hadoop版本演变历史
hadoop发行版非常的多,有华为发行版、intel发行版、cloudera hadoop(cdh)、hortonworks hadoop(hdp),这些发行版都是基于apache hadoop衍生出来的。
目前hadoop经历了三个大的版本。

hadoop1.x:hdfs+mapreduce
hadoop2.x:hdfs+yarn+mapreduce
hadoop3.x:hdfs+yarn+mapreduce

在hadoop1.x中,分布式计算和资源管理都是mapreduce负责的,从hadoop2.x开始把资源管理单独拆分出来了,yarn是一个公共的资源管理平台,在它上面不仅仅可以跑mapreduce程序,还可以跑很多其他的程序,例如:spark、flink等计算框架都是支持在yarn上面执行的,并且在实际工作中也都是在yarn上面执行,只要程序满足yarn的规则即可。
hadoop3.x的架构并没有发生什么变化,但是它在其他细节方面做了很多优化,常见的包括:
- 最低java版本要求从java7变为java8;
- 在hadoop 3中,hdfs支持纠删码,纠删码是一种比副本存储更节省存储空间的数据持久化存储方法,使用这种方法,相同容错的情况下可以比之前节省一半的存储空间
hdfs erasure coding - hadoop 2中的hdfs最多支持两个namenode,一主一备,而hadoop 3中的hdfs支持多个namenode,一主多备;
hdfs high availability using - mapreduce任务级本地优化,mapreduce添加了映射输出收集器的本地化实现的支持。对于密集型的洗牌操作(shuffle-intensive)jobs,可以带来30%的性能提升,
task level native optimization - 修改了多重服务的默认端口,hadoop2中一些服务的端口和hadoop3中是不一样的
hadoop 3和2之间的主要区别在于新版本提供了更好的优化和可用性
参考官网
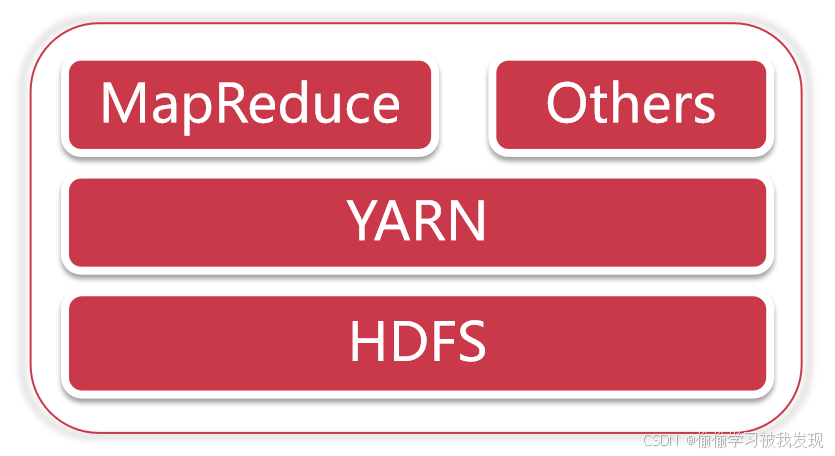
hadoop三大核心组件
hadoop主要包含三大组件:hdfs+mapreduce+yarn
- hdfs负责海量数据的分布式存储
