【yolov8学习记录】——如何构建数据集用于训练(以目标检测为例)
一、数据集及其构建来源
数据集对于模型算法的训练重要程度在此不加赘述,其质量与规模关系到模型的训练效果。因此这部分的目的就是集成一个具有较高质量与可观规模的训练数据集。通常来说,数据集的构建方式有以下两种:
1、获取开源的高质量数据集
目前有许多大型公司都开源了他们制作的高质量数据集。这些数据集的图片种类非常丰富,且所需检测目标的存在形式非常多样,是很专业的数据集,十分有利于学习。前段时间尝试了许多开源数据集,个人最喜欢的还是google公司开源的open images dataset v7,接下来的获取方式就以此为例。
1.1 open images dataset v7简介
open images dataset v7于22年底发布,包含有20000多个类别的图像级标签。数据集的制定十分细致,在部分图片还有人为涂鸦以增加检测难度,包含训练数据集以及验证数据集。
点击explore,可以找到自己想要的数据集。比如说我想要做船舶的目标检测训练,那么择取的选项如下所示:
选择“训练”,下方为“验证测试”
除了“目标检测”还有“分割”、“视觉关系”(即同时标注人物主体、动作、动作对象,如:woman/throw/ball)、“点级标签”、“图片场景定位及诠释”以及所有注解在内的图片格式。
选择想要的图片类型为“boat”,即可找到船舶的目标检测数据集。
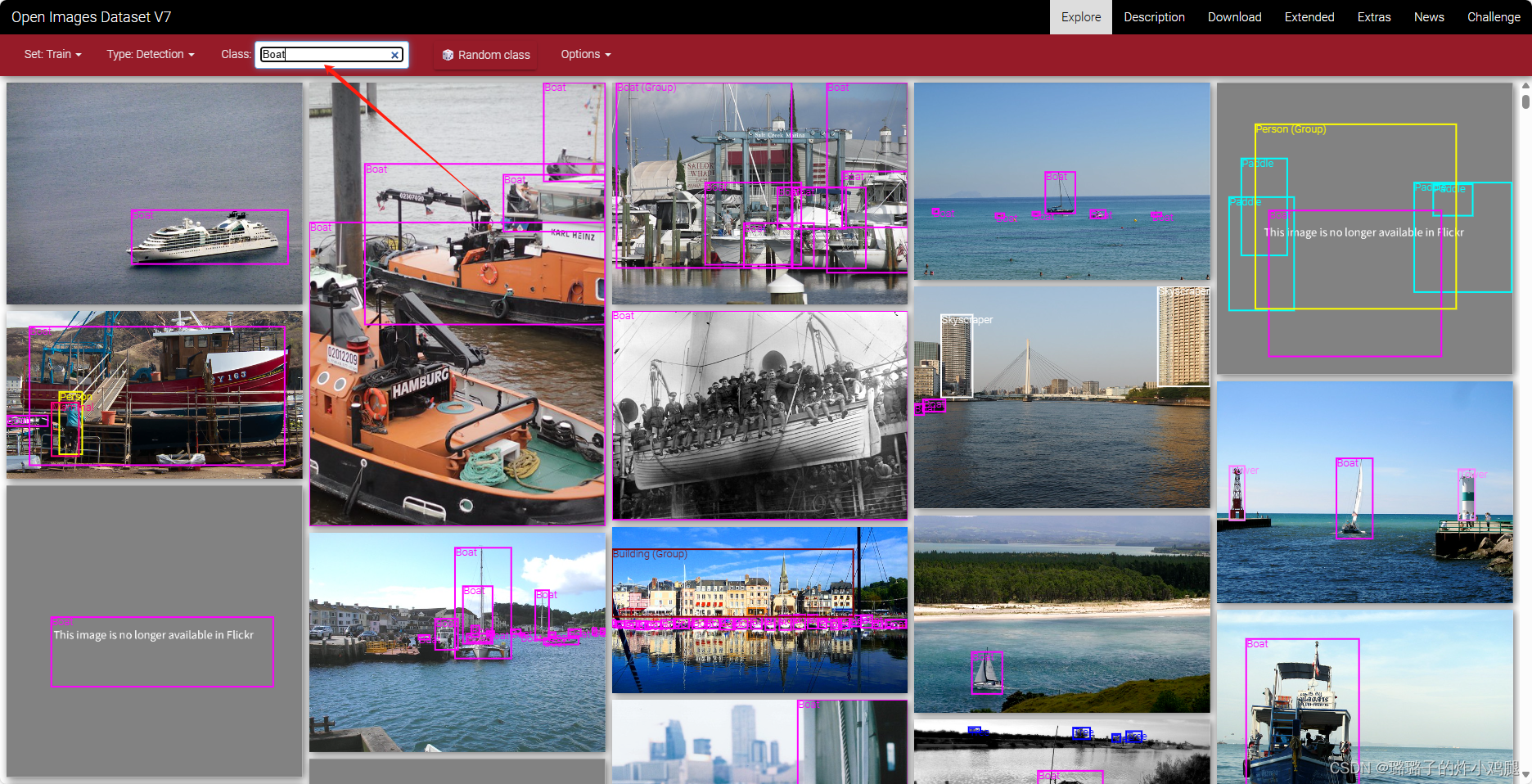
通过勾选该列表,可以现实不同要素标签
1.2 如何下载open images dataset v7的数据集
关于这个问题,官方给了很多选择,详情见下载页面。在这里面还可以下载往期版本的数据集。
