hadoop 复习 ---- chapter04
-
hdfs 的特性
1:它是一个分布式文件系统,适用于一次写入,多次读取的场景。
2:它是一个主从结构体系,由 namenode + datanode + (secondarynamenode)
3:namenode : datanode = 1 : n
4:namenode:负责文件的命名空间
5:datanode:主要对数据进行存储
6:secondarynamenode:是 namenode 的冷备 -
hdfs 适合对大数据的存储,大数据我们应该如何存储呢?
大数据的存储我们采用的是分而治之的思想。我们将一个大文件分成若干小文件进行存储。 -
那么分成的小文件多大的?
128m -
一个文件的操作需要两步
寻址时间 : 传输时间 = 1 : 100 = 10ms : 1s
我们硬盘的传输速率一般 100m/s -
hadoop2.x 默认 block 128m
-
hadoop3.x 默认 block 64m
-
一个集群的最小节点数量 2n+1 n>=1
-
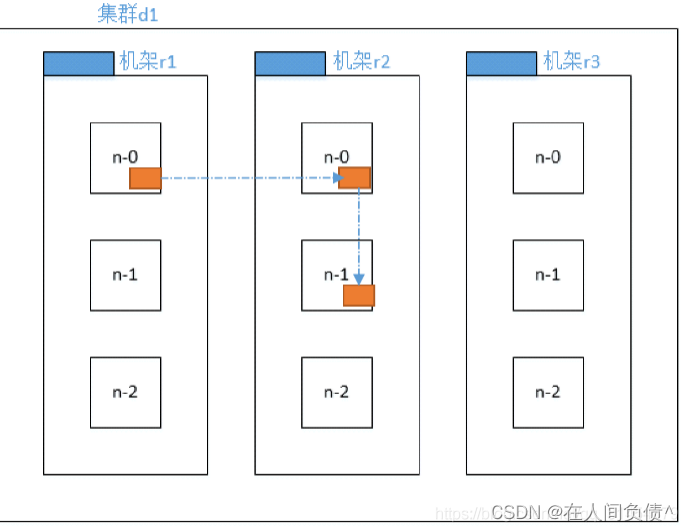
hadoop 默认有 3 个副本(3 个副本怎么存放呢?)
机架感知策略
第一个副本放置在随机的一个机架上的一个节点上。
第二个副本放置在第一个副本相邻的机架上的任意节点上。
第三个副本放置在第一个副本的机架的相邻节点上。
-
namednode:用来管理文件系统的命名空间
-
namenode 的数据主要包含两部分:内存元数据 + 硬盘元数据
内存元数据:是真实的,是实时更新的最新的命令空间
硬盘元数据:是持久化的,序列化的问价。fsimage + edit -
模拟:对命令空间的增加操作
1:我们在启动 namenode 之前,应该先对 namenode 进行格式化。
hdfs namenode -format
2:启动 namenode,start-all.sh,是不是也在启动 datanode,datanode 会主动将他的信息发送给 namenode,所以 namenode 拥有 datanode 的命名空间信息。
3:我们要添加一个命名空间。
4:首先将添加操作记录到 edit01 文件中。且同步到 secondarynamenode(edit 文件只记录事务性操作)
5:内存元数据真实对命名空间进行操作。这时没内存元数据的数据就是最新数据,如果你要进行查询操作,你是对内存元数据进行的查询操作。
6:edit01 文件会变得越来越大,我们不希望他越来越大。
7:secondarynamenode 设置一个检查带你 checkpoint。
主要满足下面任意一条件,进行数据合并 fsimage + edit01
1、edit01 满足一定的大小
2、edit01 满足一定的存活时间
8:secondarynamenode 要进行合并,它会告知 namenode。这时 namenode 会滚动生成一个新的 edit02 文件,后面的所有操作写入到 edit02 文件中。
9:secondarynamenode 要进行合并文件 fsimage.check
10:secondarynamenode 将文件 fsimage.check 上传到 namenode
11:namenode 重命名 fsimage.check 为 fsimage,覆盖原有文件。
剩下的操作重复 3-11 的操作
-
hadoop.tmp.dir = /opt.hadoop/tmp:存放临时文件的目录
-
dfs.name.dir = /opt/hadoop/namenode:存放 namenode 信息的目录
-
dfs.data.dir = /opt/hadoop/datanode:存放 datanode 信息的目录
-
所有的 hdfs 通信协议都是构建在 tcp/ip 协议上。
clientprotocal:client 和 namenode 之间的通信协议
datanodeprotatal:datanode 和 namenode 之间的通信协议
从 clientprotocol 和 datanodeprotocol 抽象出来一个远程调用(rpc),在设计上,namenode 不会主动发起 rpc,而是响应来自客户端和 datanode 的 rpc 请求。 -
hdfs 的安全模式
hdfs:1个 namenode + n个datanode + 1个secondarynamenode
我们启动 hdfs 顺序:namenode -> datanode -> secondarynamenode
namenode 启动成功,但是 datanode 并未全部启动成功。
当每个 datanode 启动成功后,会主动的汇报他的信息到 namenode。
当 namenode 收集到的 datanode 启动的成功率达到 99%。
namenode 会等待 30s,然后 namenode 退出安全模式。
在过程中,namenode 处于安全模式下,不能修改。 -
客户端读取文件的流程。
读取文件需要使用什么?
