前沿-同系列文章
用粗快猛 + 大模型问答 + 讲故事学习方式快速掌握大数据技术知识,每篇都有上万字,如果觉得太长,看开始的20%,有所收获就够了,剩下的其他内容可以收藏后再看~
| 序号 | 技术栈 | 文章链接🔗 |
|---|---|---|
| 1 | hadoop | |
| 2 | spark | |
| 3 | mysql | |
| 4 | kafka | |
| 5 | flink | |
| 6 | airflow | |
| 7 | hbase | |
| 8 | linux | |
| 9 | yarn | |
| 10 | hdfs | |
| 11 | python | |
| 12 | emr |
作为一名大数据开发者,我深知学习新技术的挑战。今天,我想和大家分享如何高效学习hive的经验,希望能为正在或即将踏上大数据之路的你提供一些启发。

part 1 初学hive
hive是什么?
在开始之前,让我们先简单了解一下hive。hive是一个建立在hadoop之上的数据仓库工具,它能够将结构化的数据文件映射为一张数据库表,并提供类sql查询功能。简单来说,hive让我们可以用sql的方式来查询和分析存储在hadoop分布式文件系统中的海量数据。
我的"糙快猛"学习故事
还记得我刚接触大数据时的情景吗?作为一个零基础跨行的新手,面对繁杂的概念和技术,我曾一度感到迷茫。但很快,我领悟到了一个重要的学习方法:“糙快猛”。

什么是"糙快猛"?简单来说,就是:
- 糙:不追求一步到位的完美
- 快:以最快的速度掌握核心概念
