联邦学习架构:客户端层,骨干层,fl任务层
fl任务层:模型所有者每次只发布一个任务,模型在无人机上进行训练,生成原始数据,然后,在不泄露原始数据的情况下,将本地更新的模型参数传输给模型所有者进行聚合。在集中平台进行参数聚合后,更新后的全局模型响应无人机进行下一轮训练,直到收敛到目标。
骨干层:由无人机簇头组成,每个簇头充当集群的中央聚合服务器,在集群内聚合和更新训练模型;并且执行集群间交互来聚合中间训练结果。本文直接选择了资源较多的节点作为簇头(感觉是不是可以从能量,信任度来考虑簇头的选择问题)
客户端层:对于每个集群,数据可以被认为是同构的,可以将全局优化问题看作针对多个聚类的联合优化问题。其中cfl包括:
- 工人通过下载最后一轮模型w来将任务与簇头h同步
- 无人机进行随机梯度下降来执行多次迭代,tig奥中间模型的性能
![]()
- 簇头h聚合集群内参与者的局部参数,更新新的中间模型
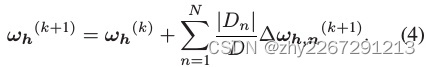
每隔k,簇头发送中间模型参数,模型所有者进行全局聚合,如果不满足训练目标,则将中间模型打回重新进行局部训练。
系统模型:作为任务发布者,模型所有者的目标是通过k迭代 训练模型,使全局损失函数l(w)最小化,其中w表示全局模型参数。
无人机:每个worker都有本地数据样本来说参与dn![]() 来参与聚类联邦学习任务,簇头h的支付取决于相应worker的数据贡献。数据贡献可以定义为pn=dnd
来参与聚类联邦学习任务,簇头h的支付取决于相应worker的数据贡献。数据贡献可以定义为pn=dnd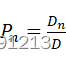 ,考虑到一个集群内的学习过程消耗的计算资源,计算成本可以表示为
,考虑到一个集群内的学习过程消耗的计算资源,计算成本可以表示为
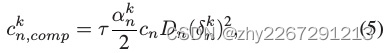