- mapreduce是一个计算模型,负责海量数据的分布式计算
- yarn主要负责集群资源的管理和调度
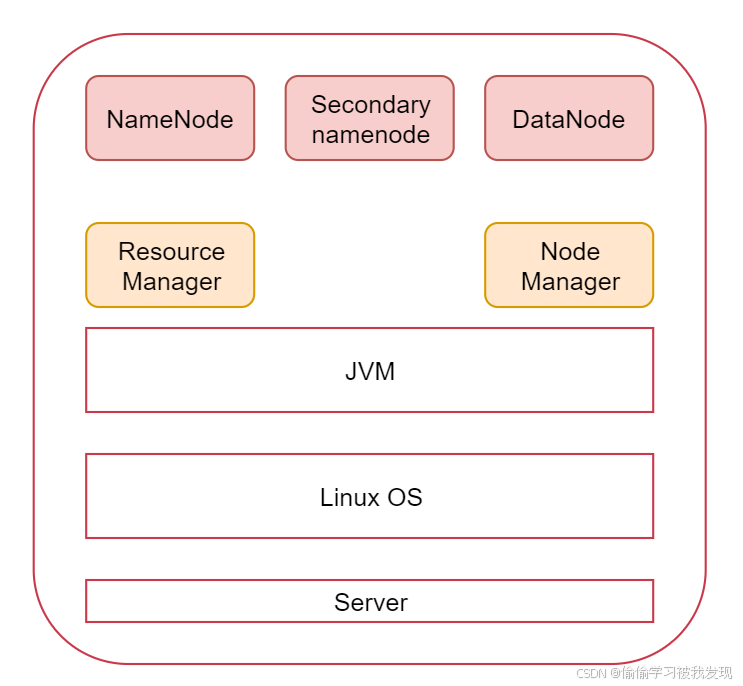
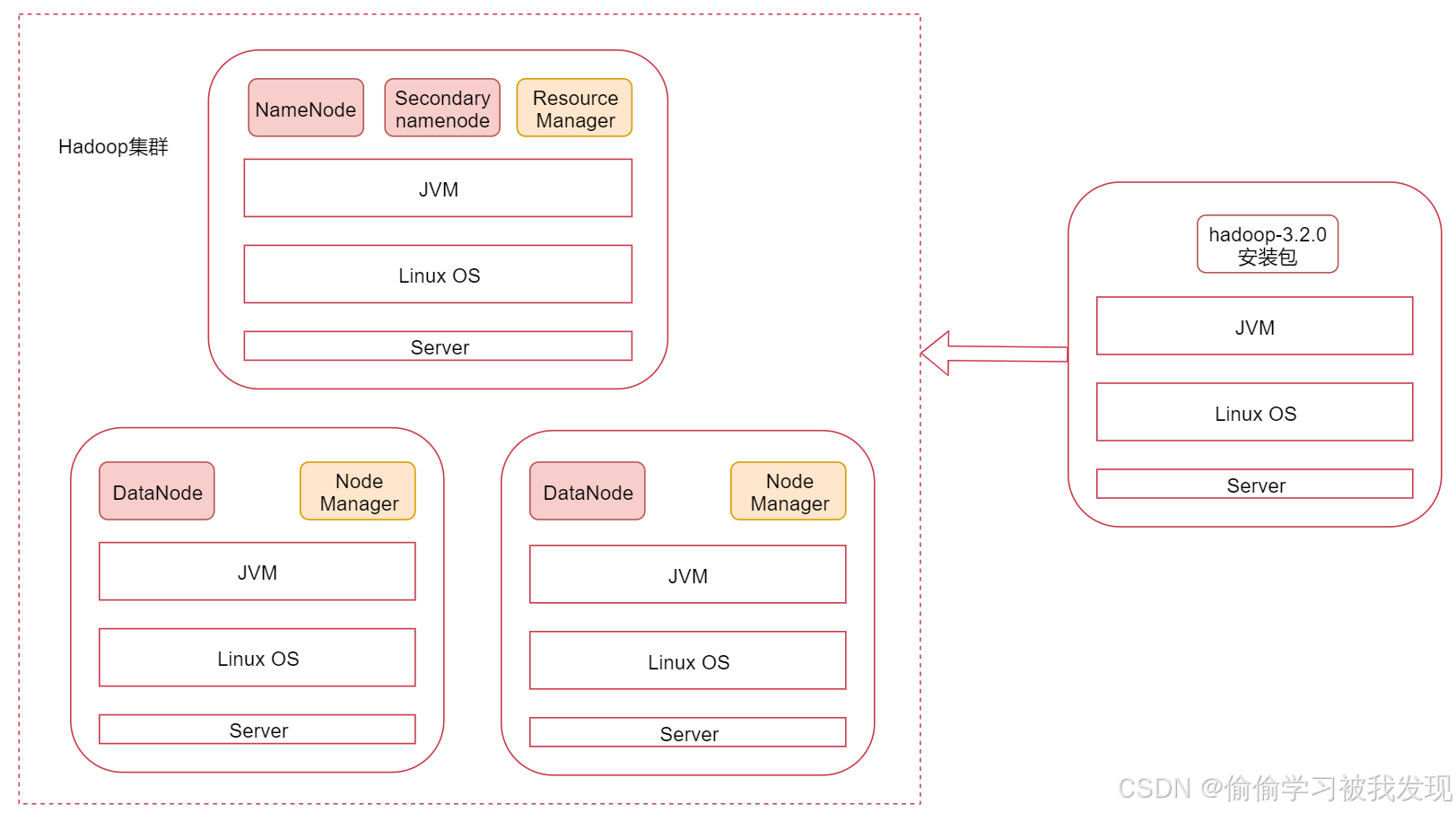
这张图代表是一台linux机器,也可以称为是一个节点,上面安装的有jdk环境,最上面的是hadoop集群会启动的进程,其中namenode、secondarynamenode、datanode是hdfs服务的进程,resourcemanager、nodemanager是yarn服务的进程,mapredcue在这里没有进程,因为它是一个计算框架,等hadoop集群安装好了以后mapreduce程序可以在上面执行。
分布式集群安装
左边这一个是主节点,右边的两个是从节点,hadoop集群是支持主从架构的。
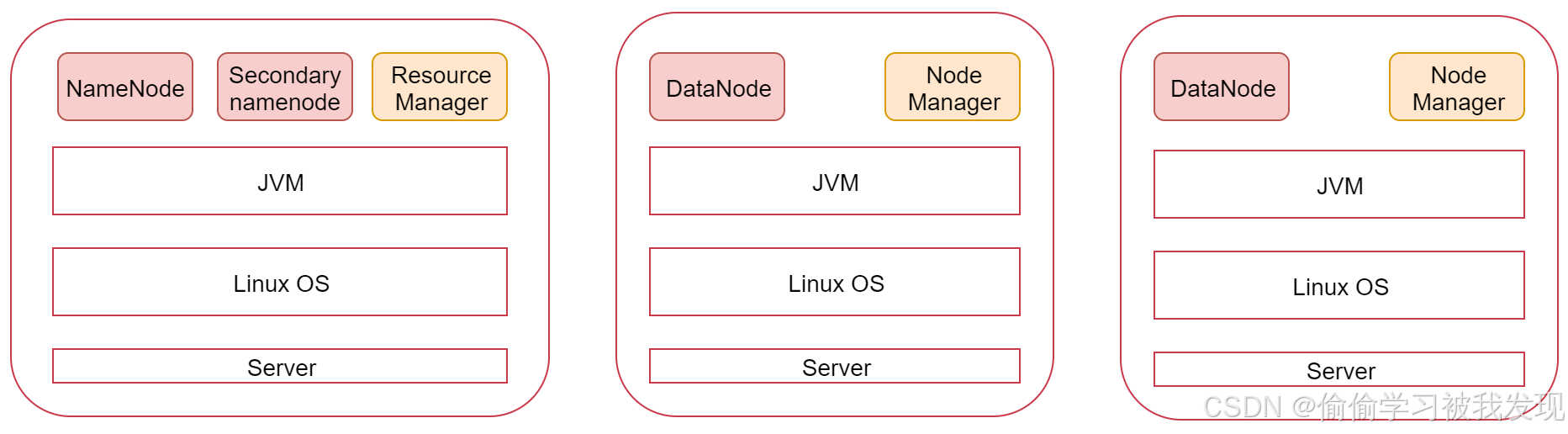
一主两从的hadoop集群,环境准备:三个节点
bigdata01 192.168.182.100
bigdata02 192.168.182.101
bigdata03 192.168.182.102
下载安装包
hadoop官网下载地址
版本hadoop3.2.0
配置基础环境
设置静态ip、hostname、host、firewalld、ssh免密码登录、安装jdk与环境变量、集群节点之间时间同步
设置静态ip
# 主节点 ipaddr=192.168.182.100
# 从节点 ipaddr=192.168.182.101、ipaddr=192.168.182.102
[root@localhost ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
type="ethernet"
proxy_method="none"
browser_only="no"
bootproto="static"
defroute="yes"
ipv4_failure_fatal="no"
ipv6init="yes"
ipv6_autoconf="yes"
ipv6_defroute="yes"
ipv6_failure_fatal="no"
