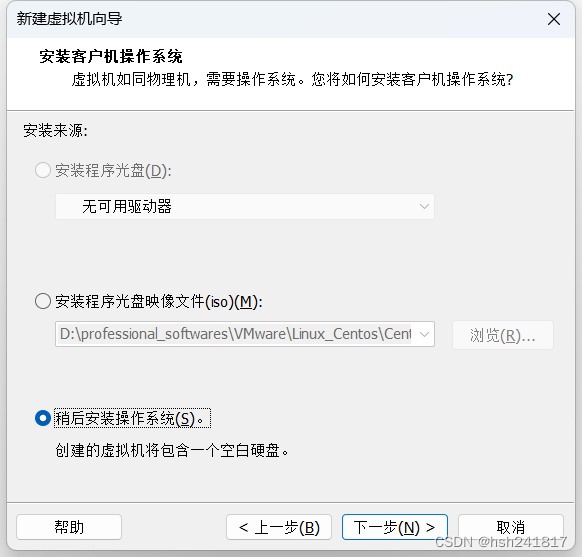
以防万一,首先先点击安装程序光盘映像文件设置好centos的镜像路径,最好将centos的镜像选择放在在d盘的某个合适的位置,再点击稍后安装操作系统,点击下一步
3、选择客户机操作系统:
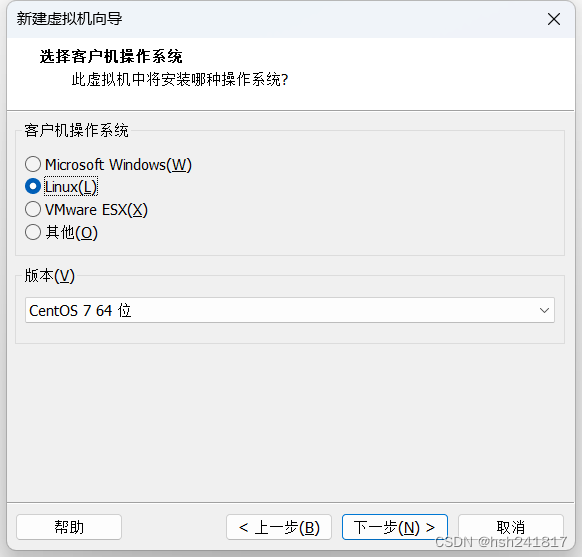
点击下一步
4、定义虚拟机名称和选择虚拟机和操作系统将要安装的位置:
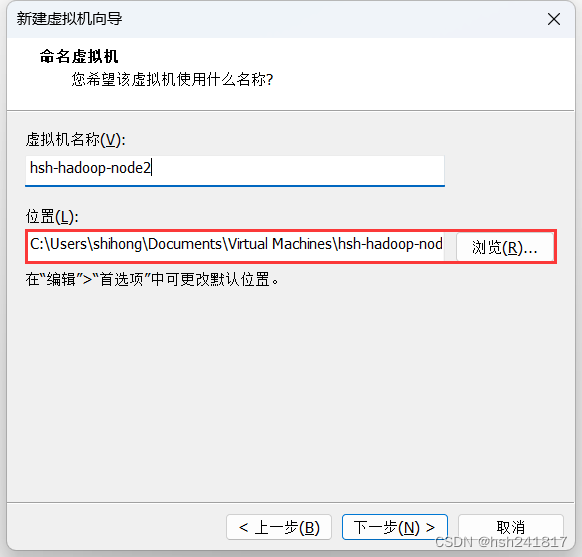
虚拟机的名称改一个统一的名称,比如hsh-hadoop-node2(在此之前我已经安装好了第一个节点)
位置:选择一个d盘的位置,这里将要存放的是centos操作系统
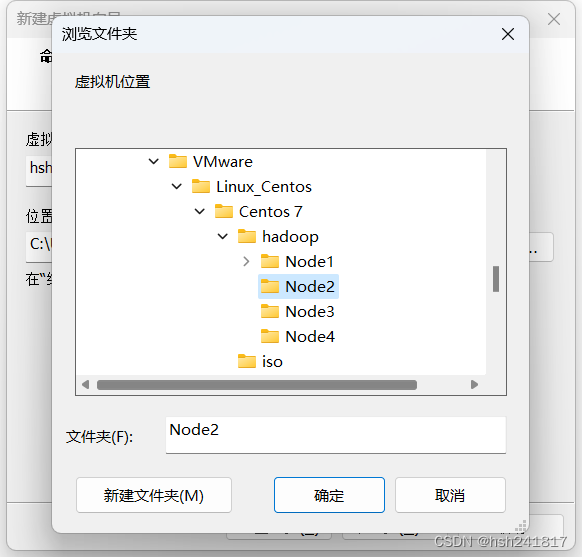

点击下一步
5、指定磁盘容量
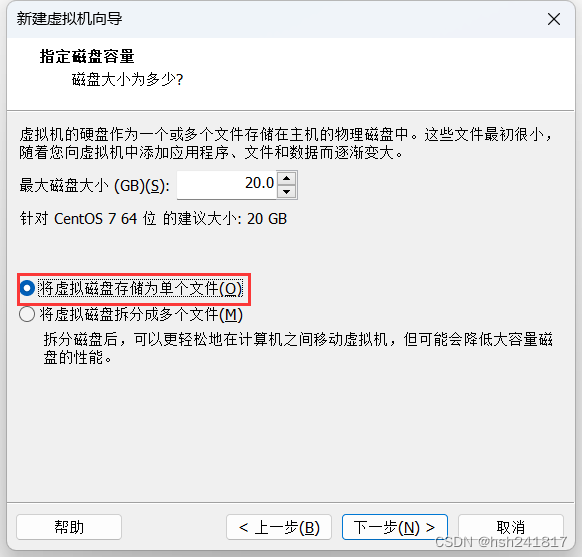
选择最大磁盘大小为20gb
并选择将虚拟磁盘存储为单个文件,前提是你这个操作系统之后不会频繁移动,并且d盘需要有足够大的空间
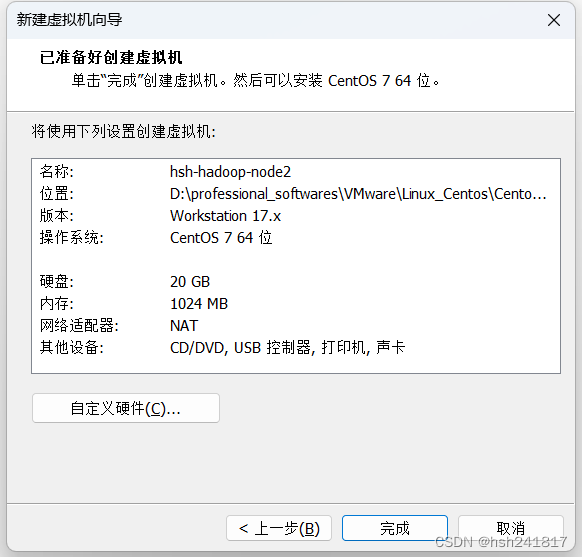
点击完成
6、点击虚拟机设置,选择centos的iso映像文件
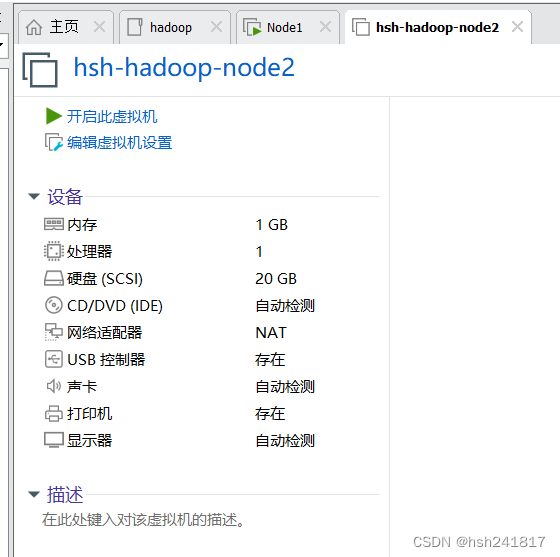