(τ表示一次迭代k期间的轮数,cn表示能量消耗的单位成本。αnk表示工人n的计算芯片组的有效电容参数,其计算能力由cpu决定为δnk)
可以得到在迭代k中计算的时间消耗:
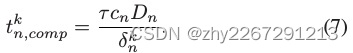
传输和存储消耗的能力:
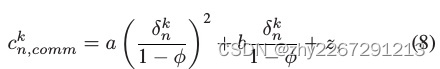
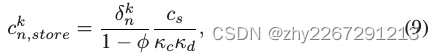
(a、b、z表示通信成本的权重因子。从工人nh到簇头h的资源记为δnk。我们用![]() 表示传输过程中有损耗的能量,其中φ表示传输损失率。符号cs表示存储能量的单位成本。κc和κd分别表示存储数据的无人机的充放电系数)
表示传输过程中有损耗的能量,其中φ表示传输损失率。符号cs表示存储能量的单位成本。κc和κd分别表示存储数据的无人机的充放电系数)
工人n的目标是通过向训练模型出售计算资源,使其效用最大化
![]()
(总资源-计算成本-传输成本-存储成本)
簇头模型
基于无人机局部优化结果相似度的静态无人机群聚类策略:利用分解余弦相似度对高维数据样本进行聚类决策。
通过计算反向传播或模型参数更新,获得无人机学习梯度余弦相似度:
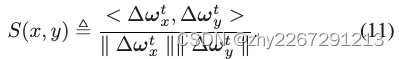
由于数据高维,取余弦相似度的欧式距离,再进行svd分解,将局部模型的更新分解为j个方向,将问题转化为了更新与方向之间的相似性(就是将具有相似学习目标的无人机聚类):
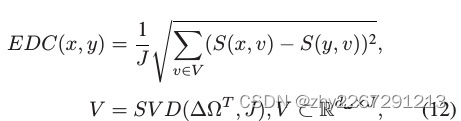
聚类后,可以得到余弦相似度矩阵
![]()
根据边际收益递减的经济规律,当cpu频率的数量增加时,簇头的增量速度效用逐渐减少。
所以将簇头h在第k次迭代中的效用定义为:
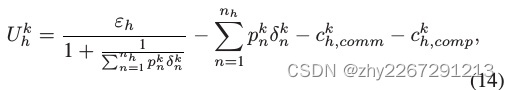
