一、分区的定义
二、静态分区、动态分区对比
静态分区与动态分区的主要区别在于静态分区是手动指定,是编译时进行分区。支持load和insert两种插入方式。适合于分区数少、分区名可以明确的数据
而动态分区是通过数据来进行判断,是在sql执行时进行分区。只支持inset这一种插入方式。需要先开启动态设置。实际项目里按日期进行分区的数据一般都是动态分区
三、hdfs数据准备
(一)hdfs文件后缀名以日期区分
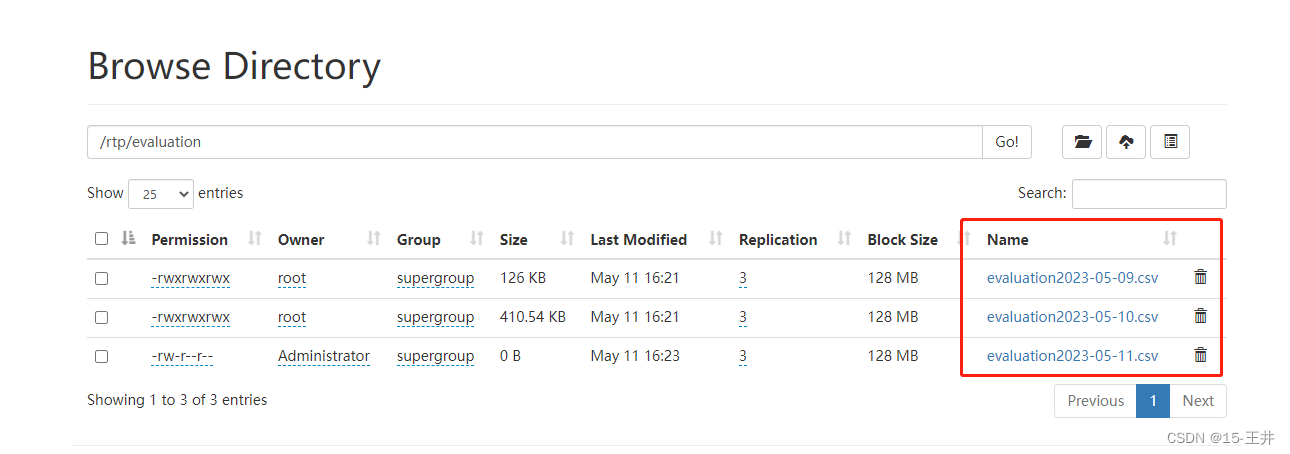
(二)查看数据样式

四、hive建普通外部表 不分区
(一)建表语句
create external table if not exists ods_evaluation(
device_no string comment '设备编号',
cycle int comment '评价数据周期',
lane_num int,
create_time timestamp comment '创建时间',
lane_no int comment '车道编号',
volume int comment '车道内过停止线流量(辆)',
queue_len_max float comment '车道内最大排队长度(m)',
sample_num int comment '评价数据计算样本量',
stop_avg int comment '车道内平均停车次数(次)',
delay_avg float comment '车道内平均延误时间(s)',
stop_rate float comment '车道内一次通过率',
travel_dist float comment '车道内检测行程距离(m)',
travel_time_avg float comment '车道内平均行程时间'
)
comment '评价数据表'
row format delimited fields terminated by ','
stored as textfile location '/rtp/evaluation'
tblproperties("skip.header.line.count"="1") ;
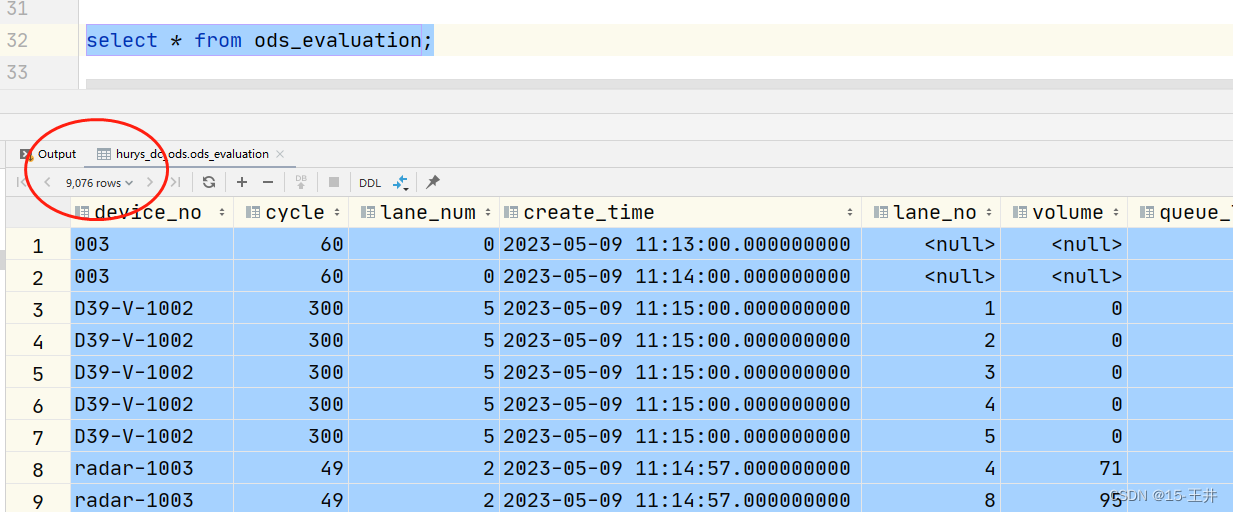
(二)结果展示 共9076条数据
五、静态分区
(一)建表语句
create external table if not exists ods_evaluation_static(
device_no string comment '设备编号',
cycle int comment '评价数据周期',
lane_num int,
create_time timestamp comment '创建时间',
lane_no int comment '车道编号',
volume int comment '车道内过停止线流量(辆)',
queue_len_max float comment '车道内最大排队长度(m)',
sample_num int comment '评价数据计算样本量',
stop_avg int comment '车道内平均停车次数(次)',
delay_avg float comment '车道内平均延误时间(s)',
stop_rate float comment '车道内一次通过率',
travel_dist float comment '车道内检测行程距离(m)',
travel_time_avg float comment '车道内平均行程时间'
)
comment '评价历史数据表 静态分区'
partitioned by (day string) --分区字段不能是表中已经存在的数据,可以将分区字段看作表的伪列。
row format delimited fields terminated by ','
tblproperties("skip.header.line.count"="1") ;
注意点:
1、指定的分区字段不能是表中已经存在的数据 我这边分区字段为day 而表中没有这个字段
2、建表没有指定文件路径
(二)加载数据(有坑)
注意:从hdfs中加载数据到hive,如果直接load hdfs中的数据到hive中,那么原hdfs数据文件就会消失在原路径,而是去了一个hive的新地方。直接load,这种行为它类似于剪切,而不是我们所希望的复制文件。 这是一个坑!!!
所以如果我们希望既可以load数据到hive,还能够保存hdfs的原文件,那么必须采用迂回策略,从hdfs先到本地,再load到hive。比如加载hdfs中2023-05-09的数据
先从hdfs到l本地 /opt/hdfs_rtp/
[root@hurys22 conf]# hdfs dfs -get /rtp/evaluation/evaluation2023-05-09.csv /opt/hdfs_rtp/
从本地加载到hive
load data local inpath '/opt/hdfs_rtp/evaluation2023-05-09.csv' into table ods_evaluation_static partition(day='2023-05-09');
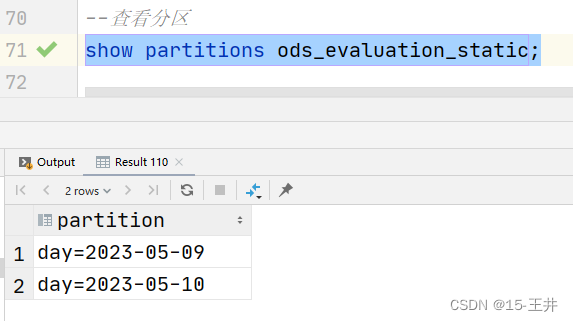
(三)查看分区
show partitions ods_evaluation_static;
(四)查看数据