- 猛:勇往直前,大胆实践
就拿学习hive来说,我并没有一开始就钻研所有的理论知识,而是迅速搭建了一个hive环境,开始动手实践。记得有一次,我需要分析一大堆日志数据。虽然对hive还不是很熟悉,但我还是决定直接上手。
实践出真知:一个简单的hive查询示例
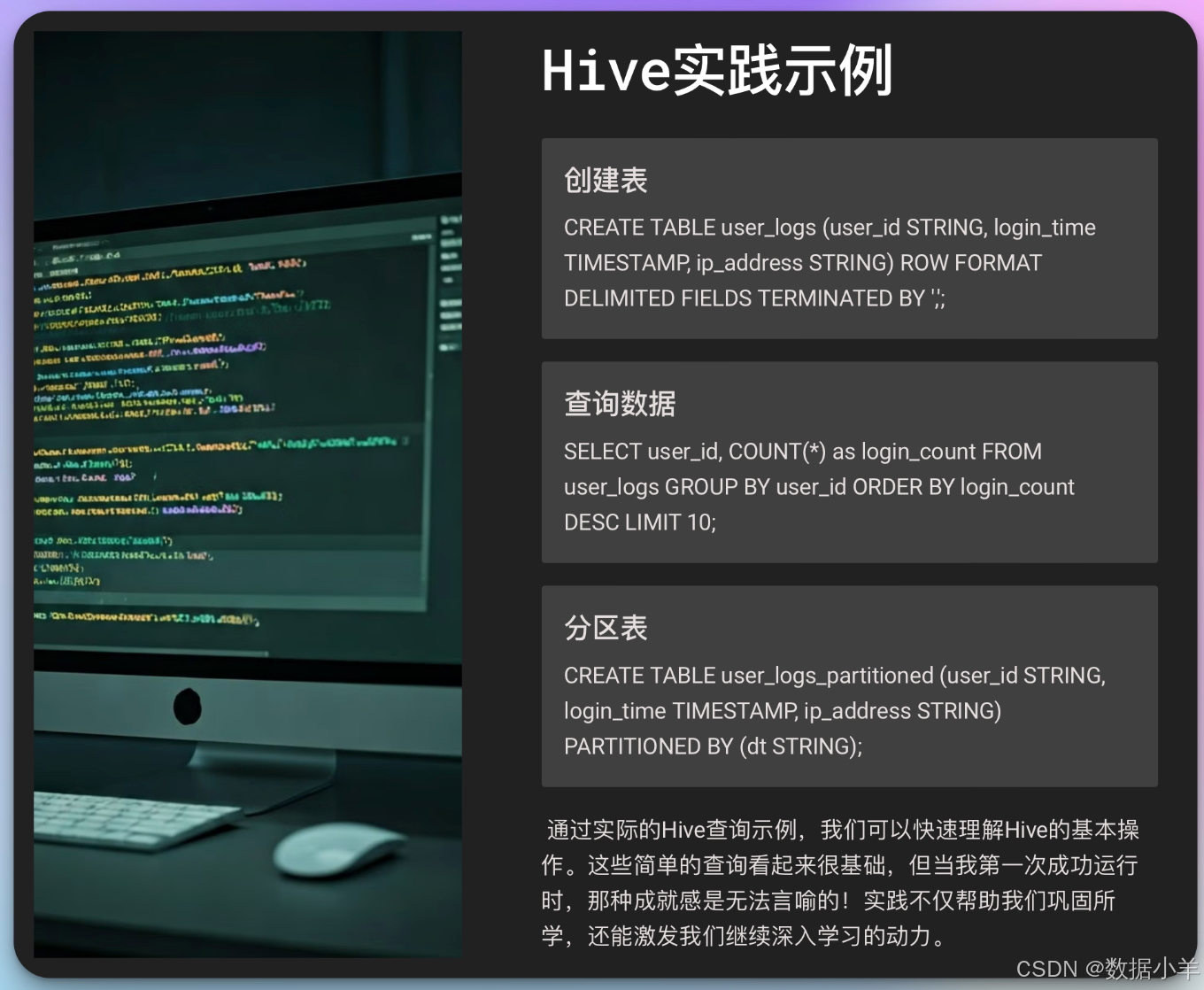
让我们看一个具体的例子。假设我们有一张存储用户登录日志的表user_logs:
create table user_logs (
user_id string,
login_time timestamp,
ip_address string
)
row format delimited
fields terminated by ',';
现在,我们要统计每个用户的登录次数。以下是一个简单的hiveql查询:
select user_id, count(*) as login_count
from user_logs
group by user_id
order by login_count desc
limit 10;
这个查询看起来很简单,对吧?但当我第一次写出这样的查询并成功运行时,那种成就感是无法言喻的!
为什么要"糙快猛"?
-
快速获得反馈:通过实践,我们可以快速了解自己掌握得如何,哪里还需要加强。
-
建立信心:每一个小成功都会增强我们的信心,激发学习动力。
-
发现真正的难点:实践中遇到的问题往往是最值得深入研究的。
-
培养实战能力:在"糙快猛"的过程中,我们不知不觉地培养了解决实际问题的能力。
如何更好地"糙快猛"?
