目录
引言
metaai提出的能够“分割一切”的视觉基础大模型sam提供了很好的分割效果,为探索视觉大模型提供了一个新的方向。虽然sam的效果很好,但由于sam的backbone使用了vit,导致推理时显存的占用较多,推理速度偏慢,对硬件的要求较高,在项目应用上有很大的限制。
sam的详细讲解:
一些研究在尝试解决这个问题,其中一个是清华团队的expedit-sam,对模型进行加速,论文结果最多可以提速1.5倍。主要思路是用2个不需要参数的操作:token clustering layer和token reconstruction layer。token clustering layer通过聚类将高分辨率特征转到低分辨率,推理时用低分辨率的进行卷积等操作,这样可以加速推理时间;token reconstruction layer是将低分辨率特征重新转回高分辨率。个人测试好像没有明显提升,不过已经打开了sam推理加速的思路。
1 fastsam介绍
1.1 fastsam诞生
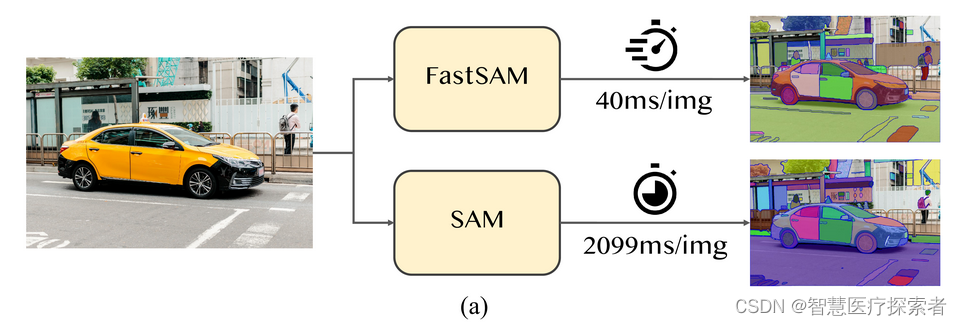
最近发布的fastsam(fast segment anything),论文结果最快提升50倍,参数更少,显存占用减少,适合应用部署。
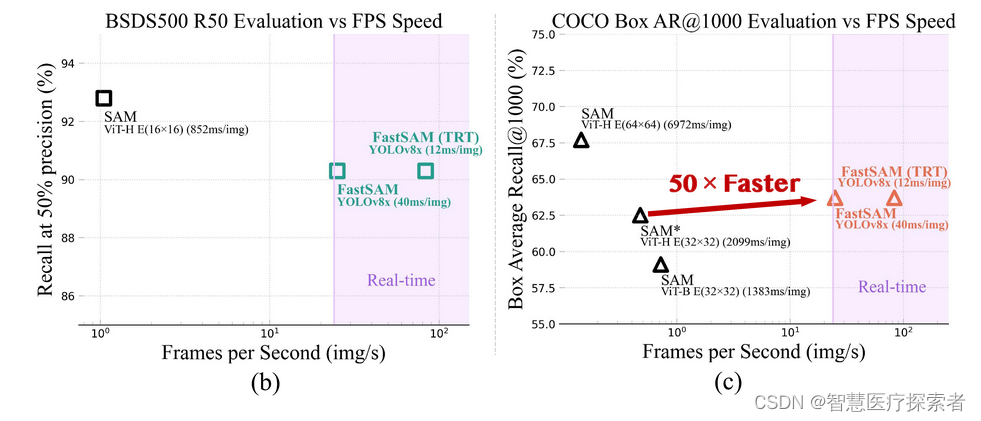
fastsam是基于yolov8-seg的,这是一个配备了实例分割分支的对象检测器,它利用了yolact 方法。作者还采用了由sam发布的广泛的sa-1b数据集。通过直接在仅2%(1/50)的sa-1b数据集上训练这个cnn检测器,它实现了与sam相当的性能,但大大减少了计算和资源需求,从而实现了实时应用。作者还将其应用于多个下游分割任务,以显示其泛化性能。在ms coco的对象检测任务上,在ar1000上实现了63.7,比32×32点提示输入的sam高1.2分,在nvidia rtx 3090上运行速度快50倍。
实时sma对工业应用都是有价值的。它可以应用于许多场景。所提出的方法不仅为大量的视觉任务提供了一种新的、实用的解决方案,而且它的速度非常高,比目前的方法快数十或数百倍。它还为一般视觉任务的大型模型架构提供了新的用途。作者认为,对于专业的任务,专业的模型具备更好的效率和准确性的权衡。然后,在模型压缩的意义上,fastsam的方法证明了一个路径的可行性,通过引入一个人工的结构,可以显著减少计算工作量。
论文地址:https://arxiv.org/pdf/2306.12156.pdf
代码地址:https://github.com/casia-iva-lab/fastsam
web demo:https://huggingface.co/spaces/an-619/fastsam
1.2 模型算法
以yolov8-seg的instance segmentation为基础,检测时集成instance segmentation分支。

fastsam主要分成2步:全实例分割(all instance segmentation)和基于prompt的mask输出(prompt-guided selection)。
- 模型:基于yolov8-seg的模型.