点击编辑虚拟机设置,由于之前我们在选择安装源时选择的是稍后安装操作系统,所以我们需要在这个选择合适的iso镜像文件
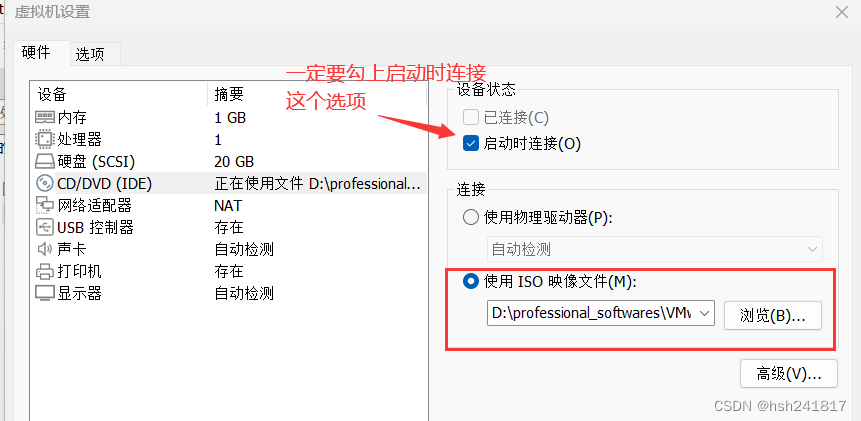
确定后点击开启虚拟机
7、配置操作系统:
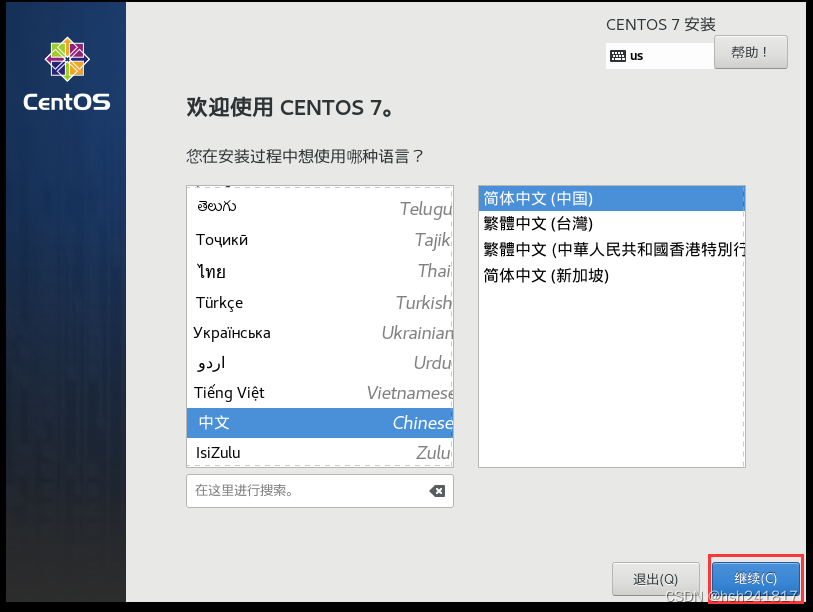
选择简体中文,点击继续
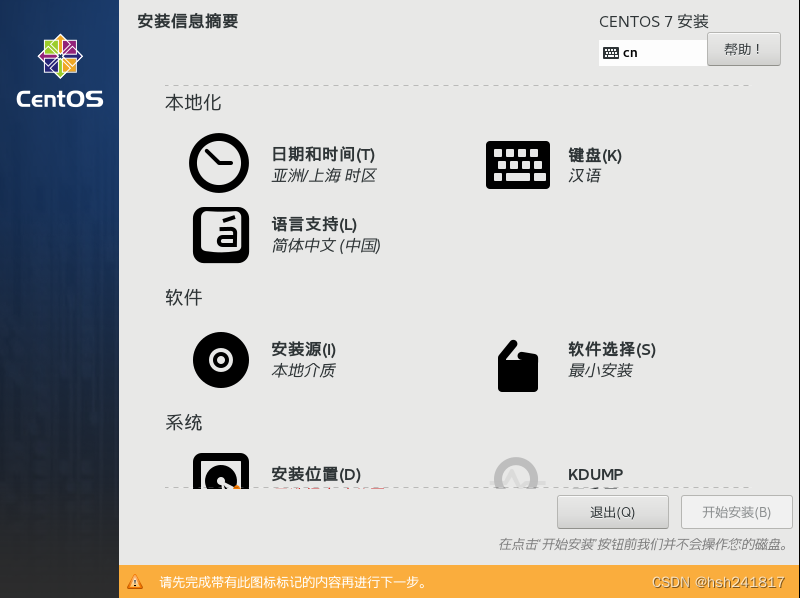

1、日期时间选择亚洲/上海时区
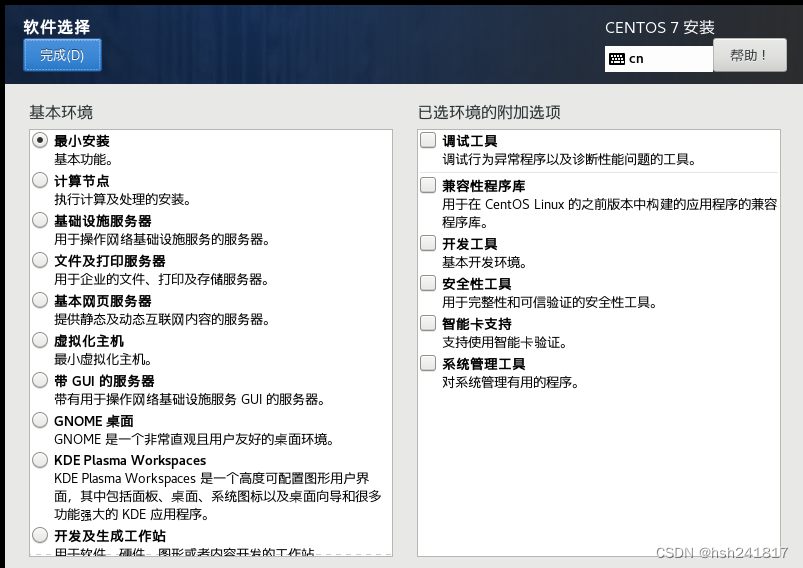
2、软件选择最小安装,如下图即可
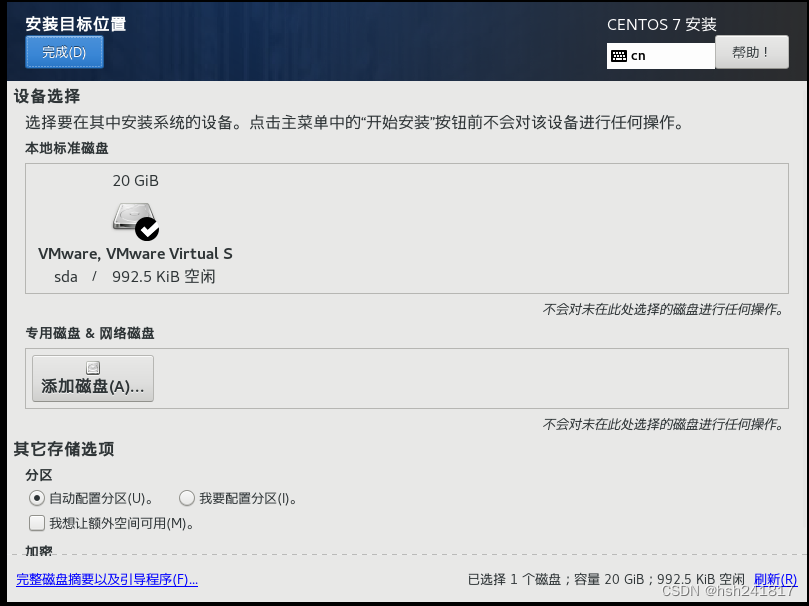
3、安装目标位置选择自动分配分区即可,如下图
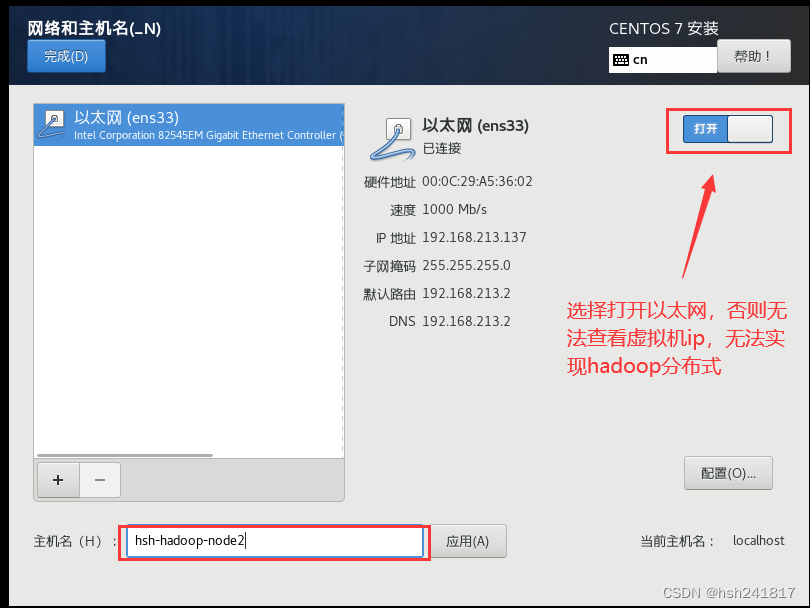
4、网络和主机名中,将以太网打开,适当选择修改主机名
5、点击开始安装即可
6、设置root密码,一定要设置,创建用户看个人需要,可以在之后创建

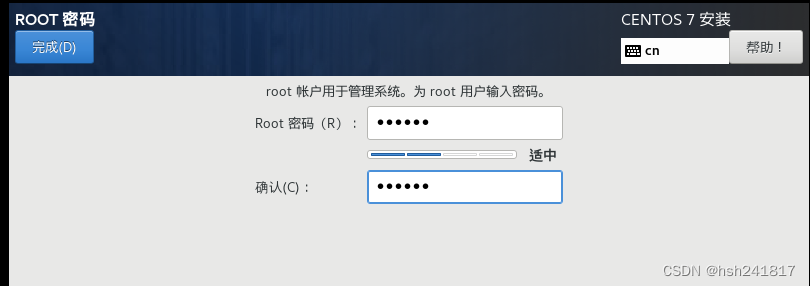
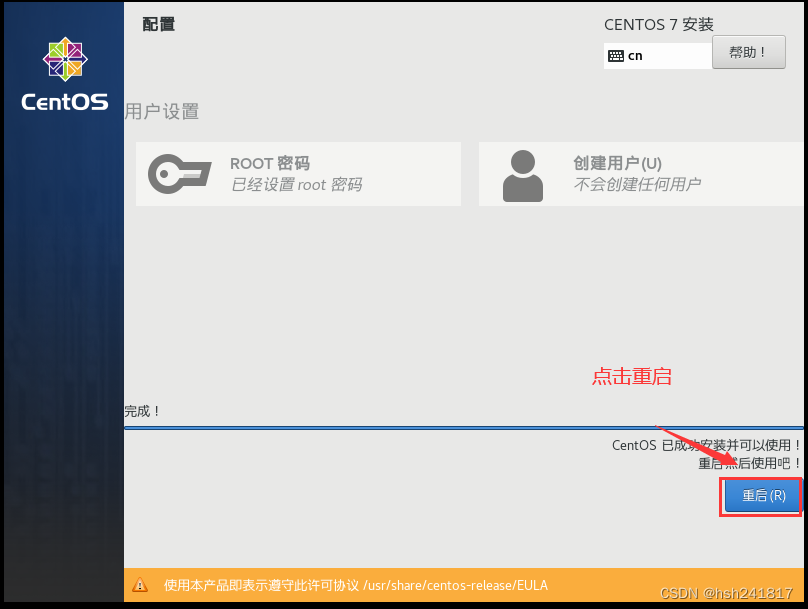
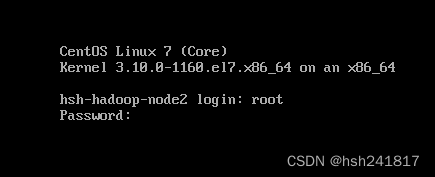
输入root用户名和密码即可登录centos操作系统

8、虚拟机克隆:
因为要搭建hadoop集群,所以需要多个虚拟机,一个一个安装太慢,可以使用虚拟机克隆的方式
拍摄快照之后,另外三台虚拟机就可以通过快照克隆的方式搭建。
(用的已经配置好hadoop搭建前环境进行演示)
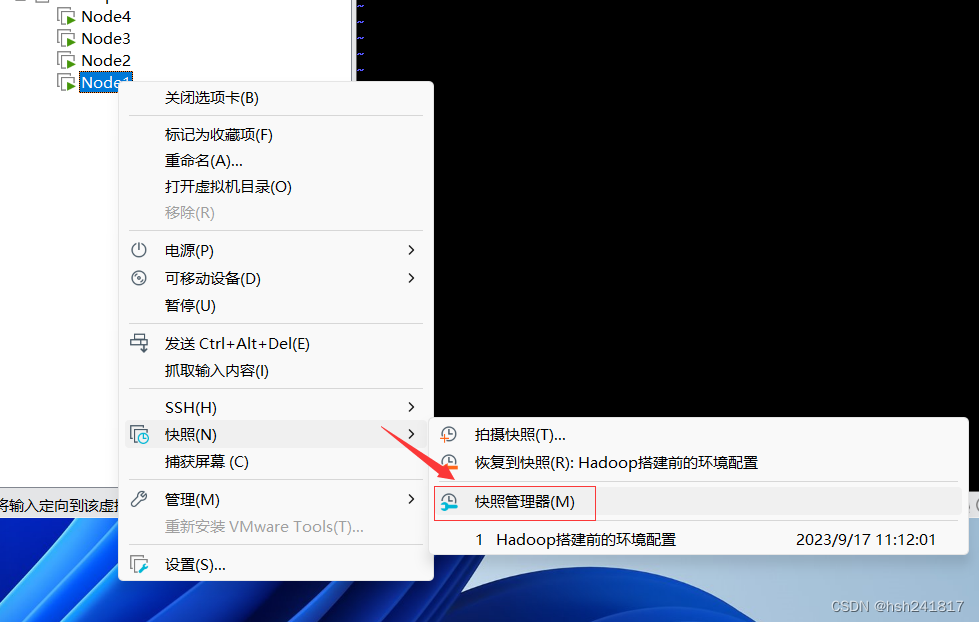
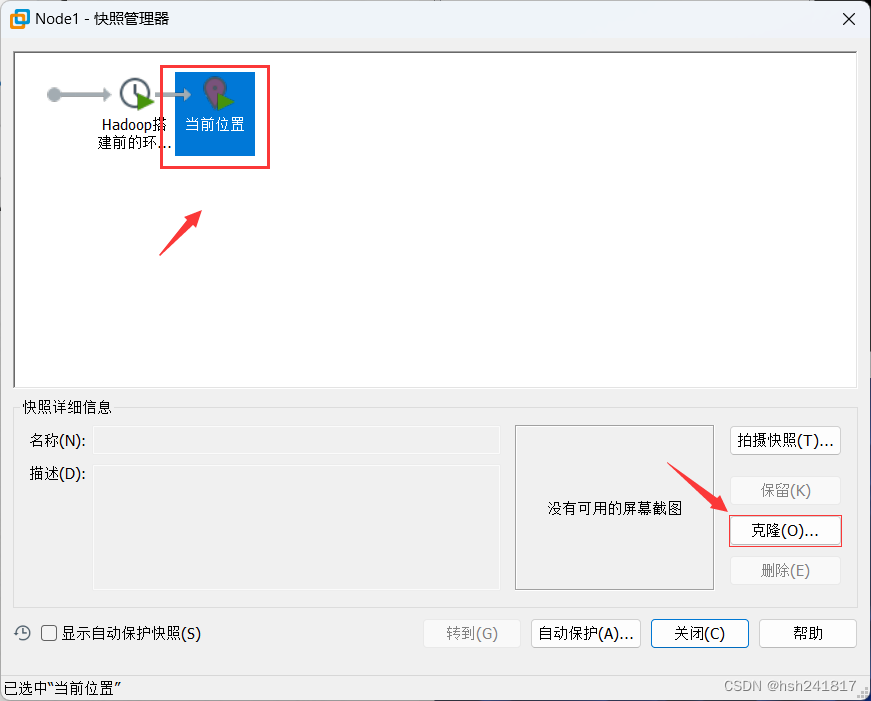
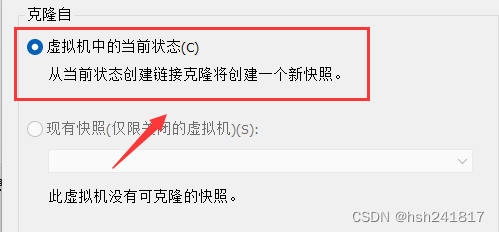
之后选择相应的d盘文件夹装载操作系统文件(克隆)
二、配置hadoop搭建前环境
1、配置linux静态ip
为什么要配置静态ip地址?
目前主流的ip地址分配主要是基于ipv4,但是目前的ipv4的地址已经基本分配完了,所以为了节省ip地址,连接到同一个局域网的设备的ip地址是由父节点动态分配的,以节省ip资源。同一个集群中的设备应尽可能避免ip地址动态分配,这会造成一些不必要的麻烦,所以将虚拟机的ip地址设为静态。
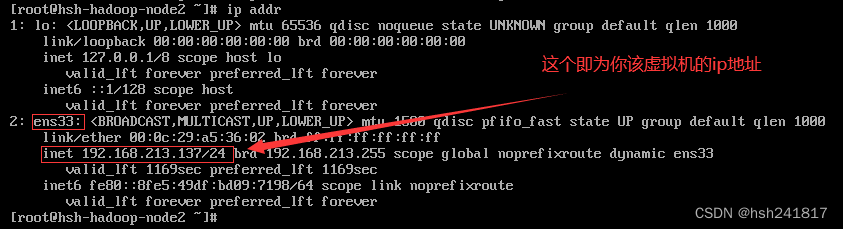
修改ip为静态ip
后面的这个ifcfg-ens33根据每个人的配置不同,名字也不一样,可能是ens780都有可能,根据你ip addr查看到的为准
进入到文件中,文件详情如下图所示
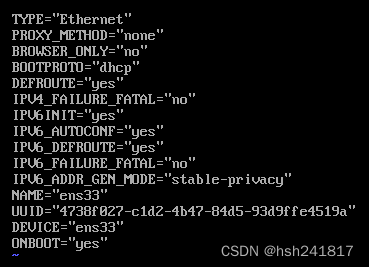