-
利用大模型:像chatgpt这样的大模型可以作为24小时助教,帮助我们快速理解概念,解决代码问题。
-
多动手:理论结合实践,遇到不懂的概念就去实验。
-
不怕犯错:错误是最好的老师,每次失败都是进步的机会。
-
保持节奏:找到适合自己的学习节奏,既不要松懈,也不要给自己太大压力。
-
培养审美:虽然我们追求"糙快猛",但也要逐步建立对代码质量、查询效率的审美。
结语
学习hive,乃至于学习任何技术,都不需要一开始就追求完美。重要的是勇敢地迈出第一步,然后不断前进。记住,“在不完美的状态下前行才是最高效的姿势”。
part 2 深入理解hive

在"糙快猛"的学习过程中,我们不仅要快速上手,还要逐步深入理解hive的核心概念和工作原理。以下是一些值得深入学习的方面:
1. hive的架构
hive的架构主要包括以下组件:
- 用户接口:包括cli、jdbc/odbc、webui
- 元数据存储:通常使用关系型数据库(如mysql)存储表的schema和其他系统元数据
- 查询处理器:解析sql,生成执行计划
- 执行引擎:默认使用mapreduce,也支持tez、spark等
理解这些组件如何协同工作,对于优化hive查询和解决问题非常有帮助。
2. hive数据类型和文件格式
hive支持多种数据类型,包括基本类型(如int、string)和复杂类型(如array、map、struct)。同时,hive也支持多种文件格式,如textfile、sequencefile、rcfile、orc等。
了解这些数据类型和文件格式的特点,可以帮助我们根据实际需求选择最合适的存储方案。
3. 分区和分桶
分区和分桶是hive中非常重要的概念,它们可以显著提高查询性能。
分区示例:
create table user_logs_partitioned (
user_id string,
login_time timestamp,
ip_address string
)
partitioned by (dt string)
row format delimited
fields terminated by ',';
-- 加载数据到分区表
insert overwrite table user_logs_partitioned
partition (dt='2023-07-24')
select user_id, login_time, ip_address
from user_logs
where to_date(login_time) = '2023-07-24';
分桶示例:
create table user_logs_bucketed (
user_id string,
login_time timestamp,
ip_address string
)
clustered by (user_id) into 4 buckets
row format delimited
fields terminated by ',';
进阶学习技巧
在掌握了基础之后,以下是一些进阶学习的建议:
-
深入源码:虽然"糙快猛"强调快速上手,但在有一定基础后,阅读hive的源码可以帮助你更深入地理解其工作原理。
-
优化查询:学习如何分析和优化hive查询是一项重要技能。了解hive的执行计划、数据倾斜问题等概念。
explain select user_id, count(*) as login_count from user_logs group by user_id; -
自定义函数:学习如何编写自定义udf(user-defined function)可以大大增强hive的功能。
public class simpleudf extends udf { public string evaluate(string input) { return input.tolowercase(); } } -
集成其他技术:学习如何将hive与其他大数据技术(如spark、hbase)集成使用。
-
参与开源社区:通过github等平台参与hive的开源项目,不仅可以提高编码能力,还能深入了解项目的发展方向。
实战项目:日志分析系统
为了将所学知识付诸实践,不妨尝试构建一个简单的日志分析系统。这个项目可以包括:
- 使用flume收集日志数据
- 通过hive创建外部表映射日志文件
- 编写hiveql查询分析日志数据
- 使用tableau或其他可视化工具展示分析结果
这样的项目能够帮助你综合运用hive的各项功能,同时也能锻炼你的系统设计能力。
结语
记住,"糙快猛"的学习方法并不意味着浅尝辄止。它强调的是在学习过程中保持前进的动力,不断挑战自己。随着你在hive领域的不断深入,你会发现还有很多值得探索的内容。
保持好奇心,不断实践,相信不久之后,你就能成为团队中的hive大神!当你解决了一个复杂的数据分析问题,或者优化了一个效率低下的查询时,别忘了骄傲地说:“可把我牛逼坏了,让我叉会腰儿!”
