hadoop在wsl中的安装
1.环境准备
在hadooop的官网上下载对应的安装包:hadoop
 使用命令
使用命令
tar -xvzf 进行解压:
tar -xvzf hadoop-3.3.4.tar.gz
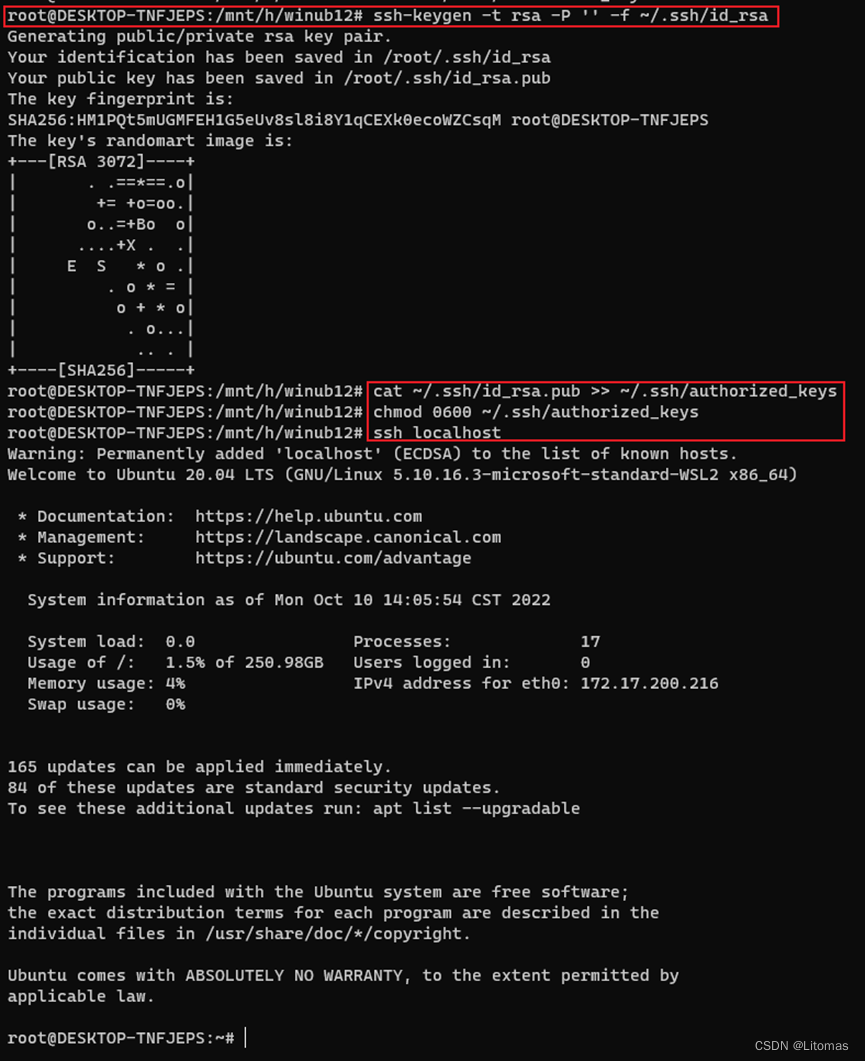
使用hadoop时需要设置ssh免密登录,接下来设置ssh localhost
命令如下:
ssh-keygen -t rsa -p '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
2.修改配置文件
接下来修改相应的配置文件:
vi etc/hadoop/core-site.xml
vi etc/hadoop/hdfs-site.xml
vi etc/hadoop/mapred-site.xml
vi etc/hadoop/yarn-site.xml
vi etc/hadoop/hadoop-env.sh
core-site.xml文件修改如下:
<configuration>
<property>
<name>fs.defaultfs</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml文件修改如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