io 流。我们以前的 io 流,都是对本地文件的读取。
那么我们如果对 hdfs 上的文件进行读取呢?
hadoop 就封装了一个 fsdatainputstream 对象,用于对 hdfs 上的文件的读取。
hadoop 就封装了一个 fsdataoutputstream 对象,用于对 hdfs 上的文件的写入。 -
hadoop 会有一些操作指令,那么这些操作指令在哪里呢?
在 hadoop 的安装包目录下 sbin 和 bin 目录中。 -
hadoop 组件 = hdfs + mapreduce(yarn)+ common
-
sbin:放置了 hadoop 组件的启动命令
-
start-all.sh:启动所有的 hadoop 组件
-
start-dfs.sh:启动 hdfs 组件 namenode + datanode + secondarynamenode
-
start-yarn.sh:启动 yarn 组件 resourcemanager + nodemanager
-
bin:放置了 hadoop 组件的操作命令
-
hadoop and hdfs 是对 hdfs 进行操作的命令
下面我们重点讲解 hadoop and hdfs.
- 查询所有指令
[niit@niit-master ~]$ hadoop fs
[niit@niit-master ~]$ hdfs dfs
usage: hadoop fs [generic options]
[-appendtofile <localsrc> ... <dst>]
[-cat [-ignorecrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-r] group path...]
[-chmod [-r] <mode[,mode]... | octalmode> path...]
[-chown [-r] [owner][:[group]] path...]
[-copyfromlocal [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-copytolocal [-f] [-p] [-ignorecrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createsnapshot <snapshotdir> [<snapshotname>]]
[-deletesnapshot <snapshotdir> <snapshotname>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-x] <path> ...]
[-expunge]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-ignorecrc] [-crc] <src> ... <localdst>]
[-getfacl [-r] <path>]
[-getfattr [-r] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-help [cmd ...]]
[-ls [-c] [-d] [-h] [-q] [-r] [-t] [-s] [-r] [-u] [<path> ...]]
[-mkdir [-p] <path> ...]
[-movefromlocal <localsrc> ... <dst>]
[-movetolocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-renamesnapshot <snapshotdir> <oldname> <newname>]
[-rm [-f] [-r|-r] [-skiptrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-r] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-r] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignorecrc] <src> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
- 获取帮助文档
查看所有指令的详细的帮准文档
[niit@niit-master ~]$ hdfs dfs -help
查看指定指令的详细的帮准文档
[niit@niit-master ~]$ hdfs dfs -help rm
- -ls :显示目录结构
注意: hdfs和linux具有相同的目录结构,使用相同树结构进行存储.