六、动态分区
(一)建表语句
create external table if not exists ods_evaluation_trends(
device_no string comment '设备编号',
cycle int comment '评价数据周期',
lane_num int,
create_time timestamp comment '创建时间',
lane_no int comment '车道编号',
volume int comment '车道内过停止线流量(辆)',
queue_len_max float comment '车道内最大排队长度(m)',
sample_num int comment '评价数据计算样本量',
stop_avg int comment '车道内平均停车次数(次)',
delay_avg float comment '车道内平均延误时间(s)',
stop_rate float comment '车道内一次通过率',
travel_dist float comment '车道内检测行程距离(m)',
travel_time_avg float comment '车道内平均行程时间'
)
comment '评价历史数据表 动态分区'
partitioned by (day string)
row format delimited fields terminated by ',';
注意:由于动态分区不是load文件,所以建表时不需要截掉第一行数据 tblproperties("skip.header.line.count"="1")
(二)开启动态分区
--开启动态分区功能(默认 true,开启) set hive.exec.dynamic.partition=true; --设置为非严格模式 nonstrict 模式表示允许所有的分区字段都可以使用动态分区 set hive.exec.dynamic.partition.mode=nonstrict; --在每个执行 mr 的节点上,最大可以创建多少个动态分区 set hive.exec.max.dynamic.partitions.pernode=1000; --在所有执行 mr 的节点上,最大一共可以创建多少个动态分区。默认 1000 set hive.exec.max.dynamic.partitions=1500;
(三)动态加载数据(insert overwrite)
insert overwrite table ods_evaluation_trends partition(day)
select device_no, cycle, lane_num, create_time, lane_no, volume, queue_len_max, sample_num, stop_avg, delay_avg, stop_rate,
travel_dist, travel_time_avg,date(create_time) day
from ods_evaluation;
注意:insert overwrite的用法
insert into 与 insert overwrite 都可以向hive表中插入数据,但是insert into是直接追加到目前表中数据的尾部,而insert overwrite则会重写数据,即先删除数据,再写入数据。如果存在分区的情况,insert overwrite只重写当前分区
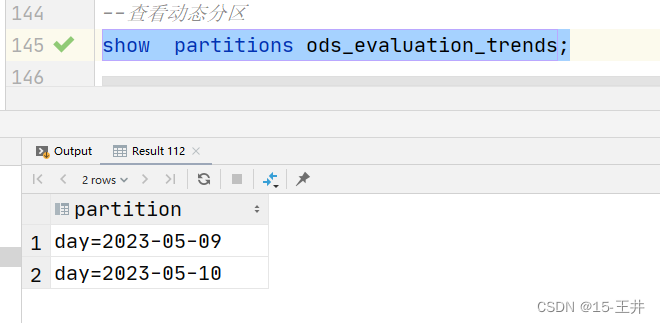
(四)查看动态分区
show partitions ods_evaluation_trends;
(五)查看数据





发表评论