ipv6_addr_gen_mode="stable-privacy"
name="ens33"
uuid="9a0df9ec-a85f-40bd-9362-ebe134b7a100"
device="ens33"
onboot="yes"
ipaddr=192.168.182.100
gateway=192.168.182.2
dns1=192.168.182.2
# 重启网络服务
[root@bigdata01 ~]# service network restart
restarting network (via systemctl): [ ok ]
[root@bigdata01 ~]# ip addr
1: lo: <loopback,up,lower_up> mtu 65536 qdisc noqueue state unknown group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <broadcast,multicast,up,lower_up> mtu 1500 qdisc pfifo_fast state up group default qlen 1000
link/ether 00:0c:29:9c:86:11 brd ff:ff:ff:ff:ff:ff
inet 192.168.182.100/24 brd 192.168.182.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::c8a8:4edb:db7b:af53/64 scope link noprefixroute
valid_lft forever preferred_lft forever
设置临时主机名和永久主机名hostname
# 临时主机名
# 主节点 bigdata01
# 从节点 bigdata02、bigdata03
[root@bigdata01 ~]# hostname bigdata01
[root@bigdata01 ~]# vi /etc/hostname
bigdata01
配置永久主机名与静态ip映射,在/etc/hosts文件中配置ip和主机名(hostname)的映射关系,把下面内容追加到/etc/hosts中,不能删除/etc/hosts文件中的已有内容!