个人较为推荐的是采用fiftyone下载,简单方便,并且可以下载除了open images dataset v7之外的许多开源高质量数据集。

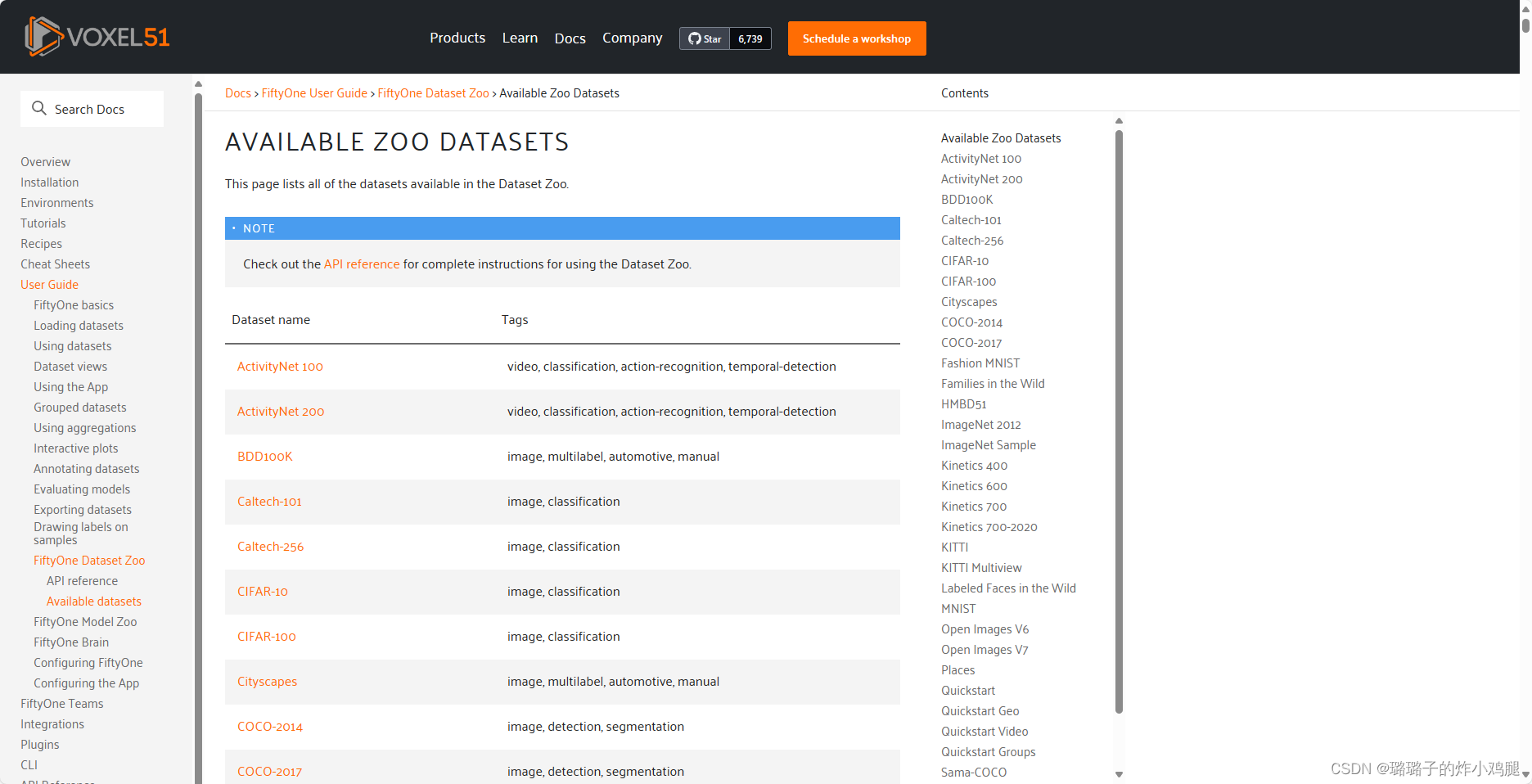
可供fiftyone下载的数据集可见:available zoo datasets — fiftyone 0.23.8 documentation (voxel51.com),该官方文件还给出了不同数据集功能标签的索引,非常方便。
1.2.1 fiftyone的下载及使用
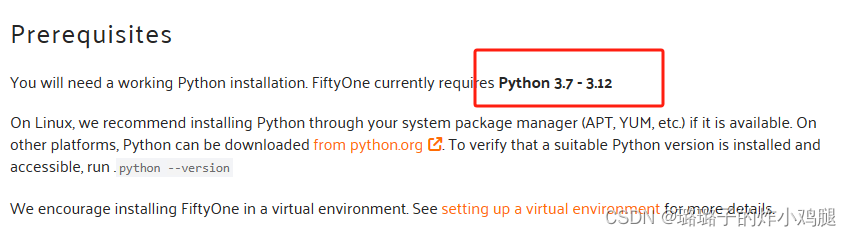
fiftyone除了可以进行进行开源数据库的下载外,还具有lable查找纠错、ml模型的评估等优秀便捷的功能。下载fifty前需要确认python版本是否适配。
如图所示,需要将python升级至3.7及以上的版本。
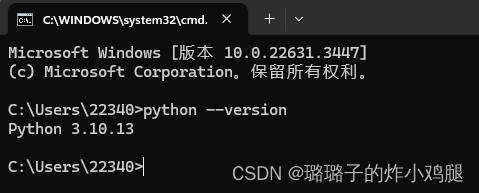
在指令框中输入
python --version
查看python版本是否适配
接着继续在指令窗口中输入
pip install fiftyone
验证是否安装成功
先进入python环境,回车后输入
import fiftyone as fo

要注意的是,成功安装后输入这一段应该是空输出,如官网说明所示:

如果存在问题,官方给出了解决方案,应该是某些包未更新,可以输入以下信息,具体不同系统安装遇到的问题详情可以参考:fiftyone installation — fiftyone 0.23.8 documentation (voxel51.com)
pip install --upgrade pip setuptools wheel
