1 安装flink

使用flink 1.12版本,部署flink standalone集群模式,启动服务,步骤如下:
step1、下载安装包
step2、上传软件包
step3、解压
step4、创建软连接
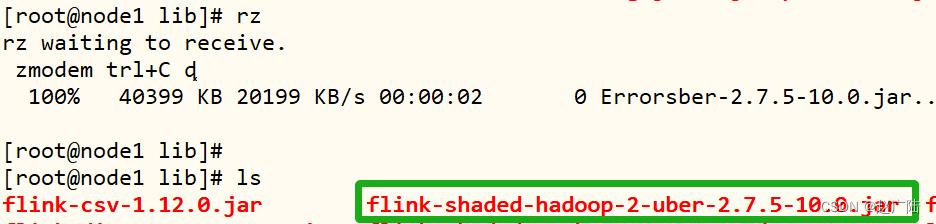
step5、添加hadoop依赖jar包
step6、启动hdfs集群
step7、启动flink本地集群

停止flink
step8、访问flink的web ui
网址:node1:8081/#/overview
step9、执行官方示例
读取文本文件数据,进行词频统计wordcount,将结果打印控制台。
2 快速入门
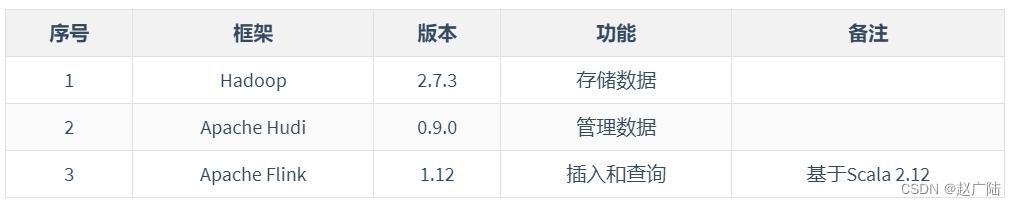
基于flink操作hudi表数据,进行查询分析,软件版本说明如下:
2.1 集成flink概述
flink集成hudi时,本质将集成jar包:hudi-flink-bundle_2.12-0.9.0.jar,放入flink 应用classpath下即可。flink sqlconnector支持hudi作为source和sink时,两种方式将jar包放入classpath路径:
● 方式一:运行flink sql client命令行时,通过参数【-j xx.jar】指定jar包

● 方式二:将jar包直接放入flink软件安装包lib目录下【$flink_home/lib】

接下来使用flink sql client提供sql命令行与hudi集成,需要启动flink standalone集群,其中需要修改配置文件【$flink_home/conf/flink-conf.yaml】,taskmanager分配slots数目为4。

2.2 环境准备
首先启动各个框架服务,然后编写ddl语句创建表,最后dml语句进行插入数据和查询分析。按照如下步骤启动环境,总共分为三步:
● 第一步、启动hdfs集群
● 第二步、启动flink 集群
由于flink需要连接hdfs文件系统,所以先设置hadoop_classpath变量,再启动standalone集群服务。
● 第三步、启动flink sql cli命令行
采用指定参数【-j xx.jar】方式加载hudi-flink集成包,命令如下。
在sql cli设置分析结果展示模式为:set execution.result-mode=tableau;。

2.3 创建表
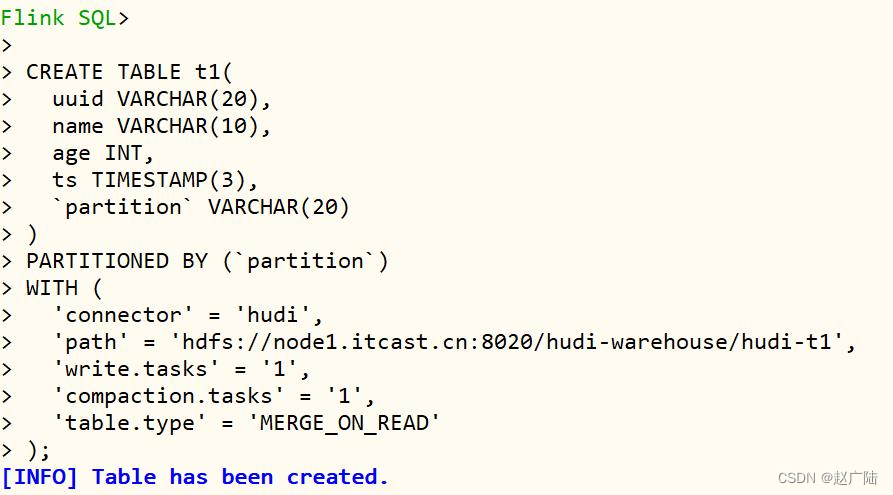
创建表:t1,数据存储到hudi表中,底层hdfs存储,表的类型:mor,语句如下:
create table t1(
uuid varchar(20),
name varchar(10),
age int,
ts timestamp(3),
`partition` varchar(20)
)
partitioned by (`partition`)
with (
'connector' = 'hudi',
'path' = 'hdfs://node1.oldlu.cn:8020/ehualu/hudi-warehouse/hudi-t1',
'write.tasks' = '1',
'compaction.tasks' = '1',
'table.type' = 'merge_on_read'
);
在flink sql cli命令行执行ddl语句,截图如下所示:
查看表及结构,命令如下:
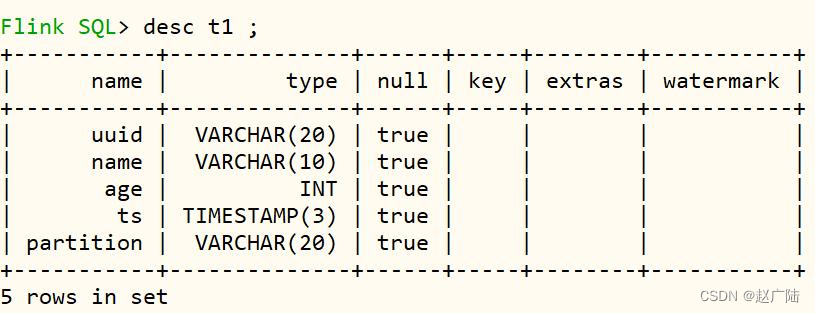
接下来,编写insert语句,向hudi表中插入数据。
2.4 插入数据
向上述创建表:t1中插入数据,其中t1表为分区表,字段名称:partition,插入数据时字段值有:【part1、part2、part3和part4】,语句如下:
insert into t1 values
('id1','danny',23,timestamp '1970-01-01 00:00:01','par1');
insert into t1 values
('id2','stephen',33,timestamp '1970-01-01 00:00:02','par1'),
('id3','julian',53,timestamp '1970-01-01 00:00:03','par2'),
('id4','fabian',31,timestamp '1970-01-01 00:00:04','par2'),
('id5','sophia',18,timestamp '1970-01-01 00:00:05','par3'),
('id6','emma',20,timestamp '1970-01-01 00:00:06','par3'),
('id7','bob',44,timestamp '1970-01-01 00:00:07','par4'),
('id8','han',56,timestamp '1970-01-01 00:00:08','par4');
在flink sql cli中执行截图如下:
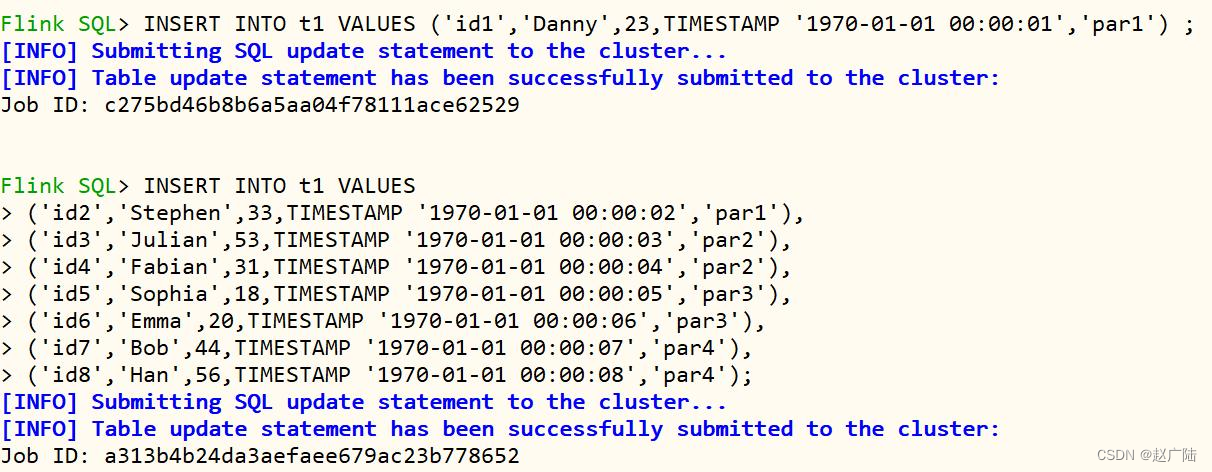
日志信息可知,将sql语句提交至flink standalone集群执行,并且insert语句执行成功。
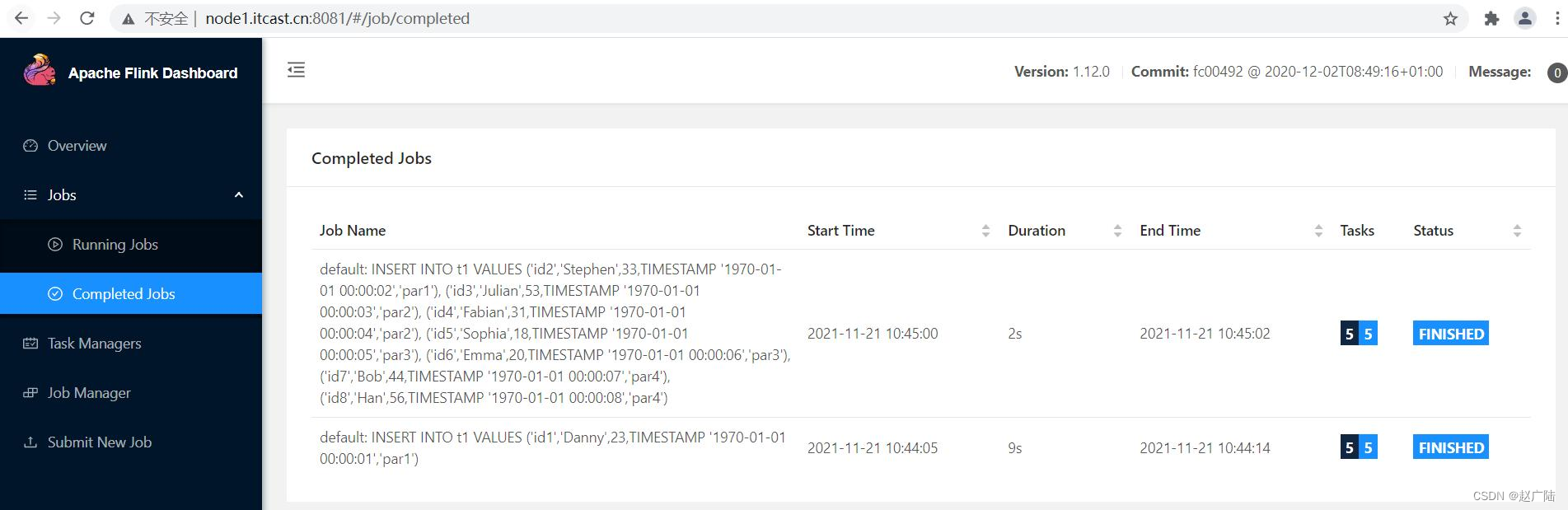
查询hdfs上数据存储目录:
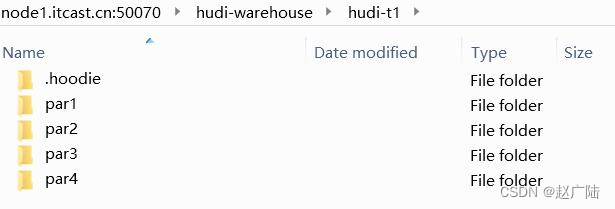
2.5 查询数据
数据通过flink sql cli插入hudi表后,编写sql语句查询数据,语句如下:
与插入数据一样,向standalone集群提交sql,生成job查询数据。

