集合进阶(set集合、collections)
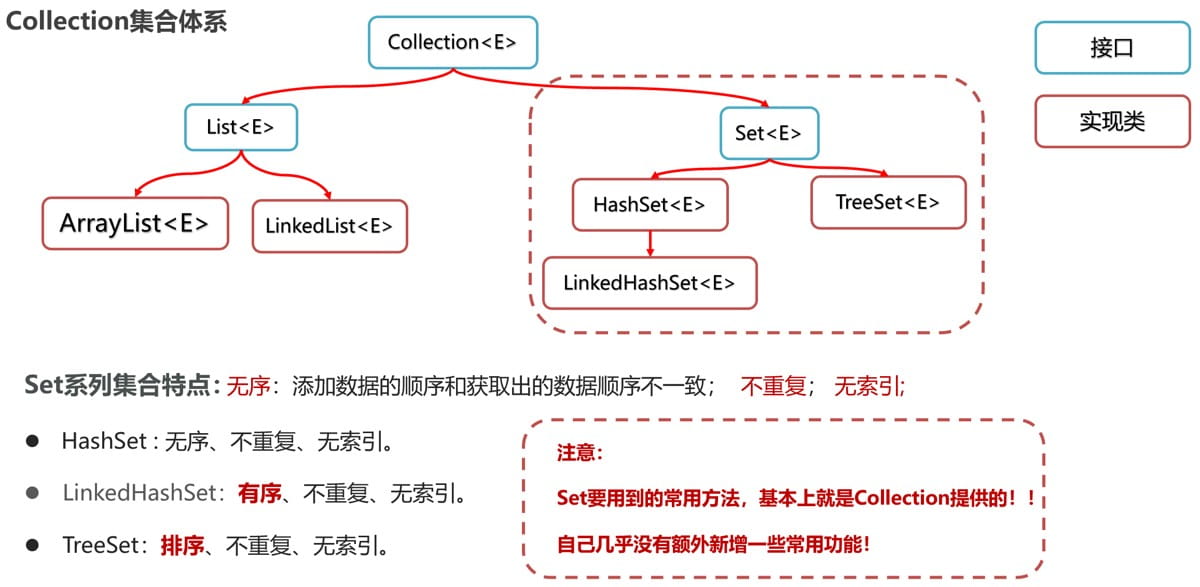
一、set系列集合
1.1 认识set集合的特点
set集合是属于collection体系下的另一个分支,它的特点如下图所示
下面我们用代码简单演示一下,每一种set集合的特点。
public class settest1 {
public static void main(string[] args) {
// 创建一个set集合的对象
/**
* hashset的集合, 是一行经典代码(常用) 特点: 无序不重复 无索引
* 针对无序不是每次都是随机的, 第一次无序排好之后, 以后都是这个顺序(面试题)
*/
// set<integer> set = new hashset<>();
// 特点: 有序、无索引、不重复
// set<integer> set = new linkedhashset<>();
// 可排序(默认升序)、无索引、不重复
set<integer> set = new treeset<>();
set.add(666);
set.add(555);
set.add(555);
set.add(888);
set.add(888);
set.add(777);
set.add(777);
system.out.println(set);
}
}1.2 hashset集合底层原理
接下来,为了让同学们更加透彻的理解hashset为什么可以去重,我们来看一下它的底层原理。
hashset集合底层是基于哈希表实现的,所以在正式了解hashset集合的底层原理前,我们需要先搞清楚一个前置知识:哈希值!:

演示哈希值的相同与不相同
public class student {
private string name;
private int age;
private double height;
public student() {
}
public student(string name, int age, double height) {
this.name = name;
this.age = age;
this.height = height;
}
// 自己提供getter 和 setter方法 以及tostring方法
@override
public boolean equals(object o) {
if (this == o) return true;
if (o == null || getclass() != o.getclass()) return false;
student student = (student) o;
return age == student.age && double.compare(height, student.height) == 0 && objects.equals(name, student.name);
}
@override
public int hashcode() {
int result = name != null ? name.hashcode() : 0;
result = 31 * result + age;
return result;
}
}
public class settest2 {
public static void main(string[] args) {
// 哈希值不相同
student s1 = new student("柳岩", 18, 163);
student s2 = new student("宝强", 18, 163);
system.out.println(s1.hashcode());
system.out.println(s1.hashcode());
system.out.println(s2.hashcode());
system.out.println("----------------------");
// 哈希值相同
string str1 = new string("abc");
string str2 = new string("acd");
system.out.println(str1.hashcode());