pip install fiftyone
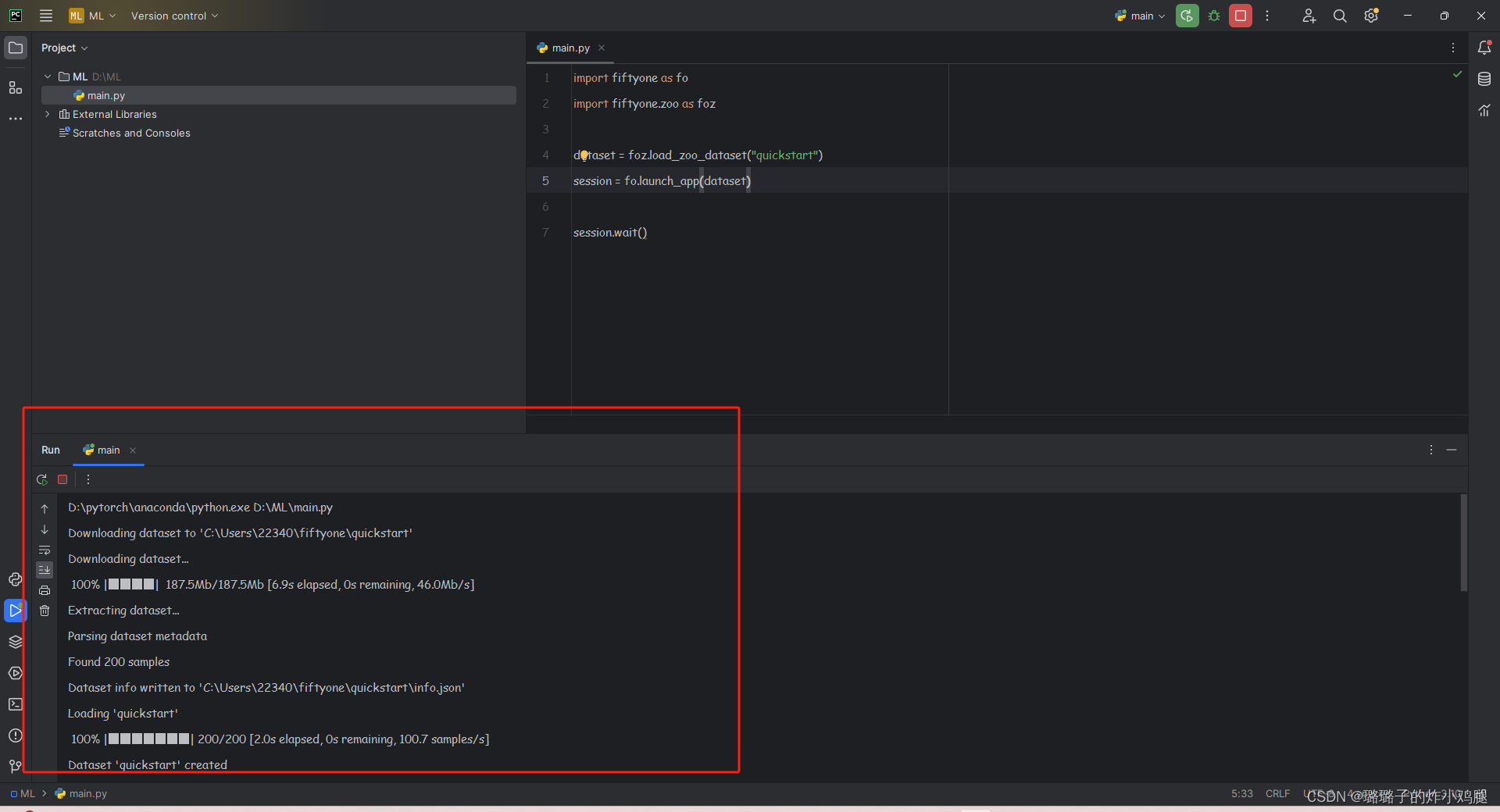
接下来使用fiftyone进行一个小小的测试以快速入手:
import fiftyone as fo
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset("quickstart")
session = fo.launch_app(dataset)
根据官方的建议,我们再加上
session.wait()

这个语句的作用是给我们观察的时间,等到关闭网页或应用时才退出执行,如下说明所示、
可能出现的情况:
**1、找不到urllib3库:**安装符合自己的环境版本的即可,我是安装了最低要求的1.26.4版本。~~如果你装了不对的版本,系统会自己提示你需要至少多少的版本(>=xx版),到时候把不对的版本uninstall然后装对的就可以,~~省的去找了(o( ̄▽ ̄)o)。
pip install urllib3==1.26.4
**2、出现timeout:**科学上网即可(你懂的)
成功之后就会自己打开网页啦,如下所示。
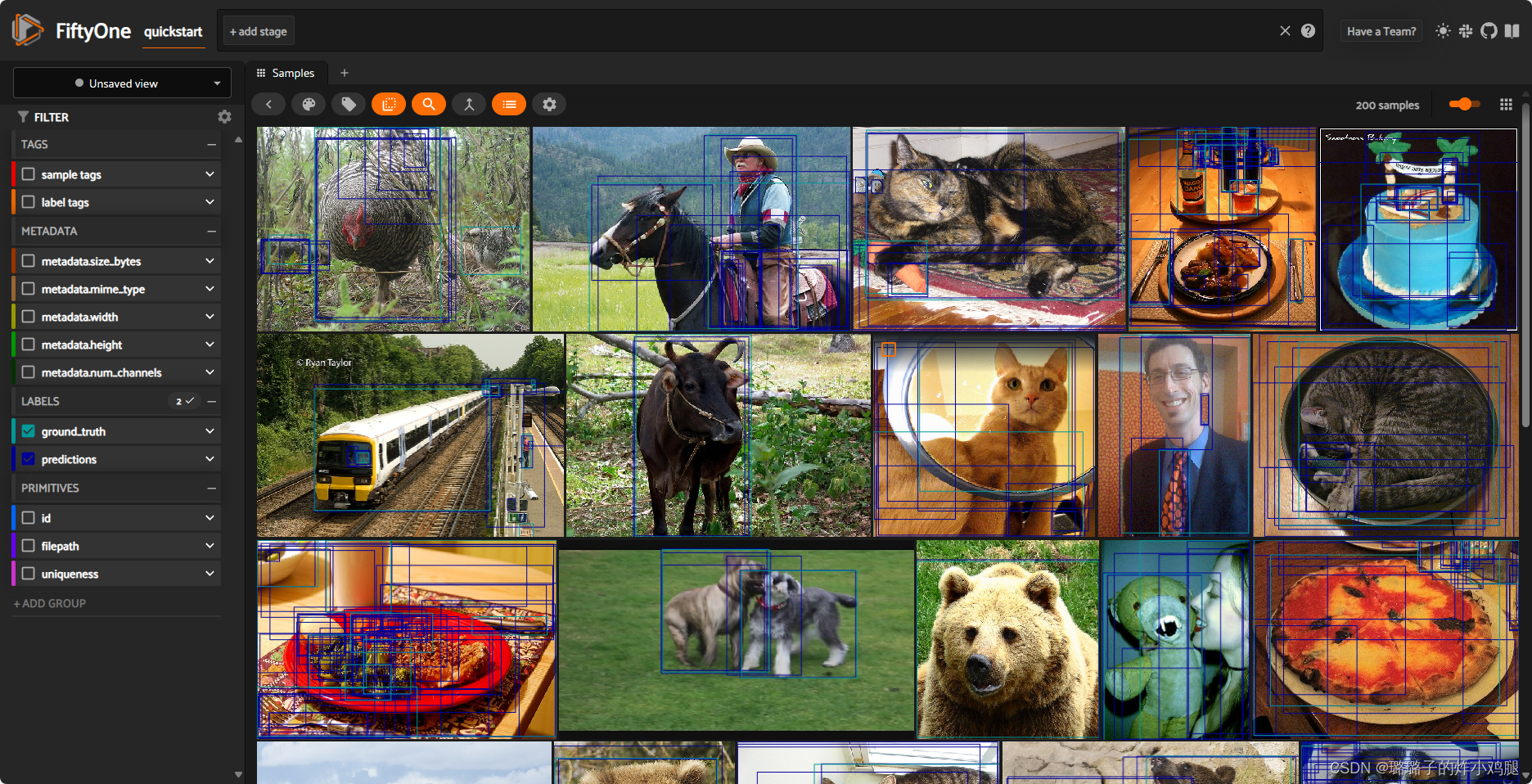
1.2.2 实战——利用fiftyone下载open images dataset v7中所需的数据集
这一步就更简单啦,主要的目的其实还是明确自己的需求(破折号后的根据自己情况而定):
以什么目的进行ml——目标检测
下载的数据集类型——open images dataset v7
下载的样本有几种——一种
下载的样本名称——boat
下载的数量、标签/标签+图片/图片……