需要修改或增添的的内容有bootproto、ipaddr、gateway、netmask、dns
bootproto:将dhcp修改为static
ipaddr:ip地址,如果在bootroto中设置为dhcp,即该ip地址为动态分配的,设置为static即为静态ip,即使重启虚拟机也不会改变
gateway:网关,和ip地址前三段相同
netmask:子网掩码
修改网关和子网掩码的要求:
点击虚拟机中的编辑,

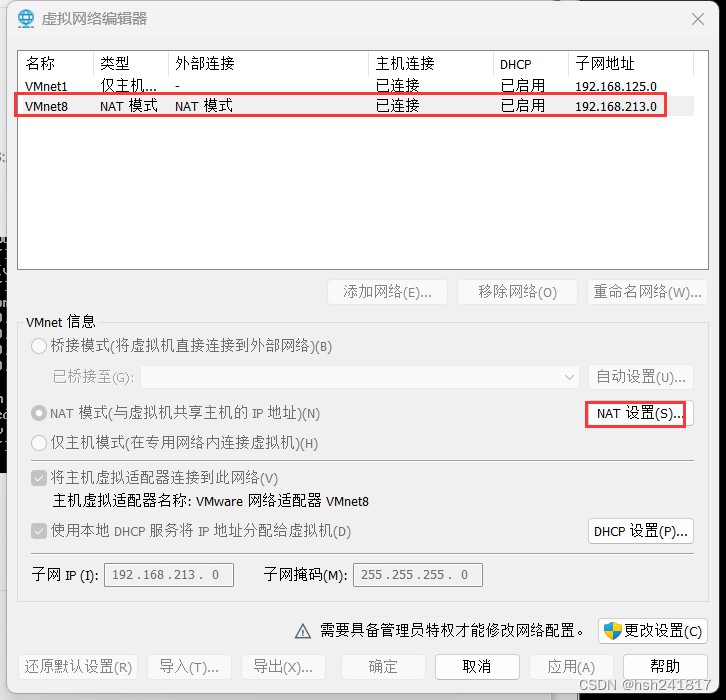
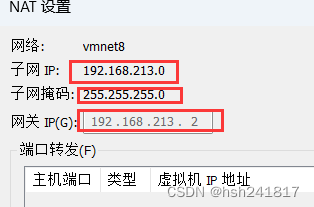
设置的网关和子网掩码务必要和虚拟机网络设置中的相同,ip地址只要和网关的前三段相同即可,tip. 网关的最后一位一般为2
dns:
在自己的主机windows系统上,打开cmd,输入ifconfig
如果连接到的是wifi,就找到无线局域网适配器wlan,查看dns服务器,将dns1、dns2添加到配置文件中。
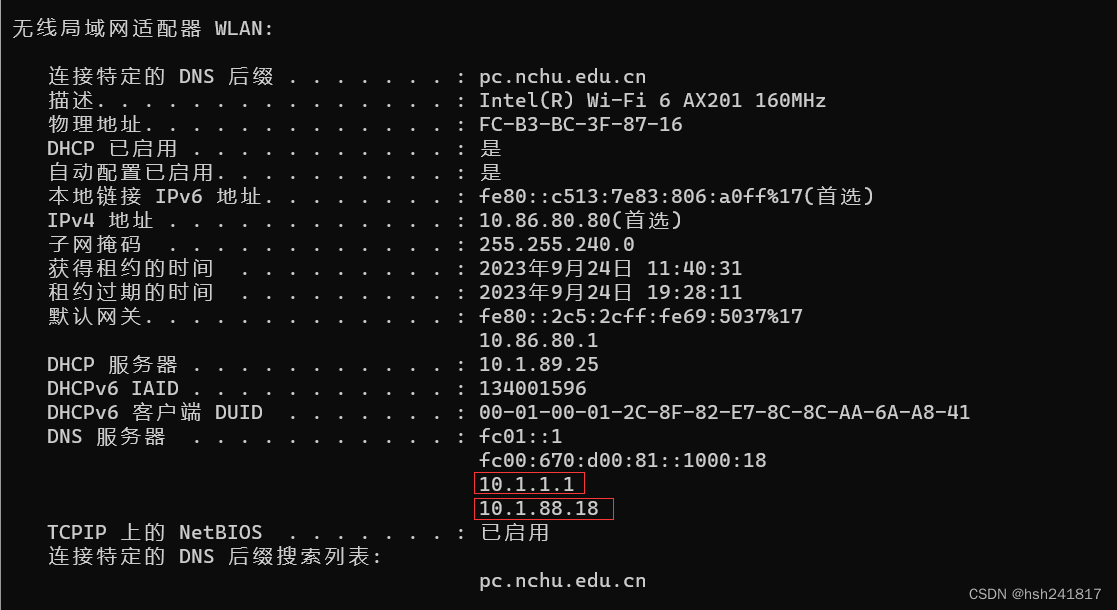
最终,将该文件内容修改为以下:
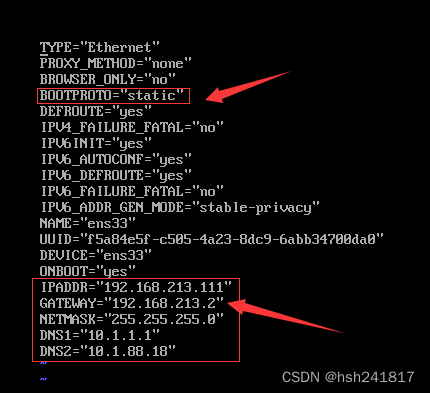