mapred-site.xml文件修改如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$hadoop_mapred_home/share/hadoop/mapreduce/*:$hadoop_mapred_home/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
hadoop-env.sh文件添加以下内容:
export java_home=/usr/lib/jvm/java-8-openjdk-amd64 #这个根据自己的java路径进行修改
export hdfs_namenode_user=root
export hdfs_datanode_user=root
export hdfs_secondarynamenode_user=root
export yarn_resourcemanager_user=root
export yarn_nodemanager_user=root
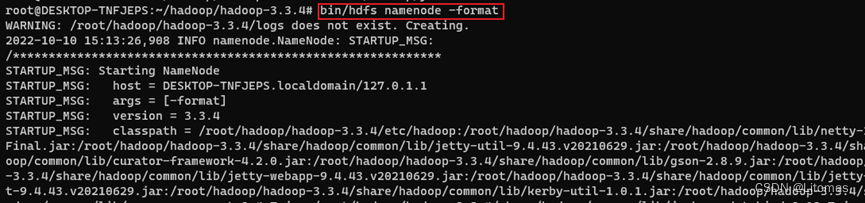
随后就可以初始化hadoop集群了
bin/hdfs namenode -format
3.启动hadoop集群的守护进程
启动dfs守护进程:
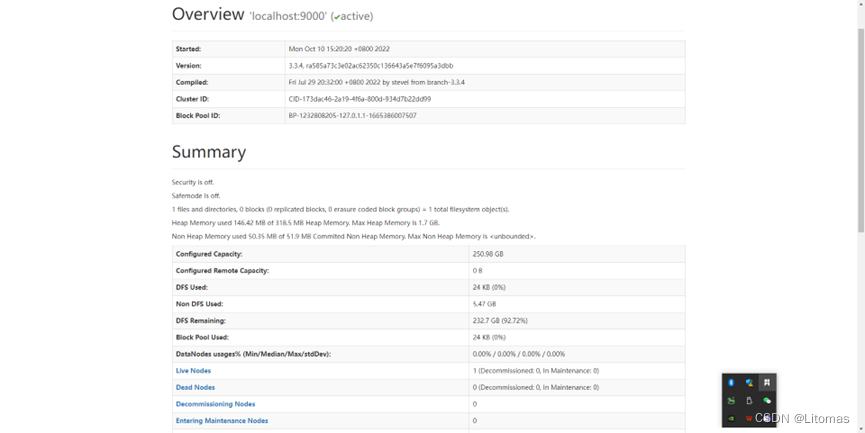
sbin/start-dfs.sh