在下载数据集时,我们需要对数据集的下载目标进行限制,并规划自己的需求,因此下载的python指令也需要做相应的调整,关于open images dataset v7,fiftyone其实有一系列较为详细的指导文档,详见网址:https://docs.voxel51.com/user_guide/dataset_zoo/datasets.html#open-images-v7,这个页面往上滑就是v6的指导下载。任何包括在fiftyone的dataset.zoo中的数据集(如:coco等)都有相应的指导文档。
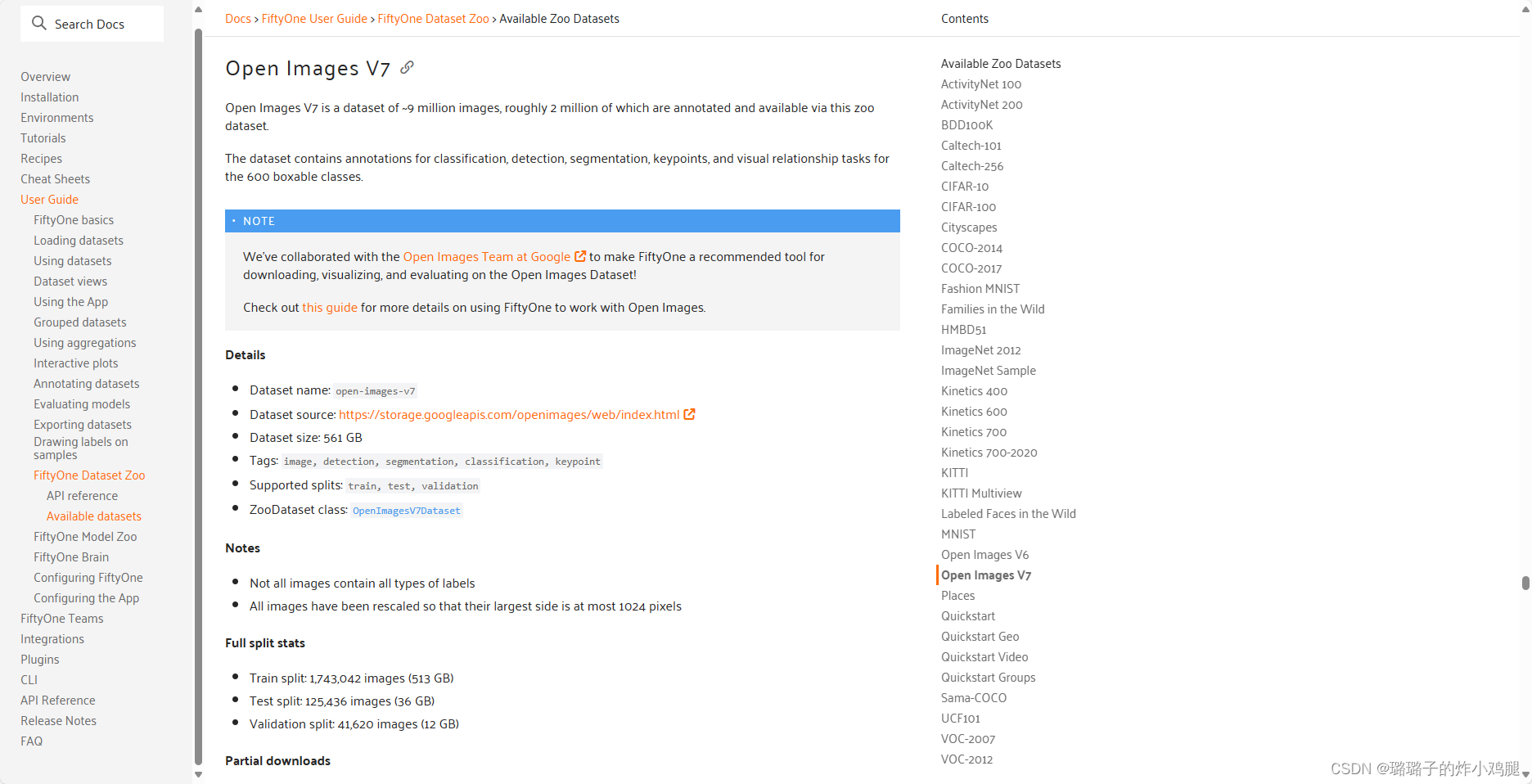
因此,我们在python指令中输入以下代码
if __name__ == "__main__": #防止出错
import fiftyone as fo
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset(
"open-images-v7",
split="train", #训练集,其余分类名称见上文贴的官方指导网址
label_types=["detections"], #检测集,其他分类同上
classes=["boat"], #可以包含多个,注意大小写(这很重要)
shuffle=true, # 随机进行图片取样,防止顺序选择的规律性干扰训练效果
only_matching=true, #只有复合类别的图片才选择
max_samples=10, #下载十张,大家自行选择数量即可
num_workers=1, #防止多线程下载干扰
dataset_dir="d:\ml\dataset_load\data_boat\d_v7", #你想要保存的数据集路径
dataset_name="d_v7", #给自己的数据集起个名字吧!