通过在 where 子句中添加 partition 路径来裁剪 partition,如下所示:
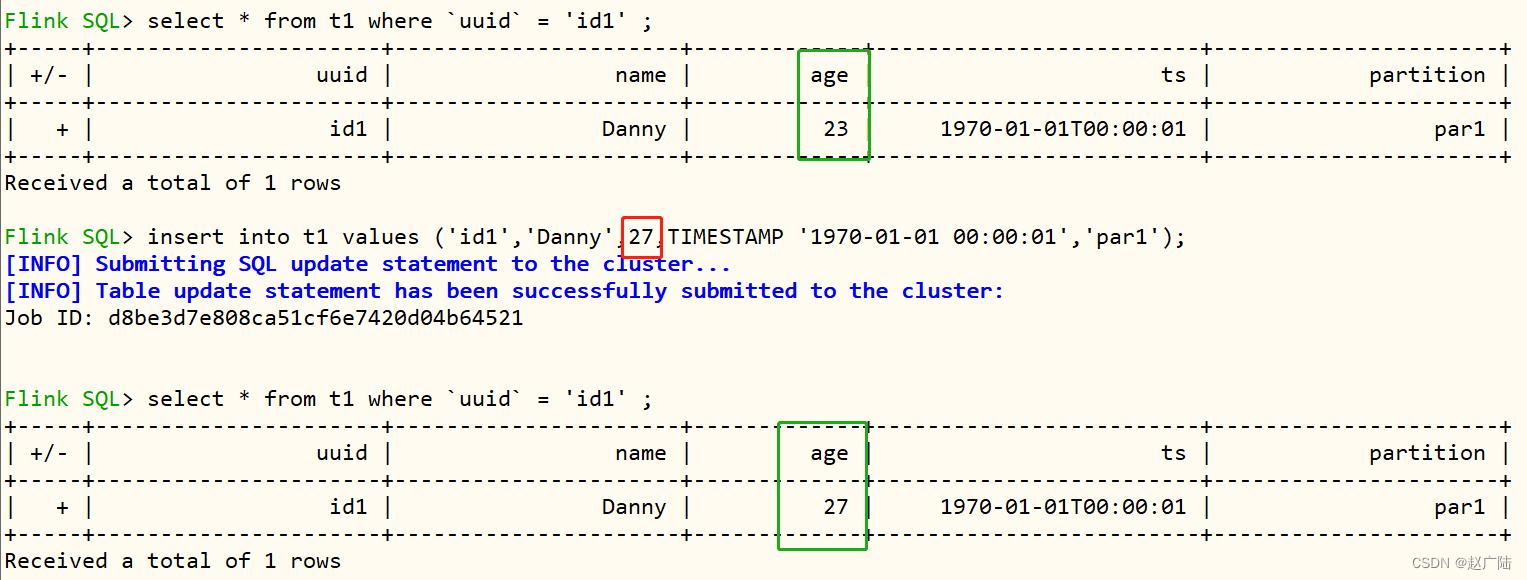
2.6 更新数据
将id1的数据age由23变为了27,执行sql语句如下:
再次查询表的数据,结果如下:
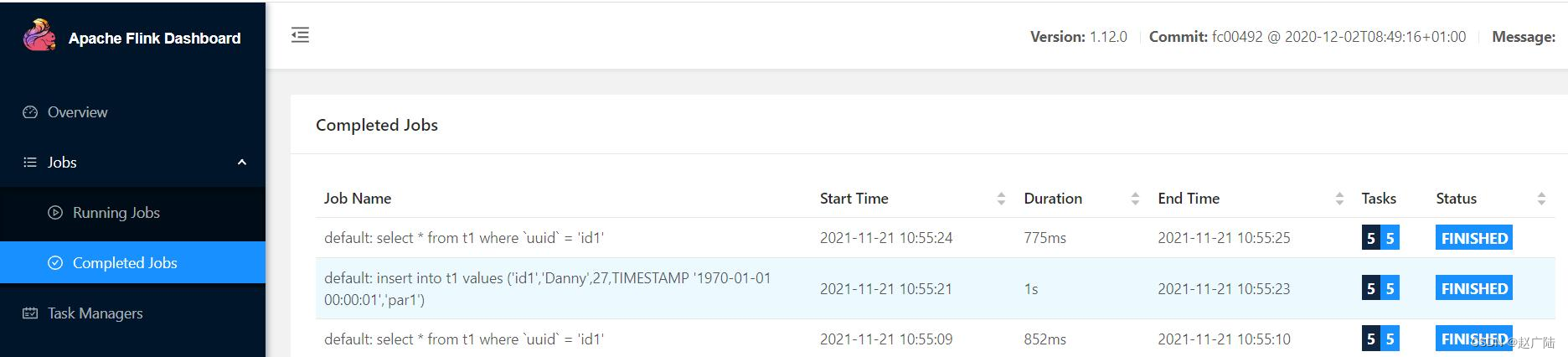
插入flink standalone监控页面8081,可以看到执行3个job。
3 streaming query
flink插入hudi表数据时,支持以流的方式加载数据,增量查询分析。
3.1 创建表
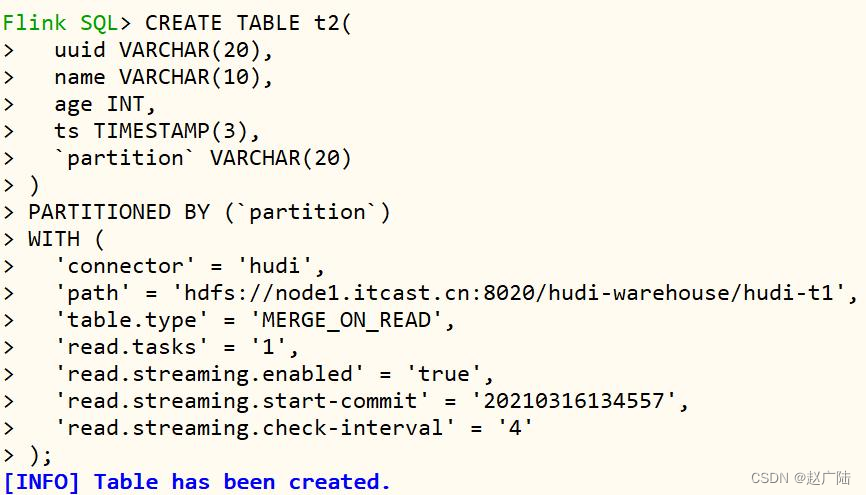
首先创建表:t2,设置相关属性,以流的方式查询读取,映射到前面表:t1,语句如下。
create table t2(
uuid varchar(20),
name varchar(10),
age int,
ts timestamp(3),
`partition` varchar(20)
)
partitioned by (`partition`)
with (
'connector' = 'hudi',
'path' = 'hdfs://node1.oldlu.cn:8020/hudi-warehouse/hudi-t1',
'table.type' = 'merge_on_read',
'read.tasks' = '1',
'read.streaming.enabled' = 'true',
'read.streaming.start-commit' = '20210316134557',
'read.streaming.check-interval' = '4'
);
核心参数选项说明:
● read.streaming.enabled 设置为 true,表明通过 streaming 的方式读取表数据;
● read.streaming.check-interval 指定了 source 监控新的 commits 的间隔为 4s;
● table.type 设置表类型为 merge_on_read;
接下来编写sql插入数据,流式方式插入表:t2数据。
3.2 查询数据
创建表:t2 以后,此时表的数据就是前面批batch模式写入的数据。
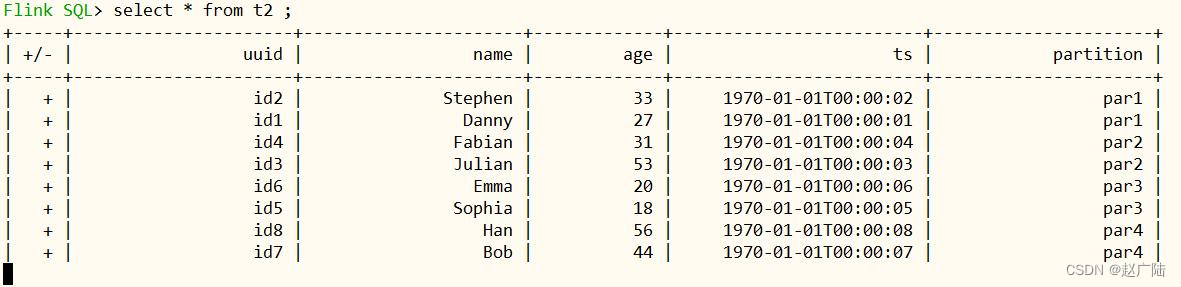
插入显示表中所有数据,光标在一直闪动,每隔4秒,再依据commit timestamp增量查询。
3.3 插入数据
重新开启terminal启动flink sql cli,重新创建表:t1,采用批batch模式插入1条数据。
create table t1(
uuid varchar(20),
name varchar(10),
age int,
ts timestamp(3),
`partition` varchar(20)
)
partitioned by (`partition`)
with (
'connector' = 'hudi',
'path' = 'hdfs://node1.oldlu.cn:8020/hudi-warehouse/hudi-t1',
'write.tasks' = '1',
'compaction.tasks' = '1',
'table.type' = 'merge_on_read'
);
insert into t1 values ('id9','test',27,timestamp '1970-01-01 00:00:01','par5');
几秒后在流表中可以读取到一条新增的数据(前面插入的一条数据)。
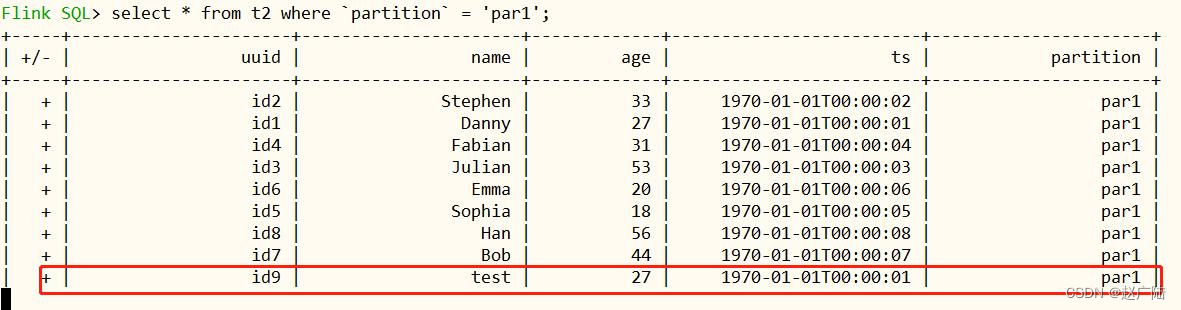
通过一些简单的演示,发现 hudi flink 的集成已经相对完善,读写数据均已覆盖。
4 flink sql writer
在hudi-flink模块中提供flink sql connector连接器,支持从hudi表读写数据。
文档:https://hudi.apache.org/docs/writing_data#flink-sql-writer
4.1 flink sql集成kafka
首先配置flink sql 集成kafka,实时消费kafka topic数据,具体操作如下步骤:
● 第一步、创建topic
启动zookeeper和kafka服务组件,案例演示flinksql与kafka集成,实时加载数据。使用kafkatool工具,连接启动kafka服务,创建topic:flink-topic。
可以使用命令行创建topic,具体命令如下:
– 创建topic:flink-topic
启动flink standalone集群服务,运行flink-sql命令行,创建表映射到kafka中。
■第二步、启动hdfs集群
■第三步、启动flink 集群
由于flink需要连接hdfs文件系统,所以先设置hadoop_classpath变量,再启动standalone集群服务。
■第四步、启动flink sql cli命令行
采用指定参数【-j xx.jar】方式加载hudi-flink集成包,命令如下。
在sql cli设置分析结果展示模式为:tableau。
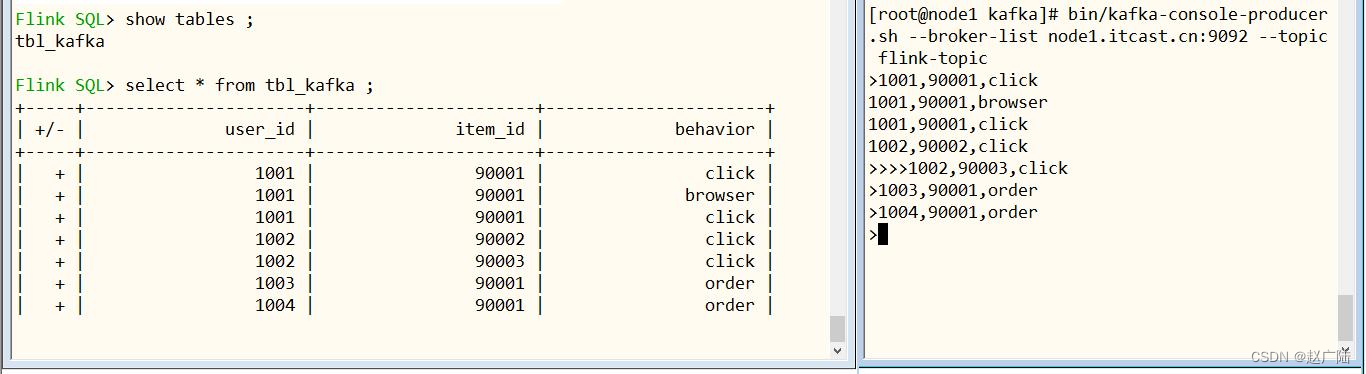
■第五步、创建表,映射到kafka topic
其中kafka topic中数据是csv文件格式,有三个字段:user_id、item_id、behavior,从kafka消费数据时,设置从最新偏移量开始,创建表语句如下:set execution.result-mode=tableau;
create table tbl_kafka (
`user_id` bigint,
`item_id` bigint,
`behavior` string
) with (
'connector' = 'kafka',
'topic' = 'flink-topic',
'properties.bootstrap.servers' = 'node1.oldlu.cn:9092',
'properties.group.id' = 'test-group-10001',
'scan.startup.mode' = 'latest-offset',
'format' = 'csv'
);
执行命令后,查看表,截图如下:

■第六步、实时向topic发送数据,并在flinksql查询
首先,在flinksql页面,执行select查询语句,截图如下:

其次,通过kafka console producer向topic发送数据,命令和数据如下:
– 生产者发送数据
kafka-console-producer.sh --broker-list node1.oldlu.cn:9092 --topic flink-topic
/*
1001,90001,click
1001,90001,browser
1001,90001,click
1002,90002,click
1002,90003,click
1003,90001,order
1004,90001,order
*/
插入数据,观察flinksql界面,可以发现数据实时查询处理,截图如下所示:
至此flinksql集成kafka,采用表的方式关联topic数据,接下来编写flink sql 程序实时将kafka数据同步到hudi表中。
4.2 flink sql写入hudi
将上述编写structuredstreaming流式程序改为flink sql程序:实时从kafka消费topic数据,解析转换后,存储至hudi表中,示意图如下所示。

4.2.1 创建maven module

创建maven module模块,添加依赖,此处flink:1.12.2和hudi:0.9.0版本。
<repositories>
<repository>
<id>nexus-aliyun</id>
<name>nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</repository>
<repository>
<id>central_maven</id>
<name>central maven</name>
<url>https://repo1.maven.org/maven2</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>apache.snapshots</id>
<name>apache development snapshot repository</name>
<url>https://repository.apache.org/content/repositories/snapshots/</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
<properties>
<project.build.sourceencoding>utf-8</project.build.sourceencoding>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<flink.version>1.12.2</flink.version>
<hadoop.version>2.7.3</hadoop.version>
<mysql.version>8.0.16</mysql.version>
</properties>
<dependencies>
<!-- flink client -->
<dependency>
<groupid>org.apache.flink</groupid>
<artifactid>flink-clients_${scala.binary.version}</artifactid>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupid>org.apache.flink</groupid>
<artifactid>flink-java</artifactid>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupid>org.apache.flink</groupid>
<artifactid>flink-streaming-java_${scala.binary.version}</artifactid>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupid>org.apache.flink</groupid>
<artifactid>flink-runtime-web_${scala.binary.version}</artifactid>
<version>${flink.version}</version>
</dependency>
<!-- flink table api & sql -->
<dependency>
<groupid>org.apache.flink</groupid>
<artifactid>flink-table-common</artifactid>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupid>org.apache.flink</groupid>
<artifactid>flink-table-planner-blink_${scala.binary.version}</artifactid>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupid>org.apache.flink</groupid>
<artifactid>flink-table-api-java-bridge_${scala.binary.version}</artifactid>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupid>org.apache.flink</groupid>
<artifactid>flink-connector-kafka_${scala.binary.version}</artifactid>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupid>org.apache.flink</groupid>
<artifactid>flink-json</artifactid>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupid>org.apache.hudi</groupid>
<artifactid>hudi-flink-bundle_${scala.binary.version}</artifactid>
<version>0.9.0</version>
</dependency>
<dependency>
<groupid>org.apache.flink</groupid>
<artifactid>flink-shaded-hadoop-2-uber</artifactid>
<version>2.7.5-10.0</version>
</dependency>
<!-- mysql/fastjson/lombok -->
<dependency>
<groupid>mysql</groupid>
<artifactid>mysql-connector-java</artifactid>
<version>${mysql.version}</version>
</dependency>
<dependency>
<groupid>com.alibaba</groupid>
<artifactid>fastjson</artifactid>
<version>1.2.68</version>
</dependency>
<dependency>
<groupid>org.projectlombok</groupid>
<artifactid>lombok</artifactid>
<version>1.18.12</version>
</dependency>
<!-- slf4j及log4j -->
<dependency>
<groupid>org.slf4j</groupid>
<artifactid>slf4j-log4j12</artifactid>
<version>1.7.7</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupid>log4j</groupid>
<artifactid>log4j</artifactid>
<version>1.2.17</version>
<scope>runtime</scope>
</dependency>
</dependencies>
<build>
<sourcedirectory>src/main/java</sourcedirectory>
<testsourcedirectory>src/test/java</testsourcedirectory>
<plugins>
<!-- 编译插件 -->
<plugin>
<groupid>org.apache.maven.plugins</groupid>
<artifactid>maven-compiler-plugin</artifactid>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<!--<encoding>${project.build.sourceencoding}</encoding>-->
</configuration>
</plugin>
<plugin>
<groupid>org.apache.maven.plugins</groupid>
<artifactid>maven-surefire-plugin</artifactid>
<version>2.18.1</version>
<configuration>
<usefile>false</usefile>
<disablexmlreport>true</disablexmlreport>
<includes>
<include>**/*test.*</include>
<include>**/*suite.*</include>
</includes>
</configuration>
</plugin>
<!-- 打jar包插件(会包含所有依赖) -->
<plugin>
<groupid>org.apache.maven.plugins</groupid>
<artifactid>maven-shade-plugin</artifactid>
<version>2.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>meta-inf/*.sf</exclude>
<exclude>meta-inf/*.dsa</exclude>
<exclude>meta-inf/*.rsa</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.manifestresourcetransformer">
<!-- <mainclass>com.oldlu.flink.batch.flinkbatchwordcount</mainclass> -->
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
4.2.2 消费kafka数据
创建类:flinksqlkafakdemo,基于flink table api,从kafka消费数据,提取字段值(方便后续存储hudi表中)。
package cn.oldlu.hudi;
import org.apache.flink.table.api.environmentsettings;
import org.apache.flink.table.api.table;
import org.apache.flink.table.api.tableenvironment;
import static org.apache.flink.table.api.expressions.$;
/**
* 基于flink sql connector实现:实时消费topic中数据,转换处理后,实时存储hudi表中
*/
public class flinksqlkafakdemo {
public static void main(string[] args) {
// 1-获取表执行环境
environmentsettings settings = environmentsettings
.newinstance()
.instreamingmode()
.build();
tableenvironment tableenv = tableenvironment.create(settings) ;
// 2-创建输入表, todo: 从kafka消费数据
tableenv.executesql(
"create table order_kafka_source (\n" +
" orderid string,\n" +
" userid string,\n" +
" ordertime string,\n" +
" ip string,\n" +
" ordermoney double,\n" +
" orderstatus int\n" +
") with (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'order-topic',\n" +