system.out.println(str2.hashcode());
}
}hashset集合的底层原理
- 基于哈希表实现。
- 哈希表是一种增删改查数据,性能都较好的数据结构。
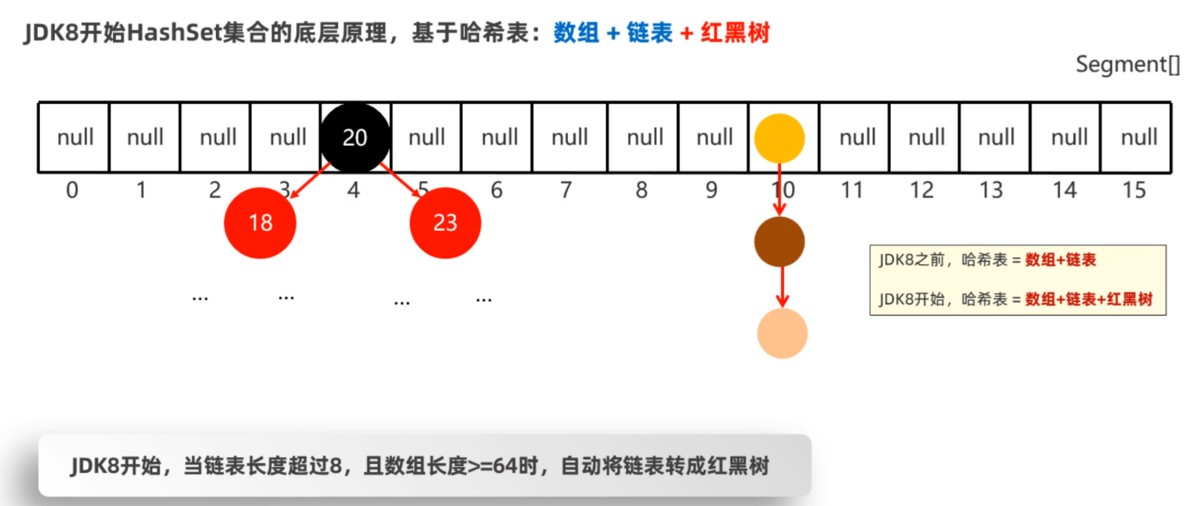
哈希表根据jdk版本的不同,也是有点区别的
- jdk8以前:哈希表 = 数组+链表
- jdk8以后:哈希表 = 数组+链表+红黑树

我们发现往hashset集合中存储元素时,底层调用了元素的两个方法:一个是hashcode方法获取元素的hashcode值(哈希值);另一个是调用了元素的equals方法,用来比较新添加的元素和集合中已有的元素是否相同。
- 只有新添加元素的hashcode值和集合中以后元素的hashcode值相同、新添加的元素调用equals方法和集合中已有元素比较结果为true, 才认为元素重复。
- 如果hashcode值相同,equals比较不同,则以链表的形式连接在数组的同一个索引为位置(如上图所示)
在jdk8开始后,为了提高性能,当链表的长度超过8时,就会把链表转换为红黑树,如下图所示:
总结:
1. 什么是哈希值?对象的哈希值有什么特点?
所谓的哈希值就是jdk根据对象的地址或者属性值算出来的int类型整数。
特点:
同一个对象多次调用hashcode()方法的哈希值相同
不同对象调用的hashcode()方法,哈希值不同,但是可以根据子类重写hashcode()方法让其相同。
2. hashset集合的底层原理是什么样的?
基于哈希表实现的。
jdk8之前的,哈希表:底层使用数组+链表组成
jdk8开始后,哈希表:底层采用数组+链表+红黑树组成。
3. hashset集合利用哈希表操作数据的详细流程是咋回事?
hashset底层采用了哈希表数据结构
哈希表又叫做散列表,哈希表底层是一个数组,这个数组中每一个元素是一个单向链表,每个单向链表都有一个独一无二的hash值,代表数组的下标。在某个单向链表中的每一个节点上的hash值是相同的。hash值实际上是key调用hashcode方法,再通过"hash function"转换成的值。
如何向哈希表中添加元素?
先调用被存储的key的hashcode方法,经过某个算法得出hash值,如果在这个哈希表中不存在这个hash值,则直接加入元素。如果该hash值已经存在,继续调用key之间的equals方法,如果equals方法返回false,则将该元素添加。如果equals方法返回true,则放弃添加该元素
hashset初始化容量是16,默认加载因子是0.75
4. 哈希表的详细流程(面试题)
①.创建一个默认长度16,默认加载因为0.75的数组,数组名table
②.根据元素的哈希值跟数组的长度计算出应存入的位置
③.判断当前位置是否为null,如果是null直接存入,如果位置不为null,表示有元素,则调用equals方法比较属性值,如果一样,则不存,如果不一样,则存入数组。
④.当数组存满到16*0.75=12时,就自动扩容,每次扩容原先的两倍
1.3 hashset去重原理
前面我们学习了hashset存储元素的原理,依赖于两个方法:一个是hashcode方法用来确定在底层数组中存储的位置,另一个是用equals方法判断新添加的元素是否和集合中已有的元素相同。
要想保证在hashset集合中没有重复元素,我们需要重写元素类的hashcode和equals方法。
比如以下面的student类为例,假设把student类的对象作为hashset集合的元素,想要让学生的姓名和年龄相同,就认为元素重复。
public class student{
private string name; //姓名
private int age; //年龄
private double height; //身高
//无参数构造方法
public student(){}
//全参数构造方法
public student(string name, int age, double height){
this.name=name;
this.age=age;
this.height=height;
}
//...get、set、tostring()方法自己补上..