- 实例分割:yolov8-seg实现了实例分割,结果包含了检测和分割分支。检测分支输出box和类别cls,检测分支输出k(默认为32)个mask分数,检测和分割分支是并行的。看推理代码的模型,这块其实就是yolov8的segment网络,具体可以看yolov8的segment训练代码。
利用prompt挑选出感兴趣的特点目标,类似sam,支持point/box/text。
- point prompt:点prompt用点和实例分割输出的mask进行匹配。和sam一样,利用前景点/背景点作为prompt。如果一个前景点落在多个mask中,可以通过背景点进行过滤。通过使用一组前景/背景点,能够在感兴趣的区域内选择多个mask,然后将这些mask合并为一个mask,用于完整的标记感兴趣的对象。此外,利用形态学操作来提高掩模合并的性能。
- box prompt:与实例分割输出的mask的box和输入的box进行iou计算,利用iou得分过滤mask。
- text prompt:利用clip模型,利用图像编码和文本编码直接的相似性,提取分数较高的mask。因为引入clip模型,text prompt的运行速度比较慢。
1.3 实验结果
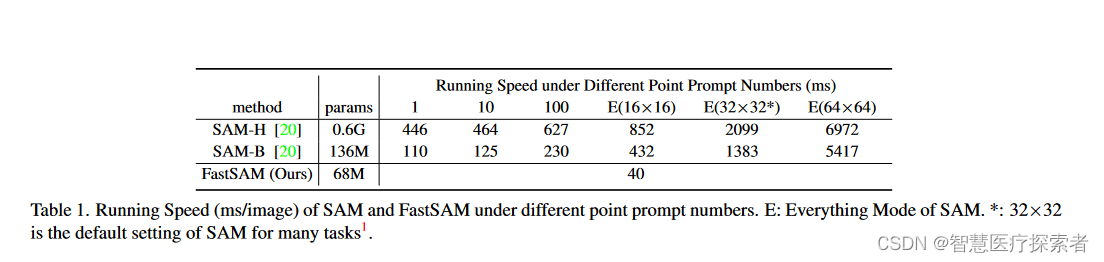
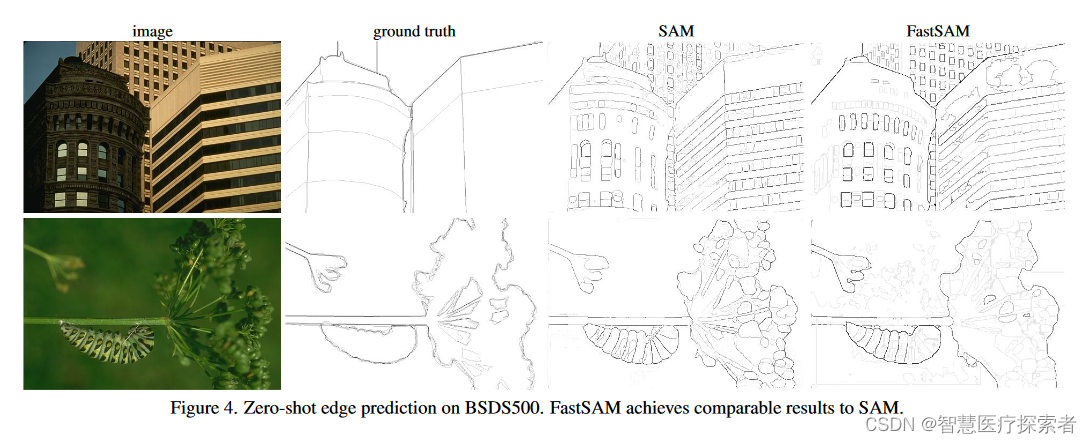
fastsam利用yolov8-x模型;取sa-1b数据集的2%进行监督训练;为了检测更大的instance,将yolov8的reg_max参数从16改成26;输入图像的size为1024。在4种级别的任务上与sam的zero-shot对比:边缘检测、目标proposal、实例分割、提示输入分割。





2 fastsam运行环境构建
2.1 conda环境构建
conda环境准备详见:
2.2 运行环境安装
conda create -n fastsam python=3.9
conda activate fastsam
git clone https://ghproxy.com/https://github.com/casia-iva-lab/fastsam.git
cd fastsam
pip install -r requirements.txt
pip install git+https://ghproxy.com/https://github.com/openai/clip.git
pip install gradio==3.40.1 -i https://mirrors.aliyun.com/pypi/simple/2.3 模型下载
创建模型保存模型的目录weights
mkdir weights模型下载地址:模型
模型下载后,存储到weights目录下
(fastsam) [root@localhost fastsam]# ll weights/
总用量 141548
-rw-r--r-- 1 root root 144943063 8月 21 16:28 fastsam_x.pt3 fastsam运行
原始图片如下,通过fastsam对这张图片进行处理

3.1 命令行运行
3.1.1 everything mode
python inference.py --model_path ./weights/fastsam_x.pt --img_path ./images/dogs.jpg
3.1.2 text prompt
python inference.py --model_path ./weights/fastsam_x.pt --img_path ./images/dogs.jpg --text_prompt "the yellow dog"