)
中间可能会卡一段时间,不要轻易退出(我刚开始摸索以为是好了,结果发现很多没有下载到的东西修了半天t t)
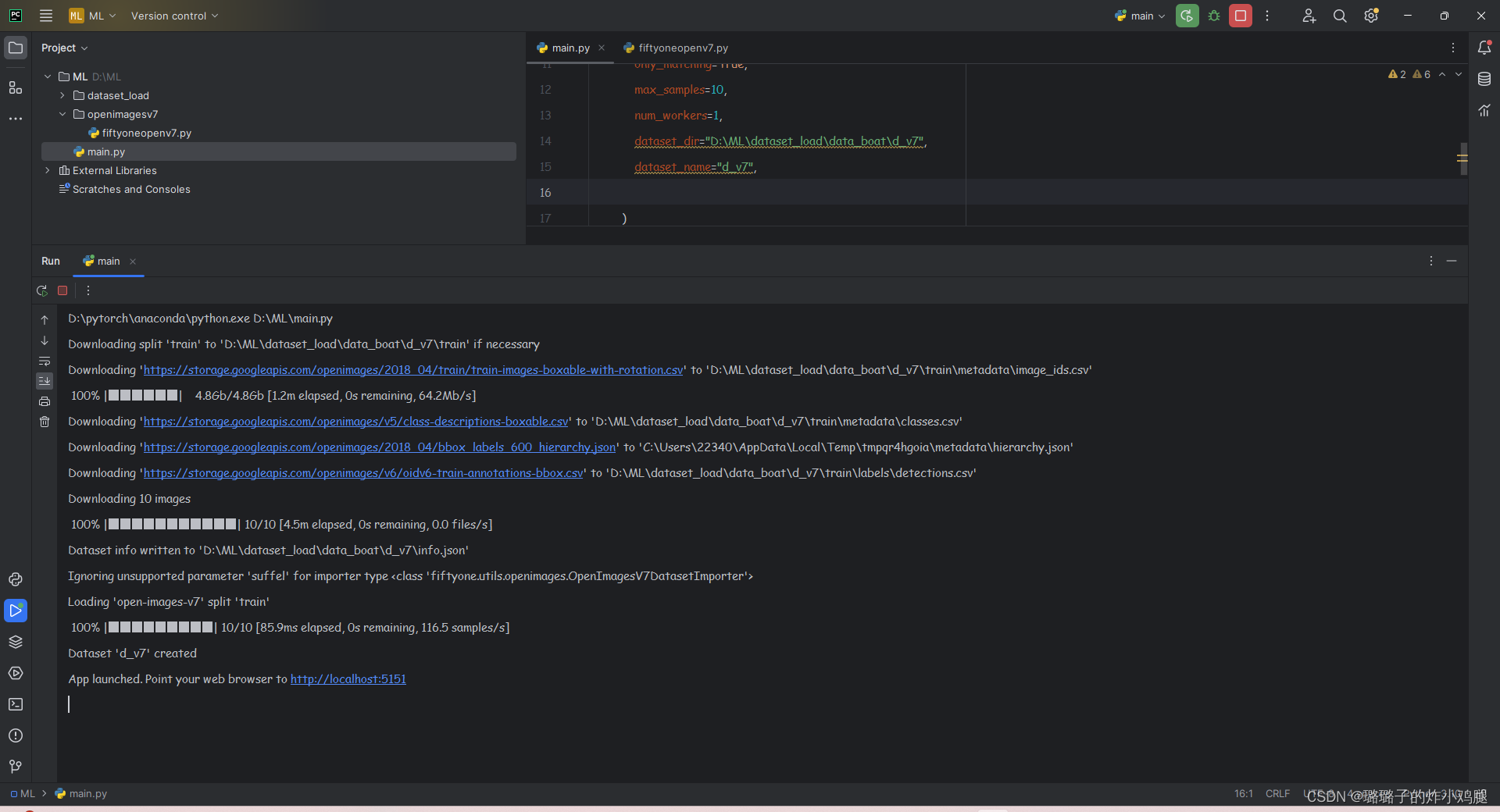
当然,以上示例也提供了一个反面教材,在文中贴出来的代码是更正后的,可以放心复制

之后会自动打开网页可视化
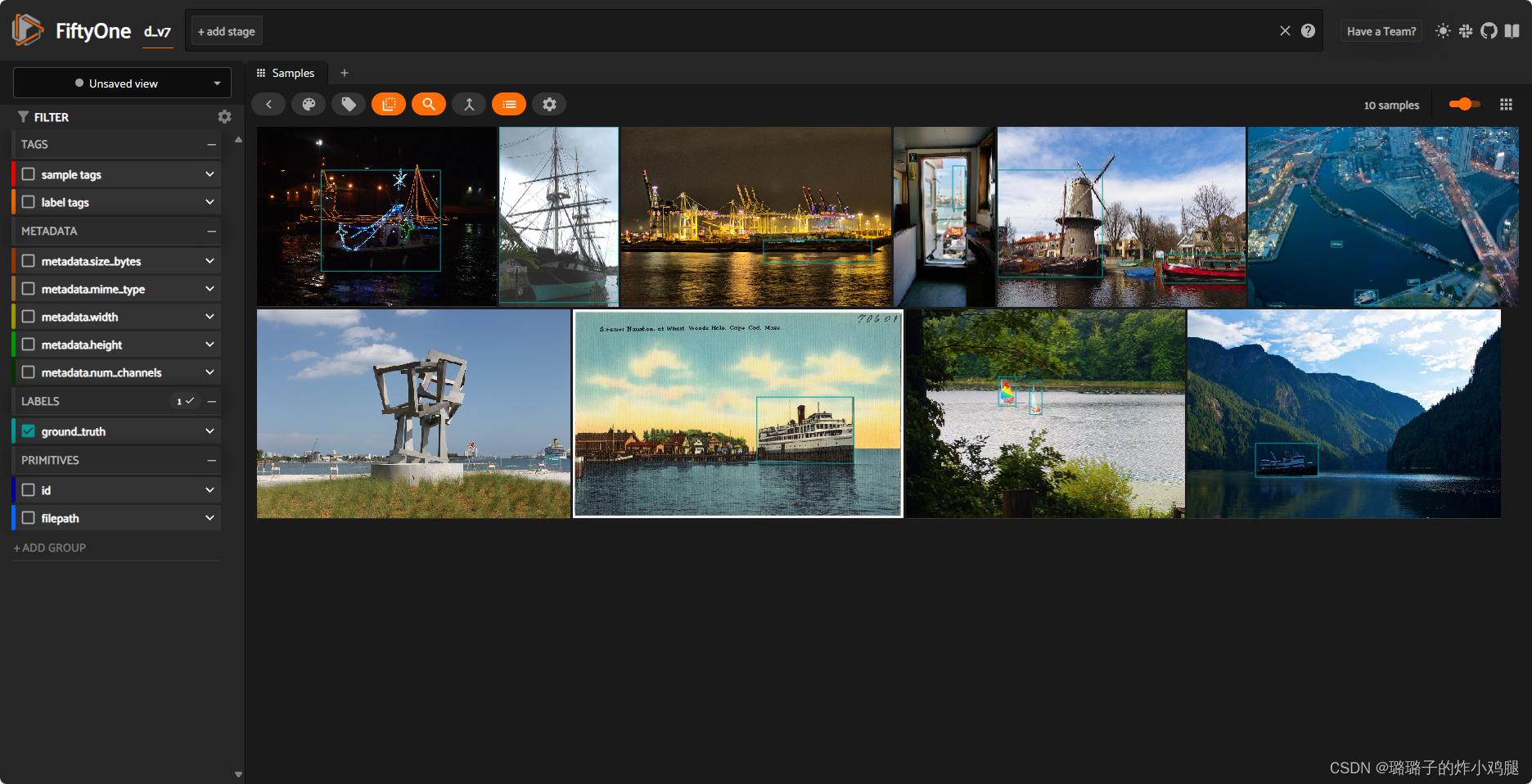
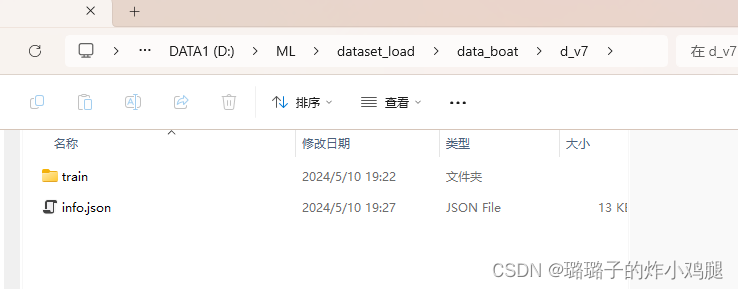
这样就大功告成啦,再看看咱们的本地文件夹
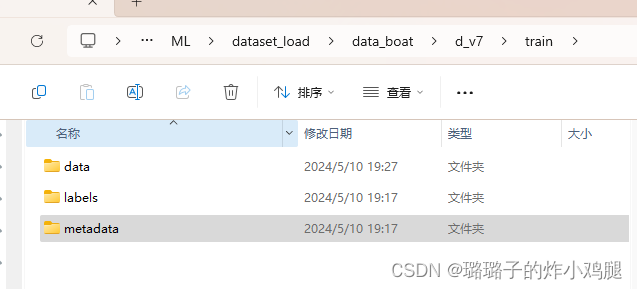
打开train,里面label是标签集,metadata是分类等csv文件保存的地方,data是图片保存的地方,如果你想要构建自己的数据集,也可以利用这些原图哦!(当然记得发表时注意开源数据集的版权)