part3 hive性能优化之道

在"糙快猛"地掌握了hive的基础知识后,下一步就是学习如何优化hive查询性能。这不仅能让你的查询跑得更快,还能让你在团队中脱颖而出。以下是一些常用的优化技巧:
1. 合理使用列式存储格式
orc和parquet是hive中常用的列式存储格式,它们可以显著提高查询性能。例如:
create table user_logs_orc (
user_id string,
login_time timestamp,
ip_address string
)
stored as orc
tblproperties ("orc.compress"="snappy");
insert into table user_logs_orc select * from user_logs;
2. 使用索引
虽然hive不支持像传统数据库那样的索引,但我们可以创建一些特殊的索引来提高查询性能:
create index idx_user_id on table user_logs_orc (user_id) as 'compact' with deferred rebuild;
alter index idx_user_id on user_logs_orc rebuild;
3. 优化join操作
大表join是hive中常见的性能瓶颈。以下是一些优化技巧:
-
使用map join:当一个表足够小时,可以将其完全加载到内存中。
set hive.auto.convert.join=true; set hive.mapjoin.smalltable.filesize=25000000; -
倾斜数据处理:对于数据分布不均匀的情况,可以使用倾斜数据优化。
set hive.optimize.skewjoin=true; set hive.skewjoin.key=100000;
4. 合理设置参数
一些hive配置参数可以显著影响查询性能:
set mapred.reduce.tasks = 32; -- 设置reduce任务数
set hive.exec.parallel=true; -- 开启并行执行
set hive.exec.parallel.thread.number=16; -- 设置并行度
实际案例研究:电商平台用户行为分析
让我们通过一个实际案例来综合运用我们所学的hive知识。假设我们是一个大型电商平台的数据分析师,需要分析用户的购物行为。
步骤1:数据建模
首先,我们需要创建相应的表结构:
create table user_behavior (
user_id string,
item_id string,
category_id string,
behavior_type string,
timestamp bigint
)
partitioned by (dt string)
stored as orc;
步骤2:数据etl
假设我们每天都有新的日志数据需要导入:
insert overwrite table user_behavior
partition (dt='2023-07-25')
select user_id, item_id, category_id, behavior_type, timestamp
from raw_logs
where to_date(from_unixtime(timestamp)) = '2023-07-25';
步骤3:数据分析
现在我们可以进行一些有意思的分析了:
- 计算每个类别的点击量、收藏量、加购量和购买量:
select
category_id,
sum(case when behavior_type = 'pv' then 1 else 0 end) as pv_count,
sum(case when behavior_type = 'fav' then 1 else 0 end) as fav_count,
sum(case when behavior_type = 'cart' then 1 else 0 end) as cart_count,
sum(case when behavior_type = 'buy' then 1 else 0 end) as buy_count
from user_behavior
where dt = '2023-07-25'
group by category_id;
- 计算用户的购买转化率:
with user_funnel as (
select
user_id,
max(case when behavior_type = 'pv' then 1 else 0 end) as has_pv,
max(case when behavior_type = 'fav' then 1 else 0 end) as has_fav,
max(case when behavior_type = 'cart' then 1 else 0 end) as has_cart,
max(case when behavior_type = 'buy' then 1 else 0 end) as has_buy
from user_behavior
where dt = '2023-07-25'
group by user_id
)
select
sum(has_pv) as pv_users,
sum(has_fav) as fav_users,
sum(has_cart) as cart_users,
sum(has_buy) as buy_users,
sum(has_buy) / sum(has_pv) as conversion_rate
from user_funnel;
part 4 与大数据生态系统的集成

hive并不是孤立存在的,它是大数据生态系统中的一员。学习如何将hive与其他工具集成使用,可以让你的技能更加全面。
1. hive on spark
使用spark作为hive的执行引擎可以显著提高查询性能:
set hive.execution.engine=spark;
2. hive与hbase集成
hive可以直接查询hbase中的数据:
create external table hbase_table_emp(
id int,
name string,
role string
)
stored by 'org.apache.hadoop.hive.hbase.hbasestoragehandler'
with serdeproperties ("hbase.columns.mapping" = ":key,f1:name,f1:role")
tblproperties ("hbase.table.name" = "emp");
3. hive与kafka集成
使用kafka连接器,我们可以将kafka中的数据实时导入hive:
create external table kafka_table (
id int,
name string,
age int
)
stored by 'org.apache.hadoop.hive.kafka.kafkastoragehandler'
tblproperties (
"kafka.topic" = "test-topic",
"kafka.bootstrap.servers" = "localhost:9092"
);
持续学习的建议
-
关注hive的发展:定期查看apache hive的官方文档和release notes,了解新特性和改进。
-
参与社区:加入hive用户邮件列表,参与讨论,这是学习和解决问题的好方法。
-
阅读源码:尝试阅读hive的源代码,这可以帮助你更深入地理解hive的工作原理。
-
实践,实践,再实践:尝试在工作中解决实际问题,或者参与一些开源项目。
-
分享知识:尝试写博客或者在团队中分享你的hive使用经验,教是最好的学习方式。
结语
学习hive是一个不断深入的过程。从"糙快猛"的入门,到逐步掌握高级特性,再到能够优化复杂查询和设计大规模数据仓库,每一步都充满挑战和乐趣。
记住,在大数据的世界里,技术更新很快,保持学习的激情和好奇心至关重要。当你解决了一个复杂的数据分析问题,优化了一个效率低下的查询,或者设计了一个高效的数据仓库时,别忘了骄傲地说:“可把我牛逼坏了,让我叉会腰儿!”
