一、核心概念:集群是什么?为何而生?
rabbitmq集群的本质,是将多个rabbitmq节点(node)连接成一个逻辑上的消息服务器。这些节点共享一部分数据和状态(主要是元数据),从而在单个节点故障时,其他节点可以接管其工作,保证服务不中断。
它解决的核心问题:
- 高可用性:避免单点故障(spof)。
- 横向扩展:通过增加节点,分散连接和信道的压力,提升整体吞吐量。
- 数据冗余:通过镜像队列,在多节点间复制消息,防止数据丢失。
需要注意:rabbitmq集群默认是“元数据共享,消息不共享”。这意味着交换机、队列的定义和绑定关系在所有节点同步,但队列中的消息默认只存在于声明它的那个节点上。要实现消息的冗余,必须依赖于镜像队列(mirrored queues)策略。
二、底层原理:erlang/otp的分布式基因
rabbitmq的集群能力并非后天嫁接,而是深深植根于其底层实现语言——erlang 的基因之中。erlang/otp平台生来就是为了构建高并发、分布式、高可用的电信级系统。
- 节点通信:集群节点间通过 erlang cookie 进行认证。这是一个相同的字符串,存储在
$home/.erlang.cookie文件中。只有cookie相同的erlang节点才能组成集群。 - 分布式进程:在erlang看来,rabbitmq的每个队列、信道都是一个“进程”。集群将这些进程及其状态信息(元数据)在节点间通过 erlang分布式消息传递 进行同步,效率极高。
- mnesia数据库:rabbitmq使用erlang内置的分布式数据库mnesia来存储集群的元数据(交换机、队列、绑定、用户、vhost等)。mnesia确保了元数据在集群内强一致性。
原理流程图:元数据同步
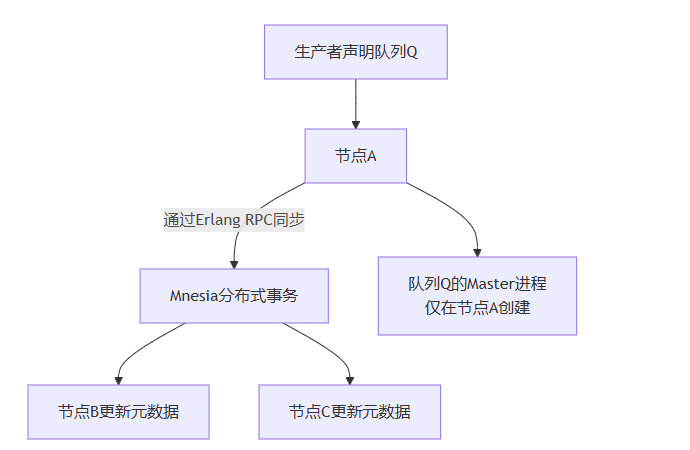
图示:声明队列时,其元数据(定义)在集群内强一致同步,但承载消息的master队列进程只在一个节点创建。*
三、集群部署实战:三步构建集群
我们以三台机器(node1, node2, node3)为例,演示如何手动搭建集群。
前置条件:所有节点安装相同版本的rabbitmq和erlang,并确保 ~/.erlang.cookie 文件内容一致。
步骤1:启动各节点
# 在 node1, node2, node3 上分别执行 sudo systemctl start rabbitmq-server # 或 rabbitmq-server -detached
步骤2:将 node2, node3 加入 node1 的集群
# 在 node2 上执行 rabbitmqctl stop_app rabbitmqctl reset # 如果是新节点,可不reset。如果是已存数据的节点,reset会清除数据! rabbitmqctl join_cluster rabbit@node1 # 注意:rabbit是默认的erlang节点名前缀 rabbitmqctl start_app # 在 node3 上执行相同操作 rabbitmqctl stop_app rabbitmqctl join_cluster rabbit@node1 rabbitmqctl start_app
步骤3:验证集群状态
# 在任意节点执行 rabbitmqctl cluster_status
运行结果示例:
cluster status of node rabbit@node1 ... basics cluster name: rabbit@node1 disk nodes rabbit@node1 rabbit@node2 rabbit@node3 running nodes rabbit@node1 rabbit@node2 rabbit@node3 ...