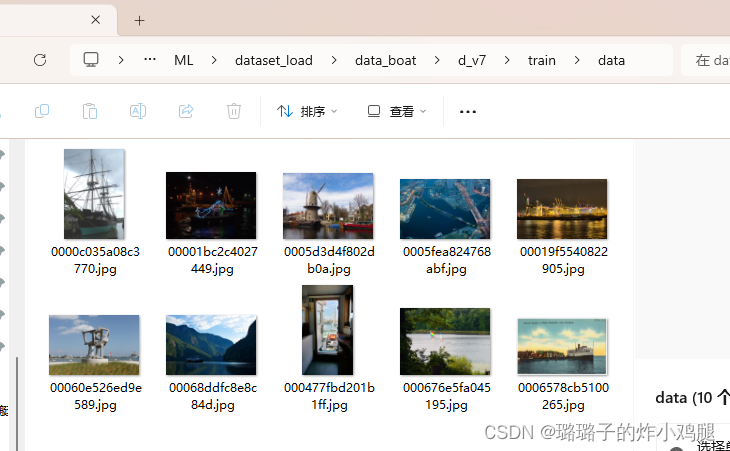
1.3 可能遇到的问题
numpy.core._exceptions._arraymemoryerror: unable to allocate 2.06 gib for an array with shape (5, 55258859) and data type object:是指分配矩阵的空间不够,可以参考该博客的解决方案:分配矩阵空间不够_unable to allocate 226. mib for an array with shap-csdn博客
timeout:科学上网
ignoring unsupported parameter ‘xxx’:是不是名称打错啦?
2. 构建自己的数据集
2.1 选择合适的图片,确定数据集规模