# 主节点 bigdata01
# 从节点 bigdata02、bigdata03
[root@bigdata01 ~]# vi /etc/hosts
192.168.182.100 bigdata01
配置/etc/hosts
因为需要在主节点远程连接两个从节点,所以需要让主节点能够识别从节点的主机名,使用主机名远程访问,默认情况下只能使用ip远程访问,想要使用主机名远程访问的话需要在节点的/etc/hosts文件中配置对应机器的ip和主机名信息。
所以在这里我们就需要在bigdata01的/etc/hosts文件中配置下面信息,最好把当前节点信息也配置到里面,这样这个文件中的内容就通用了,可以直接拷贝到另外两个从节点
# 在bigdata01的/etc/hosts文件中配置ip与hostname映射
[root@bigdata01 ~]# vi /etc/hosts
192.168.182.100 bigdata01
192.168.182.101 bigdata02
192.168.182.102 bigdata03
# 在bigdata02的/etc/hosts文件中配置ip与hostname映射
[root@bigdata02 ~]# vi /etc/hosts
192.168.182.100 bigdata01
192.168.182.101 bigdata02
192.168.182.102 bigdata03
# 在bigdata03的/etc/hosts文件中配置ip与hostname映射
[root@bigdata03 ~]# vi /etc/hosts
192.168.182.100 bigdata01
192.168.182.101 bigdata02
192.168.182.102 bigdata03
关闭防火墙
# 临时关闭防火墙
[root@bigdata01 ~]# systemctl stop firewalld
# 永久关闭防火墙
[root@bigdata01 ~]# systemctl disable firewalld
[root@bigdata02 ~]# systemctl disable firewalld
[root@bigdata03 ~]# systemctl disable firewalld
ssh免密码登录
ssh 是secure shell,安全的shell,通过ssh可以远程登录到远程linux机器。
不管是几台机器的集群,启动集群中程序的步骤都是一样的,都是通过ssh远程连接去操作,就算是一台机器,它也会使用ssh自己连自己。
在启动集群的时候只需要在一台机器上启动就行,然后hadoop会通过ssh连到其它机器,把其它机器上面对应的程序也启动起来,使用ssh连接其它机器的时候会发现需要输入密码,所以现在需要实现ssh免密码登录。
# ssh连接主节点
[root@bigdata01 ~]# ssh bigdata01
the authenticity of host 'bigdata01 (fe80::c8a8:4edb:db7b:af53%ens33)' can't be established.
ecdsa key fingerprint is sha256:uug2qrwrlzxcwfv6guot9dvs9c+ifugz7fhr89m2s00.
ecdsa key fingerprint is md5:82:9d:01:51:06:a7:14:24:a9:16:3d:a1:5e:6d:0d:16.
are you sure you want to continue connecting (yes/no)? yes【第一次使用这个主机名需要输入yes】
warning: permanently added 'bigdata01,fe80::c8a8:4edb:db7b:af53%ens33' (ecdsa) to the list of known hosts.
root@bigdata01's password: 【这里需要输入密码】
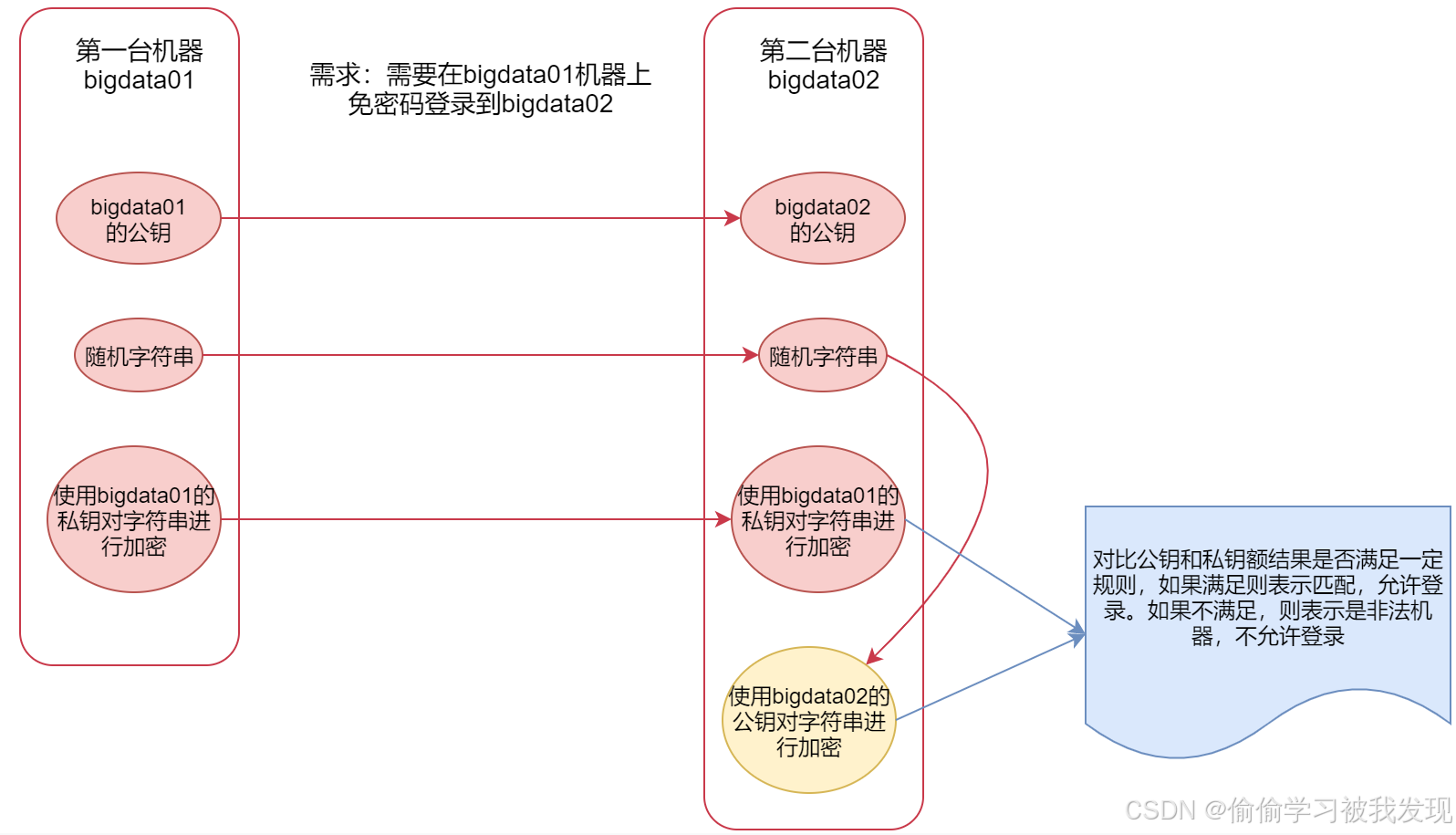
ssh登录原理
ssh这种安全/加密的shell,使用的是非对称加密.