四、灵魂所在:镜像队列(mirrored queues)
默认集群无法解决消息丢失问题,镜像队列才是实现高可用的关键。它会将队列的内容(消息)复制到集群中的其他多个节点上。
配置策略:通过策略(policy)来为匹配的队列设置镜像规则。
# 设置一个策略,将名称以“mirrored.”开头的队列镜像到所有节点
rabbitmqctl set_policy ha-all "^mirrored\." '{"ha-mode":"all"}'
# 更常见的生产配置:镜像到多数节点(n/2+1),例如3节点集群中镜像到2个
rabbitmqctl set_policy ha-majority "^ha\." '{"ha-mode":"exactly", "ha-params":2, "ha-sync-mode":"automatic"}'- ha-mode:
all,exactly,nodes - ha-sync-mode:
manual(手动同步,默认) 或automatic(自动同步)。生产环境建议在业务低峰期手动同步,或新建队列时自动同步,避免高峰同步引发网络阻塞。
镜像队列架构图:
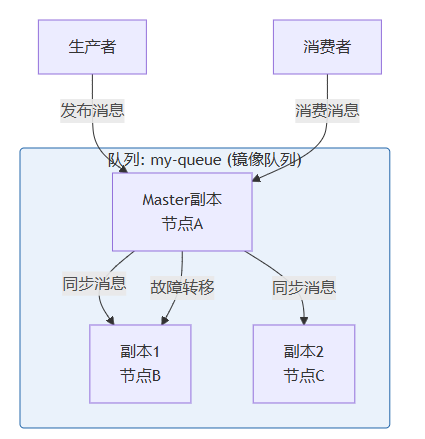
图示:生产者/消费者只与master副本交互。master故障后,最老的副本会被提升为新的master。*
五、客户端连接:负载均衡与故障转移
客户端连接集群时,不应写死一个节点地址,而应提供节点列表,客户端会按顺序尝试连接。
java客户端连接示例:
import com.rabbitmq.client.connection;
import com.rabbitmq.client.connectionfactory;
import java.io.ioexception;
import java.util.concurrent.timeoutexception;
public class clusterconnectionexample {
public static void main(string[] args) throws ioexception, timeoutexception {
connectionfactory factory = new connectionfactory();
factory.setusername("guest");
factory.setpassword("guest");
factory.setvirtualhost("/");
// 关键:设置集群节点地址数组
// 格式:amqp:// 可省略,默认端口5672
address[] addresses = new address[] {
new address("node1", 5672),
new address("node2", 5672),
new address("node3", 5672)
};
// 自动重试连接。也可以使用外部负载均衡器(如haproxy、f5)
connection connection = factory.newconnection(addresses, "myapp-client");
system.out.println("成功连接到集群: " + connection.getaddress().gethostaddress());
// ... 使用 connection 创建 channel 进行后续操作
connection.close();
}
}运行结果:
成功连接到集群: node1 (假设node1是第一个可用的节点)
六、企业级最佳实践与配置详解
- 节点类型:
- 磁盘节点(disc node):将元数据和消息存储到磁盘。集群中至少需要一个磁盘节点来保证元数据可靠性。 生产环境通常所有节点都是磁盘节点。
- 内存节点(ram node):将元数据仅存储在内存,性能极高,但重启后数据丢失(依赖磁盘节点同步)。适用于临时、高性能的中间节点,但增加了运维复杂度,不推荐新手使用。
- 集群规模:建议3或5个节点(奇数个),便于维持仲裁多数(quorum)。超过5个节点,同步开销会显著增大,收益递减。
- 网络要求:集群节点间需要稳定的低延迟网络。避免跨地域部署集群,应使用同地域多可用区。
- 镜像队列策略:
- ha-sync-mode: 新镜像节点加入时,
automatic会同步所有历史消息,可能阻塞队列。建议在业务低峰期通过rabbitmqctl sync_queue {queue_name}手动同步。 - ha-promote-on-shutdown: 控制主节点优雅关闭时是否提升镜像。默认为
when-synced,只有已同步的镜像才会被提升,更安全。 - ha-promote-on-failure:类似,控制故障时的提升行为。
- ha-sync-mode: 新镜像节点加入时,
七、spring amqp整合:声明镜像队列
在spring boot中,我们可以通过rabbitadmin和cachingconnectionfactory优雅地集成集群。
import org.springframework.amqp.core.*;
import org.springframework.amqp.rabbit.connection.cachingconnectionfactory;
import org.springframework.amqp.rabbit.core.rabbitadmin;
import org.springframework.context.annotation.bean;
import org.springframework.context.annotation.configuration;
import java.util.hashmap;
import java.util.map;
@configuration
public class rabbitmqclusterconfig {
@bean
public cachingconnectionfactory connectionfactory() {
cachingconnectionfactory factory = new cachingconnectionfactory();