tips:其他的教程可能会说配置dns为8.8.8.8 和114.114.114.114,8.8.8.8的dns服务器是微软的dns服务器,但其实使用这个dns可能会有问题,所以建议dns服务器最好就是选择你自己经常连接的wifi自动分配的dns服务器(不要电脑连接手机热点,手机热点的dns服务器会经常更换,可能会有问题)
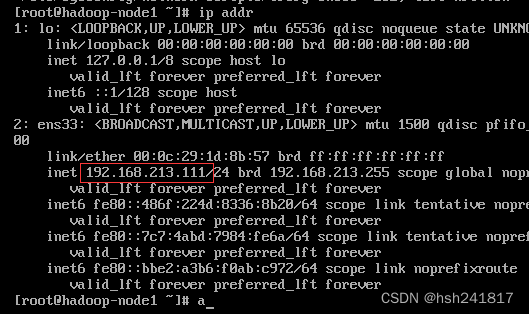
观察到ip地址改为文件修改时的ip地址即修改成功
2、linux主机名和ip映射
为什么要设置主机名和ip映射?
将不同的虚拟机设置一个独有且有规律的名字有助于集群中设备的管理,ip映射也是如此,他将主机名与设备的ip地址绑定,有利于设备的管理和集群工作。
![]()
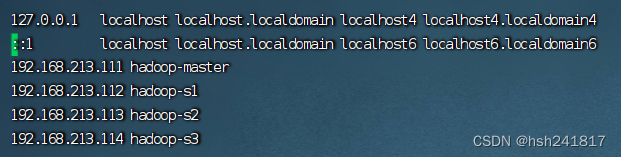
增添 192.168.213.111 hadoop-master (192.168.213.111为文件修改的ip地址,hadoop-master为你想修改的主机名)

并且要将集群中所有的节点主机映射全部添加(每台虚拟机都需要配置,之后我们可以通过scp命令将文件传输到其他节点上,现在不需要去另外节点配置)
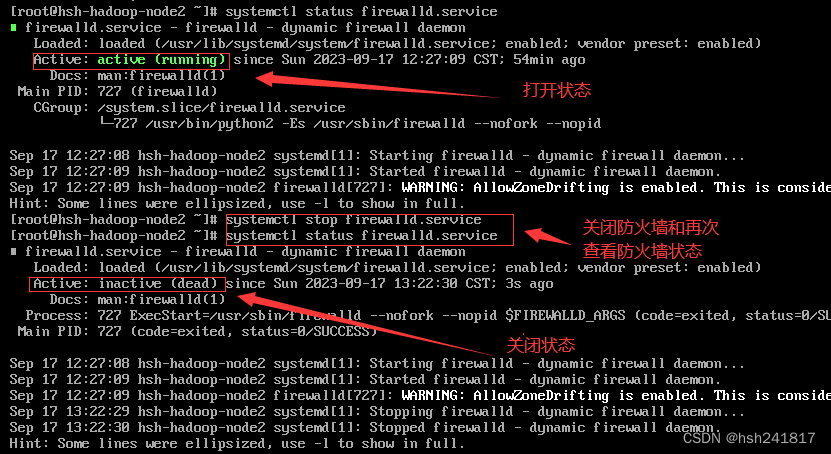
3、关闭linux防火墙
为什么关闭防火墙?
防火墙会阻挡集群中每个设备之间的通信,防火墙可能会阻止某些端口的连接或者关闭端口,总之打开各个设备的防火墙有害于集群之间的通信
4、linux ssh免密登录
为什么设置ssh免密登录?