[niit@niit-master ~]$ hdfs dfs -ls /
found 3 items
drwxr-xr-x - niit supergroup 0 2020-08-19 19:11 /hbase
drwx------ - niit supergroup 0 2022-09-09 11:43 /tmp
drwxr-xr-x - niit supergroup 0 2020-07-28 09:40 /user
[niit@niit-master ~]$ hdfs dfs -ls ./
found 2 items
-rw-r--r-- 1 niit supergroup 171 2020-08-19 17:58 init.txt
drwxr-xr-x - niit supergroup 0 2020-08-19 19:25 jars
注意:
niit用户在linux系统中默认家目录 /home/niit
niit用户在hdfs系统中指定家目录 /user/niit
- -mkdir:在hdfs上创建空目录
[niit@niit-master ~]$ hdfs dfs -mkdir andy
andy创建在哪里? /user/niit/andy
- -movefromlocal:将本地文件上传到hdfs中
[niit@niit-master ~]$ vi niit.txt
[niit@niit-master ~]$ cat niit.txt
hadoop
[niit@niit-master ~]$ hdfs dfs -movefromlocal ./niit.txt ./
- -cat:查看hdfs中文件的内容
[niit@niit-master ~]$ hdfs dfs -cat ./niit.txt
hadoop
- -copyfromlocal:复制本地文件到hdfs
[niit@niit-master ~]$ vi qdu.txt
[niit@niit-master ~]$ cat qdu.txt
hbase
[niit@niit-master ~]$ hdfs dfs -copyfromlocal ./qdu.txt ./andy
- -chgrp -chown -chmod:修改hdfs文件的所属和权限
[niit@niit-master ~]$ hdfs dfs -chown -r niit:niit ./andy
[niit@niit-master ~]$ hdfs dfs -chmod 777 ./andy/qdu.txt
- -copytolocal:将hdfs上的文件拷贝到本地
[niit@niit-master ~]$ hdfs dfs -copytolocal ./niit.txt ./
- -cp:hdfs中文件的相互拷贝
[niit@niit-master ~]$ hdfs dfs -cp ./niit.txt ./andy
- -mv:hdfs中文件的相互移动
[niit@niit-master ~]$ hdfs dfs -mv ./niit.txt ./anna
- -get:等价于-copytolocal:将hdfs上的文件拷贝到本地
[niit@niit-master ~]$ rm -rf *
[niit@niit-master ~]$ hdfs dfs -get ./anna/niit.txt ./
- -put:等价于-copyfromlocal:复制本地文件到hdfs
[niit@niit-master ~]$ hdfs dfs -put ./niit.txt ./
- -getmerge:合并下载多个文件
[niit@niit-master ~]$ hdfs dfs -getmerge ./andy/ ./and.txt
[niit@niit-master ~]$ ll
总用量 8
-rw-r--r--. 1 niit niit 13 9月 9 15:10 and.txt
-rw-r--r--. 1 niit niit 7 9月 9 15:08 niit.txt
[niit@niit-master ~]$ cat and.txt
hadoop
hbase
- -tail:显示hdfs中文件的末尾的内容
[niit@niit-master ~]$ hdfs dfs -tail ./niit.txt
- -rm:删除hdfs上的普通文件
[niit@niit-master ~]$ hdfs dfs -rm ./anna
rm: `anna': is a directory
[niit@niit-master ~]$ hdfs dfs -rm ./niit.txt
deleted niit.txt
- -rmdir:删除hdfs上的空目录
[niit@niit-master ~]$ hdfs dfs -rmdir ./anna
rmdir: `anna': directory is not empty
- -rmr:层级删除hdfs上的目录
[niit@niit-master ~]$ hdfs dfs -rmr ./anna
rmr: deprecated: please use '-rm -r' instead.
deleted anna
- -du:查看目录信息
[niit@niit-master ~]$ hdfs dfs -du ./andy
7 andy/niit.txt
6 andy/qdu.txt
- -setrep:设置文件的副本数
[niit@niit-master ~]$ hdfs dfs -setrep 3 ./andy/niit.txt
replication 3 set: andy/niit.txt
- jar :运行hadoop的jar包
[niit@niit-master ~]$ hadoop jar /usr/local/hadoop-2.9.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /user/niit/input /user/niit/output
指定我们的jar路径: /usr/local/hadoop-2.9.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar
jar中的主方法的名字: wordcount (对输入文件进行单词统计)
该主方法的第一参数指定输入文件: /user/niit/input
该主方法的第二参数指定输出文件: /user/niit/output
注意:输出文件一定不能存在,否则报错




发表评论