// 设置集群节点地址
factory.setaddresses("node1:5672,node2:5672,node3:5672");
factory.setusername("guest");
factory.setpassword("guest");
factory.setvirtualhost("/");
// 开启publisher confirms,保证消息可靠投递
factory.setpublisherconfirmtype(cachingconnectionfactory.confirmtype.correlated);
// 开启publisher returns,监听不可路由消息
factory.setpublisherreturns(true);
return factory;
}
@bean
public rabbitadmin rabbitadmin(cachingconnectionfactory connectionfactory) {
return new rabbitadmin(connectionfactory);
}
@bean
public queue mirroredqueue() {
map<string, object> args = new hashmap<>();
// 在代码中也可以声明队列参数,但通常更推荐用policy在服务端统一定义
// args.put("x-ha-policy", "all"); // 旧参数,已弃用
// 推荐在rabbitmq管理后台或通过rabbitmqctl set_policy设置
return new queue("order.queue",
true, // durable 持久化
false, // exclusive 非独占
false, // autodelete 不自动删除
args);
}
@bean
public directexchange orderexchange() {
return new directexchange("order.exchange", true, false);
}
@bean
public binding orderbinding() {
return bindingbuilder.bind(mirroredqueue())
.to(orderexchange())
.with("order.created");
}
}八、生产环境高可用架构:集群+负载均衡
单一集群仍可能因机房故障而瘫痪。真正的企业级方案是 “多集群镜像” 或 “集群+负载均衡器”。
推荐架构:
[生产者/消费者]
|
[负载均衡器: haproxy/nginx] (virtual ip)
|
[rabbitmq集群]
/ | \
node1 node2 node3 (磁盘节点,同机房)- 负载均衡器:对外提供单一入口,实现节点故障自动切换。
- 客户端:只需连接vip。当node1宕机,连接自动转移到node2。
haproxy配置示例片段:
listen rabbitmq_cluster
bind 0.0.0.0:5670
mode tcp
balance roundrobin
timeout client 3h
timeout server 3h
option clitcpka
server node1 node1:5672 check inter 5s rise 2 fall 3
server node2 node2:5672 check inter 5s rise 2 fall 3
server node3 node3:5672 check inter 5s rise 2 fall 3客户端连接地址改为 haproxy-host:5670。
九、监控、运维与故障排查
- 监控指标:
- 节点状态:
rabbitmqctl cluster_status,rabbitmqctl node_health_check - 队列状态:消息数、消费者数、内存占用、同步状态(对于镜像队列)。
- erlang运行时:内存、进程数、ets表数量。
- 管理界面:访问
http://node-ip:15672,在 admin -> cluster 查看节点信息,在 queues 页查看队列的“features”是否包含ha(表示是镜像队列)及同步状态(+1表示有一个镜像,+2表示两个)。
- 节点状态:
- 常见故障排查:
- 节点无法加入集群:检查cookie、主机名解析、防火墙、erlang版本。
- 镜像队列不同步:检查网络,查看
rabbitmqctl list_queues name slave_pids synchronised_slave_pids,手动触发同步。 - 脑裂(network partition):这是最严重的问题。rabbitmq会检测到网络分区,并显示在管理界面。处理需谨慎,可设置
cluster_partition_handling参数为pause_minority(少数派节点自动暂停)或autoheal(自动恢复),但都有风险,最好从网络层面避免。
十、易错点与常见误区
误区1:搭建了集群,消息就不会丢失了。
- 正确理解:默认集群只同步元数据。必须配合使用【持久化消息(delivery mode=2)】、【持久化队列】和【镜像队列策略】, 才能实现节点故障时的消息不丢失。同时,生产者需要使用publisher confirm,消费者需要手动ack。
误区2:镜像队列越多,可靠性越高,性能越好。
- 正确理解:镜像队列带来可靠性的同时,会显著增加网络开销和磁盘io。每一条消息都要同步到所有镜像节点,性能会下降。通常镜像到2-3个节点(包含master)是性价比较高的选择。
误区3:消费者可以连接任意节点消费任意队列。
- 正确理解:消费者可以连接集群任意节点。但如果该节点不是队列master所在节点,rabbitmq会在内部建立跨节点信道,将消息从master节点路由到消费者连接的节点,这会增加内部网络流量。最佳实践是让消费者尽量连接到队列master所在的节点(但这通常由负载均衡器决定,难以精确控制)。