启动了dfs守护进程后,通过访问 http://localhost:9870/dfshealth.html#tab-overview 来查看namenode。
启动yarn守护进程
sbin/start-yarn.sh

之后通过访问http://localhost:8088/cluster来查看yarn资源管理界面:

4.运行实例

test.txt文件中的内容
新建hadoop中hdfs文件系统的目录,并传入文件test.txt
hadoop fs -mkdir /input
hadoop fs -put test.txt /input
随后运行,hadoop中的wordcount程序
bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount /input /output
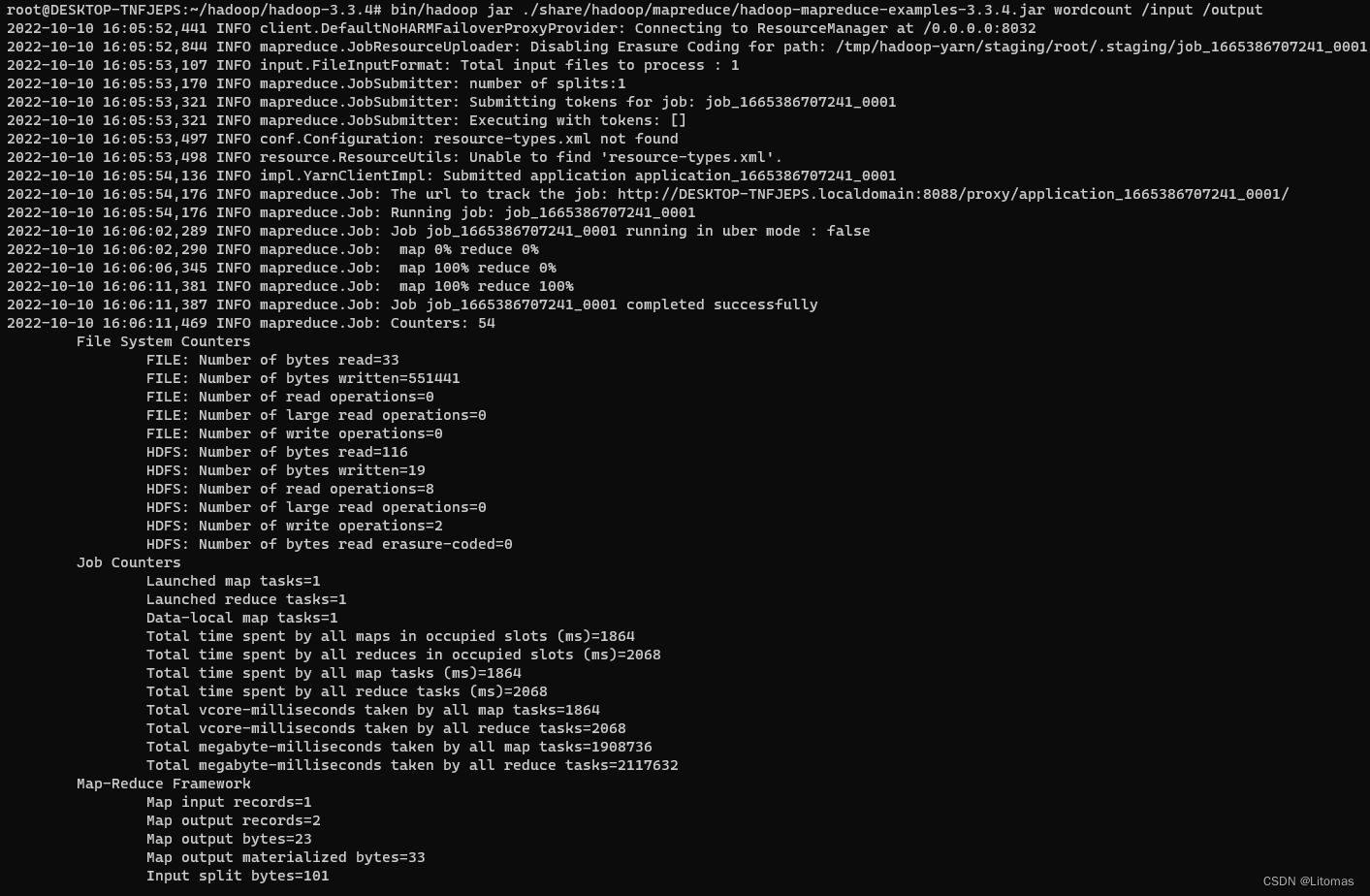
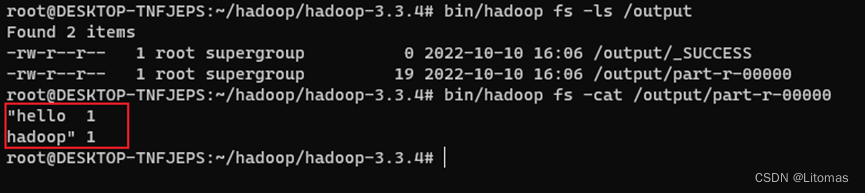
查看测试结果文件:
bin/hadoop fs -cat /output/part-r-00000
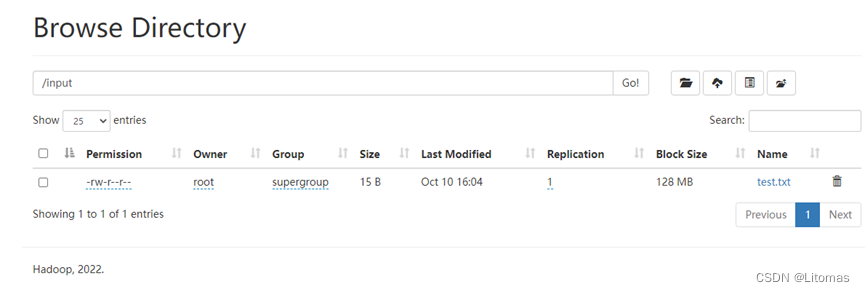
访问ui界面也可以查看input和output中的文件:





发表评论