// 按快捷键生成hashcode和equals方法
// alt+insert 选择 hashcode and equals
// 只要两个对象的内容一样就会返回true
@override
public boolean equals(object o) {
if (this == o) return true;
if (o == null || getclass() != o.getclass()) return false;
student student = (student) o;
if (age != student.age) return false;
if (double.compare(student.height, height) != 0) return false;
return name != null ? name.equals(student.name) : student.name == null;
}
// 只要两个对象内容一样, 返回的哈希值就是一样的
@override
public int hashcode() {
// 根据姓名 年龄 身高计算哈希值
return objects.hash(name, age, height);
}
}接着,写一个测试类,往hashset集合中存储student对象。
public class settest3 {
public static void main(string[] args) {
set<student> students = new hashset<>();
student s1 = new student("至尊宝",20, 169.6);
student s2 = new student("蜘蛛精",23, 169.6);
student s3 = new student("蜘蛛精",23, 169.6);
student s4 = new student("牛魔王",48, 169.6);
system.out.println(s2.hashcode());
system.out.println(s3.hashcode());
students.add(s1);
students.add(s2);
students.add(s3);
students.add(s4);
for(student s : students){
system.out.println(s);
}
}
}打印结果如下,我们发现存了两个蜘蛛精,当时实际打印出来只有一个,而且是无序的。
student{name='牛魔王', age=48, height=169.6}
student{name='至尊宝', age=20, height=169.6}
student{name='蜘蛛精', age=23, height=169.6}
总结:
如果希望set集合认为2个内容相同的对象是重复的应该怎么办?
需要重写元素类的hashcode和equals方法。
1.4 linkedhashset底层原理
接下来,我们再学习一个hashset的子类linkedhashset类。linkedhashset它底层采用的是也是哈希表结构,只不过额外新增了一个双向链表来维护元素的存取顺序。如下下图所示:
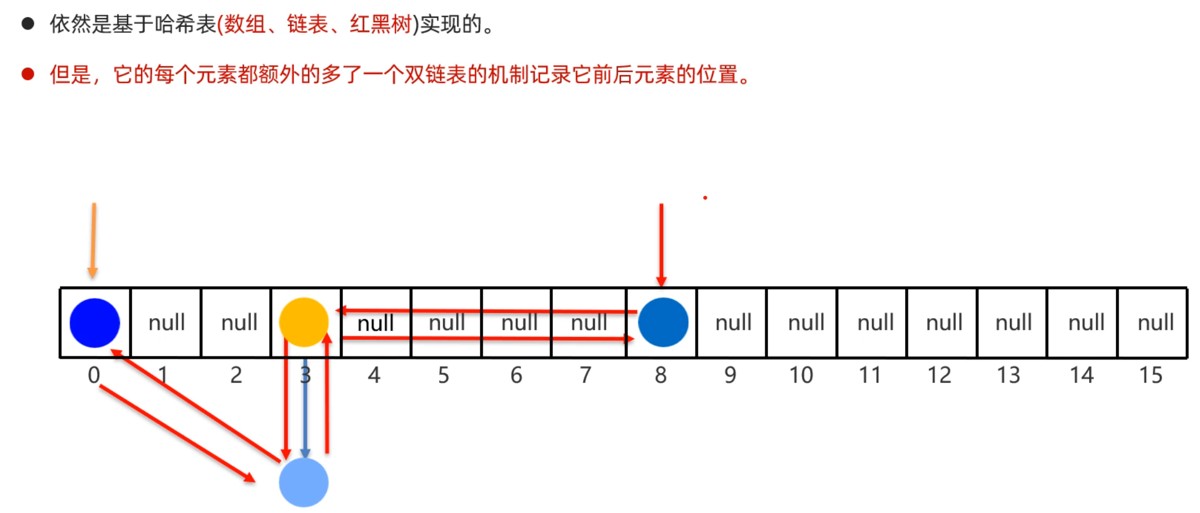
每次添加元素,就和上一个元素用双向链表连接一下。第一个添加的元素是双向链表的头节点,最后一个添加的元素是双向链表的尾节点。
把上个案例中的集合改成linkedlist集合,我们观察效果怎样
public class settest4 {
public static void main(string[] args) {
set<student> students = new linkedhashset<>();
student s1 = new student("至尊宝",20, 169.6);
student s2 = new student("蜘蛛精",23, 169.6);
student s3 = new student("蜘蛛精",23, 169.6);
student s4 = new student("牛魔王",48, 169.6);
students.add(s1);
students.add(s2);
students.add(s3);
students.add(s4);
for(student s : students){
system.out.println(s);
}
}
}打印结果如下
student{name='至尊宝', age=20, height=169.6}
student{name='蜘蛛精', age=23, height=169.6}
student{name='牛魔王', age=48, height=169.6}
总结:
linkedhashset集合的特点和原理是怎么样的?
特点: 有序、不重复、无索引
底层原理: 基于哈希表,使用链表记录添加顺序。
到此这篇关于java集合set与collections案例详解的文章就介绍到这了,更多相关java集合set与collections内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论