已解决“from tensorflow.keras.preprocessing.image import ImageDataGenerator”标红,解决版本问题导致导包失败
一般这种原代码的trensflow版本都比较老,和新版本的导入语句会有区别,遇到这种导入出现找不到包的情况,建议直接注释掉标红的那行代码,然后找到对应调用该方法的语句(也会标红或),鼠标放在上面(不是点击),会提示需要导入的包的位置,直接点击提示框里的Importxxx就行。说明在tensorflow包里没找到keras文件,去该程序编译器(这里编译器为python3.11)对应的tensorflow里看了下,果然没有keras。在该编译器的其他文件夹里,找到了包含要导入的包的keras 目标文件。
有一种最简单的方法(适用大部分由于版本差异,导致的import红线问题)。
一般这种原代码的trensflow版本都比较老,和新版本的导入语句会有区别,遇到这种导入出现找不到包的情况,建议直接注释掉标红的那行代码,然后找到对应调用该方法的语句(也会标红或),鼠标放在上面(不是点击),会提示需要导入的包的位置,直接点击提示框里的importxxx就行。到这一步红线应该就消失了


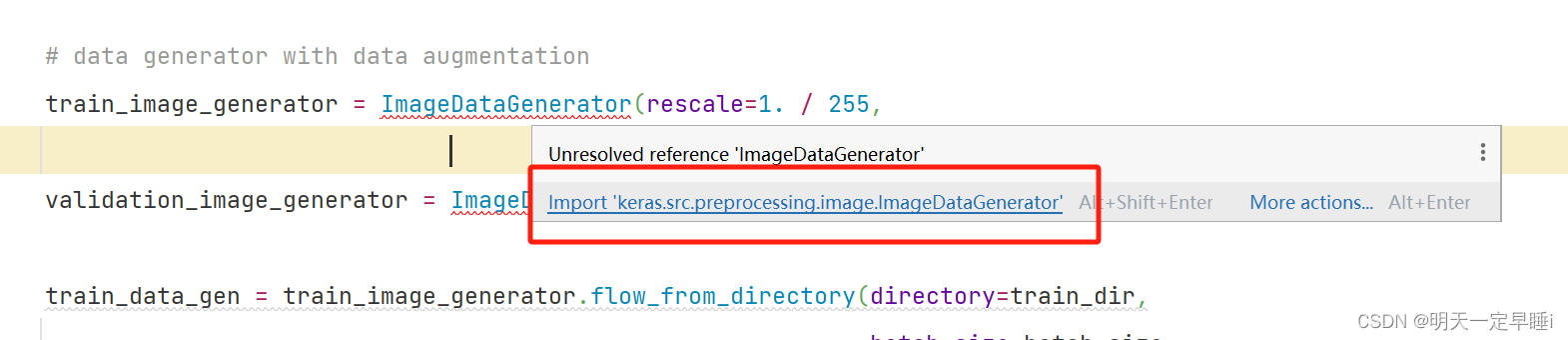
可能是tensorflow版本不同,文件的位置有差异,import语句会有所不同导致的
研究了一下具体的路径:
说明在tensorflow包里没找到keras文件,去该程序编译器(这里编译器为python3.11)对应的tensorflow里看了下,果然没有keras
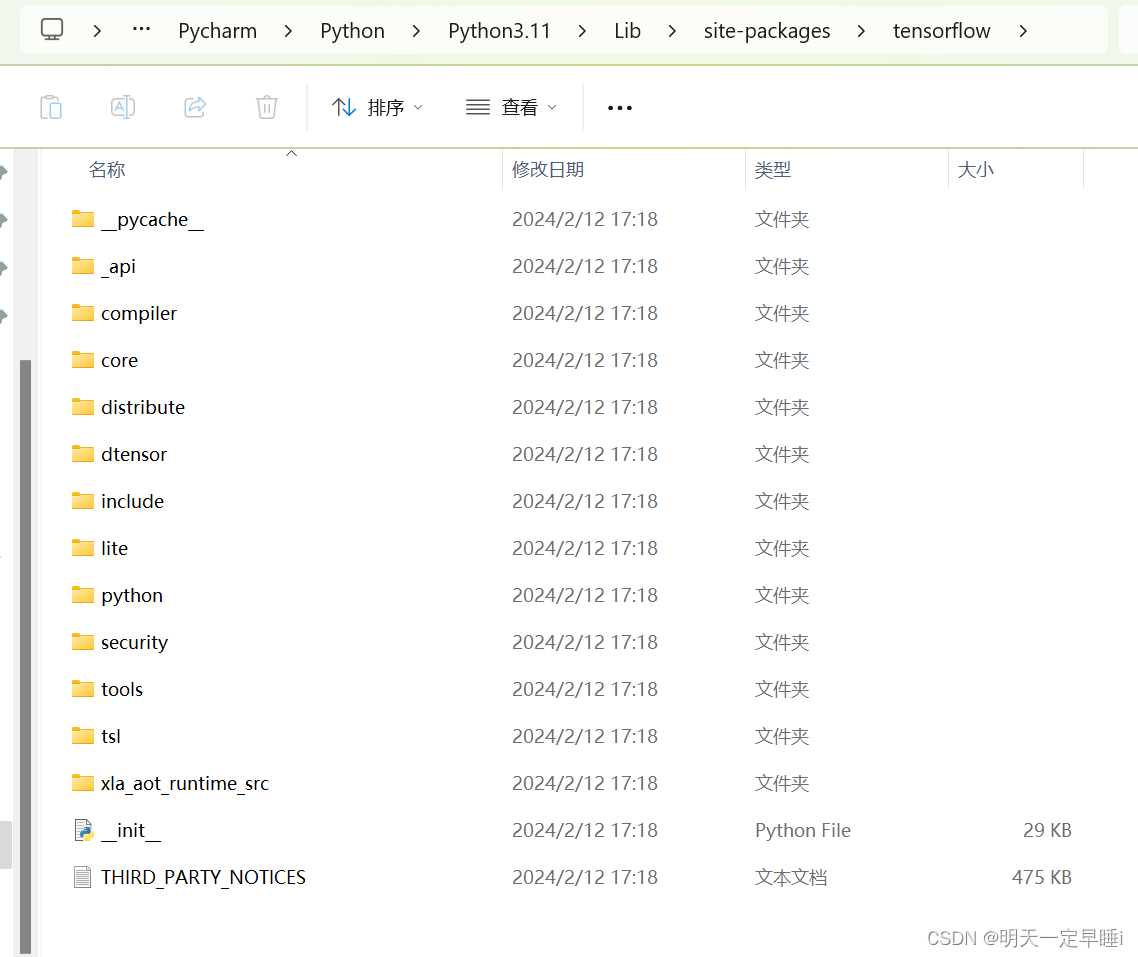
在该编译器的其他文件夹里,找到了包含要导入的包的keras 目标文件
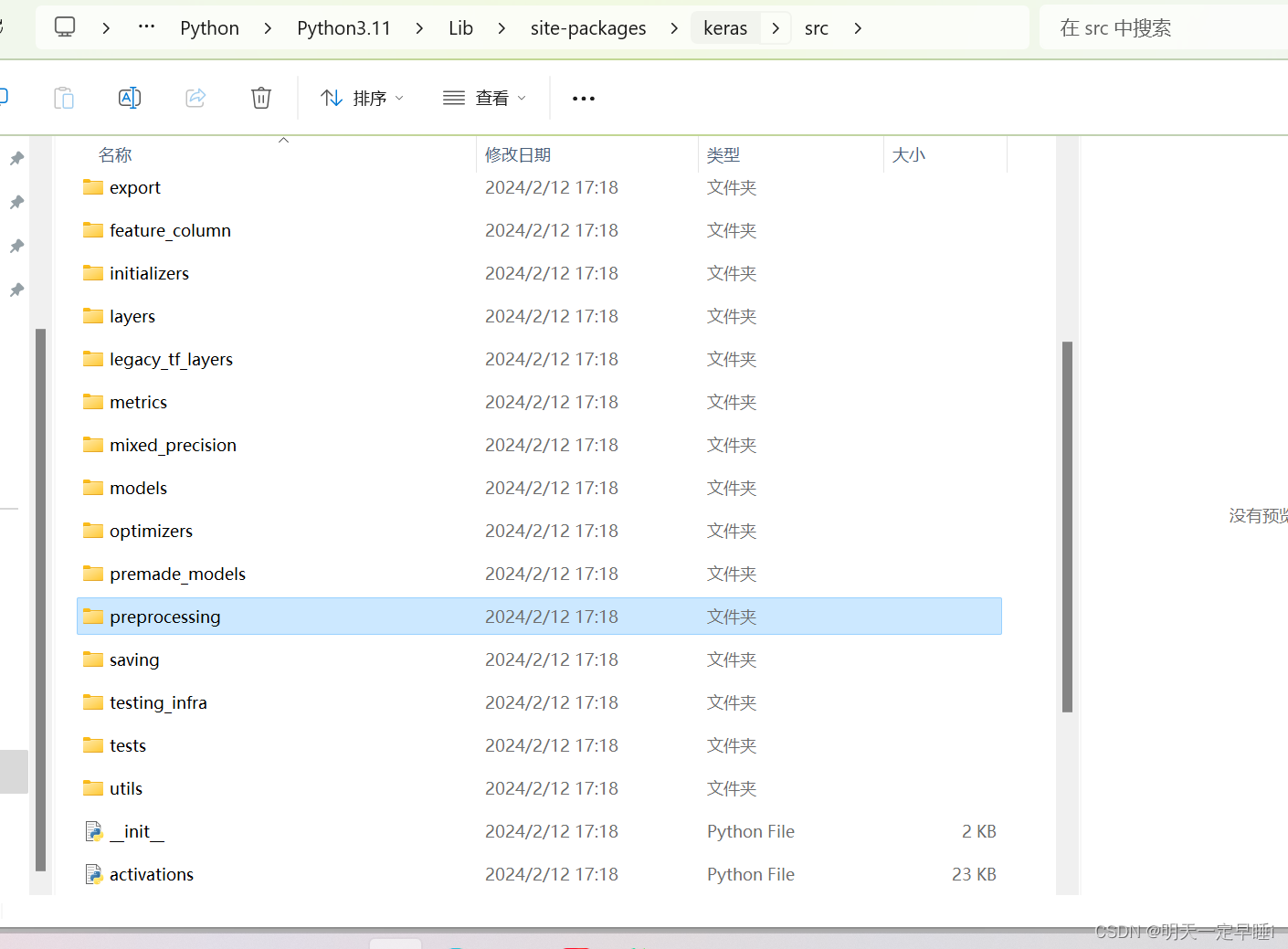
这时候有两个解决办法
方法1是,把这个keras复制到trensflow文件夹里,原代码改为
from tensorflow.keras.src.preprocessing.image import imagedatagenerator
方法2是,不动文件,直接修改导入命令为
from keras.src.preprocessing.image import imagedatagenerator
相关文章:
-
到这一步就可以开发了,为了项目条理更加清晰,还需要引入【自定义组件一般而言,自定义组件可以简单理解为一个目录,里面存放一些功能函数,提供给main函数进行调用。打开终端,切换到待创…
-
-
-
本文对transformers之pipeline的自动语音识别(automatic-speech-recognition)从概述、技术原理、pipeline参数、pipeline实…
-
Whisper 是一种通用的语音识别模型。它是在包含各种音频的大型数据集上训练的,也是一个多任务模型,可以执行多语言语音识别、语音翻译和语言识别。Open AI在2022年9月21…
-
版权声明:本文内容由互联网用户贡献,该文观点仅代表作者本人。本站仅提供信息存储服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 2386932994@qq.com 举报,一经查实将立刻删除。


发表评论