" 'properties.bootstrap.servers' = 'node1.oldlu.cn:9092',\n" +
" 'properties.group.id' = 'gid-1001',\n" +
" 'scan.startup.mode' = 'latest-offset',\n" +
" 'format' = 'json',\n" +
" 'json.fail-on-missing-field' = 'false',\n" +
" 'json.ignore-parse-errors' = 'true'\n" +
")"
);
// 3-数据转换:提取订单时间中订单日期,作为hudi表分区字段值
table etltable = tableenv
.from("order_kafka_source")
.addcolumns(
$("ordertime").substring(0, 10).as("partition_day")
)
.addcolumns(
$("orderid").substring(0, 17).as("ts")
);
tableenv.createtemporaryview("view_order", etltable);
// 4-查询数据
tableenv.executesql("select * from view_order").print();
}
}
运行流式应用程序和模拟数据程序,查看控制台。
4.2.3 保存数据至hudi
编写创建表ddl语句,映射到hudi表中,指定相关属性:主键字段、表类型等等。
create table order_hudi_sink (
orderid string primary key not enforced,
userid string,
ordertime string,
ip string,
ordermoney double,
orderstatus int,
ts string,
partition_day string
)
partitioned by (partition_day)
with (
'connector' = 'hudi',
'path' = 'file:///d:/flink_hudi_order',
'table.type' = 'merge_on_read',
'write.operation' = 'upsert',
'hoodie.datasource.write.recordkey.field'= 'orderid',
'write.precombine.field' = 'ts',
'write.tasks'= '1'
);
将hudi表数据保存在本地文件系统localfs目录中,此外,向hudi表写入数据时,采用insert into插入方式写入数据,具体ddl语句如下:
– 子查询插入insert … select …
insert into order_hudi_sink
select
orderid, userid, ordertime, ip, ordermoney, orderstatus,
substring(orderid, 0, 17) as ts, substring(ordertime, 0, 10) as partition_day
from order_kafka_source ;
12345
创建类:flinksqlhudidemo,编写代码:从kafka消费数据,转换后,保存到hudi表。
package cn.oldlu.hudi;
import org.apache.flink.streaming.api.environment.streamexecutionenvironment;
import org.apache.flink.table.api.environmentsettings;
import org.apache.flink.table.api.table;
import org.apache.flink.table.api.bridge.java.streamtableenvironment;
import static org.apache.flink.table.api.expressions.$;
/**
* 基于flink sql connector实现:实时消费topic中数据,转换处理后,实时存储hudi表中
*/
public class flinksqlhudidemo {
public static void main(string[] args) {
system.setproperty("hadoop_user_name","root");
// 1-获取表执行环境
streamexecutionenvironment env = streamexecutionenvironment.getexecutionenvironment();
env.setparallelism(1);
env.enablecheckpointing(5000);
environmentsettings settings = environmentsettings
.newinstance()
.instreamingmode()
.build();
streamtableenvironment tableenv = streamtableenvironment.create(env, settings) ;
// 2-创建输入表, todo: 从kafka消费数据
tableenv.executesql(
"create table order_kafka_source (\n" +
" orderid string,\n" +
" userid string,\n" +
" ordertime string,\n" +
" ip string,\n" +
" ordermoney double,\n" +
" orderstatus int\n" +
") with (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'order-topic',\n" +
" 'properties.bootstrap.servers' = 'node1.oldlu.cn:9092',\n" +
" 'properties.group.id' = 'gid-1001',\n" +
" 'scan.startup.mode' = 'latest-offset',\n" +
" 'format' = 'json',\n" +
" 'json.fail-on-missing-field' = 'false',\n" +
" 'json.ignore-parse-errors' = 'true'\n" +
")"
);
// 3-数据转换:提取订单时间中订单日期,作为hudi表分区字段值
table etltable = tableenv
.from("order_kafka_source")
.addcolumns(
$("orderid").substring(0, 17).as("ts")
)
.addcolumns(
$("ordertime").substring(0, 10).as("partition_day")
);
tableenv.createtemporaryview("view_order", etltable);
// 4-定义输出表,todo:数据保存到hudi表中
tableenv.executesql(
"create table order_hudi_sink (\n" +
" orderid string primary key not enforced,\n" +
" userid string,\n" +
" ordertime string,\n" +
" ip string,\n" +
" ordermoney double,\n" +
" orderstatus int,\n" +
" ts string,\n" +
" partition_day string\n" +
")\n" +
"partitioned by (partition_day) \n" +
"with (\n" +
" 'connector' = 'hudi',\n" +
" 'path' = 'file:///d:/flink_hudi_order',\n" +
" 'table.type' = 'merge_on_read',\n" +
" 'write.operation' = 'upsert',\n" +
" 'hoodie.datasource.write.recordkey.field' = 'orderid'," +
" 'write.precombine.field' = 'ts'" +
" 'write.tasks'= '1'" +
")"
);
// 5-通过子查询方式,将数据写入输出表
tableenv.executesql(
"insert into order_hudi_sink\n" +
"select\n" +
" orderid, userid, ordertime, ip, ordermoney, orderstatus, ts, partition_day\n" +
"from view_order"
);
}
}
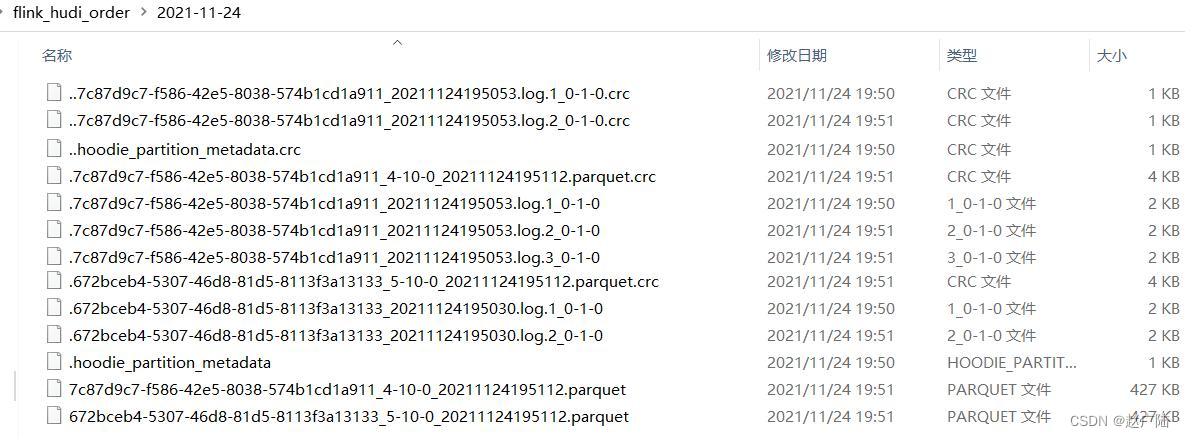
运行上述编写流式程序,查看本地文件系统目录,保存hudi表数据结构信息:
4.2.4 加载hudi表数据
创建类:flinksqlreaddemo,加载hudi表中数据,采用流式方式读取,同样创建表,映射关联到hudi表数据存储目录中,创建表ddl语句如下:
create table order_hudi(
orderid string primary key not enforced,
userid string,
ordertime string,
ip string,
ordermoney double,
orderstatus int,
ts string,
partition_day string
)
partitioned by (partition_day)
with (
'connector' = 'hudi',
'path' = 'file:///d:/flink_hudi_order',
'table.type' = 'merge_on_read',
'read.streaming.enabled' = 'true',
'read.streaming.check-interval' = '4'
);
完整flink sql流式程序代码如下:
package cn.oldlu.hudi;
import org.apache.flink.table.api.environmentsettings;
import org.apache.flink.table.api.tableenvironment;
/**
* 基于flink sql connector实现:从hudi表中加载数据,编写sql查询
*/
public class flinksqlreaddemo {
public static void main(string[] args) {
system.setproperty("hadoop_user_name","root");
// 1-获取表执行环境
environmentsettings settings = environmentsettings
.newinstance()
.instreamingmode()
.build();
tableenvironment tableenv = tableenvironment.create(settings) ;
// 2-创建输入表, todo: 加载hudi表查询数据
tableenv.executesql(
"create table order_hudi(\n" +
" orderid string primary key not enforced,\n" +
" userid string,\n" +
" ordertime string,\n" +
" ip string,\n" +
" ordermoney double,\n" +
" orderstatus int,\n" +
" ts string,\n" +
" partition_day string\n" +
")\n" +
"partitioned by (partition_day)\n" +
"with (\n" +
" 'connector' = 'hudi',\n" +
" 'path' = 'file:///d:/flink_hudi_order',\n" +
" 'table.type' = 'merge_on_read',\n" +
" 'read.streaming.enabled' = 'true',\n" +
" 'read.streaming.check-interval' = '4'\n" +
")"
);
// 3-通过子查询方式,将数据写入输出表
tableenv.executesql(
"select \n" +
" orderid, userid, ordertime, ip, ordermoney, orderstatus, ts ,partition_day \n" +
"from order_hudi"
).print();
}
}
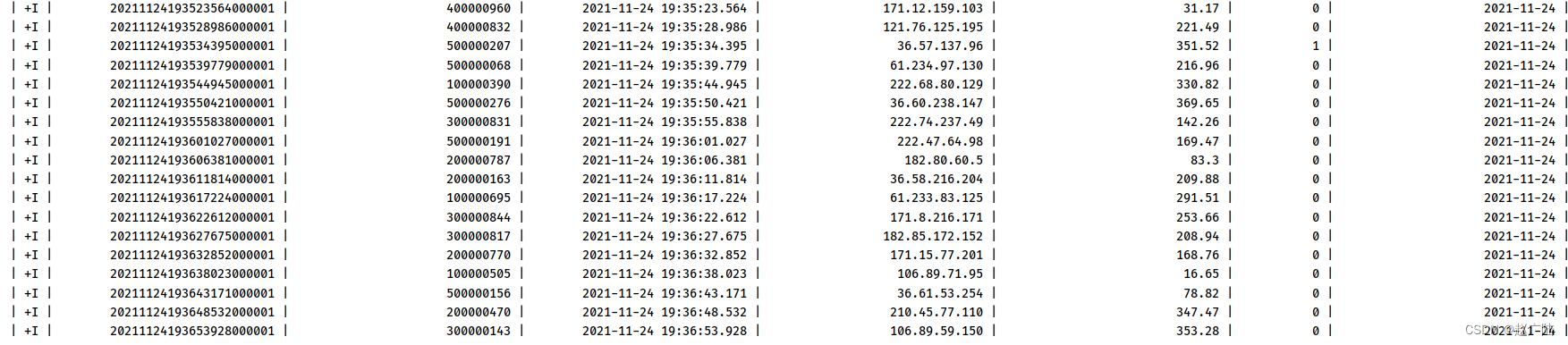
运行流式程序,加载hudi表数据,结果如下所示:

4.3 flink sql client 写入hudi
启动flink standalone集群,运行sql client命令行客户端,执行ddl和dml语句,操作数据。
4.3.1 集成环境
■配置flink 集群
修改$flink_home/conf/flink-conf.yaml文件
jobmanager.rpc.address: node1.oldlu.cn
jobmanager.memory.process.size: 1024m
taskmanager.memory.process.size: 2048m
taskmanager.numberoftaskslots: 4
classloader.check-leaked-classloader: false
classloader.resolve-order: parent-first
execution.checkpointing.interval: 3000
state.backend: rocksdb
state.checkpoints.dir: hdfs://node1.oldlu.cn:8020/flink/flink-checkpoints
state.savepoints.dir: hdfs://node1.oldlu.cn:8020/flink/flink-savepoints
state.backend.incremental: true
● 将hudi与flink集成jar包及其他相关jar包,放置到$flink_home/lib目录

● 启动standalone集群
● 启动sql client,最好再次指定hudi集成jar包
● 设置属性
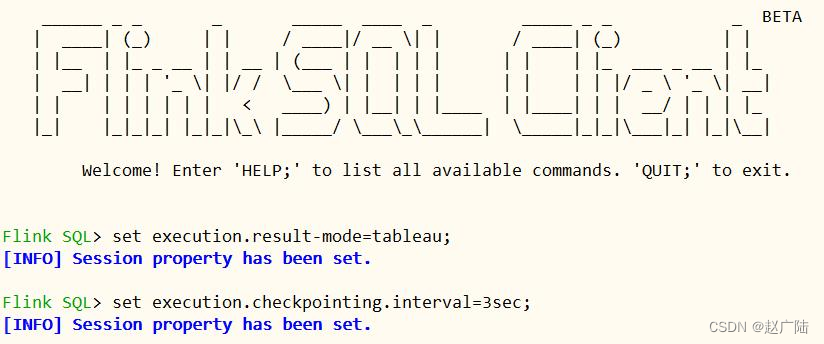
4.3.2 执行sql
首先创建输入表:从kafka消费数据,其次编写sql提取字段值,再创建输出表:将数据保存值hudi表中,最后编写sql查询hudi表数据。
● 第1步、创建输入表,关联kafka topic
– 输入表:kafka source
create table order_kafka_source (
orderid string,
userid string,
ordertime string,
ip string,
ordermoney double,
orderstatus int
) with (
'connector' = 'kafka',
'topic' = 'order-topic',
'properties.bootstrap.servers' = 'node1.oldlu.cn:9092',
'properties.group.id' = 'gid-1001',
'scan.startup.mode' = 'latest-offset',
'format' = 'json',
'json.fail-on-missing-field' = 'false',
'json.ignore-parse-errors' = 'true'
);
select orderid, userid, ordertime, ip, ordermoney, orderstatus from order_kafka_source ;
● 第2步、处理获取kafka消息数据,提取字段值
select
orderid, userid, ordertime, ip, ordermoney, orderstatus,
substring(orderid, 0, 17) as ts, substring(ordertime, 0, 10) as partition_day
from order_kafka_source ;
● 第3步、创建输出表,保存数据至hudi表,设置相关属性
– 输出表:hudi sink
create table order_hudi_sink (
orderid string primary key not enforced,
userid string,
ordertime string,
ip string,
ordermoney double,
orderstatus int,
ts string,
partition_day string
)
partitioned by (partition_day)
with (
'connector' = 'hudi',
'path' = 'hdfs://node1.oldlu.cn:8020/hudi-warehouse/order_hudi_sink',
'table.type' = 'merge_on_read',
'write.operation' = 'upsert',
'hoodie.datasource.write.recordkey.field'= 'orderid',
'write.precombine.field' = 'ts',
'write.tasks'= '1',
'compaction.tasks' = '1',
'compaction.async.enabled' = 'true',
'compaction.trigger.strategy' = 'num_commits',
'compaction.delta_commits' = '1'
);
● 第4步、使用insert into语句,将数据保存hudi表
– 子查询插入insert … select …
insert into order_hudi_sink
select
orderid, userid, ordertime, ip, ordermoney, orderstatus,
substring(orderid, 0, 17) as ts, substring(ordertime, 0, 10) as partition_day
from order_kafka_source ;
12345
此时,提交flink job运行在flinkstandalone集群上,示意图如下:
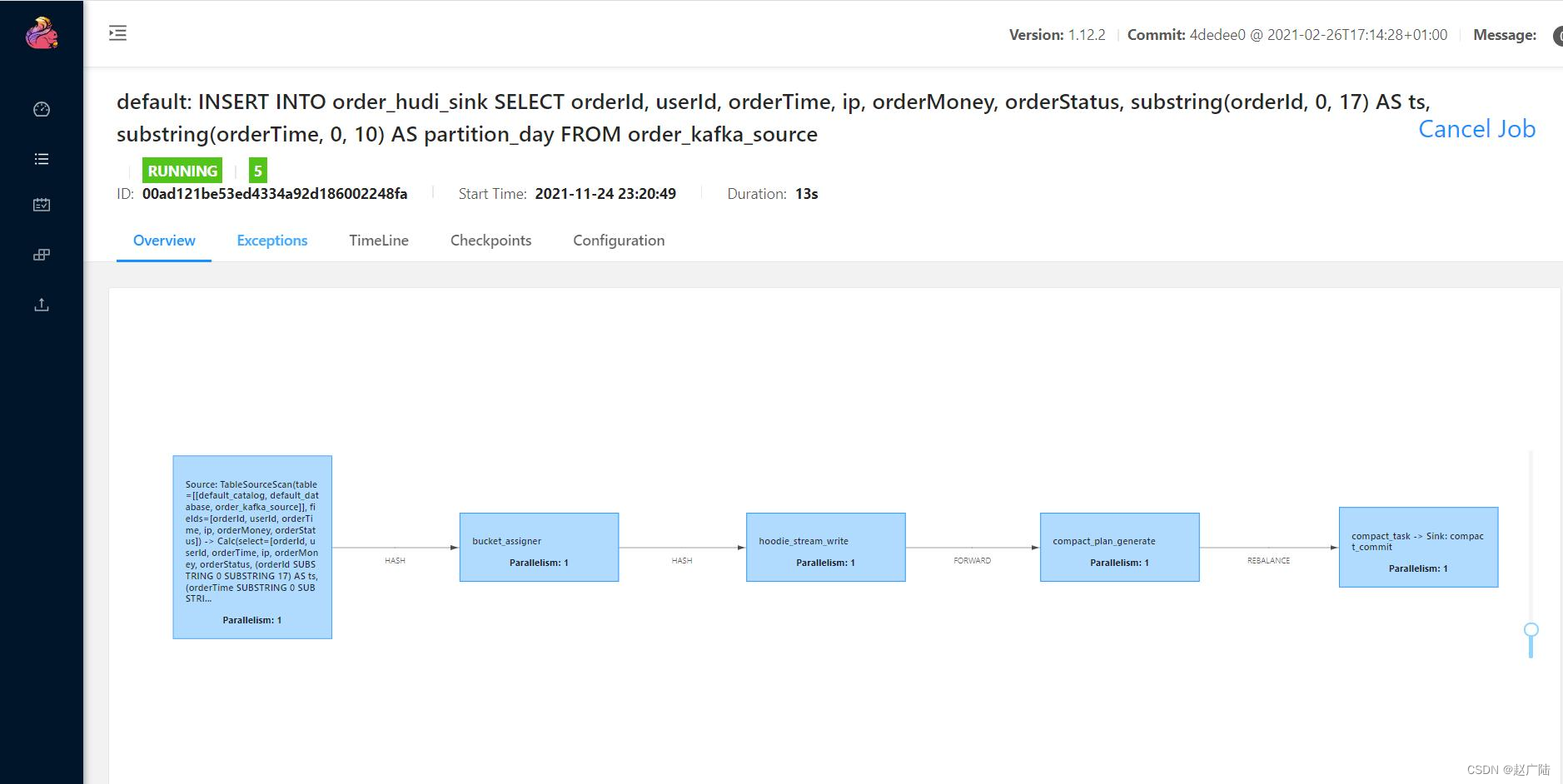
只要运行模拟交易订单数据程序,就会将数据发送到kafka,最后转换保存至hudi表,截图如下:
■第5步、编写select语句,查询hudi表交易订单数据
– 查询hudi表数据