加密有两种,对称加密和非对称加密。
非对称加密的解密过程是不可逆的,比较安全。非对称加密会产生秘钥,秘钥分为公钥和私钥,在这里公钥是对外公开的,私钥是自己持有的。
ssh通信过程:
1、第一台机器会把自己的公钥给到第二台机器;
2、当第一台机器要给第二台机器通信时,第一台机器会给第二台机器发送一个随机的字符串;
3、第二台机器会使用公钥对这个字符串加密,同时第一台机器会使用自己的私钥也对这个字符串进行加密,然后也传给第二台机器;
4、这时第二台机器就有了两份加密的内容,一份是自己使用公钥加密的,一份是第一台机器使用私钥加密传过来的;
5、公钥和私钥是通过一定的算法计算出来的,这时第二台机器就会对比这两份加密之后的内容是否匹配。如果匹配,第二台机器就会认为第一台机器是可信的,就允许登录。如果不相等 就认为是非法的机器。
rsa(rivest-shamir-adleman)是一种非对称加密算法,公钥和私钥成对生成并可以用于加密和解密。工作原理:
- 密钥生成:用户选择两个大素数p和q,并计算它们的乘积n=pq,这将是公钥的一部分。然后,计算欧拉函数φ(n)=(p-1)(q-1),选取一个与φ(n)互质的整数e(通常为一个小于φ(n)且大于1的整数),公钥包含n和e。私钥则包含n和d(满足d*e ≡ 1 mod φ(n)),这样任何知道d的人都可以解密。
- 加密:使用接收者的公钥(n和e)进行加密。消息被转换为数字m,通过取模运算(m^e) mod n得到密文c。
- 解密:只有拥有私钥的人才能解密,使用私钥中的d,通过计算(c^d) mod n得到原始消息m。
# 使用rsa对ssh加密
# 执行这个命令以后,需要连续按 4 次回车键回到 linux 命令行才表示这个操作执行结束,在按回车的时候不需要输入任何内容。
[root@bigdata01 ~]# ssh-keygen -t rsa
generating public/private rsa key pair.
enter file in which to save the key (/root/.ssh/id_rsa):
enter passphrase (empty for no passphrase):
enter same passphrase again:
your identification has been saved in /root/.ssh/id_rsa.
your public key has been saved in /root/.ssh/id_rsa.pub.
the key fingerprint is:
sha256:i8j8rdun4bklmx9t45srskau7fvp2hqtriyuquqf1q4 root@bigdata01
the key's randomart image is:
+---[rsa 2048]----+
| o . |
| o o o . |
| o.. = o o |
| +o* o * o |
|..=.= b s = |
|.o.o o b = . |
|o.o . +.o . |
|.e.o.=...o |
| .o+=*.. |
+----[sha256]-----+
# 执行以后会在~/.ssh目录下生产对应的公钥和私钥文件
[root@bigdata01 ~]# ll ~/.ssh/
total 12
-rw-------. 1 root root 1679 apr 7 16:39 id_rsa
-rw-r--r--. 1 root root 396 apr 7 16:39 id_rsa.pub
# 在bigdata01上执行
[root@bigdata01 ~]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# 在主节点 bigdata01机器上执行下面命令,将公钥信息拷贝到从节点bigdata02
[root@bigdata01 ~]# scp ~/.ssh/authorized_keys bigdata02:~/
the authenticity of host 'bigdata02 (192.168.182.101)' can't be established.