在这里使用open images dataset v7的下载图片作为示例,因此我又多下载了一些,为200张
由于下载过boat类型以及open images dataset v7的部分文件,因此这次下载就简单很多
同样可以看到fiftyone的可视化网页中也增加了许多新图片

这些图片下载到我们的磁盘中有不包含检测框与标签的原图,因此也可以用这些图片自己规划检测框进行操作。
2.2 进行检测框的标注
这里个人比较推荐使用cvat进行标注,这里可以进行免费的设计,对学生党来说是足够的。
由于我直接用github账号登陆,因此这边直接略过注册流程,可以参考其他博客。
首先新建一个项目
点击右下角加号导入图片信息
命名为第一组图片,用于训练,导入两百多张图片
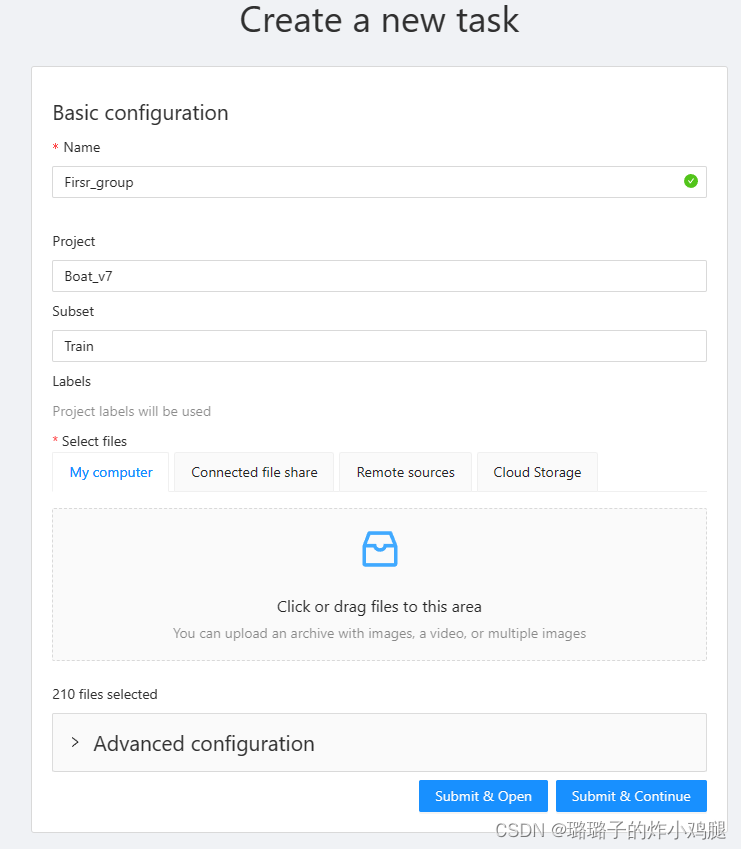
可以看到已经存在有第一组数据集啦
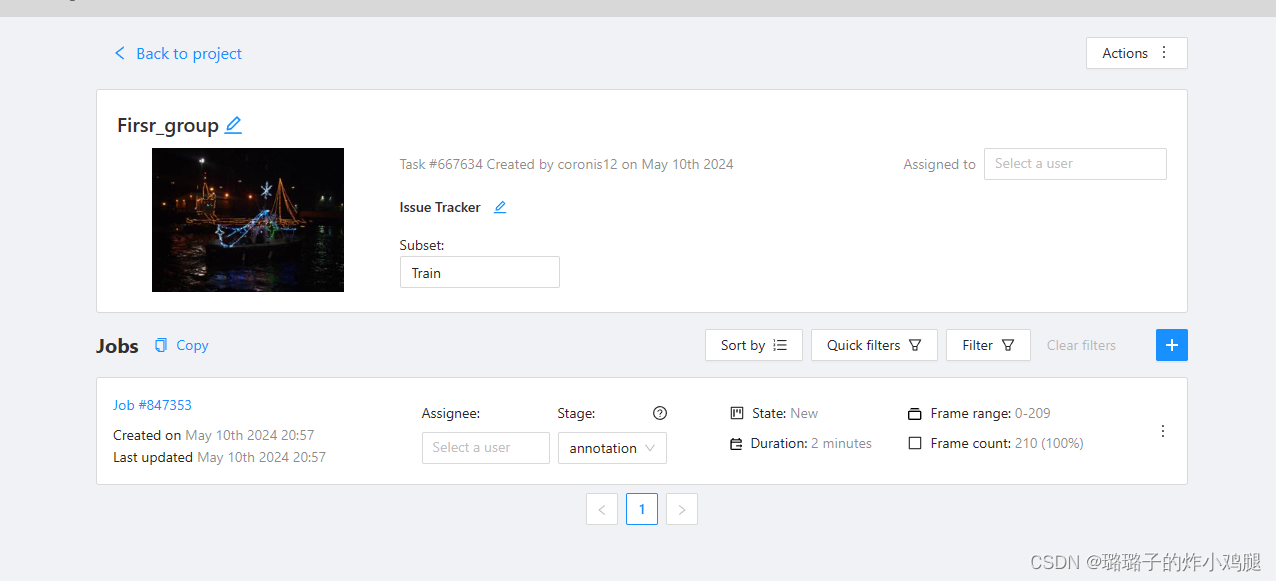