5 hudi cdc
cdc的全称是change data capture,即变更数据捕获,主要面向数据库的变更,是是数据库领域非常常见的技术,主要用于捕获数据库的一些变更,然后可以把变更数据发送到下游。
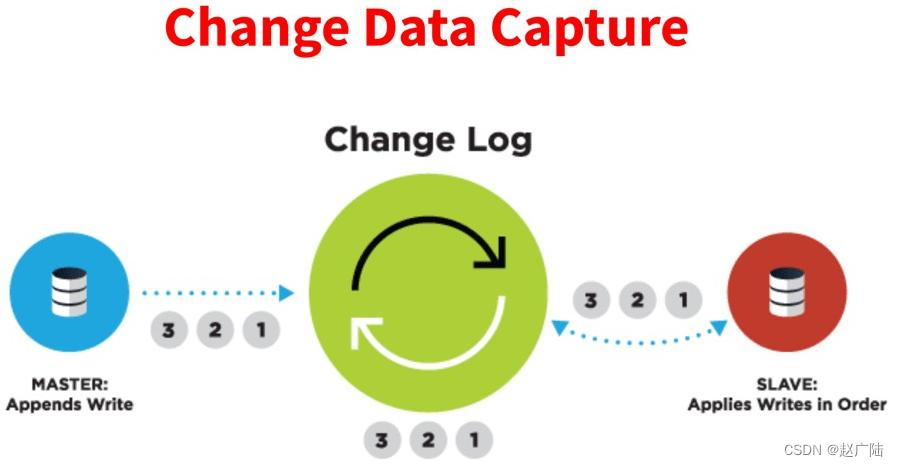
对于cdc,业界主要有两种类型:一是基于查询的,客户端会通过sql方式查询源库表变更数据,然后对外发送。二是基于日志,这也是业界广泛使用的一种方式,一般是通过binlog方式,变更的记录会写入binlog,解析binlog后会写入消息系统,或直接基于flink cdc进行处理。
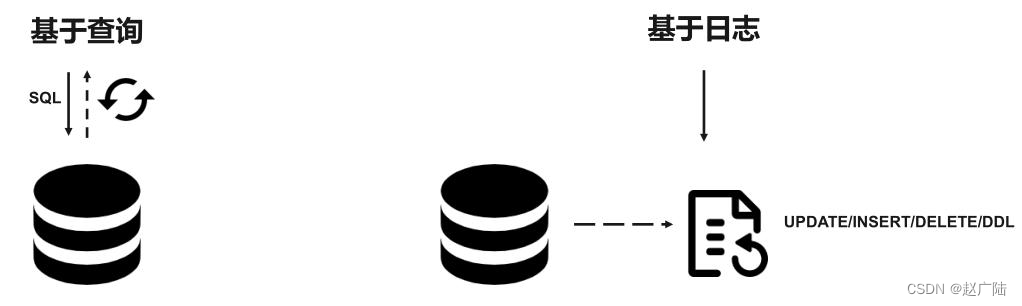
■基于查询:这种 cdc 技术是入侵式的,需要在数据源执行 sql 语句。使用这种技术实现cdc 会影响数据源的性能。通常需要扫描包含大量记录的整个表。
■基于日志:这种 cdc 技术是非侵入性的,不需要在数据源执行 sql 语句。通过读取源数据库的日志文件以识别对源库表的创建、修改或删除数据。
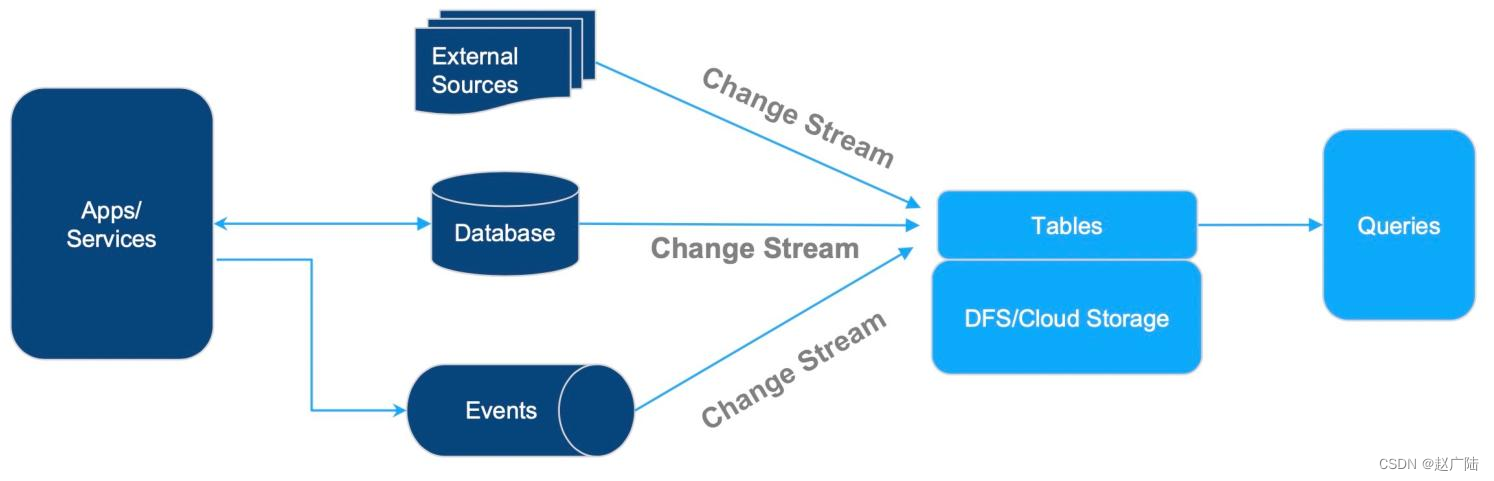
5.1 cdc 数据入湖
基于cdc数据的入湖,这个架构非常简单:上游各种各样的数据源,比如db的变更数据、事件流,以及各种外部数据源,都可以通过变更流的方式写入表中,再进行外部的查询分析。
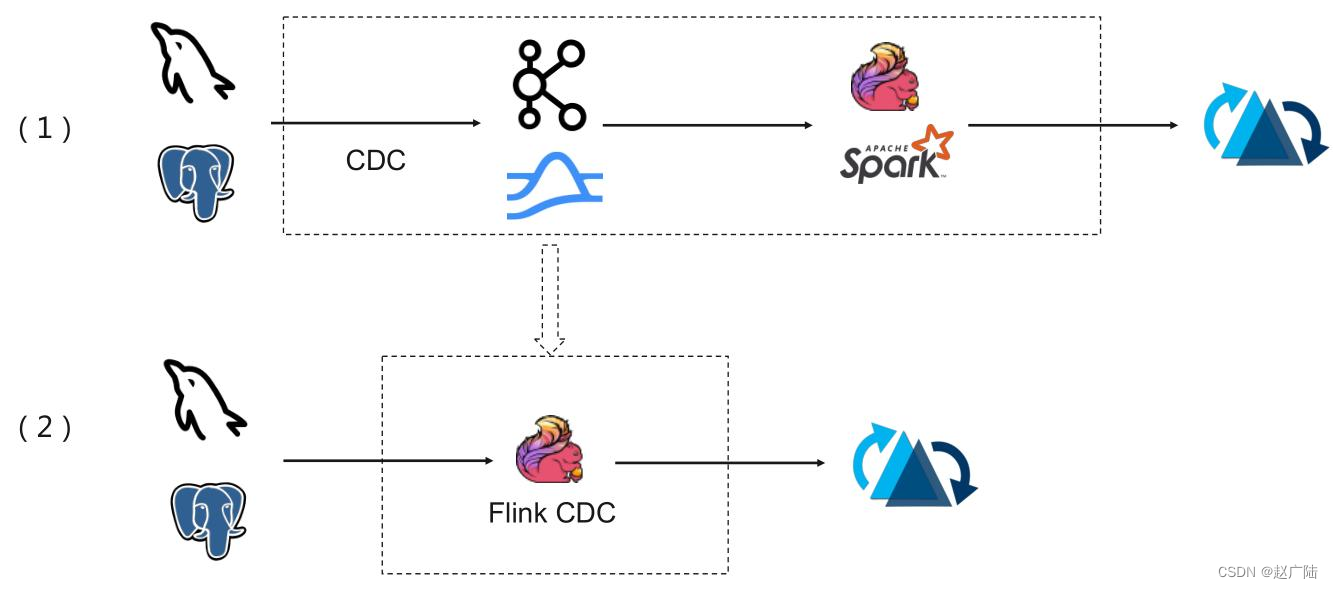
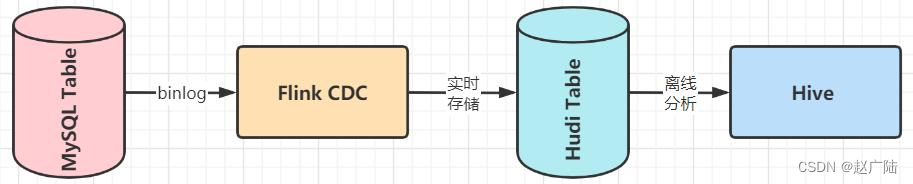
典型cdc入湖的链路:上面的链路是大部分公司采取的链路,前面cdc的数据先通过cdc工具导入kafka或者pulsar,再通过flink或者是spark流式消费写到hudi里。第二个架构是通过flink cdc直联到mysql上游数据源,直接写到下游hudi表。
5.2 flink cdc hudi
基于flink cdc技术,实时采集mysql数据库表数据,进行过etl转换处理,最终存储hudi表。
5.2.1 业务需求
mysql数据库创建表,实时添加数据,通过flink cdc将数据写入hudi表,并且hudi与hive集成,自动在hive中创建表与添加分区信息,最后hive终端beeline查询分析数据。
hudi 表与hive表,自动关联集成,需要重新编译hudi源码,指定hive版本及编译时包含hive依赖jar包,具体步骤如下。
● 修改hudi集成flink和hive编译依赖版本配置
原因:现在版本hudi,在编译的时候本身默认已经集成的flink-sql-connector-hive的包,会和flink lib包下的flink-sql-connector-hive冲突。所以,编译的过程中只修改hive编译版本。
文件:hudi-0.9.0/packaging/hudi-flink-bundle/pom.xml