ecdsa key fingerprint is sha256:uug2qrwrlzxcwfv6guot9dvs9c+ifugz7fhr89m2s00.
ecdsa key fingerprint is md5:82:9d:01:51:06:a7:14:24:a9:16:3d:a1:5e:6d:0d:16.
are you sure you want to continue connecting (yes/no)? yes
warning: permanently added 'bigdata02,192.168.182.101' (ecdsa) to the list of known hosts.
root@bigdata02's password:
authorized_keys 100% 396 506.3kb/s 00:00
# # 在主节点 bigdata01机器上执行下面命令,将公钥信息拷贝到从节点bigdata03
[root@bigdata01 ~]# scp ~/.ssh/authorized_keys bigdata03:~/
the authenticity of host 'bigdata03 (192.168.182.102)' can't be established.
ecdsa key fingerprint is sha256:uug2qrwrlzxcwfv6guot9dvs9c+ifugz7fhr89m2s00.
ecdsa key fingerprint is md5:82:9d:01:51:06:a7:14:24:a9:16:3d:a1:5e:6d:0d:16.
are you sure you want to continue connecting (yes/no)? yes
warning: permanently added 'bigdata03,192.168.182.102' (ecdsa) to the list of known hosts.
root@bigdata03's password:
authorized_keys 100% 396 606.1kb/s 00:00
# 在bigdata02上执行
[root@bigdata02 ~]# cat ~/authorized_keys >> ~/.ssh/authorized_keys
# 在bigdata03上执行
[root@bigdata03 ~]# cat ~/authorized_keys >> ~/.ssh/authorized_keys
# 验证bigdata01免密登陆bigdata02
[root@bigdata01 ~]# ssh bigdata02
last login: tue apr 7 21:33:58 2020 from bigdata01
[root@bigdata02 ~]# exit
logout
connection to bigdata02 closed.
# # 验证bigdata01免密登陆bigdata03
[root@bigdata01 ~]# ssh bigdata03
last login: tue apr 7 21:17:30 2020 from 192.168.182.1
[root@bigdata03 ~]# exit
logout
connection to bigdata03 closed.
[root@bigdata01 ~]#
没必要实现从节点之间互相免密登录,因为在启动集群的时候只有主节点需要远程连接其它节点。
安装jdk及环境变量
# 解压jdk安装包
[root@bigdata01 ~]# cd /data/soft
[root@bigdata01 soft]# tar -zxvf jdk-8u202-linux-x64.tar.gz
# 重命名为jdk1.8
[root@bigdata01 soft]# mv jdk1.8.0_202 jdk1.8
# 配置环境变量 java_home
[root@bigdata01 soft]# vi /etc/profile
.....
export java_home=/data/soft/jdk1.8
export path=.:$java_home/bin:$path
# 验证
[root@bigdata01 soft]# source /etc/profile
[root@bigdata01 soft]# java -version
java version "1.8.0_202"
java(tm) se runtime environment (build 1.8.0_202-b08)
java hotspot(tm) 64-bit server vm (build 25.202-b08, mixed mode)
集群节点之间时间同步
集群只要涉及到多个节点的就需要对这些节点做时间同步,如果节点之间时间不同步相差太多,会应该集群的稳定性,甚至导致集群出问题。
使用ntpdate -u ntp.sjtu.edu.cn实现时间同步
# 默认是没有ntpdate命令的,需要使用yum在线安装
[root@bigdata01 ~]# ntpdate -u ntp.sjtu.edu.cn
-bash: ntpdate: command not found
# 安装ntpdate
[root@bigdata01 ~]# yum install -y ntpdate
loaded plugins: fastestmirror
loading mirror speeds from cached hostfile
* base: mirrors.cn99.com
* extras: mirrors.cn99.com
* updates: mirrors.cn99.com
base | 3.6 kb 00:00
extras | 2.9 kb 00:00
updates | 2.9 kb 00:00
resolving dependencies
--> running transaction check
---> package ntpdate.x86_64 0:4.2.6p5-29.el7.centos will be installed
--> finished dependency resolution
dependencies resolved
===============================================================================
package arch version repository size
===============================================================================
installing:
ntpdate x86_64 4.2.6p5-29.el7.centos base 86 k
transaction summary
===============================================================================
install 1 package
total download size: 86 k
installed size: 121 k
downloading packages:
ntpdate-4.2.6p5-29.el7.centos.x86_64.rpm | 86 kb 00:00
running transaction check
running transaction test
transaction test succeeded
running transaction
installing : ntpdate-4.2.6p5-29.el7.centos.x86_64 1/1
verifying : ntpdate-4.2.6p5-29.el7.centos.x86_64 1/1
installed:
ntpdate.x86_64 0:4.2.6p5-29.el7.centos
complete!