集群中的设备之间存在某些共享的文件和数据,如果不设置免密登录,则每次设备之间获取共享数据时都要输入密码,大幅降低了集群的工作效率。
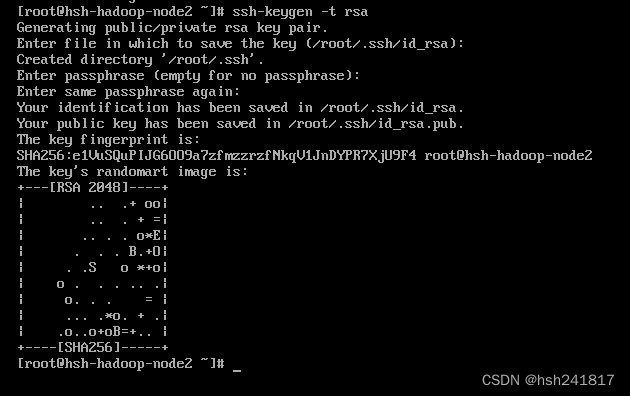
首先在控制台切换到用户根目录,使用ssh-keygen -t rsa命令 (ssh-keygen 是密钥生成器,-t为参数 rsa是一种加密算法)生成密钥对(即公钥文件id_rsa.pub和私钥文件id_rsa)
重复按下enter键出现以下内容即生成密钥对成功
接下来再查看.ssh目录的文件,并将公钥文件id_rsa.pub中的内容复制到相同目录下的authorized_keys中

再然后以上操作对所有虚拟机都要进行一遍操作,并且将每台虚拟机中的id_rsa.pub中的内容拷贝到一台虚拟机中的authorized_keys文件中(在本教程中,我将s1、s2、s3中的id_rsa.pub文件内容都拷贝到了master的authorized_keys文件中),拷贝有远程连接软件会方便很多,如果没有远程连接软件,可以自己试试其他方法
以下为各台虚拟机id_rsa.pub文件情况




拷贝到master之后
以下为matser节点的authorizer_keys文件

接下来再将matser节点的authorized_keys远程拷贝到其他节点(其他节点也相同),这步在最后我们可以通过scp命令进行传输,先不急
切换到hadoop用户的根目录下,为.ssh目录及文件赋予相应权限
![]()
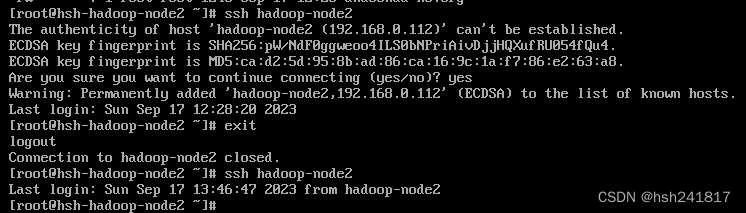
最后使用ssh命令登录hadoop-s1,第一次登录需要输入yes进行确认,第二次则不用,此时表示设置成功,其他节点也是如此
如果第二次连接依旧还需要密码,则可能是 chmod 700 .ssh chmod 600 .ssh/* 并没有执行或执行成功,这会导致hadoop集群无法正常启动,免密登录设置这一步很重要
ex.最后再配置一个时间同步(在ssh目录下使用以下命令)
![]()
5、关键一步,快照保存
每次完成一次重要的配置或者软件安装,最好都需要进行一次快照保存,以便之后恢复历史节点
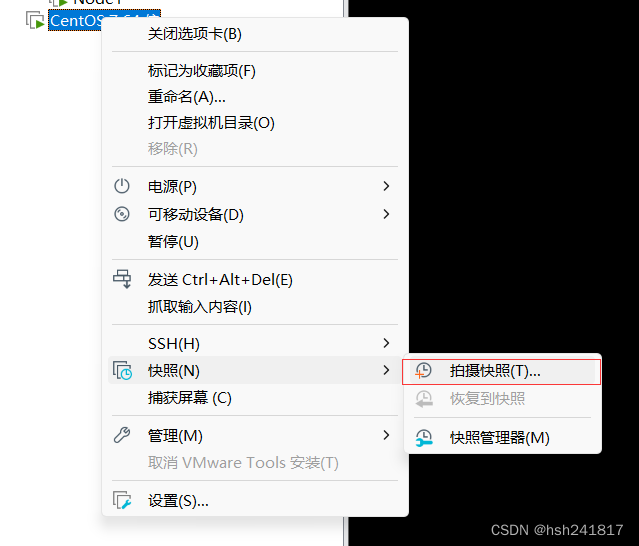
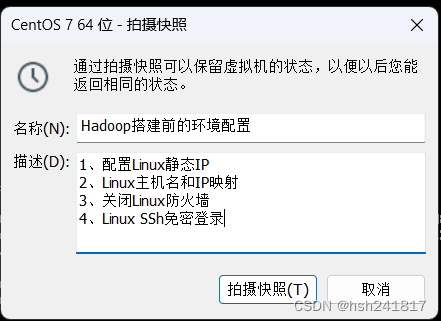
记录本次配置的关键信息,点击拍摄快照即可
三、搭建hadoop(在此次配置中以hadoop3.3.6进行演示)
1、登录hadoop官网下载hadoop压缩包、登录java官网下载jdk压缩包(jdk1.8.0_381),tip.下载jdk1.8.0_381需要注册oracle账号
hadoop下载网址:apache hadoop
jdk下载网站:java downloads | oracle 中国

下载好之后打开远程连接软件(如winscp、finallshell,我自己用的是finallshell)连接虚拟机,上传hadoop和jdk压缩包(jdk使用1.8版本)
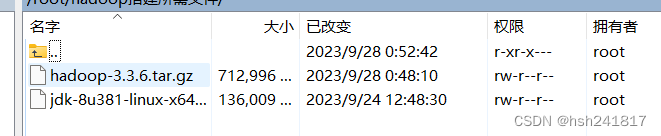
进入压缩包所在的目录,并进入相关文件夹解压两个压缩包,我自己的hadoop安装目录是放在/home/hadoop目录下的
2、解压缩好之后,配置jdk环境变量
生效环境变量(也可以等hadoop的环境变量配好之后再生效环境变量,但推荐还是每配置好一个环境就生效以查验是否正确安装)
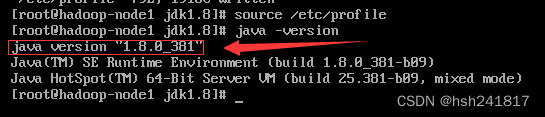
观察到java version和安装的jdk版本相同即可
3、配置hadoop
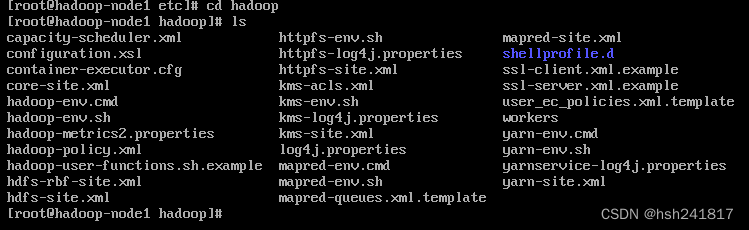
进入hadoop目录配置hadoop-env.sh文件及其他重要文件
1、配置hadoop-env.sh:
# 修改或添加以下内容
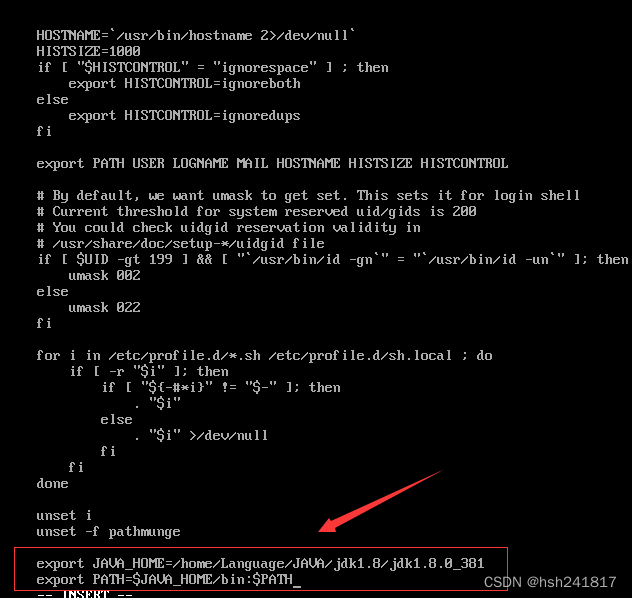
export java_home=/home/language/java/jdk1.8/jdk1.8.0_381 #都是修改为自己安装的路径
export hadoop_home=/home/hadoop/hadoop-3.3.6
2、配置core-site.xml文件:
# 在configureation之间添加以下内容
<property>
<name>fs.defaultfs</name> # fs.defaultfs是指定hadoop文件系统的默认uri
<value>hdfs://hadoop_master:9000</value> # 表示默认的hadoop的文件系统是运行在hadoop_master节点上
</property>
<property>
<name>hadoop.tmp.dir</name> #hadoop的临时文件存放位置
<value>/home/softwares/hadoop/hadoop-3.3.6/hadoopdata</value> #将hadoop的临时文件存储到hadoopdata目录下
</property>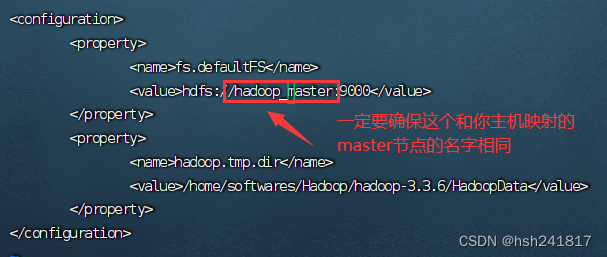
