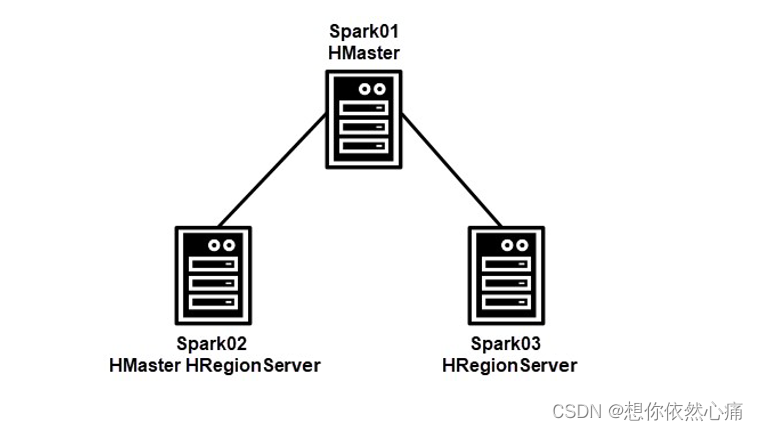
hbase是一个面向列的分布式存储数据库。hbase的运行依赖于hadoop和zookeeper,hbase利用hdfs作为其文件存储系统;利用mapreduce处理hbase中的数据;利用zookeeper作为分布式应用程序协调服务,同时存储hbase集群的元数据信息可以为hbase集群提供故障自动转移功能,以保证hbase集群的高可用。集群规划如下图所示:
一、安装hbase集群
- 下载hbase
访问apache资源网站下载linux操作系统的hbase安装包hbase-1.2.1-bin.tar.gz。
注意:还没有下载安装包的,下载地址可以去这里查看:
-
上传hbase安装包
使用securecrt远程连接工具连接虚拟机spark01,在存放应用安装包的目录/export/software/下执行“rz”命令上传hbase安装包。 -
安装hbase
在虚拟机spark01中,通过解压缩的方式安装hbase,将hbase安装到存放应用的目录/export/servers/。
tar -zxvf /export/software/hbase-1.2.1-bin.tar.gz -c /export/servers/ -
修改配置文件hbase-env.sh
在hbase安装目录下的conf目录,执行“vi hbase-env.sh”命令编辑hbase配置文件hbase-env.sh,配置hbase运行时的相关参数。
# 指定jdk安装目录。
export java_home=/export/servers/jdk1.8.0_161
#指定不使用内置的zookeeper
export hbase_manages_zk=false
- 修改配置文件hbase-site.xml
在hbase安装目录下的conf目录,执行“vi hbase-site.xml”命令编辑hbase配置文件hbase-site.xml,配置hbase相关参数。
<property >
<name>hbase.rootdir</name>#hbase集群中所有hregionserver共享目录,用来持久化hbase的数据
<value>hdfs://master/hbase</value>
</property>
<property >
<name>hbase.cluster.distributed</name>#设置hbase的存储模式为分布式存储
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>#设置zookeeper的服务器地址
<value>spark01:2181,spark02:2181,spark03:2181</value>
</property>
- 修改配置文件regionservers
在hbase安装目录下的conf目录,执行“vi regionservers”命令编辑hbase配置文件regionservers,配置运行hregionserver所在的服务器主机名。
spark02
spark03
-
复制hadoop配置文件
进入hadoop安装目录的conf目录,将配置文件core-site.xml和hdfs-site.xml复制到hbase安装目录下的conf目录,用于hbase启动时读取hadoop的核心配置信息和hdfs配置信息。
cp {core-site.xml,hdfs-site.xml} /export/servers/hbase-1.2.1/conf/ -
配置备用hmaster
在hbase安装目录下的conf目录,执行“vi backup-masters”命令编辑备用hmaster配置文件backup-masters,配置备用hmaster所在的服务器主机名spark02。 -
分发hbase安装目录
为了便于快速配置hbase集群中其他服务器,将虚拟机spark01中的hbase安装目录分发到虚拟机spark02和spark03。
scp -r /export/servers/hbase-1.2.1/ root@spark02:/export/servers/
scp -r /export/servers/hbase-1.2.1/ root@spark03:/export/servers/
- 配置hbase环境变量
分别在虚拟机spark01、spark02和spark03,执行“vi /etc/profile”命令编辑系统环境变量文件profile,配置hbase环境变量。
export hbase_home=/export/servers/hbase-1.2.1
export path=$path:$hbase_home/bin
系统环境变量文件profile配置完成后保存并退出即可,随后执行“source /etc/profile”命令初始化系统环境变量使配置内容生效。
二、 启动hbase集群
- 在确保zookeeper集群和hadoop高可用集群正常启动的情况下,在虚拟机spark01中执行“
start-hbase.sh”命令启动hbase高可用集群。
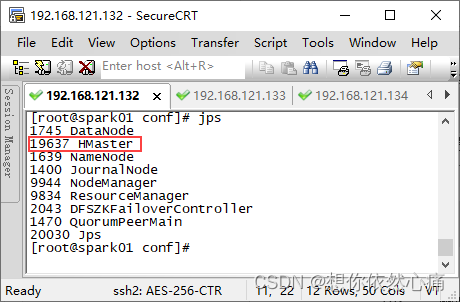
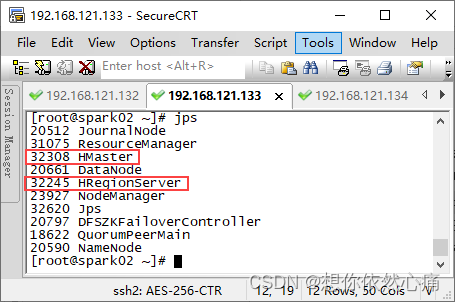
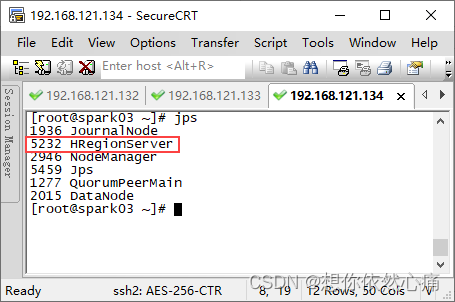
注意:启动hbase集群警告
若启动hbase时出现“java hotspot™ 64-bit server vm warning: ignoring option xxx; support was removed in 8.0”警告信息,这是因为我们使用jdk的版本为8,此时我们可以在hbase-env.sh文件中注释如下内容即可,再次重启hbase集群便不会再出现警告。
#export hbase_master_opts="$hbase_master_opts -xx:permsize=128m -xx:maxpermsize=128m"
#export hbase_regionserver_opts="$hbase_regionserver_opts -xx:permsize=128m -xx:maxpermsize=128m"
好了,hbase的集群部署我们就讲到这里了,下一篇我们将讲解kafka集群部署
转载自:
欢迎start,欢迎评论,欢迎指正





发表评论