# 执行ntpdate -u ntp.sjtu.edu.cn 确认是否可以正常执行
[root@bigdata01 ~]# ntpdate -u ntp.sjtu.edu.cn
7 apr 21:21:01 ntpdate[5447]: step time server 185.255.55.20 offset 6.252298 sec
# 建议把这个同步时间的操作添加到linux的crontab定时器中,每分钟执行一次
[root@bigdata01 ~]# vi /etc/crontab
* * * * * root /usr/sbin/ntpdate -u ntp.sjtu.edu.cn
# 在bigdata02和bigdata03节点上配置时间同步
[root@bigdata02 ~]# yum install -y ntpdate
[root@bigdata02 ~]# vi /etc/crontab
* * * * * root /usr/sbin/ntpdate -u ntp.sjtu.edu.cn
[root@bigdata03 ~]# yum install -y ntpdate
[root@bigdata03 ~]# vi /etc/crontab
* * * * * root /usr/sbin/ntpdate -u ntp.sjtu.edu.cn
集群中三个节点的基础环境就都配置完毕了,接下来就需要在这三个节点中安装hadoop了。
安装hadoop
1、把hadoop-3.2.0.tar.gz安装包上传到/data/soft目录下
# 把hadoop-3.2.0.tar.gz安装包上传到/data/soft
[root@bigdata01 soft]# ll
total 527024
-rw-r--r--. 1 root root 345625475 jul 19 2019 hadoop-3.2.0.tar.gz
drwxr-xr-x. 7 10 143 245 dec 16 2018 jdk1.8
-rw-r--r--. 1 root root 194042837 apr 6 23:14 jdk-8u202-linux-x64.tar.gz
2、解压hadoop安装包
# 在bigdata01上解压hadoop安装包
[root@bigdata01 soft]# tar -zxvf hadoop-3.2.0.tar.gz
3、修改hadoop相关配置文件
- hadoop-env.sh,在文件末尾增加环境变量信息;
- core-site.xml,fs.defaultfs属性中的主机名需要和主节点的主机名或者静态ip保持一致;
- hdfs-site.xml文件,把hdfs中文件副本的数量设置为2,因为现在集群中有两个从节点,dfs.namenode.secondary.http-address设置为secondarynamenode进程所在的节点信息;
- mapred-site.xml,设置mapreduce使用的资源调度框架yarn;
- yarn-site.xml,设置yarn上支持运行的服务和环境变量白名单,还需要设置resourcemanager的hostname,否则nodemanager找不到resourcemanager节点
- workers文件,增加所有从节点的主机名,一个一行
- start-dfs.sh,stop-dfs.sh,添加hdfs的datanode、namenode用户
hdfs_datanode_user、hdfs_datanode_secure_user、hdfs_namenode_user、hdfs_namenode_user、hdfs_secondarynamenode_user; - start-yarn.sh,stop-yarn.sh,添加yarn的resourcemaneger、nodemanger用户
yarn_resourcemanager_user、hadoop_secure_dn_user、yarn_nodemanager_user;
# 修改hadoop相关配置文件
[root@bigdata01 soft]# cd hadoop-3.2.0/etc/hadoop/
# 首先修改hadoop-env.sh文件,在文件末尾增加环境变量信息
[root@bigdata01 hadoop]# vi hadoop-env.sh
export java_home=/data/soft/jdk1.8
export hadoop_log_dir=/data/hadoop_repo/logs/hadoop
# 修改core-site.xml文件
# 注意fs.defaultfs属性中的主机名需要和主节点的主机名或者静态ip保持一致
[root@bigdata01 hadoop]# vi core-site.xml
<configuration>
<property>
<name>fs.defaultfs</name>
<value>hdfs://bigdata01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop_repo</value>
</property>
</configuration>
# 修改hdfs-site.xml文件
# 把hdfs中文件副本的数量设置为2,最多为2,因为现在集群中有两个从节点
# secondarynamenode进程所在的节点信息
[root@bigdata01 hadoop]# vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata01:50090</value>
</property>
</configuration>
# 修改mapred-site.xml
# 设置mapreduce使用的资源调度框架
[root@bigdata01 hadoop]# vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
# 修改yarn-site.xml,设置yarn上支持运行的服务和环境变量白名单
# 注意,针对分布式集群在这个配置文件中还需要设置resourcemanager的hostname,否则nodemanager找不到resourcemanager节点。
[root@bigdata01 hadoop]# vi yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>java_home,hadoop_common_home,hadoop_hdfs_home,hadoop_conf_dir,classpath_prepend_distcache,hadoop_yarn_home,hadoop_mapred_home</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata01</value>
</property>
</configuration>
