前言
java.lang.outofmemoryerror —— 相信每一个 java 开发者都被它折磨过。生产环境凌晨三点的告警,频繁 full gc 之后的服务宕机,排查了半天发现是几年前留下的"祖传代码"……
oom 的可怕之处不在于错误本身,而在于它往往是长时间问题积累的集中爆发,排查链路长、现场难复现。
本文结合实际生产经验,系统梳理 6 种常见 oom 类型,对每一种都给出:触发原因 → 排查手段 → 解决方案 → 避坑建议,力求一文搞定。
1. oom 全景速览
java 的内存结构决定了 oom 有多个"爆炸点",先来一张全景图:
jvm 内存模型全景图
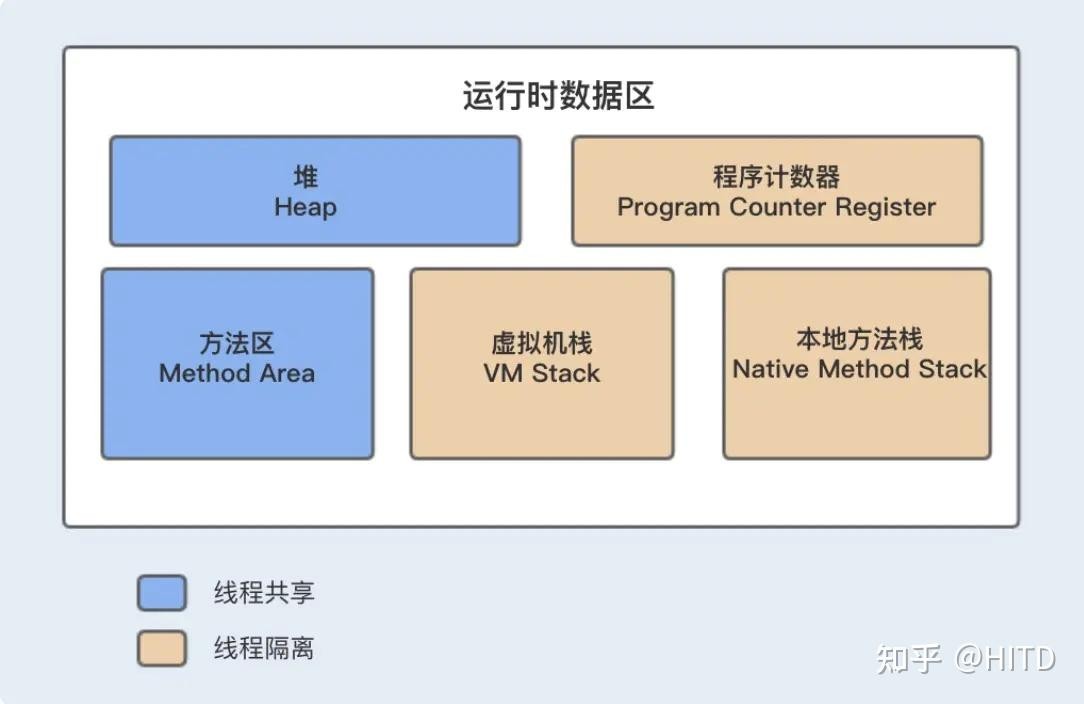
gc 触发区域:young gc(eden满)→ old gc(old满)→ full gc(整个堆+metaspace)
| oom 类型 | 触发区域 | 常见程度 |
|---|---|---|
| java heap space | 堆内存 | ⭐⭐⭐⭐⭐ |
| gc overhead limit exceeded | 堆内存 | ⭐⭐⭐⭐ |
| metaspace | 元空间 | ⭐⭐⭐ |
| unable to create new native thread | 线程 | ⭐⭐⭐ |
| direct buffer memory | 堆外内存 | ⭐⭐ |
| stackoverflowerror | 栈 | ⭐⭐ |
2. java heap space — 堆内存溢出
2.1 错误表现
java.lang.outofmemoryerror: java heap space
at java.util.arrays.copyof(arrays.java:3210)
at java.util.arraylist.grow(arraylist.java:265)
...2.2 触发原因
① 内存泄漏(最常见)
对象持有引用,gc 无法回收,随时间积累直到堆撑爆。
典型场景:
- 静态集合无限增长(
static list/map只增不减) - 未关闭的资源(connection、inputstream)
- 监听器注册后未注销(event listener)
- 线程局部变量 threadlocal 未 remove
// 💣 危险代码:静态 map 充当"黑洞"
public class cachemanager {
private static final map<string, object> cache = new hashmap<>();
public void add(string key, object value) {
cache.put(key, value); // 只进不出,迟早 oom
}
}
② 内存溢出(数据量真的太大)
- 一次性加载超大数据集到内存(如全表查询几千万条数据)
- 生成超大文件(excel、pdf)全部在内存中处理
2.3 排查手段
step 1:开启 oom 时自动 dump
# jvm 启动参数中加入 -xx:+heapdumponoutofmemoryerror -xx:heapdumppath=/var/logs/heapdump.hprof
step 2:分析 heap dump
推荐工具:jprofiler(idea 官方推荐,可视化极强)
- 打开 jprofiler,选择 “open a heap dump” 导入
.hprof文件 - 点击 “biggest objects” → 直接展示占用内存最多的对象
- 使用 “dominator tree” → 分析对象引用树,定位泄漏根因
- “references” 视图 → 查看谁在引用大对象,追溯到具体代码行
step 3:线上快速定位(不重启)
# 手动 dump(需要进程 pid) jmap -dump:format=b,file=/tmp/heap.hprof <pid> # 查看堆内存概要 jmap -heap <pid> # 实时查看 gc 情况 jstat -gcutil <pid> 1000 10
2.4 解决方案
| 方案 | 适用场景 |
|---|---|
| 修复内存泄漏代码 | 根本解法,强烈推荐 |
合理设置堆大小 -xmx | 内存真不够用时临时扩容 |
| 分批处理大数据 | 避免全量加载 |
| 引入缓存淘汰策略 | 用 weakhashmap、guava cache 替代普通 map |
| 流式处理(stream/游标) | 大文件、大查询场景 |
// ✅ 正确姿势:使用 mybatis 游标批量处理
@options(resultsettype = resultsettype.forward_only, fetchsize = 1000)
@select("select * from big_table")
cursor<bigdata> streamall();
// 配合使用
try (cursor<bigdata> cursor = mapper.streamall()) {
for (bigdata data : cursor) {
process(data); // 逐条处理,不全量加载