part 5 hive内部原理深究
要真正掌握hive,了解其内部工作原理是必不可少的。这不仅能帮助你更好地优化查询,还能在遇到问题时快速定位原因。
1. hive查询的生命周期
了解hive查询的执行过程可以帮助我们更好地理解和优化查询:
- 解析:hive将hql转换为抽象语法树(ast)
- 编译:将ast转换为运算符树
- 优化:进行逻辑和物理优化
- 执行:生成执行计划并提交到hadoop集群执行
2. hive的元数据管理
hive的元数据存储在关系型数据库中(默认是derby,生产环境常用mysql)。了解元数据的结构可以帮助我们更好地管理hive:
-- 查看表的元数据
desc formatted my_table;
-- 查看分区信息
show partitions my_table;
3. hive的序列化和反序列化
hive使用serde(serializer/deserializer)来读写数据。了解不同serde的特点可以帮助我们选择最适合的数据存储格式:
-- 使用自定义serde
create table my_csv_table (
id int,
name string
)
row format serde 'org.apache.hadoop.hive.serde2.opencsvserde'
with serdeproperties (
"separatorchar" = ",",
"quotechar" = "'",
"escapechar" = "\\"
);
高级优化技巧
除了之前提到的基本优化技巧,还有一些高级技巧可以进一步提升hive的性能:
1. 动态分区优化
动态分区可以自动创建分区,但如果使用不当可能会创建大量小文件。可以通过以下设置来优化:
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions=1000;
set hive.exec.max.dynamic.partitions.pernode=100;
2. 小文件合并
小文件会导致创建大量map任务,影响性能。可以通过以下设置来合并小文件:
set hive.merge.mapfiles=true;
set hive.merge.mapredfiles=true;
set hive.merge.size.per.task=256000000;
3. 压缩和编码
合理使用压缩和编码可以减少i/o,提高查询速度:
set hive.exec.compress.intermediate=true;
set hive.exec.compress.output=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.snappycodec;
故障排除和性能诊断
在使用hive的过程中,难免会遇到各种问题。以下是一些常见问题及其解决方案:
1. 数据倾斜
症状:某些reducer任务运行时间明显长于其他任务。
解决方案:
- 对倾斜的键进行预处理
- 使用倾斜join优化
set hive.optimize.skewjoin=true; set hive.skewjoin.key=100000;
2. out of memory错误
症状:任务失败,日志中出现outofmemoryerror。
解决方案:
- 增加mapper/reducer的内存
set mapred.child.java.opts=-xmx1024m; - 如果是数据倾斜导致,参考上述数据倾斜的解决方案
3. 查询速度慢
症状:查询执行时间过长。
诊断步骤:
- 使用explain命令查看查询计划
- 检查表的分区和索引是否合理
- 查看是否有数据倾斜
- 检查join的顺序是否优化
explain extended
select /*+ mapjoin(b) */ a.val, b.val
from a join b on (a.key = b.key);
part 6 hive在企业级数据仓库中的应用
在实际的企业环境中,hive常常作为大规模数据仓库的核心组件。让我们探讨一下hive在企业级应用中的一些最佳实践和常见架构。

1. 分层数据仓库架构
在企业级数据仓库中,通常采用分层架构来组织数据:
- ods(操作数据存储)层:存储原始数据,通常是从源系统直接导入的数据。
- dwd(数据仓库明细)层:存储经过清洗和规范化的明细数据。
- dws(数据仓库服务)层:存储轻度汇总的数据,用于提供常用的统计指标。
- ads(应用数据服务)层:存储高度汇总的数据,直接服务于应用和报表。