上面的这张图有误,我自己的主节点名为hadoop-master,大家配的时候配自己的主节点(master)名即可
3、配置hdfs-site.xml文件:
# 添加或修改内容如下
<property>
<name>dfs.namenode.secondary.http-address</name> #这个是为主节点配置一个副本节点,防止主节点宕机数据丢失,但其实在实际情况中,secondary节点和master节点不在同一台机器或服务器上配置
<value>hadoop-master:50090</value>
</property>
<property>
<name>dfs.replication</name> #指定数据块的复制数为3
<value>3</value>
</propert>
<property>
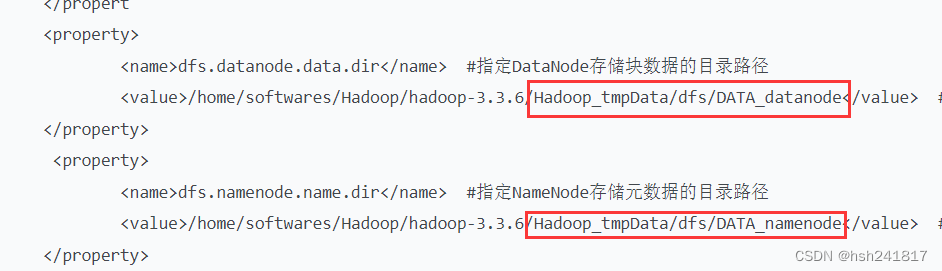
<name>dfs.datanode.data.dir</name> #指定datanode存储块数据的目录路径
<value>/home/softwares/hadoop/hadoop-3.3.6/hadoop_tmpdata/dfs/data_datanode</value> # data_datanode文件夹需要之后自行创建,不过好像hadoop集群再启动的时候如果没有也会自行创建,但还是自己创建一个最好
</property>
<property>
<name>dfs.namenode.name.dir</name> #指定namenode存储元数据的目录路径
<value>/home/softwares/hadoop/hadoop-3.3.6/hadoop_tmpdata/dfs/data_namenode</value> # data_namenode如上
</property>
4、配置mapred-site.xml文件:
# 添加或修改以下内容
<property>
<name>mapreduce.framework.name</name> 表示mapreduce应用程序应在yarn(yet another resource negotiator)框架上运行。
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name> # 此属性指定 jobhistory 服务器的地址,用于跟踪已完成和正在运行的作业。
<value>hadoop-master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name> # 此属性定义 jobhistory 服务器的 web 应用程序地址。用户可以通过指定地址(在本例中为“hadoop-master:19888”)的 web 界面访问作业历史记录信息。
<value>hadoop-master:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name> # 此属性在 yarn 应用程序中运行时为 mapreduce applicationmaster (am) 设置环境变量。
<value>hadoop_mapred_home=/home/hadoop/hadoop-3.3.6</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>hadoop_mapred_home=/home/hadoop/hadoop-3.3.6</value> # 这个包括下面的属性分别为 map 和 reduce 任务设置环境变量。
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>hadoop_mapred_home=/home/hadoop/hadoop-3.3.6</value>
</property> 
5、配置yarn-site.xml文件:
#添加或修改为以下内容
<property>
<name>yarn.resourcemanager.hostname</name> # 此属性设置yarn资源管理器的主机名。在这里,它被设置为 "hadoop-master",这表示yarn资源管理器应该运行在名为 "hadoop-master" 的主机上。
<value>hadoop_master</value>
</property>
<property>
<name>yarn.nodemanage.aux-services</name> # 个属性定义了nodemanager上运行的辅助服务。在这里,它被设置为 "mapreduce_shuffle",这表示nodemanager将提供mapreduce的shuffle服务。mapreduce中的shuffle是指在map任务完成后,将输出数据传输到reduce任务的过程。
<value>mapreduce_shuffle</value>
</property>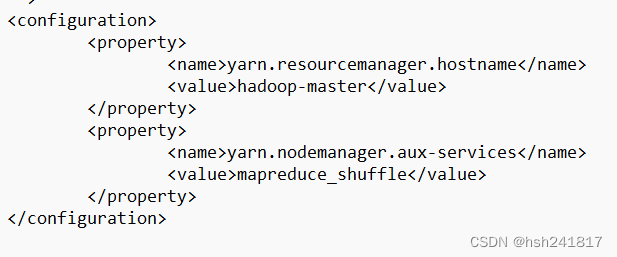
6、配置workers文件:
删除localhost
#加入以下内容
hadoop-s1