}
}
3. gc overhead limit exceeded — gc 开销超限
3.1 错误表现
java.lang.outofmemoryerror: gc overhead limit exceeded
3.2 触发原因
jvm 默认阈值:gc 耗时超过 98% 的时间,而回收的内存不到 2%,连续多次后触发此 oom。
本质上是"堆内存已满,gc 拼命跑却白忙活"的信号,往往先于 heap space oom 出现。
3.3 排查与解决
排查方式同 堆内存溢出,核心是找到内存泄漏点。
临时规避(不推荐长期使用):
# 关闭此限制检测(治标不治本) -xx:-usegcoverheadlimit
根治方向:
- 调大堆内存
-xmx - 优化对象创建,减少短生命周期大对象
- 使用合适的 gc 算法(g1/zgc)
4. metaspace — 元空间溢出
4.1 错误表现
java.lang.outofmemoryerror: metaspace
java 8 之前是
permgen space(永久代),java 8 之后改为metaspace(元空间,使用本地内存)。
4.2 触发原因
metaspace 存储类的元数据(类名、方法、字段信息等)。以下情况会导致类爆炸:
- 动态代理/字节码增强框架:如 spring aop、cglib、asm 运行时生成大量代理类
- groovy 动态脚本:每次执行都生成新的 class
- 热部署/反复 reload:旧类无法被 gc(classloader 有强引用)
- osgi 插件化架构:bundle 频繁加载卸载
// 💣 危险:在循环中动态生成类
for (int i = 0; i < 100000; i++) {
// 每次都生成新的代理类,classloader 持有引用无法 gc
object proxy = proxy.newproxyinstance(
classloader, interfaces, handler
);
}
4.3 排查手段
# 查看 metaspace 使用情况 jstat -gcmetacapacity <pid> # 查看加载了多少类 jstat -class <pid> # jvm 参数:开启详细 gc 日志 -xx:+printgcdetails -xx:+printgcdatestamps -xloggc:/var/log/gc.log
用 jvisualvm 或 arthas 查看类加载数量趋势,若持续增长不下降 → 类泄漏确认。
4.4 解决方案
# 设置 metaspace 上限,防止无限增长吃掉系统内存 -xx:maxmetaspacesize=256m # 设置初始大小,减少频繁扩容 -xx:metaspacesize=128m
代码层面:
- 复用 classloader,避免频繁创建
- 脚本引擎(groovy/mvel)使用缓存,不每次新建
- 检查框架版本,部分老版本 cglib 有类泄漏 bug
5. unable to create new native thread — 无法创建线程
5.1 错误表现
java.lang.outofmemoryerror: unable to create new native thread
5.2 触发原因
这个 oom 不是 java 堆内存不足,而是:
- 系统线程数达到上限(linux 默认每进程约 1024 个线程)
- 线程泄漏:线程池配置不当,任务堆积导致线程数失控
- 每个线程占用栈内存(默认 512kb~1mb),线程过多耗尽系统内存
5.3 排查手段
# 查看当前进程线程数 ps -elf | grep java | wc -l # 查看系统允许的最大线程数 cat /proc/sys/kernel/threads-max # 查看每个用户的线程限制 ulimit -u # arthas 查看线程堆栈(神器) java -jar arthas-boot.jar # 进入后执行: thread -n 10 # 查看 cpu 占用最高的 10 个线程 thread -b # 查找死锁
jstack 分析线程 dump:
jstack <pid> > /tmp/thread.dump # 然后统计各线程状态 grep "java.lang.thread.state" /tmp/thread.dump | sort | uniq -c | sort -rn
5.4 解决方案
① 调大系统线程限制
# 临时修改(重启失效) ulimit -u 65535 # 永久修改 /etc/security/limits.conf * soft nproc 65535 * hard nproc 65535
② 规范线程池使用
// ❌ 错误:每次请求都创建新线程
new thread(() -> dotask()).start();
// ✅ 正确:统一线程池管理
@bean
public threadpoolexecutor taskexecutor() {
return new threadpoolexecutor(
10, // corepoolsize
50, // maximumpoolsize