● 编译hudi源码
编译完成以后,有2个jar包,至关重要:
hudi-flink-bundle_2.12-0.9.0.jar,位于
hudi-0.9.0/packaging/hudi-flink-bundle/target,flink 用来写入和读取数据,将其拷贝至
katex parse error: unexpected character: '' at position 39: …同名jar包,先删除再拷贝。 ̲ hudi-hadoop-mr…hive_home/lib目录中。
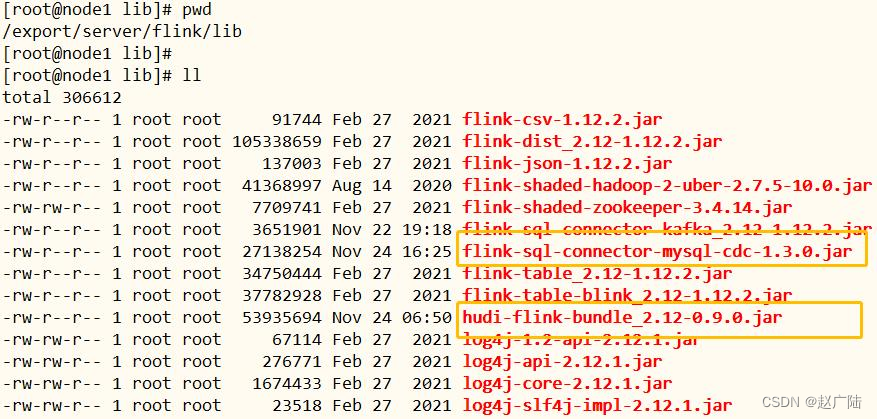
■ 将flink cdc mysql对应jar包,放到$flink_home/lib目录中
flink-sql-connector-mysql-cdc-1.3.0.jar
至此,$flink_home/lib目录中,有如下所需的jar包,缺一不可,注意版本号。
5.2.2 创建 mysql 表
首先开启mysql数据库binlog日志,再重启mysql数据库服务,最后创建表。
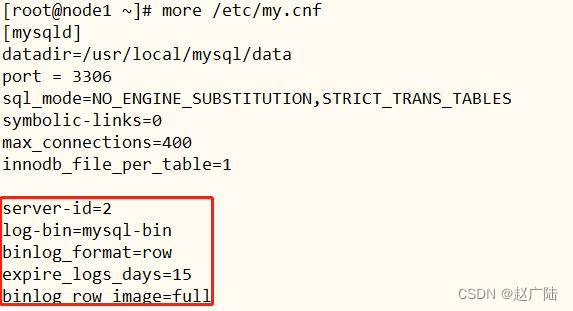
■第一步、开启mysql binlog日志
在[mysqld]下面添加内容:
server-id=2
log-bin=mysql-bin
binlog_format=row
expire_logs_days=15
binlog_row_image=full
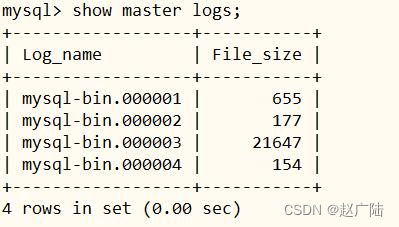
■第二步、重启mysql server
登录mysql client命令行,查看是否生效。
■第三步、在mysql数据库,创建表
– mysql 数据库创建表
create database test ;
create table test.tbl_users(
id bigint auto_increment primary key,
name varchar(20) null,
birthday timestamp default current_timestamp not null,
ts timestamp default current_timestamp not null
);
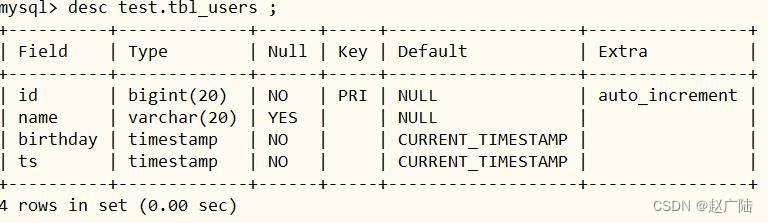
5.2.3 创建 cdc 表
先启动hdfs服务、hive metastore和hiveserver2服务和flink standalone集群,再运行sql client,最后创建表关联mysql表,采用mysql cdc方式。
● 启动hdfs服务,分别启动namenode和datanode
– 启动hdfs服务
● 启动hive服务:元数据metastore和hiveserver2
– hive服务
■启动flink standalone集群
– 启动flink standalone集群
■启动sql client客户端
设置属性:
● 创建输入表,关联mysql表,采用mysql cdc 关联
– flink sql client创建表
create table users_source_mysql (
id bigint primary key not enforced,
name string,
birthday timestamp(3),
ts timestamp(3)
) with (
'connector' = 'mysql-cdc',
'hostname' = 'node1.oldlu.cn',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'server-time-zone' = 'asia/shanghai',
'debezium.snapshot.mode' = 'initial',
'database-name' = 'test',
'table-name' = 'tbl_users'
);
查询表的结构,其中id为主键,ts为数据合并字段。
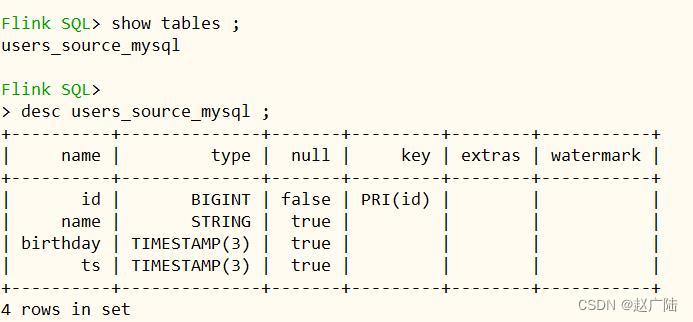
● 查询cdc表数据
– 查询数据

● 开启mysql client客户端,执行dml语句,插入数据
5.2.4 创建视图
创建一个临时视图,增加分区列part,方便后续同步hive分区表。
– 创建一个临时视图,增加分区列 方便后续同步hive分区表
查看视图view中数据
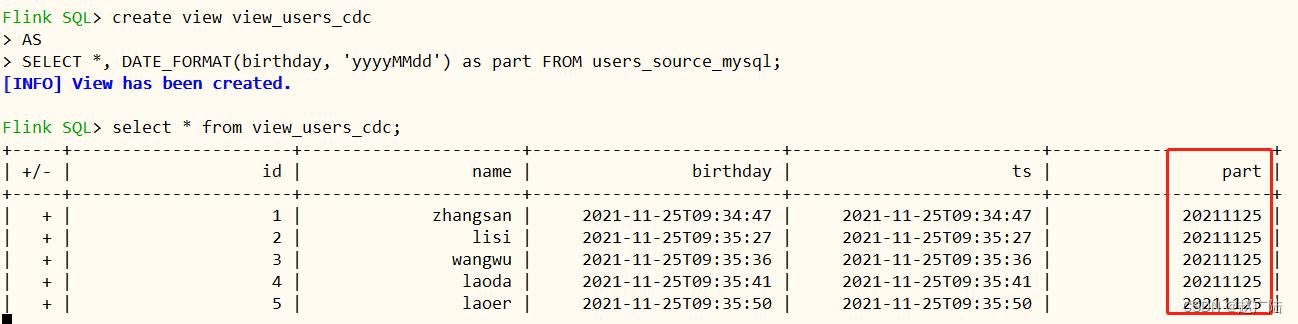
5.2.5 创建 hudi 表
创建 cdc hudi sink表,并自动同步hive分区表,具体ddl语句。
create table users_sink_hudi_hive(
id bigint ,
name string,
birthday timestamp(3),
ts timestamp(3),
part varchar(20),
primary key(id) not enforced
)
partitioned by (part)
with(
'connector'='hudi',
'path'= 'hdfs://node1.oldlu.cn:8020/ehualu/hudi-warehouse/users_sink_hudi_hive',
'table.type'= 'merge_on_read',
'hoodie.datasource.write.recordkey.field'= 'id',
'write.precombine.field'= 'ts',
'write.tasks'= '1',
'write.rate.limit'= '2000',
'compaction.tasks'= '1',
'compaction.async.enabled'= 'true',
'compaction.trigger.strategy'= 'num_commits',
'compaction.delta_commits'= '1',
'changelog.enabled'= 'true',
'read.streaming.enabled'= 'true',
'read.streaming.check-interval'= '3',
'hive_sync.enable'= 'true',
'hive_sync.mode'= 'hms',
'hive_sync.metastore.uris'= 'thrift://node1.oldlu.cn:9083',
'hive_sync.jdbc_url'= 'jdbc:hive2://node1.oldlu.cn:10000',
'hive_sync.table'= 'users_sink_hudi_hive',
'hive_sync.db'= 'default',
'hive_sync.username'= 'root',
'hive_sync.password'= '123456',
'hive_sync.support_timestamp'= 'true'
);
此处hudi表类型:mor,merge on read (读时合并),快照查询+增量查询+读取优化查询(近实时)。使用列式存储(parquet)+行式文件(arvo)组合存储数据。更新记录到增量文件中,然后进行同步或异步压缩来生成新版本的列式文件。
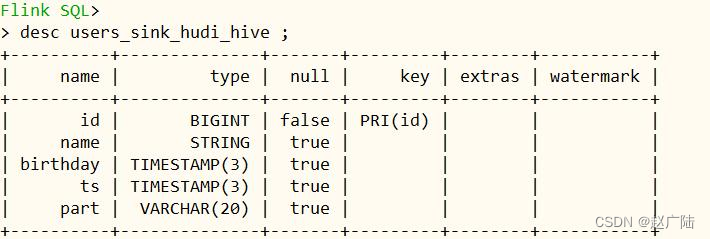
5.2.6 数据写入hudi表
编写insert语句,从视图中查询数据,再写入hudi表中,语句如下:
flink web ui dag图:
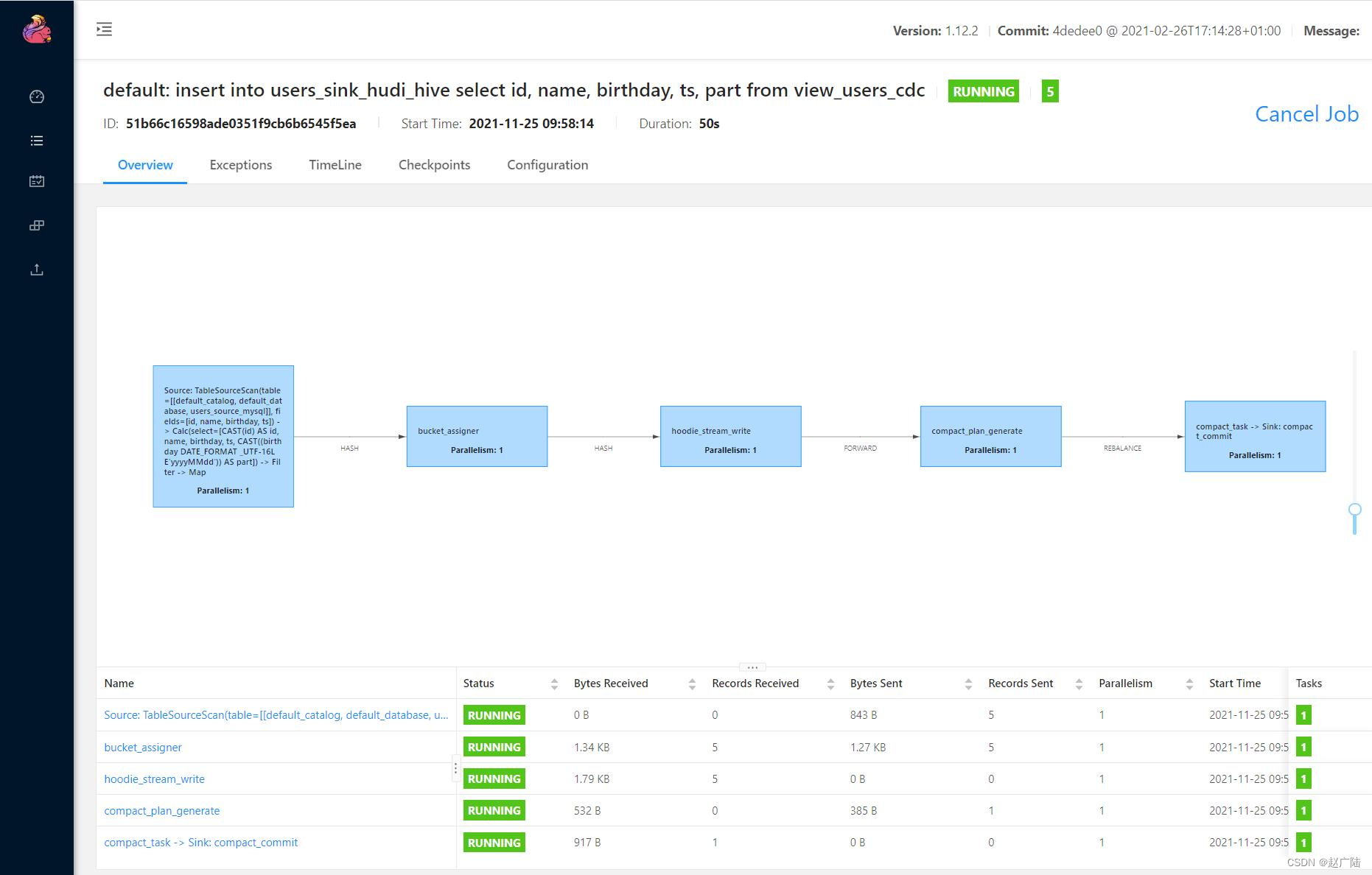
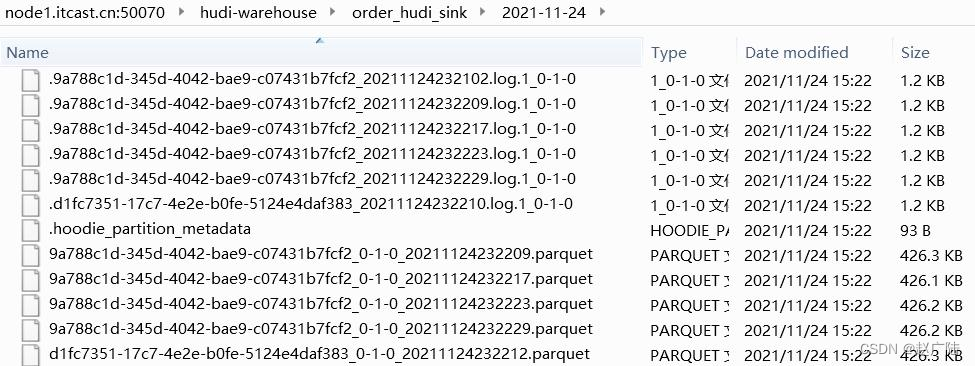
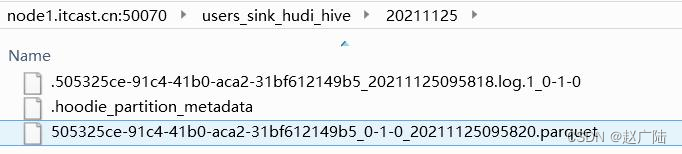
hdfs上hudi文件目录情况:
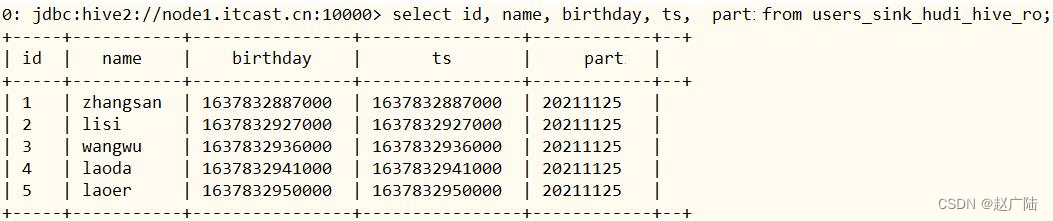
查询hudi表数据,select语句如下:

5.2.7 hive 表查询
需要引入hudi-hadoop-mr-bundle-0.9.0.jar包,放到$hive_home/lib下。
启动hive中beeline客户端,连接hiveserver2服务:
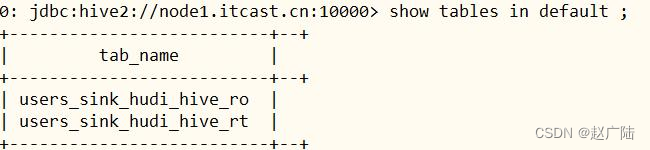
已自动生产hudi mor模式的2张表:
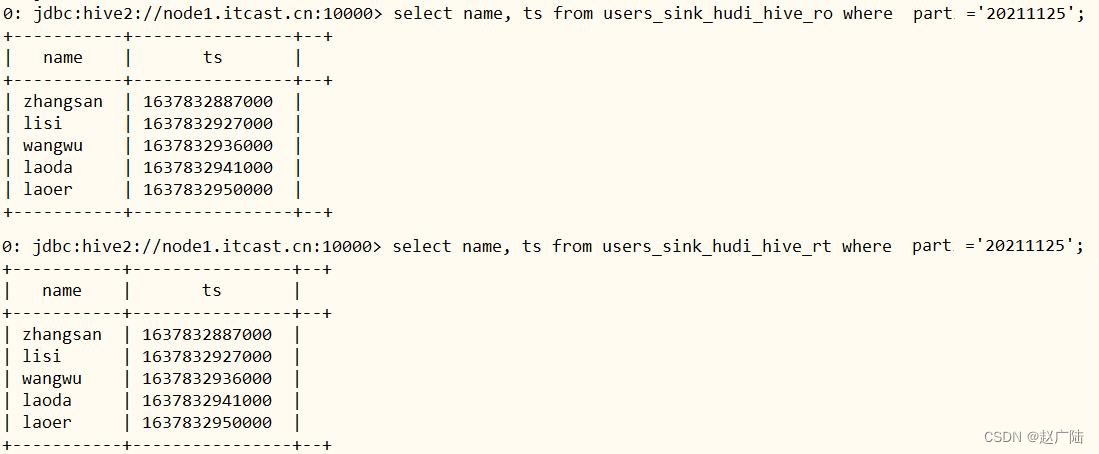
■users_sink_hudi_hive_ro,ro 表全称 read oprimized table,对于 mor 表同步的 xxx_ro 表,只暴露压缩后的 parquet。其查询方式和cow表类似。设置完 hiveinputformat 之后 和普通的 hive 表一样查询即可;
■users_sink_hudi_hive_rt,rt表示增量视图,主要针对增量查询的rt表;ro表只能查parquet文件数据, rt表 parquet文件数据和log文件数据都可查;
查看自动生成表users_sink_hudi_hive_ro结构:
create external table `users_sink_hudi_hive_ro`(
`_hoodie_commit_time` string comment '',
`_hoodie_commit_seqno` string comment '',
`_hoodie_record_key` string comment '',
`_hoodie_partition_path` string comment '',
`_hoodie_file_name` string comment '',
`_hoodie_operation` string comment '',
`id` bigint comment '',
`name` string comment '',
`birthday` bigint comment '',
`ts` bigint comment '')
partitioned by (
`part` string comment '')
row format serde
'org.apache.hadoop.hive.ql.io.parquet.serde.parquethiveserde'
with serdeproperties (
'hoodie.query.as.ro.table'='true',
'path'='hdfs://node1.oldlu.cn:8020/users_sink_hudi_hive')
stored as inputformat
'org.apache.hudi.hadoop.hoodieparquetinputformat'
outputformat
'org.apache.hadoop.hive.ql.io.parquet.mapredparquetoutputformat'
location
'hdfs://node1.oldlu.cn:8020/users_sink_hudi_hive'
tblproperties (
'last_commit_time_sync'='20211125095818',
'spark.sql.sources.provider'='hudi',
'spark.sql.sources.schema.numpartcols'='1',
'spark.sql.sources.schema.numparts'='1',
'spark.sql.sources.schema.part.0'='{\"type\":\"struct\",\"fields\":[{\"name\":\"_hoodie_commit_time\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"_hoodie_commit_seqno\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"_hoodie_record_key\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"_hoodie_partition_path\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"_hoodie_file_name\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"_hoodie_operation\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"id\",\"type\":\"long\",\"nullable\":false,\"metadata\":{}},{\"name\":\"name\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"birthday\",\"type\":\"timestamp\",\"nullable\":true,\"metadata\":{}},{\"name\":\"ts\",\"type\":\"timestamp\",\"nullable\":true,\"metadata\":{}},{\"name\":\"part\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}}]}',
'spark.sql.sources.schema.partcol.0'='partition',
'transient_lastddltime'='1637743860')
查看自动生成表的分区信息:
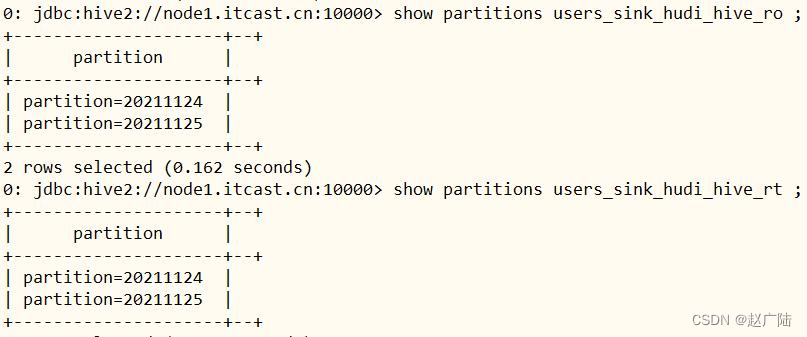
查询hive 分区表数据
指定分区字段过滤,查询数据
5.3 hudi client操作hudi表
进入hudi客户端命令行:hudi-0.9.0/hudi-cli/hudi-cli.sh
连接hudi表,查看表信息

查看hudi commit信息

查看hudi compactions 计划



![aidl文件生成Java、C++[android]、C++[ndk]、Rust接口](/images/newimg/nimg4.png)


发表评论