hadoop-s2
hadoop-s3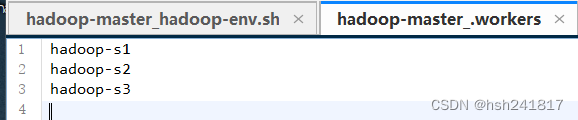
注意:如果在这个workers文件当中,将hadoop-master也添加进来,那么最后hadoop集群启动之后,在hadoop-master主节点也会存在datanode进程,如果不添加则不存在,只会在从节点中会有datanode进程。建议master节点上不要添加datanode,master节点主要负责管理即可。
7、配置其他文件以防止hadoop启动失败
在start-dfs.sh,stop-dfs.sh 两个文件顶部添加以下参数
hdfs_datanode_user=root
hadoop_secure_dn_user=hdfs
hdfs_namenode_user=root
hdfs_secondarynamenode_user=root在start-yarn.sh,stop-yarn.sh两个文件顶部添加以下参数
yarn_resourcemanager_user=root
hadoop_secure_dn_user=yarn
yarn_nodemanager_user=root以上配置是为了防止error attempting to operate on hdfs namenode as root 的报错,因为我们目前的整个集群都是基于linux的root用户配置的,其实在在真实的生产环境中,是不会用root用户的,因为这会存在安全问题,但目前初学者来说大部分都是使用root用户,所以也可以强制hadoop使用root用户启动运行。
创建相关文件目录
hadoop配置完成后 cd 回到hadoop-3.3.6目录,创建hadoopdata目录和data_datanode、data_namenode目录(在本例子中,目录路径为:/home/softwares/hadoop/hadoop-3.3.6/hadoopdata)

4、配置以及检查主节点虚拟机的hadoop的环境变量
1、配置hadoop环境变量
# 添加以下内容:
export hadoop_home=/home/softwares/hadoop/hadoop-3.3.6
export path=$hadoop_home/bin:$hadoop_home/sbin:$path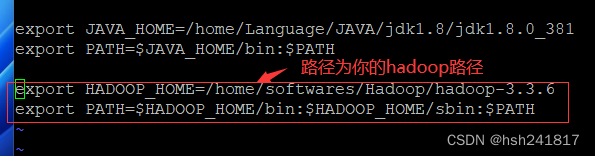
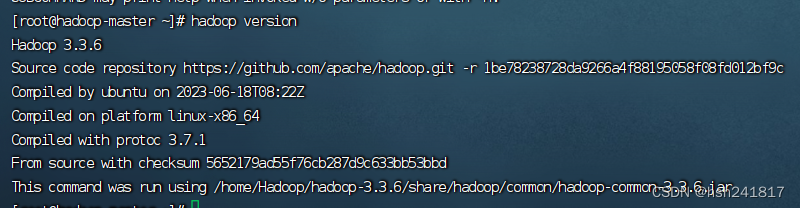
2、测试是否正确安装
出现如下页面即为安装成功
5、传送相应文件至从节点,并生效环境变量
要传的文件有hadoop(在我的目录里,hadoop目录下是包括了hadoop-3.3.6的,/home/softwares/hadoop/hadoop-3.3.6,其实只需要传hadoop-3.3.6目录即可,具体看自己配的环境变量路径和hadoop配置文件里的路径)、java目录(我自己的java目录下包括了jdk-1.8,,/home/language/java/jdk1.8/jdk1.8.0_381,其实只需要上传jdk-1.8目录即可,具体看自己配的环境变量路径和hadoop配置文件里的路径),profile文件(环境变量文件, /etc/profile)
1、传送hosts文件
在/etc目录下
2、传送hadoop目录
回到softwares目录
将hadoop/hadoop-3.3.6传送到s1,s2,s3的指定目录下(省的每个虚拟机都要修改相同的配置)

3、传送java/jdk-1.8
将jdk的包和环境变量的文件传送到s1 s2 s3。
4、传送环境变量
将/etc/profile的环境变量文件传送到 s1 s2 s3
5、生效环境变量在每个虚拟机中,使环境变量文件生效(使用finalshell可以同时发送命令到全部会话)
四、启动hadoop集群
在master节点下
测试hadoop集群是否正常启动
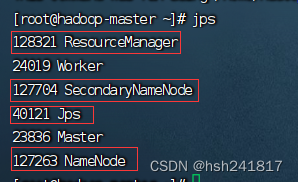
启动之后,使用jps命令查看正在运行的进程,正常来说在master节点下会有以下四个红框的进程,未被红框标记的进程是其他的进程(storm的进程,在本次hadoop集群的搭建中无关紧要),未出现这四个节点即集群启动不成功
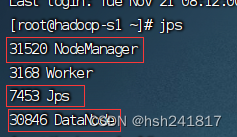
在从节点上,使用jps命令可以看到以下三个红框标记的进程,未被红框标记的进程是其他的进程(storm的进程,在本次hadoop集群的搭建中无关紧要),未出现这三个节点也表示集群启动不成功
如果集群正常启动,则可以登录hadoop的网页:主节点ip地址:9870(我自己的地址是192.168.213.111:9870)
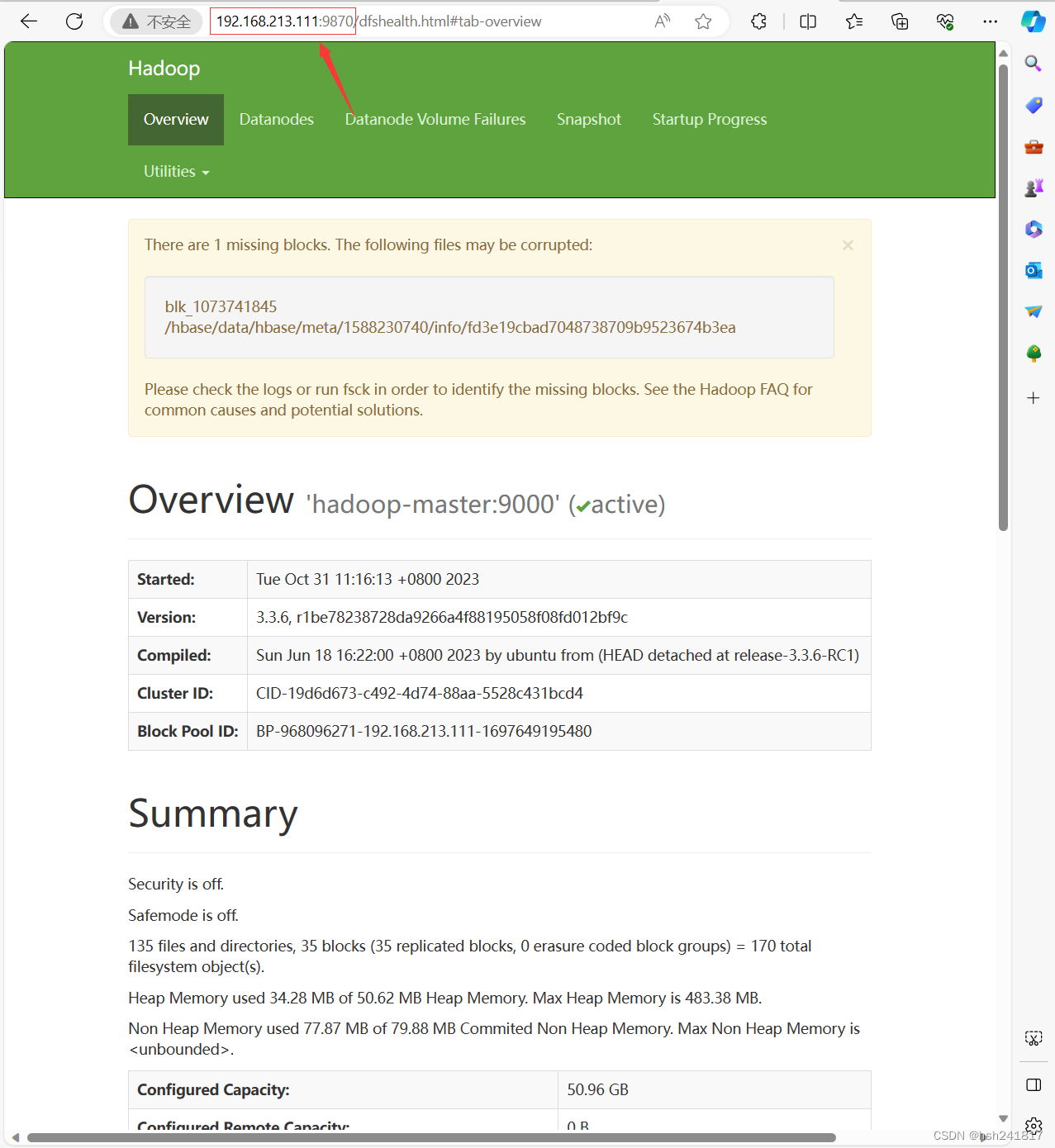
如果顺利出现以上页面,恭喜你,你已经成功迈出了大数据学习的第一步!
还有一件事!!!!不要忘了给每台虚拟机保存虚拟机快照
最后,祝大家配置hadoop都能一发入魂,good luck!!
欢迎大家对本次教程提出批评与指正,这真的很重要!!
联系:
qq:106672998
微信:hsh232626
发表评论