60l, // keepalivetime
timeunit.seconds,
new linkedblockingqueue<>(1000), // 有界队列!
new threadfactorybuilder().setnameformat("task-%d").build(),
new threadpoolexecutor.callerrunspolicy() // 拒绝策略
);
}
⚠️ 强调:禁止使用
executors.newcachedthreadpool(),其最大线程数为integer.max_value,高并发下必炸。
6. direct buffer memory — 直接内存溢出
6.1 错误表现
java.lang.outofmemoryerror: direct buffer memory
6.2 触发原因
directbytebuffer 分配的是堆外内存(off-heap),不受 -xmx 限制,由 -xx:maxdirectmemorysize 控制。
常见场景:
- netty / nio 框架大量使用直接内存
- 手动调用
bytebuffer.allocatedirect()未及时释放 - 直接内存回收依赖 gc,但 gc 不频繁时堆外内存不释放
// 💣 危险:频繁申请直接内存不释放
for (int i = 0; i < 10000; i++) {
bytebuffer buffer = bytebuffer.allocatedirect(1024 * 1024); // 1mb
// 忘记 ((directbuffer) buffer).cleaner().clean()
}
6.3 排查与解决
# 查看直接内存使用(通过 jmx) jcmd <pid> vm.native_memory summary # 设置直接内存上限 -xx:maxdirectmemorysize=512m
代码层面:
- netty 使用
pooledbytebufallocator复用 buffer - 手动申请的 directbuffer 使用完后调用
cleaner().clean()或等待 gc - 升级 netty 版本,新版本内存管理更完善
7. stack overflow — 栈溢出
7.1 错误表现
java.lang.stackoverflowerror
at com.example.fibonacci.fib(fibonacci.java:5)
at com.example.fibonacci.fib(fibonacci.java:5)
...(重复 n 次)
严格来说
stackoverflowerror是error不是oom,但生产环境同样会引发服务不可用。
7.2 触发原因
- 无限递归:递归终止条件缺失或错误
- 递归深度过大:数据结构深度超过栈容量(默认约 512~1024 帧)
- 对象循环引用 + json 序列化(如 tostring/equals 触发无限调用)
// 💣 死递归
public int factorial(int n) {
return n * factorial(n - 1); // 忘记 if(n == 0) return 1;
}
7.3 解决方案
// ✅ 方案一:修复递归终止条件
public int factorial(int n) {
if (n <= 0) return 1; // 终止条件
return n * factorial(n - 1);
}
// ✅ 方案二:改为循环(深度无限制)
public int factorial(int n) {
int result = 1;
for (int i = 2; i <= n; i++) {
result *= i;
}
return result;
}
// ✅ 方案三:尾递归优化(java 不原生支持,可用 trampoline 模式)
调大栈深度(谨慎):
-xss2m # 每个线程栈大小,默认 512k,调大会减少最大线程数
8. 生产级排查工具箱
8.1 arthas —— 线上诊断神器
# 下载并启动
curl -o https://arthas.aliyun.com/arthas-boot.jar
java -jar arthas-boot.jar
# 常用命令
dashboard # 实时查看 jvm 状态
heap # 查看堆内存
thread -n 5 # cpu 最高的 5 个线程
jad com.example.foo # 反编译线上类
watch com.example.foo methodname '{params,returnobj}' # 监控方法入参出参
trace com.example.foo methodname # 追踪方法调用链路耗时
8.2 常用工具对比
| 工具 | 适用场景 | 优点 |
|---|---|---|
| jprofiler | idea 集成 heap dump 分析 | 可视化极强,idea 官方推荐 |
| arthas | 线上动态诊断 | 无需重启,功能强大 |
| jvisualvm | 本地可视化监控 | jdk 自带,图形化 |
| jstack | 线程 dump 分析 | 简单直接,排查死锁 |