易混淆概念:持久化 vs 镜像
- 持久化:将消息和队列定义写入磁盘,防止rabbitmq服务重启导致数据丢失。
- 镜像:将队列的内容(消息)复制到其他节点,防止单个节点物理故障导致数据丢失。
- 关系:两者需结合使用。一个队列可以持久化但不镜像(单点重启不丢,宕机丢);也可以镜像但不持久化(节点宕机切换不丢,重启丢)。生产环境必须同时开启。
十一、高级主题:仲裁队列(quorum queues) vs 镜像队列
自rabbitmq 3.8版本引入了仲裁队列,它是为集群环境设计的现代队列类型,旨在解决经典镜像队列的一些复杂性问题。
对比表:
| 特性 | 经典镜像队列 (classic mirrored) | 仲裁队列 (quorum queue) |
|---|---|---|
| 设计目标 | 在传统主从复制上增加高可用 | 基于raft共识算法,强一致性、数据安全 |
| 数据一致性 | 最终一致性(异步复制) | 强一致性(多数节点确认) |
| 节点故障处理 | 自动故障转移,可能丢消息(未同步部分) | 自动故障转移,保证已确认消息不丢 |
| 配置复杂度 | 高(需理解policy, ha参数) | 低(声明时指定类型即可) |
| 性能 | 较高(异步复制) | 略低(强一致需多数节点确认) |
| 推荐场景 | 高吞吐,允许极小概率消息丢失的常规业务 | 金融交易、订单状态等对一致性要求极高的核心业务 |
声明仲裁队列:
import org.springframework.amqp.core.queuebuilder;
@bean
public queue quorumorderqueue() {
return queuebuilder.durable("quorum.order.queue")
.quorum() // 设置为仲裁队列
.build();
}十二、java生产-消费示例
场景:模拟一个订单创建后,发送到高可用集群的镜像队列。
1. 生产者 (orderproducer.java)
import com.rabbitmq.client.channel;
import com.rabbitmq.client.connection;
import com.rabbitmq.client.connectionfactory;
import com.rabbitmq.client.messageproperties;
import java.nio.charset.standardcharsets;
public class orderproducer {
private final static string exchange_name = "order.exchange.ha";
private final static string routing_key = "order.created";
private final static string queue_name = "order.queue.ha";
public static void main(string[] argv) throws exception {
// 1. 连接工厂
connectionfactory factory = new connectionfactory();
factory.sethost("localhost"); // 生产环境应为负载均衡器地址
factory.setport(5672);
factory.setusername("guest");
factory.setpassword("guest");
factory.setvirtualhost("/");
// 2. 创建连接和信道
// 使用try-with-resources确保资源关闭
try (connection connection = factory.newconnection();
channel channel = connection.createchannel()) {
// 3. 声明持久化的直连交换机和持久化的队列
// 注意:这些定义会在集群节点间同步(元数据)
channel.exchangedeclare(exchange_name, "direct", true);
// 队列声明,假设服务端已通过policy将此队列设为镜像队列
channel.queuedeclare(queue_name, true, false, false, null);
channel.queuebind(queue_name, exchange_name, routing_key);
// 4. 开启publisher confirms (异步确认)
channel.confirmselect();
// 5. 发送持久化消息
string message = "订单消息: order-20240426-001";
channel.basicpublish(exchange_name,
routing_key,
messageproperties.persistent_text_plain, // 关键:消息持久化
message.getbytes(standardcharsets.utf_8));
system.out.println(" [x] 发送 '" + message + "'");
// 6. 等待broker确认
if (channel.waitforconfirms(5000)) {
system.out.println(" [✓] 消息已得到broker确认,投递成功。");
} else {
system.out.println(" [x] 消息未得到broker确认,可能投递失败。");
// 实际生产环境应实现重试或落库补偿逻辑
}
} // try-with-resources会自动关闭channel和connection
}
}运行结果:
[x] 发送 '订单消息: order-20240426-001'
[✓] 消息已得到broker确认,投递成功。
2. 消费者 (orderconsumer.java)
import com.rabbitmq.client.*;