打开jobs,选择刚才我们制作的first_group
选择方框,并设置标签,用喜欢的方式进行目标框选,推荐两点定位
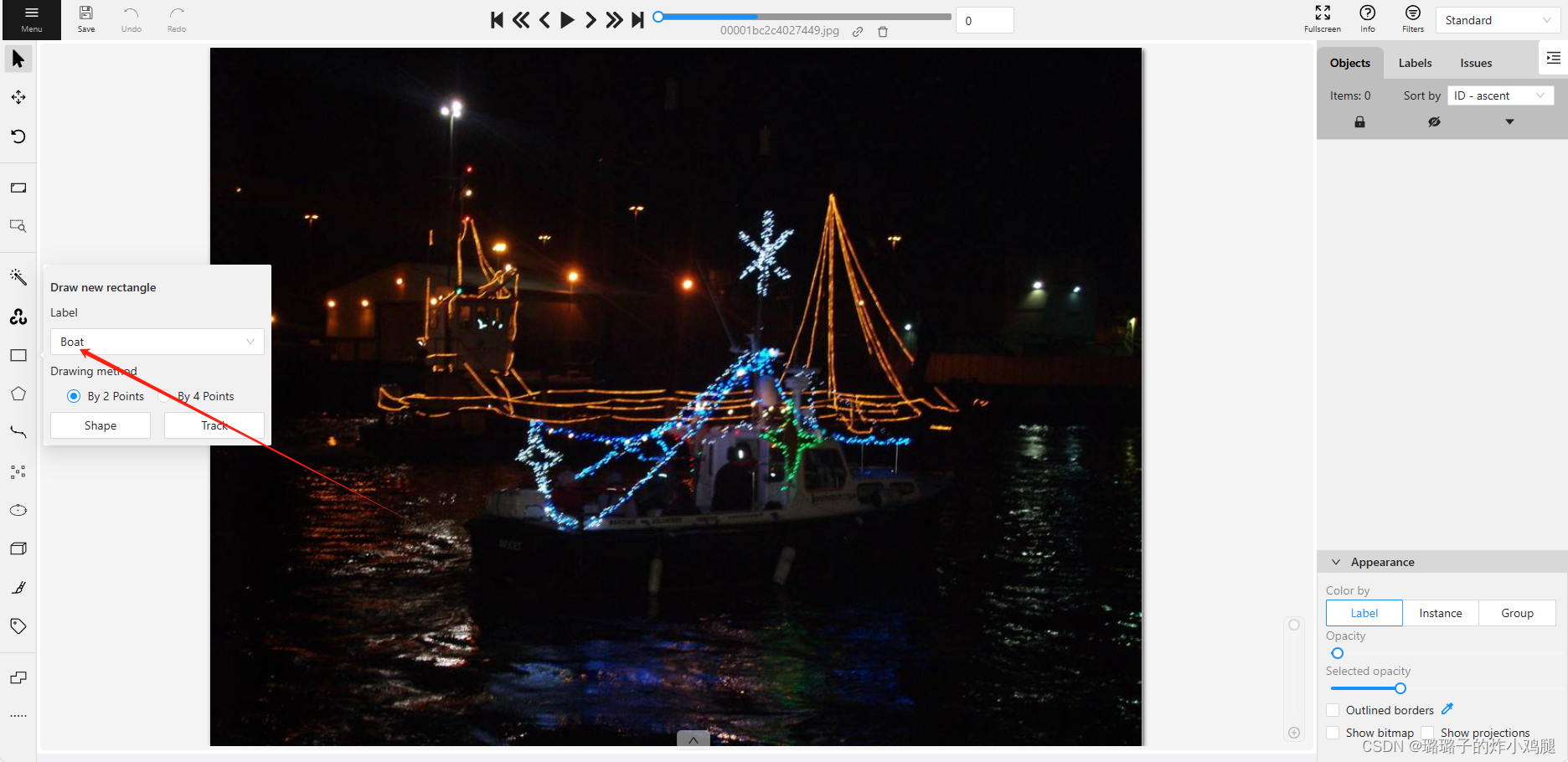
右侧可以进行进一步设计与微调

遇到这种存在有多个对象的就可以全部框选后再点击下一张图片
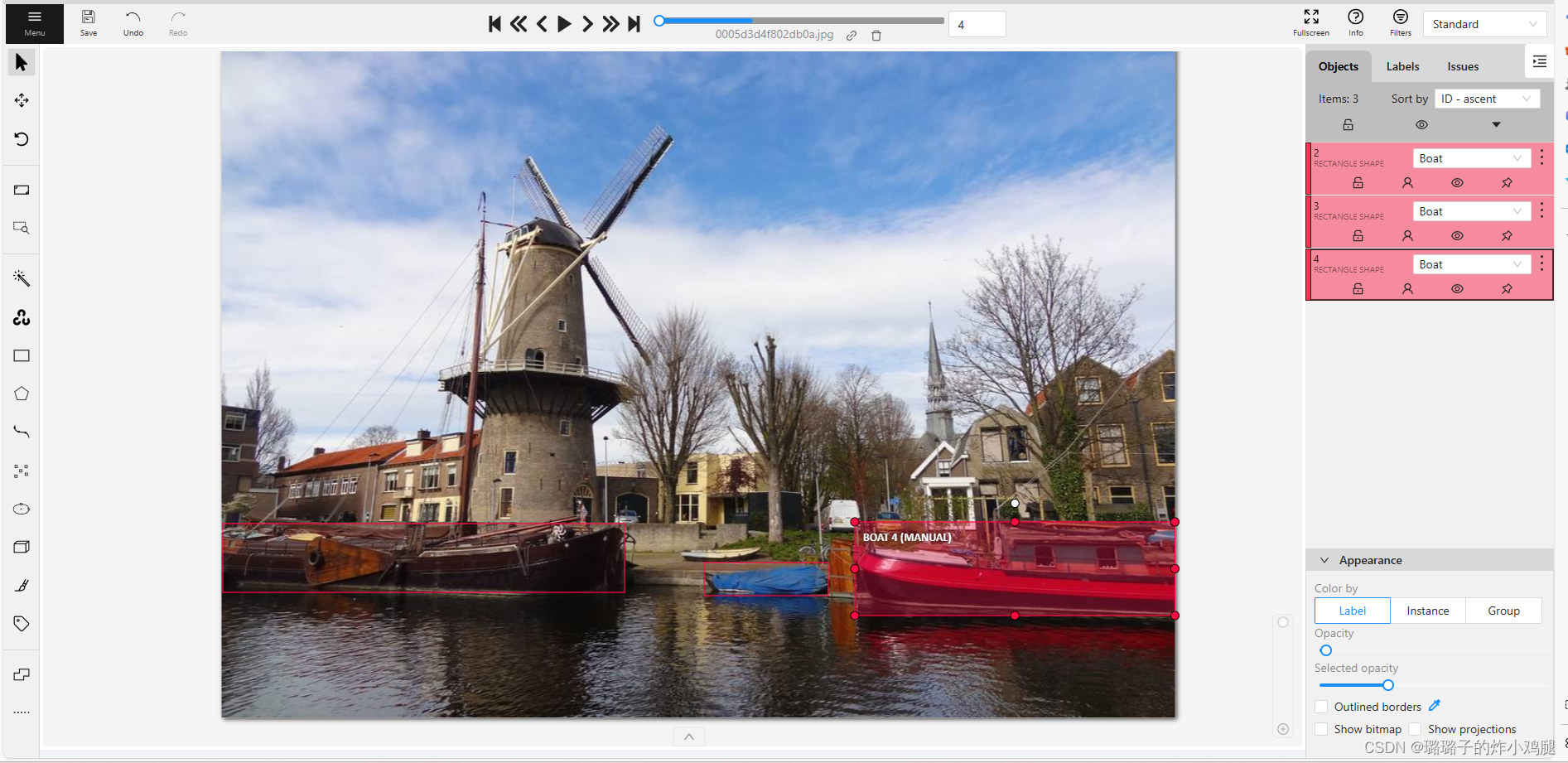
重复操作后完成所有图片的标注即可。
2.3 导出数据集用于训练
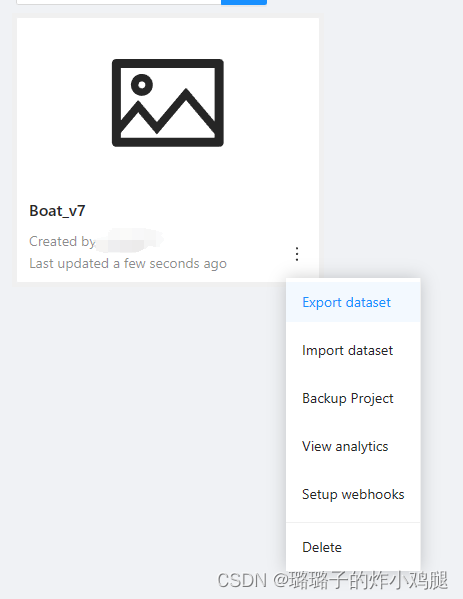
完成注释后,回到project页面,点击右下角选择导出
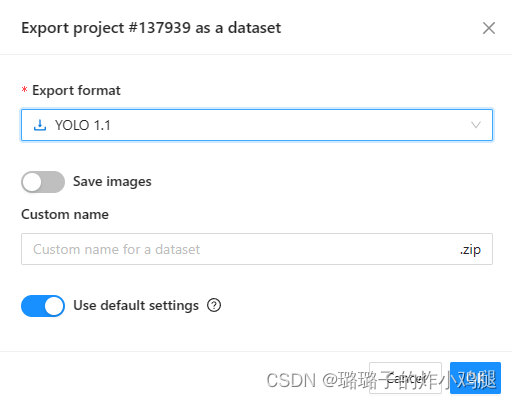
选择自己需要的格式即可(我计划用于yolov8进行训练,因此设置为yolo格式导出)~
发表评论