DBSCAN 基于密度的聚类算法,一个简单的示例
import numpy as np
import pickle
with open('clusters.pkl', 'rb') as f:
clusters = pickle.load(f)
data_list = []
for index_data, datas in enumerate(clusters):
dk = []
for i, data_cluster in enumerate(datas):
for d in data_cluster.data:
dk.append(d)
data_list.append(dk)
def dbscan(points, eps, min_points):
"""
dbscan算法实现
:param points: 数据点数组,每行表示一个数据点
:param eps: 半径
:param min_points: 最小点数
:return: 聚类标签数组
"""
labels = [-1] * len(points)
core_points = np.zeros(len(points), dtype=bool)
for i in range(len(points)):
count = np.sum(np.linalg.norm(points - points[i], axis=1) <= eps)
if count >= min_points:
core_points[i] = true
cluster_id = 0
for i in range(len(points)):
if labels[i] != -1:
continue
if core_points[i]:
labels[i] = cluster_id
expand_cluster(points, labels, core_points, i, cluster_id, eps, min_points)
cluster_id += 1
return labels
def expand_cluster(points, labels, core_points, point_id, cluster_id, eps, min_points):
"""
扩展当前点的聚类
:param points: 数据点数组,每行表示一个数据点
:param labels: 聚类标签数组
:param core_points: 点的核心性数组
:param point_id: 当前点的索引
:param cluster_id: 当前聚类的标签
:param eps: 半径
:param min_points: 最小点数
:return: none
"""
neighbor_ids = np.where(np.linalg.norm(points - points[point_id], axis=1) <= eps)[0]
if not core_points[point_id]:
labels[point_id] = cluster_id
return
for i in neighbor_ids:
if labels[i] == -1:
labels[i] = cluster_id
if core_points[i]:
expand_cluster(points, labels, core_points, i, cluster_id, eps, min_points)
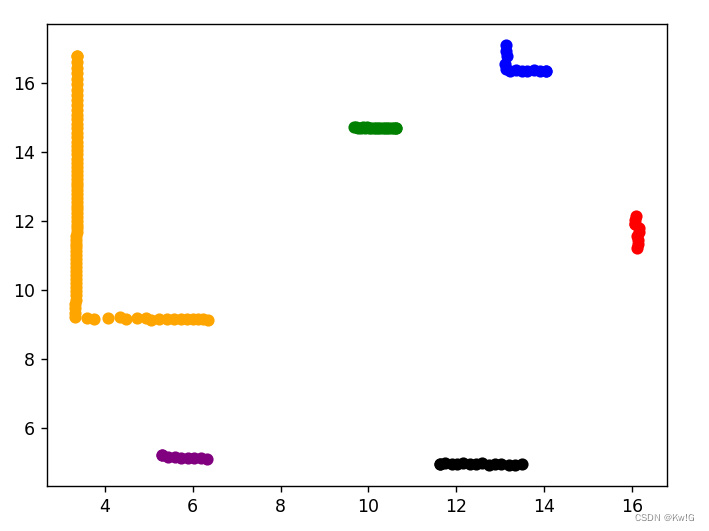
data_value = np.array(data_list[0])
l = dbscan(data_value, 0.5, 5)
import matplotlib.pyplot as plt
colors = ['red', 'blue', 'green', 'orange', 'purple','black']
for i in range(len(l)):
if l[i] != -1:
plt.scatter(data_value[i][0], data_value[i][1], c=colors[l[i]])
plt.show()
结果图
相关文章:
-
Vue3+NodeJS 接入文心一言, 发布一个 VSCode 大模型问答插件…
-
JNPF,依托代码开发技术原理,区别于传统开发交付周期长、二次开发难、技术门槛高的痛点,大部分的应用搭建都是通过拖拽控件实现,通过为开发者提供可视化的应用开发环境,降低或去除应用开…
-
一、介绍如何使用json文件将数据导入到mysql数据库中的表里?excel表格等文件的数据通过java或者python等语言读取后生成一个json文件,然后想要将文件中的数据写入…
-
-
-
非结构化数据:指数据结构不规则或不完整,没有预定义的数据模型,不方便用数据库二维逻辑表来表现的数据。如word、pdf、ppt及各种格式的图片、视频等。其实除了结构化数据和非结构化…
版权声明:本文内容由互联网用户贡献,该文观点仅代表作者本人。本站仅提供信息存储服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 2386932994@qq.com 举报,一经查实将立刻删除。

发表评论