import java.io.ioexception;
import java.nio.charset.standardcharsets;
import java.util.concurrent.timeoutexception;
public class orderconsumer {
private final static string queue_name = "order.queue.ha";
public static void main(string[] argv) throws ioexception, timeoutexception {
connectionfactory factory = new connectionfactory();
factory.sethost("localhost");
factory.setusername("guest");
factory.setpassword("guest");
connection connection = factory.newconnection();
channel channel = connection.createchannel();
// 为了保证公平分发,在消费者端设置qos
int prefetchcount = 1; // 每次只预取1条消息
channel.basicqos(prefetchcount);
system.out.println(" [*] 等待消息。按 ctrl+c 退出");
delivercallback delivercallback = (consumertag, delivery) -> {
string message = new string(delivery.getbody(), standardcharsets.utf_8);
system.out.println(" [x] 收到 '" + message + "'");
try {
// 模拟业务处理耗时
thread.sleep(1000);
system.out.println(" [✓] 业务处理完成: " + message);
} catch (interruptedexception e) {
thread.currentthread().interrupt();
} finally {
// 关键:手动确认消息,保证可靠性
// deliverytag, multiple
channel.basicack(delivery.getenvelope().getdeliverytag(), false);
system.out.println(" [✓] 消息已手动确认。");
}
};
// 消费消息,关闭自动确认(autoack=false),采用手动确认
boolean autoack = false;
channel.basicconsume(queue_name, autoack, delivercallback, consumertag -> {
system.out.println(" [x] 消费者被取消: " + consumertag);
});
}
}运行结果:
[*] 等待消息。按 ctrl+c 退出
[x] 收到 '订单消息: order-20240426-001'
[✓] 业务处理完成: 订单消息: order-20240426-001
[✓] 消息已手动确认。
十三、性能、可靠性与监控
性能考量:
- 网络延迟是最大瓶颈:镜像和仲裁队列的性能严重依赖节点间网络延迟。务必保证集群节点在低延迟的网络环境中(通常要求<1ms)。
- 磁盘速度:使用ssd硬盘,特别是对于持久化队列和仲裁队列。
- 内存:确保有足够的内存,erlang vm会利用内存进行缓存。通过
rabbitmqctl status监控memory部分。
可靠性 checklist:
- 集群节点数 >= 3(且为奇数)
- 所有节点为磁盘节点
- 配置了镜像队列或使用仲裁队列
- 生产者使用 publisher confirm
- 消息设置为持久化 (
persistent) - 消费者使用手动 ack
- 有完善的监控和告警(队列长度、节点状态、内存/磁盘使用率)
十四、延伸思考
思考一:在脑裂(网络分区)发生后,rabbitmq 的两个分区各自接管了部分队列的master,网络恢复后,数据会出现什么冲突?rabbitmq 的 pause_minority 和 autoheal 两种处理策略分别如何应对?各自的优缺点是什么?
提示:从cap理论的角度思考,rabbitmq在脑裂时优先保证了可用性(a),牺牲了部分一致性(c)。
引申阅读:raft共识算法、分布式系统脑裂处理。
思考二:如果我想实现跨地域(如北京-上海)的高可用,使用一个rabbitmq集群是否合适?如果不合适,应该采用什么架构?
提示:考虑网络延迟(通常>30ms)对镜像同步性能和可靠性的致命影响。
引申阅读:rabbitmq federation / shovel 插件,实现集群间的消息转发。
思考三:仲裁队列(quorum queue)基于raft协议,为什么它能保证强一致性和数据安全,但在写入延迟上会比经典镜像队列高?
提示:思考raft协议中“leader选举”、“日志复制”和“多数派提交”的过程。
引申阅读:raft论文,分布式共识算法。
延伸阅读:
- rabbitmq官方文档 - https://www.rabbitmq.com/clustering.html
- rabbitmq官方文档 - https://www.rabbitmq.com/ha.html
- rabbitmq官方文档 - https://www.rabbitmq.com/quorum-queues.html
- 《rabbitmq in depth》 - 第7章 clustering and high availability
到此这篇关于rabbitmq集群实现消息的高可用性和负载均衡的文章就介绍到这了,更多相关rabbitmq集群高可用性和负载均衡内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!

发表评论