示例:创建dws层的销售汇总表
create table dws_sales_daily (
date_key date,
product_id string,
category_id string,
sales_amount decimal(18,2),
sales_quantity int
)
partitioned by (dt string)
stored as orc;
insert overwrite table dws_sales_daily partition (dt='2023-07-26')
select
o.order_date as date_key,
p.product_id,
p.category_id,
sum(o.price * o.quantity) as sales_amount,
sum(o.quantity) as sales_quantity
from
dwd_orders o
join
dim_product p on o.product_id = p.product_id
where
o.dt = '2023-07-26'
group by
o.order_date, p.product_id, p.category_id;
2. 实时数据集成
随着实时数据需求的增加,许多企业开始探索如何将实时数据集成到hive中。以下是一些常见的方法:
- hive事务表:hive支持acid事务,允许进行实时的插入、更新和删除操作。
create table realtime_sales (
id int,
product_id string,
sale_amount decimal(18,2),
sale_time timestamp
)
clustered by (id) into 4 buckets
stored as orc
tblproperties ('transactional'='true');
-- 插入新的销售记录
insert into realtime_sales values (1, 'p001', 99.99, current_timestamp);
-- 更新销售金额
update realtime_sales set sale_amount = 89.99 where id = 1;
- hive streaming:通过hive streaming api,可以将实时数据流写入hive表。
hiveendpoint endpoint = new hiveendpoint("jdbc:hive2://localhost:10000/default",
"realtime_sales", arrays.aslist(""), null);
streamingconnection connection = endpoint.newconnection(true);
recordwriter writer = connection.newwriter();
writer.write(new byteswritable("p001".getbytes()), new byteswritable("99.99".getbytes()));
writer.flush();
writer.close();
3. 数据质量管理
在企业环境中,确保数据质量至关重要。以下是一些使用hive进行数据质量管理的方法:
- 数据验证查询:定期运行验证查询来检查数据的完整性和一致性。
-- 检查空值
select count(*) as null_count
from my_table
where important_column is null;
-- 检查重复值
select id, count(*) as dup_count
from my_table
group by id
having count(*) > 1;
- 使用hive udf进行数据清洗:创建自定义udf来进行复杂的数据清洗和验证。
public class datacleansingudf extends udf {
public string evaluate(string input) {
// 实现数据清洗逻辑
return cleaneddata;
}
}
add jar /path/to/data-cleansing-udf.jar;
create temporary function clean_data as 'com.example.datacleansingudf';
insert overwrite table cleaned_table