| jmap | 堆内存快照 | 配合 jprofiler 使用 |
| jstat | gc 实时监控 | 轻量,适合快速判断 |
| prometheus + grafana | 长期监控告警 | 生产环境标配 |
8.3 推荐 jvm 参数配置(生产模板)
# 堆内存 -xms2g -xmx2g # gc 选择(推荐 g1) -xx:+useg1gc -xx:maxgcpausemillis=200 # oom 自动 dump -xx:+heapdumponoutofmemoryerror -xx:heapdumppath=/var/logs/ # gc 日志 -xx:+printgcdetails -xx:+printgcdatestamps -xloggc:/var/log/gc-%t.log -xx:+usegclogfilerotation -xx:numberofgclogfiles=5 -xx:gclogfilesize=20m # metaspace -xx:metaspacesize=128m -xx:maxmetaspacesize=256m # 直接内存 -xx:maxdirectmemorysize=512m
9. 总结与最佳实践
oom 处理决策树
oom error occurred
│
▼
┌─────────────────────────────┐
│ 查看完整错误信息 │
│ 确认 oom 类型 │
└─────────────────────────────┘
│
┌───────────────┼───────────────┐
▼ ▼ ▼
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ heap / │ │ metaspace / │ │ direct / │
│ gc overhead │ │ thread oom │ │ stack oom │
└─────────────┘ └─────────────┘ └─────────────┘
│ │ │
▼ ▼ ▼
jprofiler jstat -class jcmd vm.
分析 dump 查看类加载 native_mem
ory
│ │ │
└───────┬───────┴───────┬───────┘
▼ ▼
┌─────────────┐ ┌─────────────┐
│ 找到根因 │ │ 临时止血 │
│ 修复代码 │ │ 扩内存/重启 │
└─────────────┘ └─────────────┘
│ │
└───────┬───────┘
▼
┌─────────────────┐
│ 完善监控告警 │
│ (内存>80%预警) │
└─────────────────┘
分步处理:
- oom 发生 → 第一时间查看完整错误信息,确认 oom 类型
- 根据类型选工具:
heap space/gc overhead→ jprofiler 分析 heap dump → 找泄漏点metaspace→jstat -gcmetacapacity <pid>查类加载数量unable to create native thread→ps -elf | grep java | wc -l查线程数direct buffer memory→jcmd <pid> vm.native_memory summary查堆外内存stackoverflow→jstack <pid>+ arthasthread -n 10定位递归
- 临时止血:扩内存参数 / 重启服务
- 根治方向:修复代码 + 完善监控告警(内存使用率 > 80% 触发预警)
10 条黄金实践
- 始终开启
-xx:+heapdumponoutofmemoryerror,确保出事时有案可查 - 禁止使用
executors.newcachedthreadpool(),必须使用有界线程池 - 静态集合慎用,必须有淘汰机制(ttl/lru/弱引用)
- threadlocal 必须 remove(),避免内存泄漏
- 大数据集分批处理,拒绝全量加载到内存
- 资源必须关闭,使用 try-with-resources 语法
- 定期查看 gc 日志,关注 full gc 频率和耗时
- 接入监控告警,内存使用率 > 80% 时触发预警
- 压测先于上线,暴露内存问题在生产环境之前
- 代码 review 关注内存,重点审查集合、缓存、线程相关代码
结语
oom 问题往往没有银弹,最有效的解法永远是找到根本原因,而不是盲目扩内存。扩内存只是推迟了爆炸时间,代码不改,总有一天还会炸。
希望这篇文章能成为你排查 oom 时的参考手册。如果文章对你有帮助,欢迎点赞收藏 🌟,有问题欢迎评论区交流!
参考资料
- jvm 规范 - oracle 官方文档
- jprofiler 官方文档
- arthas 用户文档
- 《深入理解 java 虚拟机》—— 周志明
到此这篇关于java oom问题定位到彻底根治的文章就介绍到这了,更多相关java oom问题解析内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论