3.1.3 box prompt (xywh)
python inference.py --model_path ./weights/fastsam_x.pt --img_path ./images/dogs.jpg --box_prompt "[[570,200,230,400]]"
3.1.4 points prompt
python inference.py --model_path ./weights/fastsam_x.pt --img_path ./images/dogs.jpg --point_prompt "[[520,360],[620,300]]" --point_label "[1,0]"
3.2 通过代码调用
vi test.pyfrom fastsam import fastsam, fastsamprompt
model = fastsam('./weights/fastsam_x.pt')
image_path = './images/dogs.jpg'
device = 'cpu'
everything_results = model(image_path, device=device, retina_masks=true, imgsz=1024, conf=0.4, iou=0.9,)
prompt_process = fastsamprompt(image_path, everything_results, device=device)
# everything prompt
ann = prompt_process.everything_prompt()
# bbox default shape [0,0,0,0] -> [x1,y1,x2,y2]
ann = prompt_process.box_prompt(bbox=[200, 200, 300, 300])
# text prompt
ann = prompt_process.text_prompt(text='a photo of a dog')
# point prompt
# points default [[0,0]] [[x1,y1],[x2,y2]]
# point_label default [0] [1,0] 0:background, 1:foreground
ann = prompt_process.point_prompt(points=[[620, 360]], pointlabel=[1])
prompt_process.plot(annotations=ann,output_path='./output/dog.jpg',)python test.py 
3.3 web运行
更改app_gradio.py的代码,更改内容如下
vi app_gradio.py# load the pre-trained model
model = yolo('./weights/fastsam.pt')
更改为
# load the pre-trained model
model = yolo('./weights/fastsam_x.pt')
demo.queue()
demo.launch()
更改为
demo.queue()
demo.launch(share=true)运行web程序
python app_gradio.py 
4 总结
在fastsam模型中,作者重新考虑了segment of anything task和相应模型结构的选择,并提出了一个比sam-vit-h (32×32)运行速度快50倍的替代解决方案。实验结果表明,fastsam可以很好地解决多个下游任务。尽管如此,fastsam仍有几个弱点可以加以改进,比如评分机制和实例面具生成范式。这些问题都留待进一步研究。
发表评论