select clean_data(column1), clean_data(column2)
from raw_table;
hive vs 其他大数据技术

随着大数据生态系统的不断发展,出现了许多新的技术。让我们比较一下hive与其他一些流行的大数据技术:
1. hive vs presto
- hive:适合大规模批处理查询,支持复杂的etl作业。
- presto:适合交互式查询,查询速度更快,但对大规模etl支持较弱。
选择建议:如果需要进行复杂的数据转换和大规模批处理,选择hive;如果需要快速的交互式查询,选择presto。
2. hive vs spark sql
- hive:成熟稳定,与hadoop生态系统深度集成。
- spark sql:查询速度更快,支持更多的数据处理范式(如流处理)。
选择建议:如果已有大量hive查询和udf,继续使用hive;如果需要更快的查询速度和更灵活的数据处理能力,考虑使用spark sql。
3. hive vs impala
- hive:支持更复杂的查询和转换,可以处理更大规模的数据。
- impala:查询延迟更低,适合交互式查询场景。
选择建议:对于需要低延迟的bi工具集成,选择impala;对于复杂的数据处理和大规模批处理,选择hive。
hive的未来:趋势和展望

尽管hive已经是一个成熟的技术,但它仍在不断发展。以下是一些hive的未来趋势:
-
与云原生技术的集成:随着云计算的普及,hive正在加强与云原生技术的集成,如支持对象存储、弹性计算资源等。
-
实时数据处理能力的增强:虽然hive主要用于批处理,但它正在增强实时数据处理能力,如改进的事务支持、与流处理系统的集成等。
-
ai和机器学习的深度集成:预计未来hive将提供更多内置的机器学习算法和功能,方便数据科学家直接在hive中进行模型训练和预测。
-
性能优化:持续的查询优化、更智能的资源管理、更高效的存储格式等。
-
安全性和治理的增强:随着数据隐私法规的加强,hive可能会提供更强大的数据加密、访问控制和审计功能。
案例研究:全球零售巨头的hive应用
让我们通过一个虚构的案例来看看hive如何在实际企业中发挥作用。
背景:全球零售巨头 retailtech 每天处理数百万笔交易,需要一个强大的数据仓库来支持其业务决策和客户洞察。
挑战:
- 每天需要处理和分析超过1pb的新数据
- 需要支持从实时销售监控到长期趋势分析的各种查询
- 数据安全和隐私保护至关重要
解决方案:
-
数据架构:
- 使用hive作为核心数据仓库
- ods层存储原始交易数据
- dwd层进行数据清洗和标准化
- dws层创建常用的汇总指标
- ads层为不同的应用场景提供专门的数据集市
-
实时数据集成:
- 使用kafka收集实时交易数据
- 通过hive streaming将实时数据写入hive事务表
- 定期将实时数据合并到批处理表中
-
查询优化:
- 使用orc存储格式并启用zlib压缩
- 根据查询模式优化分区策略
- 为常用查询创建物化视图
-
安全性:
- 启用kerberos认证
- 使用apache ranger进行细粒度的访问控制
- 对敏感数据列进行加密
-
高级分析:
- 使用hive udf实现复杂的业务逻辑
- 集成spark ml进行客户行为预测
- 使用tableau连接hive进行可视化分析
结果:
- 成功构建了一个每天可以处理1.5pb数据的数据仓库
- 支持超过1000名分析师同时进行查询,95%的查询在30秒内完成
- 实现了从实时销售监控到复杂的客户行为分析的全方位数据应用
- 显著提高了库存管理效率,减少了30%的库存成本
- 通过个性化推荐提高了15%的客户转化率
结语
从"糙快猛"的入门学习,到深入理解hive的内部原理,再到在企业级环境中应用hive构建大规模数据仓库,hive的学习之路是漫长而充满挑战的。但正是这些挑战让我们不断成长,让我们能够在大数据的海洋中游刃有余。
作为一个hive专家,你不仅需要掌握技术细节,还需要理解业务需求,平衡性能、成本和安全性,并且能够与其他大数据技术协同工作。当你成功地设计了一个高效的企业级数据仓库,解决了一个棘手的性能问题,或者用hive驱动的数据洞察帮助公司做出了重要决策时,你就可以自豪地说:“可把我牛逼坏了,让我叉会腰儿!”

记住,在这个数据驱动的时代,你掌握的不仅仅是一个技术工具,而是改变世界的力量。每一行查询背后,都可能隐藏着改变公司命运、影响数百万人生活的洞察。保持好奇,不断学习,相信数据的力量,你就能在这个精彩的大数据世界中创造奇迹!
思维导图


发表评论