(簇头效用=边际收益-边际成本
边际收益可以解释为每增加一单位资源所带来的总收益的增加;
边际成本可以解释为每增加一单位资源所带来的总成本的增加)
εh表示模型所有者对簇头h的支付,pnk![]() 为购买工人资源的单位成本,工人nh到簇头h的资源记为δnk。
为购买工人资源的单位成本,工人nh到簇头h的资源记为δnk。
解释:边际收益跟边际成本有关系,就好像饿了的时候吃第四碗面的作用不如吃第一碗面的作用大。所以可以把1+εhσn=1nhpnkδnk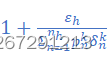 看作边际成本的影响因子,当边际成本越高时,这个因子就越接近1,效用受到的影响越小;反之,当边际成本越低时,这个因子越接近0,效用受到的影响越大。
看作边际成本的影响因子,当边际成本越高时,这个因子就越接近1,效用受到的影响越小;反之,当边际成本越低时,这个因子越接近0,效用受到的影响越大。
模型所有者评估每个集群的资源,并生成奖励分配策略集合ε![]() ,以最小化其成本值:
,以最小化其成本值:
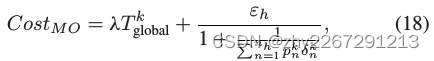
其中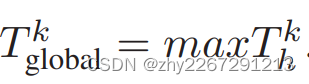 ,thk
,thk![]() 为簇h的fl总耗时。
为簇h的fl总耗时。
三阶段stackelberg博弈:
阶段1
在每次迭代k开始时,簇头h生成最优资源分配pnk![]() 以最大化效用
以最大化效用
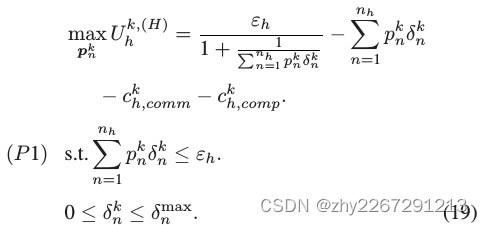
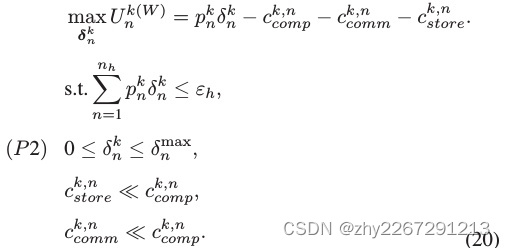
阶段2
每个工人的预期收益由其净效用决定,净效用是跟随簇头所获得的收益与支出之差。
阶段3:由于无人机的cpu能量消耗和时间成本是相互冲突的,考虑到利用资源完成联邦学习的边际效益,模型所有者形成如下的子博弈问题:
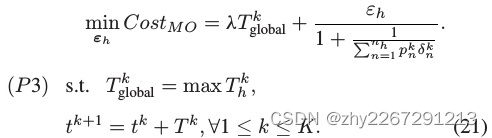
以上三个子博弈构成了一个完整的三阶段stackelberg博弈。
仿真结果分析
数据集:federated extended mnsit(femnist)
将30架无人机构建成不超过5个集群,在初始聚类阶段,局部训练轮次为10次。
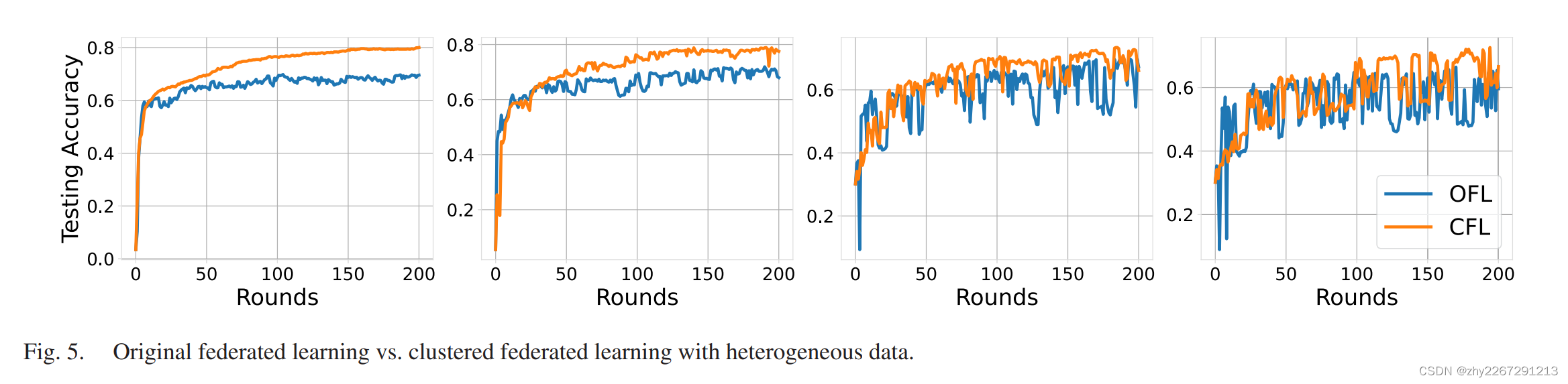
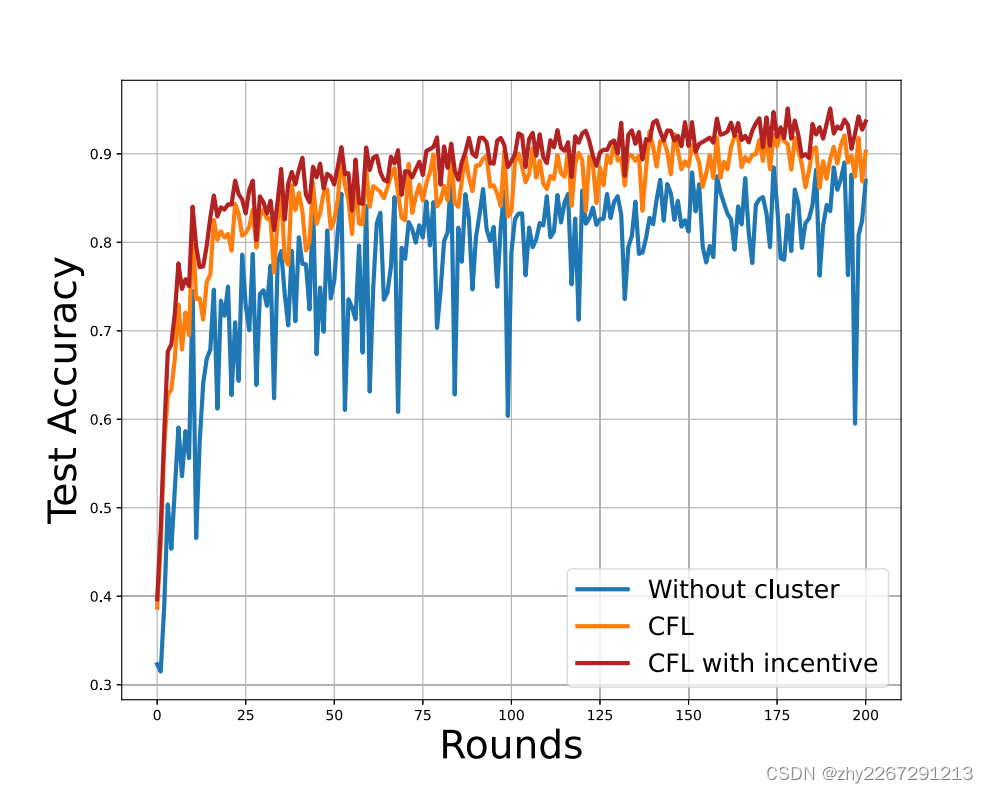
原始联邦学习和聚类联邦学习的对比
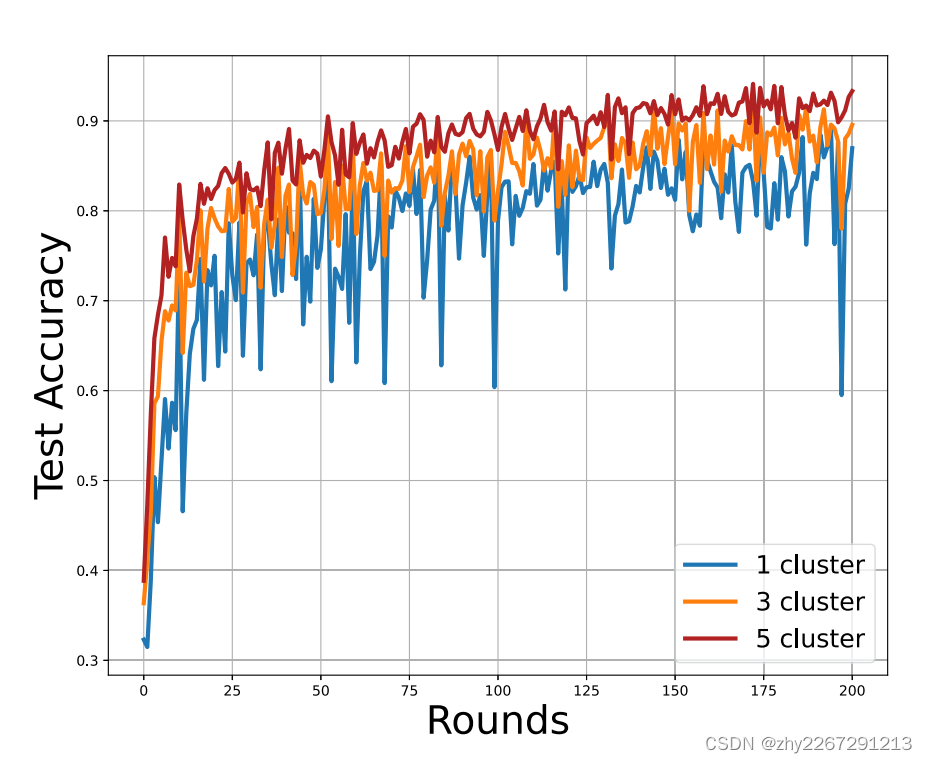
不同簇数的准确率
三种方法的性能对比
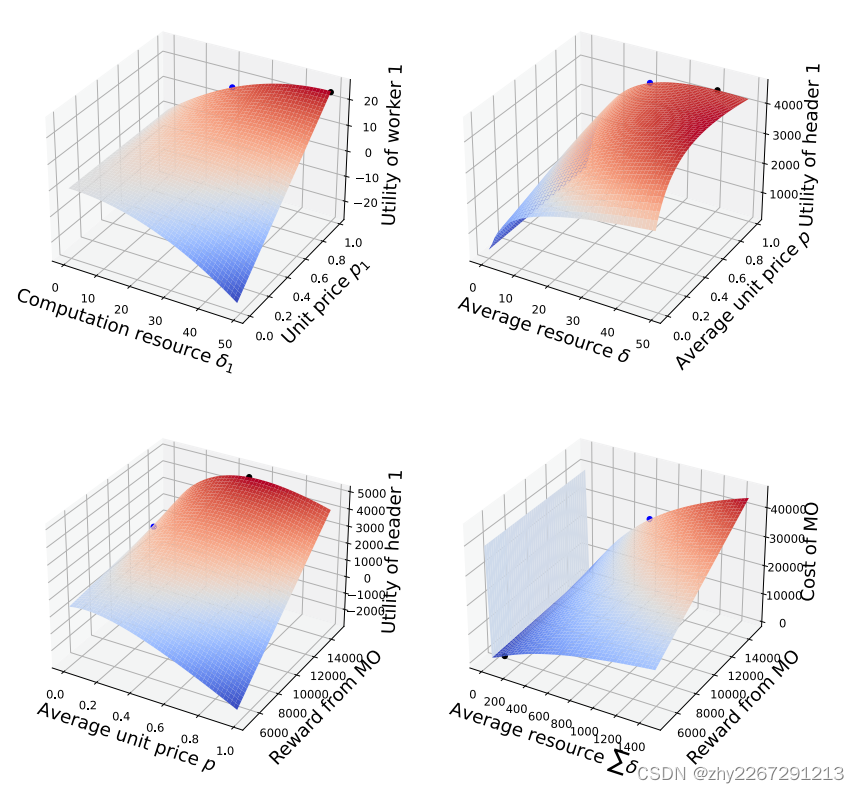
系统模型性能
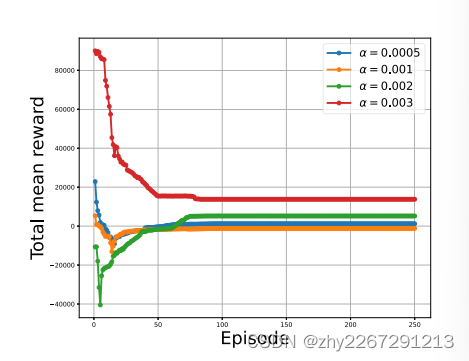
折现因子的影响

学习率的影响
结论
在联邦学习(fl)系统中,解决无人机采集数据的不一致性和由异构数据引起的学习不一致性是一个重大挑战。为了更好地保护本地隐私,提高uav群的分布式学习性能,本文提出了一种聚类fl架构。为了共同优化集群fl系统中任务发布者、集群负责人和uav工作人员的效用,我们将学习和交互建模为三阶段stackelberg博弈,并分析了stackelberg均衡的存在性和唯一性。我们还提出了一种多智能体强化学习算法来搜索博弈的均衡性。实验结果表明,结合三阶段stackelberg博弈的cfl结构可以经济地满足多实体的利益。在资源有限的动态场景下,我们提出的多方博弈辅助cfl架构可以取得很好的性能。然而,每一轮重组的可能性对cfl制度和激励机制提出了重大挑战。在这些资源有限的动态场景下,我们评估了整个系统的可行性和稳定性。我们提出的多方博弈辅助cfl架构在这种情况下表现出很强的性能。


发表评论