# 修改workers文件
# 增加所有从节点的主机名,一个一行
[root@bigdata01 hadoop]# vi workers
bigdata02
bigdata03
# 修改启动脚本
# 修改start-dfs.sh,stop-dfs.sh这两个脚本文件,在文件前面增加如下内容
[root@bigdata01 hadoop]# cd /data/soft/hadoop-3.2.0/sbin
[root@bigdata01 sbin]# vi start-dfs.sh
hdfs_datanode_user=root
hdfs_datanode_secure_user=hdfs
hdfs_namenode_user=root
hdfs_secondarynamenode_user=root
[root@bigdata01 sbin]# vi stop-dfs.sh
hdfs_datanode_user=root
hdfs_datanode_secure_user=hdfs
hdfs_namenode_user=root
hdfs_secondarynamenode_user=root
# 修改start-yarn.sh,stop-yarn.sh这两个脚本文件,在文件前面增加如下内容
[root@bigdata01 sbin]# vi start-yarn.sh
yarn_resourcemanager_user=root
hadoop_secure_dn_user=yarn
yarn_nodemanager_user=root
[root@bigdata01 sbin]# vi stop-yarn.sh
yarn_resourcemanager_user=root
hadoop_secure_dn_user=yarn
yarn_nodemanager_user=root
4、把bigdata01节点上将修改好配置的安装包拷贝到其他两个从节点
[root@bigdata01 sbin]# cd /data/soft/
[root@bigdata01 soft]# scp -rq hadoop-3.2.0 bigdata02:/data/soft/
[root@bigdata01 soft]# scp -rq hadoop-3.2.0 bigdata03:/data/soft/
5、格式化hdfs
# 在bigdata01节点上格式化hdfs
[root@bigdata01 soft]# cd /data/soft/hadoop-3.2.0
[root@bigdata01 hadoop-3.2.0]# bin/hdfs namenode -format
# 如果在后面的日志信息中能看到这一行,则说明namenode格式化成功。
common.storage: storage directory /data/hadoop_repo/dfs/name has been successfully formatted.
6、启动集群
# 在主节点 bigdata01上执行下面命令
[root@bigdata01 hadoop-3.2.0]# sbin/start-all.sh
starting namenodes on [bigdata01]
last login: tue apr 7 21:03:21 cst 2020 from 192.168.182.1 on pts/2
starting datanodes
last login: tue apr 7 22:15:51 cst 2020 on pts/1
bigdata02: warning: /data/hadoop_repo/logs/hadoop does not exist. creating.
bigdata03: warning: /data/hadoop_repo/logs/hadoop does not exist. creating.
starting secondary namenodes [bigdata01]
last login: tue apr 7 22:15:53 cst 2020 on pts/1
starting resourcemanager
last login: tue apr 7 22:15:58 cst 2020 on pts/1
starting nodemanagers
last login: tue apr 7 22:16:04 cst 2020 on pts/1
# 验证
# 在bigdata01上查看java进程,是否存在namenode、resourcemanager、secondarynamenode
[root@bigdata01 hadoop-3.2.0]# jps
6128 namenode
6621 resourcemanager
6382 secondarynamenode
# 在bigdata02上查看java进程,是否存在nodemanager、datanode
[root@bigdata02 ~]# jps
2385 nodemanager
2276 datanode
# 在bigdata03上查看java进程,是否存在nodemanager、datanode
[root@bigdata03 ~]# jps
2326 nodemanager
2217 datanode
# 停止集群
# 在主节点bigdata01上执行停止命令
[root@bigdata01 hadoop-3.2.0]# sbin/stop-all.sh
stopping namenodes on [bigdata01]
last login: tue apr 7 22:21:16 cst 2020 on pts/1
stopping datanodes
last login: tue apr 7 22:22:42 cst 2020 on pts/1
stopping secondary namenodes [bigdata01]
last login: tue apr 7 22:22:44 cst 2020 on pts/1
stopping nodemanagers
last login: tue apr 7 22:22:46 cst 2020 on pts/1
stopping resourcemanager
last login: tue apr 7 22:22:50 cst 2020 on pts/1
具体安装详情说明可查阅hadoop官网
还可以通过webui界面来验证集群服务是否正常
hdfs webui界面:http://主节点ip:9870
yarn webui界面:http://主节点ip:8088
hadoop的客户端节点
在实际工作中不建议直接连接集群中的节点来操作集群,直接把集群中的节点暴露给普通开发人员是不安全的,建议在业务机器上安装hadoop,只需要保证业务机器上的hadoop的配置和集群中的配置保持一致即可,这样就可以在业务机器上操作hadoop集群了,此机器就称为是hadoop的客户端节点,hadoop的客户端节点可能会有多个,理论上是我们想要在哪台机器上操作hadoop集群就可以把这台机器配置为hadoop集群的客户端节点。
发表评论